

At the moment’s growth in laptop imaginative and prescient (CV) began firstly of the 21st century with the breakthrough of deep studying fashions and convolutional neural networks (CNN). The primary CV strategies embrace picture classification, picture localization, object detection, and segmentation.
On this article, we dive into a number of the most vital analysis papers that triggered the speedy improvement of laptop imaginative and prescient. We break up them into two classes – classical CV approaches, and papers primarily based on deep-learning. We selected the next papers primarily based on their affect, high quality, and applicability.
- Gradient-based Studying Utilized to Doc Recognition (1998)
- Distinctive Picture Options from Scale-Invariant Keypoints (2004)
- Histograms of Oriented Gradients for Human Detection (2005)
- SURF: Speeded Up Strong Options (2006)
- ImageNet Classification with Deep Convolutional Neural Networks (2012)
- Very Deep Convolutional Networks for Massive-Scale Picture Recognition (2014)
- GoogLeNet – Going Deeper with Convolutions (2014)
- ResNet – Deep Residual Studying for Picture Recognition (2015)
- Sooner R-CNN: In direction of Actual-Time Object Detection with Area Proposal Networks (2015)
- YOLO: You Solely Look As soon as: Unified, Actual-Time Object Detection (2016)
- Masks R-CNN (2017)
- EfficientNet – Rethinking Mannequin Scaling for Convolutional Neural Networks (2019)
About us: Viso Suite is the end-to-end laptop imaginative and prescient resolution for enterprises. With a easy interface and options that give machine studying groups management over the complete ML pipeline, Viso Suite makes it attainable to attain a 3-year ROI of 695%. E book a demo to study extra about how Viso Suite might help clear up enterprise issues.
Basic Laptop Imaginative and prescient Papers
Gradient-based Studying Utilized to Doc Recognition (1998)
The authors Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner printed the LeNet paper in 1998. They launched the idea of a trainable Graph Transformer Community (GTN) for handwritten character and phrase recognition. They researched (non) discriminative gradient-based methods for coaching the recognizer with out guide segmentation and labeling.
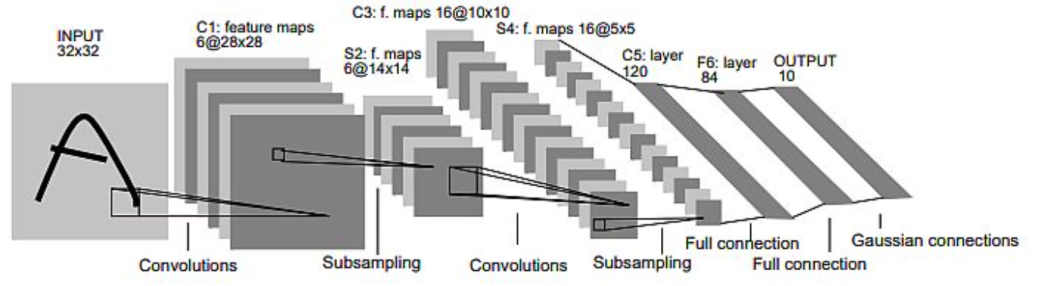
Traits of the mannequin:
- LeNet-5 CNN accommodates 6 convolution layers with a number of characteristic maps (156 trainable parameters).
- The enter is a 32×32 pixel picture and the output layer consists of Euclidean Radial Foundation Perform models (RBF) one for every class (letter).
- The coaching set consists of 30000 examples, and authors achieved a 0.35% error price on the coaching set (after 19 passes).
Discover the LeNet paper here.
Distinctive Picture Options from Scale-Invariant Keypoints (2004)
David Lowe (2004), proposed a technique for extracting distinctive invariant options from pictures. He used them to carry out dependable matching between totally different views of an object or scene. The paper launched Scale Invariant Function Remodel (SIFT), whereas reworking picture information into scale-invariant coordinates relative to native options.
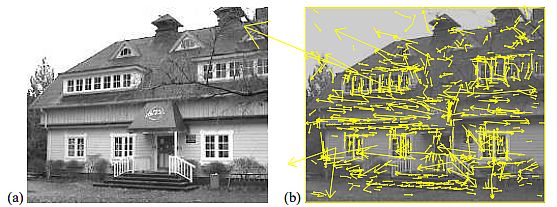
Mannequin traits:
- The tactic generates massive numbers of options that densely cowl the picture over the total vary of scales and areas.
- The mannequin must match at the least 3 options from every object – as a way to reliably detect small objects in cluttered backgrounds.
- For picture matching and recognition, the mannequin extracts SIFT options from a set of reference pictures saved in a database.
- SIFT mannequin matches a brand new picture by individually evaluating every characteristic from the brand new picture to this earlier database (Euclidian distance).
Discover the SIFT paper here.
Histograms of Oriented Gradients for Human Detection (2005)
The authors Navneet Dalal and Invoice Triggs researched the characteristic units for sturdy visible object recognition, by utilizing a linear SVM-based human detection as a take a look at case. They experimented with grids of Histograms of Oriented Gradient (HOG) descriptors that considerably outperform present characteristic units for human detection.

Authors achievements:
- The histogram technique gave near-perfect separation from the unique MIT pedestrian database.
- For good outcomes – the mannequin requires: fine-scale gradients, high quality orientation binning, i.e. high-quality native distinction normalization in overlapping descriptor blocks.
- Researchers examined a tougher dataset containing over 1800 annotated human pictures with many pose variations and backgrounds.
- In the usual detector, every HOG cell seems 4 instances with totally different normalizations and improves efficiency to 89%.
Discover the HOG paper here.
SURF: Speeded Up Strong Options (2006)
Herbert Bay, Tinne Tuytelaars, and Luc Van Goo introduced a scale- and rotation-invariant curiosity level detector and descriptor, known as SURF (Speeded Up Strong Options). It outperforms beforehand proposed schemes regarding repeatability, distinctiveness, and robustness, whereas computing a lot sooner. The authors relied on integral pictures for picture convolutions, moreover using the main present detectors and descriptors.

Authors achievements:
- Utilized a Hessian matrix-based measure for the detector, and a distribution-based descriptor, simplifying these strategies to the important.
- Offered experimental outcomes on a normal analysis set, in addition to on imagery obtained within the context of a real-life object recognition software.
- SURF confirmed robust efficiency – SURF-128 with an 85.7% recognition price, adopted by U-SURF (83.8%) and SURF (82.6%).
Discover the SURF paper here.
Papers Primarily based on Deep-Studying Fashions
ImageNet Classification with Deep Convolutional Neural Networks (2012)
Alex Krizhevsky and his group received the ImageNet Problem in 2012 by researching deep convolutional neural networks. They skilled one of many largest CNNs at that second over the ImageNet dataset used within the ILSVRC-2010 / 2012 challenges and achieved one of the best outcomes reported on these datasets. They carried out a highly-optimized GPU of 2D convolution, thus together with all required steps in CNN coaching, and printed the outcomes.
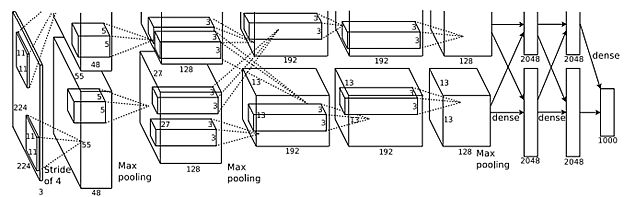
Mannequin traits:
- The ultimate CNN contained 5 convolutional and three totally related layers, and the depth was fairly important.
- They discovered that eradicating any convolutional layer (every containing lower than 1% of the mannequin’s parameters) resulted in inferior efficiency.
- The identical CNN, with an additional sixth convolutional layer, was used to categorise the complete ImageNet Fall 2011 launch (15M pictures, 22K classes).
- After fine-tuning on ImageNet-2012 it gave an error price of 16.6%.
Discover the ImageNet paper here.
Very Deep Convolutional Networks for Massive-Scale Picture Recognition (2014)
Karen Simonyan and Andrew Zisserman (Oxford College) investigated the impact of the convolutional community depth on its accuracy within the large-scale picture recognition setting. Their predominant contribution is an intensive analysis of networks of accelerating depth utilizing an structure with very small (3×3) convolution filters, particularly specializing in very deep convolutional networks (VGG). They proved {that a} important enchancment on the prior-art configurations might be achieved by pushing the depth to 16–19 weight layers.
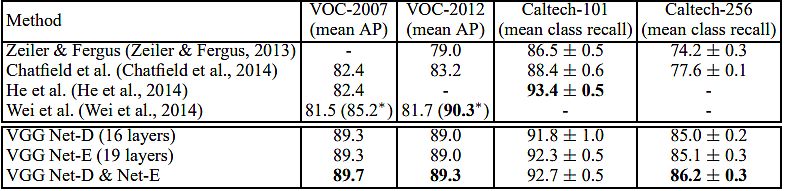
Authors achievements:
- Their ImageNet Problem 2014 submission secured the primary and second locations within the localization and classification tracks respectively.
- They confirmed that their representations generalize effectively to different datasets, the place they achieved state-of-the-art outcomes.
- They made two best-performing ConvNet fashions publicly out there, along with the deep visible representations in CV.
Discover the VGG paper here.
GoogLeNet – Going Deeper with Convolutions (2014)
The Google group (Christian Szegedy, Wei Liu, et al.) proposed a deep convolutional neural community structure codenamed Inception. They supposed to set the brand new state-of-the-art for classification and detection within the ImageNet Massive-Scale Visible Recognition Problem 2014 (ILSVRC14). The primary hallmark of their structure was the improved utilization of the computing sources contained in the community.
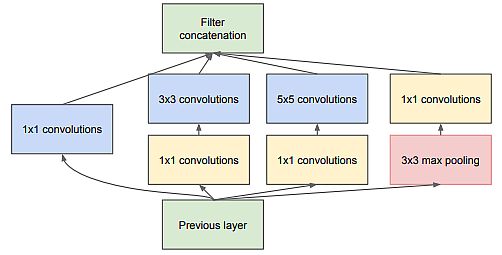
Authors achievements:
- A rigorously crafted design that enables for rising the depth and width of the community whereas protecting the computational price range fixed.
- Their submission for ILSVRC14 was known as GoogLeNet, a 22-layer deep community. Its high quality was assessed within the context of classification and detection.
- They added 200 area proposals coming from multi-box rising the protection from 92% to 93%.
- Lastly, they used an ensemble of 6 ConvNets when classifying every area which improved outcomes from 40% to 43.9% accuracy.
Discover the GoogLeNet paper here.
ResNet – Deep Residual Studying for Picture Recognition (2015)
Microsoft researchers Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Solar introduced a residual studying framework (ResNet) to ease the coaching of networks which might be considerably deeper than these used beforehand. They reformulated the layers as studying residual capabilities in regards to the layer inputs, as a substitute of studying unreferenced capabilities.
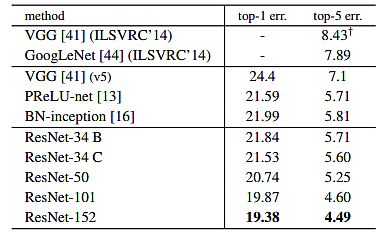
Authors achievements:
- They evaluated residual nets with a depth of as much as 152 layers – 8× deeper than VGG nets, however nonetheless having decrease complexity.
- This end result received 1st place on the ILSVRC 2015 classification job.
- The group additionally analyzed the CIFAR-10 with 100 and 1000 layers, reaching a 28% relative enchancment on the COCO object detection dataset.
- Furthermore – in ILSVRC & COCO 2015 competitions, they received 1st place on the duties of ImageNet detection, ImageNet localization, COCO detection/segmentation.
Discover the ResNet paper here.
Sooner R-CNN: In direction of Actual-Time Object Detection with Area Proposal Networks (2015)
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Solar launched the Area Proposal Community (RPN) with full-image convolutional options with the detection community, due to this fact enabling practically cost-free area proposals. Their RPN was a completely convolutional community that concurrently predicted object bounds and goal scores at every place. Additionally, they skilled the RPN end-to-end to generate high-quality area proposals, which had been utilized by Quick R-CNN for detection.
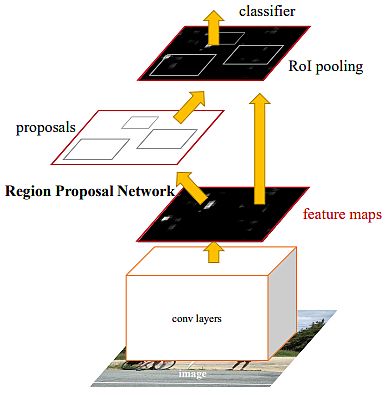
Authors achievements:
- Merged RPN and quick R-CNN right into a single community by sharing their convolutional options. As well as, they utilized neural networks with “consideration” mechanisms.
- For the very deep VGG-16 mannequin, their detection system had a body price of 5fps on a GPU.
- Achieved state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with solely 300 proposals per picture.
- In ILSVRC and COCO 2015 competitions, sooner R-CNN and RPN had been the foundations of the 1st-place profitable entries in a number of tracks.
Discover the Sooner R-CNN paper here.
YOLO: You Solely Look As soon as: Unified, Actual-Time Object Detection (2016)
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi developed YOLO, an revolutionary strategy to object detection. As a substitute of repurposing classifiers to carry out detection, the authors framed object detection as a regression downside. As well as, they spatially separated bounding containers and related class chances. A single neural community predicts bounding containers and sophistication chances instantly from full pictures in a single analysis. Because the entire detection pipeline is a single community, it may be optimized end-to-end instantly on detection efficiency.
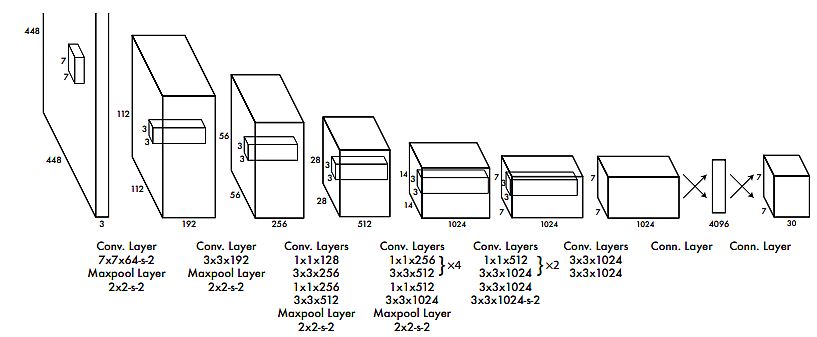
Mannequin traits:
- The bottom YOLO mannequin processed pictures in real-time at 45 frames per second.
- A smaller model of the community, Quick YOLO, processed 155 frames per second, whereas nonetheless reaching double the mAP of different real-time detectors.
- In comparison with state-of-the-art detection methods, YOLO was making extra localization errors, however was much less more likely to predict false positives within the background.
- YOLO realized very normal representations of objects and outperformed different detection strategies, together with DPM and R-CNN, when generalizing pure pictures.
Discover the YOLO paper here.
Masks R-CNN (2017)
Kaiming He, Georgia Gkioxari, Piotr Greenback, and Ross Girshick (Fb) introduced a conceptually easy, versatile, and normal framework for object occasion segmentation. Their strategy may detect objects in a picture, whereas concurrently producing a high-quality segmentation masks for every occasion. The tactic, known as Masks R-CNN, prolonged Sooner R-CNN by including a department for predicting an object masks in parallel with the prevailing department for bounding field recognition.
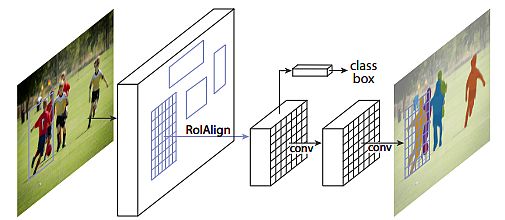
Mannequin traits:
- Masks R-CNN is easy to coach and provides solely a small overhead to Sooner R-CNN, operating at 5 fps.
- Confirmed nice leads to all three tracks of the COCO suite of challenges. Additionally, it consists of occasion segmentation, bounding field object detection, and particular person keypoint detection.
- Masks R-CNN outperformed all present, single-model entries on each job, together with the COCO 2016 problem winners.
- The mannequin served as a stable baseline and eased future analysis in instance-level recognition.
Discover the Masks R-CNN paper here.
EfficientNet – Rethinking Mannequin Scaling for Convolutional Neural Networks (2019)
The authors (Mingxing Tan, Quoc V. Le) studied mannequin scaling and recognized that rigorously balancing community depth, width, and backbone can result in higher efficiency. They proposed a brand new scaling technique that uniformly scales all dimensions of depth decision utilizing a easy however efficient compound coefficient. They demonstrated the effectiveness of this technique in scaling up MobileNet and ResNet.
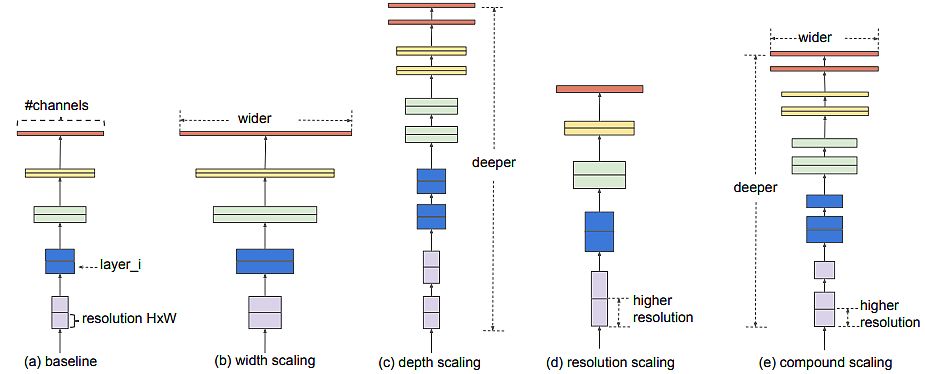
Authors achievements:
- Designed a brand new baseline community and scaled it as much as receive a household of fashions, known as EfficientNets. It had significantly better accuracy and effectivity than earlier ConvNets.
- EfficientNet-B7 achieved state-of-the-art 84.3% top-1 accuracy on ImageNet, whereas being 8.4x smaller and 6.1x sooner on inference than one of the best present ConvNet.
- It additionally transferred effectively and achieved state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and three different switch studying datasets, with a lot fewer parameters.
Discover the EfficientNet paper here.