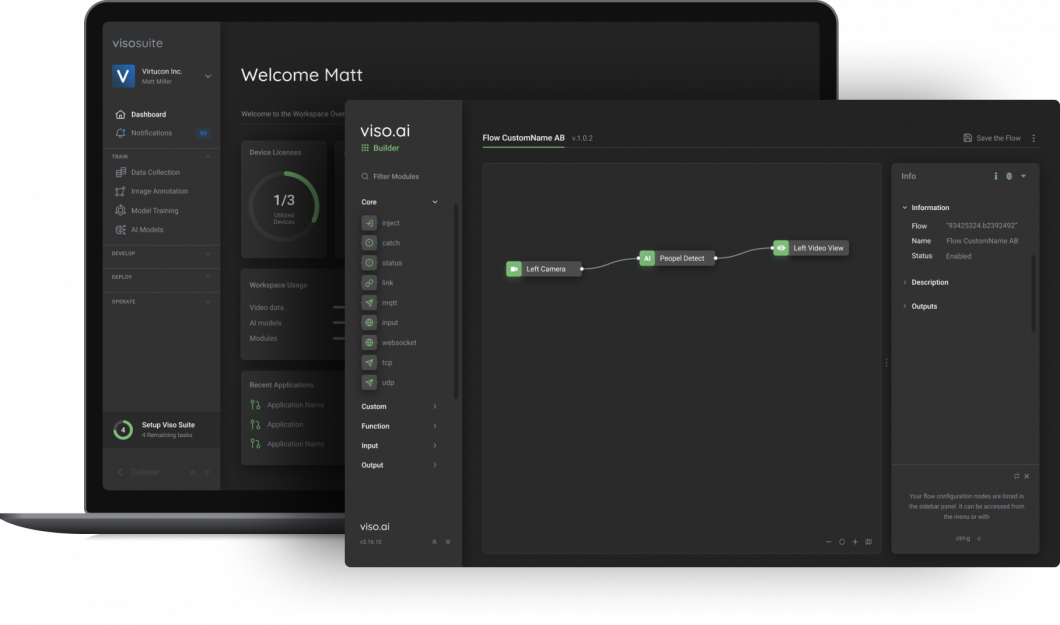
Illustration Studying is a course of that simplifies uncooked knowledge into comprehensible patterns for machine studying. It enhances interpretability, uncovers hidden options, and aids in switch studying.
Knowledge in its uncooked type (phrases and letters in textual content, pixels in pictures) is just too advanced for machines to course of straight. Illustration studying transforms the info right into a illustration that machines can use for classification or predictions.
Deep Studying, a subset of Machine Studying duties has been revolutionary up to now twenty years. This success of Deep Studying closely depends on the developments made in illustration studying.
Beforehand, guide characteristic engineering constrained mannequin capabilities, because it required in depth experience and energy to establish related options. Whereas Deep studying automated this characteristic extraction.
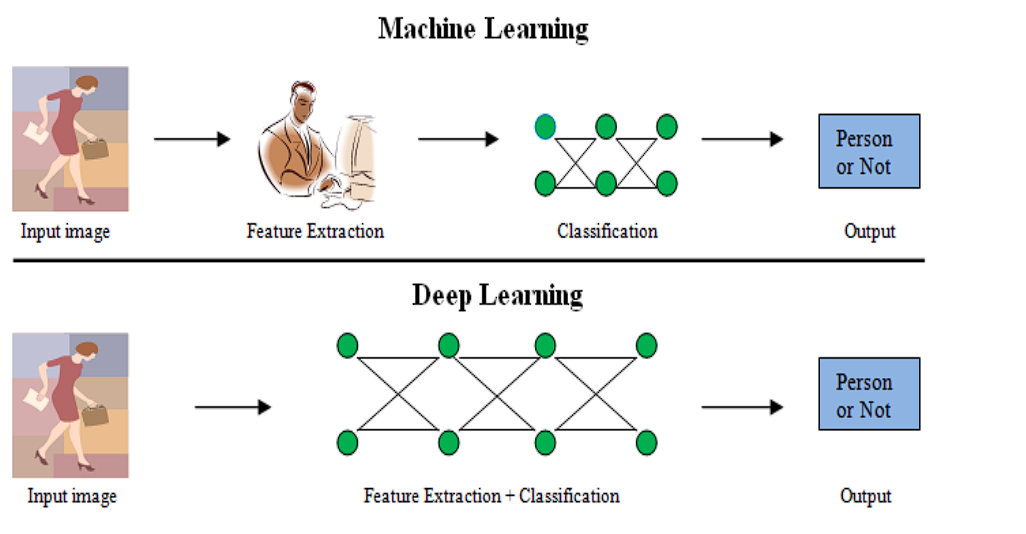
Historical past of Illustration Studying
Illustration Studying has superior considerably. Hinton and co-authors’ breakthrough discovery in 2006 marks a pivotal level, shifting the main target of illustration studying in direction of Deep Studying Architectures. The researchers’ idea of using grasping layer-wise pre-training adopted by fine-tuning deep neural networks led to additional developments.
Here’s a fast overview of the timeline.
- Conventional Strategies (Pre-2000):
- Deep Studying Period (2006 onwards):
- Neural Networks: The introduction of deep neural networks by Hinton et al. in 2006 marked a turning level. Deep Neural Community fashions might study advanced, hierarchical representations of information by a number of layers. Eg, CNN, RNN, Autoencoder, and Transformers.
What’s a Good Illustration?
illustration has three traits: Data, compactness, and generalization.
- Data: The illustration encodes essential options of the info right into a compressed type.
- Compactness:
- Low Dimensionality: Discovered embedding representations from uncooked knowledge needs to be a lot smaller than the unique enter. This permits for environment friendly storage and retrieval, and in addition discards noise from the info, permitting the mannequin to deal with related options and converge quicker.
- Preserves Important Data: Regardless of being lower-dimensional, the illustration retains essential options. This stability between dimensionality discount and data preservation is crucial.
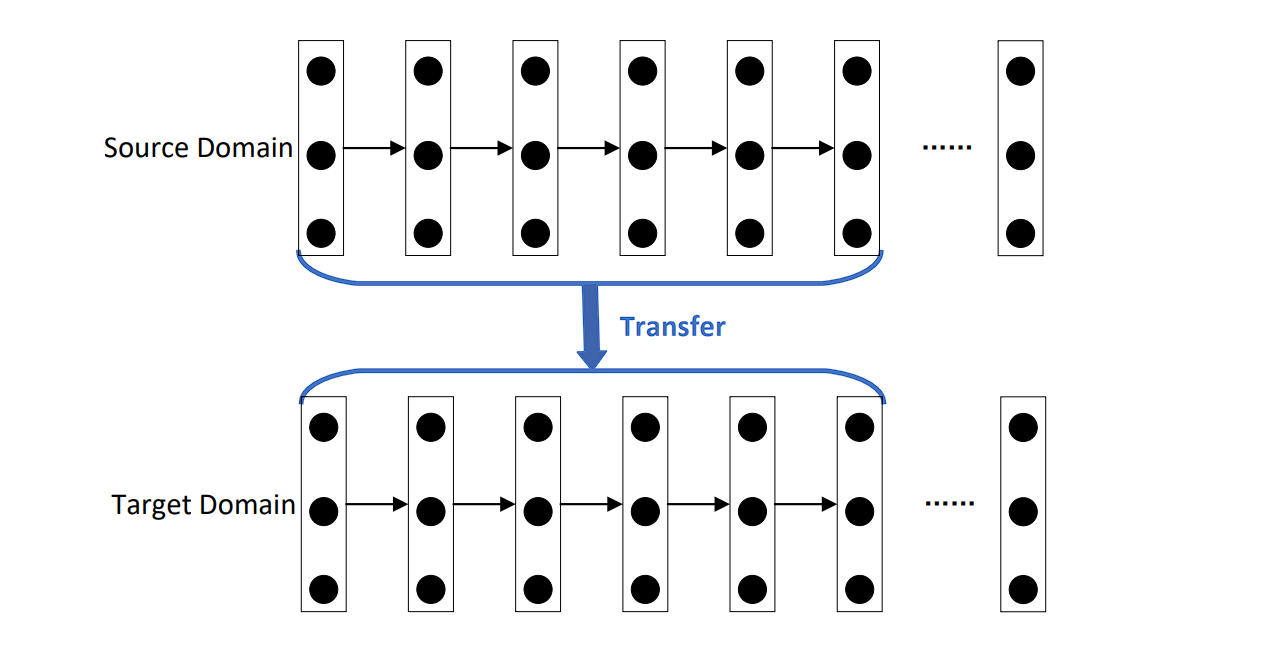
- Generalization (Switch Studying): The goal is to study versatile representations for switch studying, beginning with a pre-trained mannequin (laptop imaginative and prescient fashions are sometimes educated on ImageNet first) after which fine-tuning it for particular duties requiring much less knowledge.
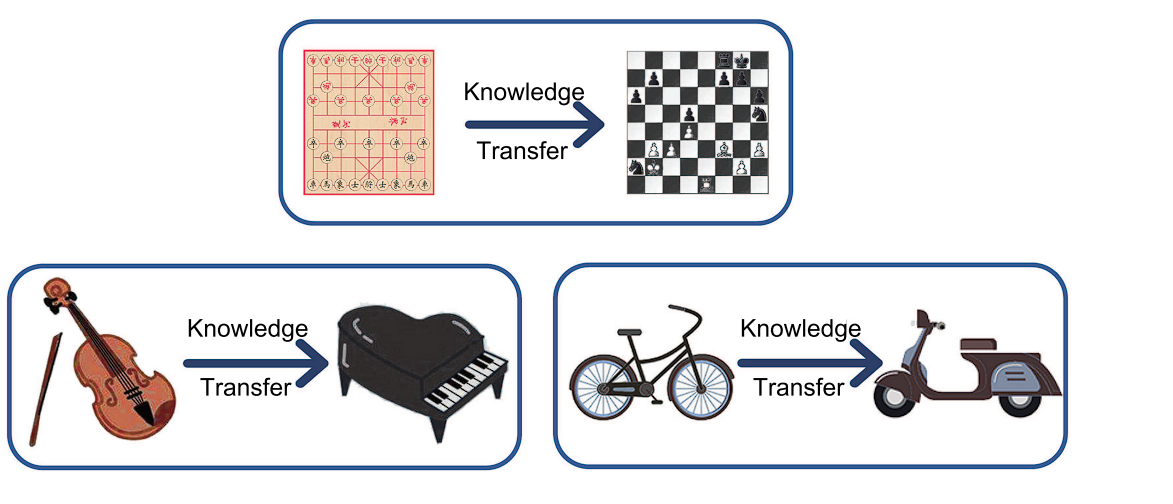
Switch Studying – Source
Deep Studying for Illustration Studying
Deep Neural Networks are illustration studying fashions. They encode the enter info into hierarchical representations and mission it into varied subspaces. These subspaces then undergo a linear classifier that performs classification operations.
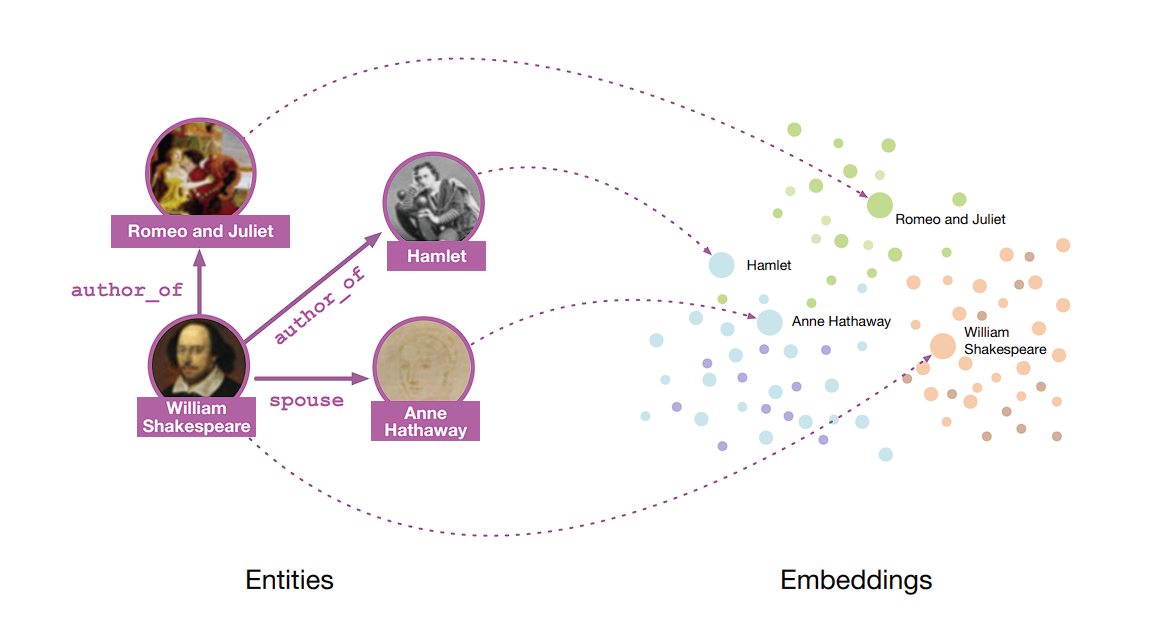
Deep Studying duties may be divided into two classes: Supervised and Unsupervised Studying. The deciding issue is the usage of labeled knowledge.
- Supervised Illustration Studying:
- Leverages Labeled Knowledge: Makes use of labeled knowledge. The labels information the educational algorithm concerning the desired consequence.
- Focuses on Particular Duties: The training course of is tailor-made in direction of a selected job, akin to picture classification or sentiment evaluation. The discovered representations are optimized to carry out nicely on that specific job.
- Examples:
- Unsupervised Illustration Studying:
- With out Labels: Works with unlabeled knowledge. The algorithm identifies patterns and relationships throughout the knowledge itself.
- Focuses on Characteristic Extraction: The aim is to study informative representations that seize the underlying construction and important options of the info. These representations can then be used for varied downstream duties (switch studying).
- Examples:
- Coaching an autoencoder to compress and reconstruct pictures, studying a compressed illustration that captures the important thing options of the picture.
- Utilizing Word2Vec or GloVe on a large textual content corpus to study phrase embeddings, the place phrases with comparable meanings have comparable representations in a high-dimensional house.
- BERT to study contextual illustration of phrases.
Supervised Deep Studying
Convolutional Neural Networks (CNNs)
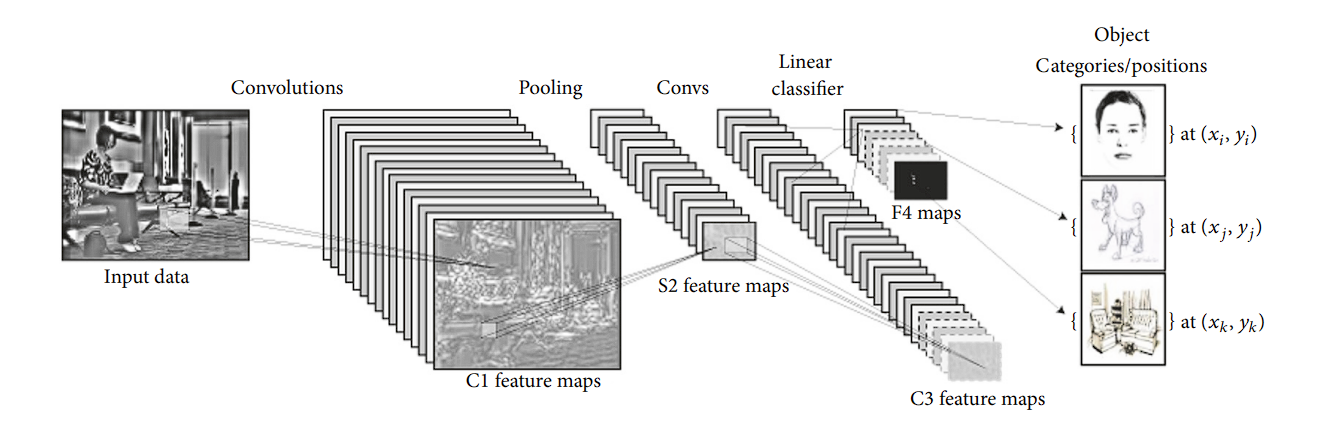
CNNs are a category of supervised studying fashions which are extremely efficient in processing grid-like structured knowledge (pictures).
A CNN captures the spatial and temporal dependencies in a picture by the appliance of learnable filters or kernels. The important thing parts of CNNs embrace:
- Convolutional Layers: These layers apply filters to the enter to create characteristic maps, highlighting essential options like edges and shapes.
- Pooling Layers: Comply with convolutional layers to cut back the dimensionality of the characteristic maps, making the mannequin extra environment friendly by retaining solely essentially the most important info.
- Absolutely Linked Layers: On the finish of the community, these layers classify the picture primarily based on the options extracted by the convolutional and pooling layers.
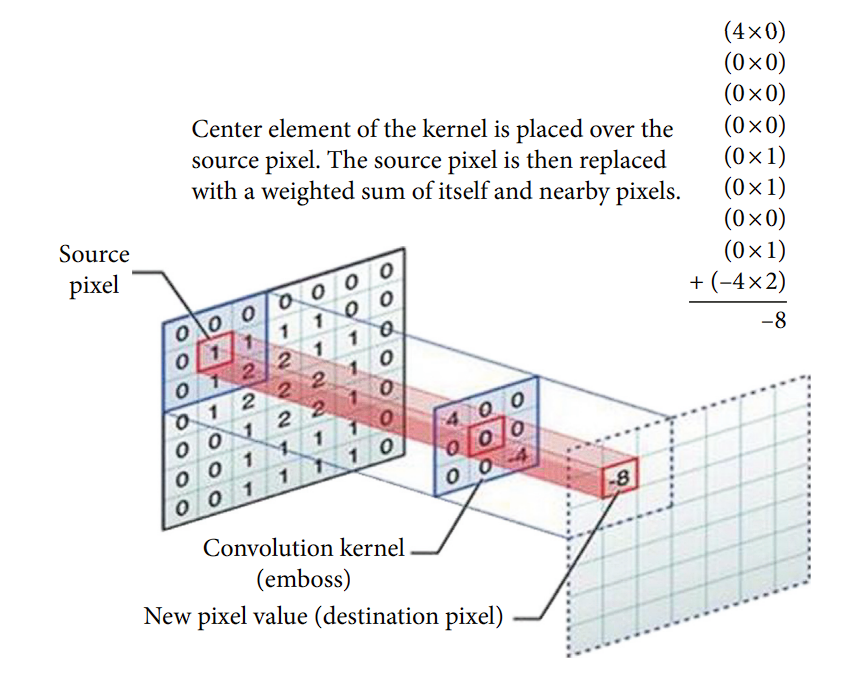
CNNs are good at studying hierarchical characteristic representations in pictures. Decrease layers study to detect edges, colours, and textures, whereas deeper layers establish extra advanced constructions like elements of objects or total objects themselves. This hierarchical studying strategy is extremely efficient for duties requiring the popularity of advanced patterns and objects inside pictures.
CNNs present translation invariance. This implies, that even when an object strikes round in a picture, or the picture is rotated, or skewed, it will probably nonetheless acknowledge the picture. Furthermore, the discovered filters incorporate giant quantity parameter sharing, permitting for dense and decreased dimension illustration.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) and their variants, together with Lengthy Quick-Time period Reminiscence (LSTM) networks and Gated Recurrent Items (GRUs), concentrate on processing sequential knowledge, making them extremely appropriate for duties in pure language processing and time sequence evaluation.
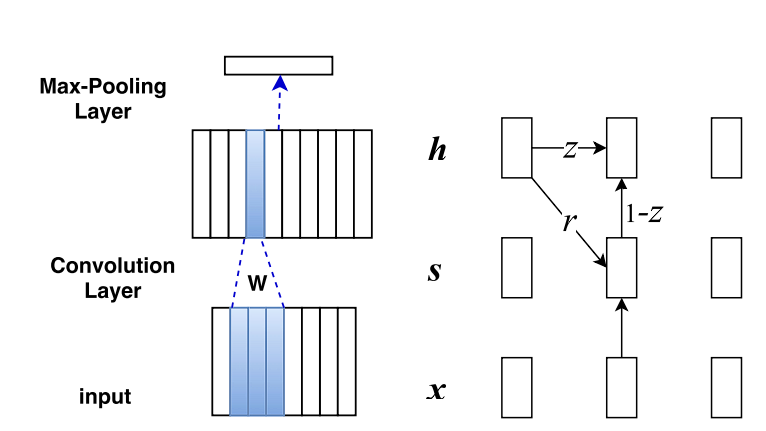
The core concept behind RNNs is their skill to keep up a reminiscence of earlier inputs of their inside state, which influences the processing of present and future inputs, permitting them to seize temporal dependencies.
- RNNs possess a easy construction the place the output from the earlier step is fed again into the community as enter for the present step, making a loop that enables info to persist. Nevertheless, they endure from exploding and vanishing gradients.
- LSTMs are a sophisticated variant of RNN. They introduce a fancy structure with a reminiscence cell and three gates (enter, overlook, and output gates). These parts work collectively to manage the circulation of knowledge, deciding what to retain in reminiscence, what to discard, and what to output. Which solves the exploding and vanishing gradients downside.
- GRUs simplify the LSTM design by combining the enter and overlook gates right into a single “replace gate” and merging the cell state and hidden state.
Nevertheless, RNNs, LSTMs, and GRUs study to seize temporal dependencies by adjusting their weights by backpropagation by time (BPTT), a variant of the usual backpropagation algorithm tailored for sequential knowledge.
By doing so, these networks study advanced patterns within the knowledge, such because the grammatical construction in a sentence or developments in a time sequence, successfully capturing each short-term and long-term dependencies.
Unsupervised Deep Studying
Autoencoders
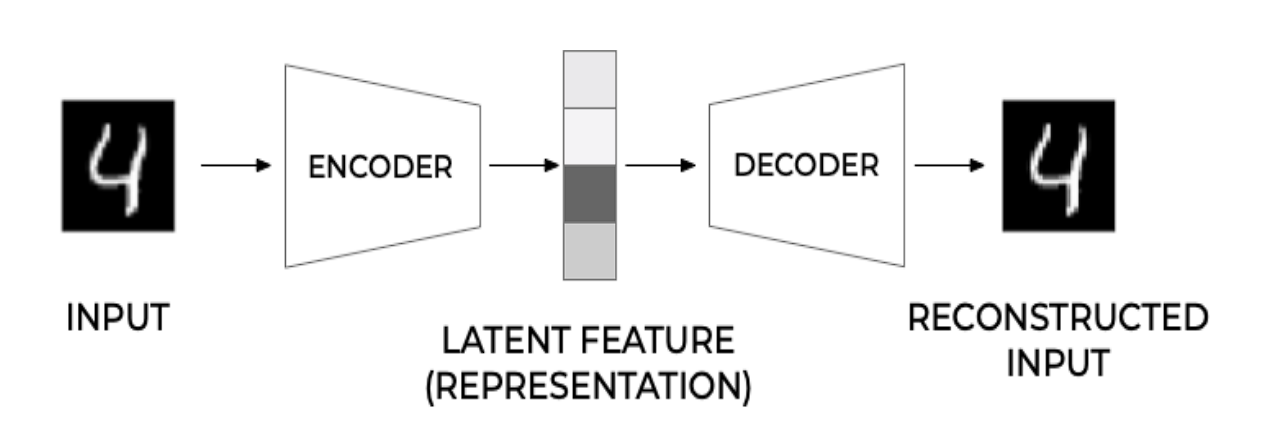
Autoencoders, as unsupervised characteristic studying fashions, study encodings of unlabeled knowledge, normally for dimensionality discount or characteristic studying. Primarily, they goal to reconstruct enter knowledge from the constructed illustration.
Autoencoders have two elements, encoder and decoder.
- Encoder: The encoder compresses the enter right into a latent-space illustration. It learns to cut back the dimensionality of the enter knowledge, capturing its most essential options in a compressed type.
- Decoder: The decoder takes the encoded knowledge and tries to recreate the unique enter. The reconstruction won’t be good however with coaching, the decoder learns to provide output considerably just like the enter.
Auto-encoders study to create dense and helpful representations of information by forcing the community to prioritize essential features of the enter knowledge. These discovered representations may be later used for varied different duties.
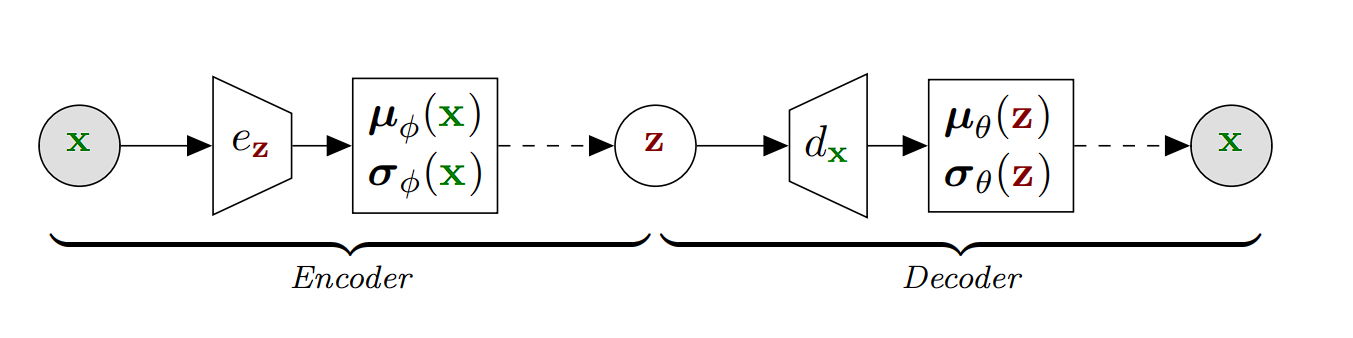
Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are a novel form of autoencoder that compresses knowledge probabilistically, not like common autoencoders. As a substitute of changing an enter (e.g. a picture) right into a single compressed type, VAEs rework it right into a spectrum of potentialities throughout the latent house, typically represented by a multivariate Gaussian distribution.
Thus, when compressing a picture, VAEs don’t choose a selected level within the latent house however somewhat a area that encapsulates the varied interpretations of that picture. Upon decompression, VAEs reconvert these probabilistic mappings into pictures, enabling them to generate new pictures primarily based on discovered representations.
Listed here are the steps concerned:
- Encoder: The encoder in a VAE maps the enter knowledge to a likelihood distribution within the latent house. It produces two issues for every enter: a imply (μ) and a variance (σ²), which collectively outline a Gaussian distribution within the latent house.
- Sampling: As a substitute of straight passing the encoded illustration to the decoder, VAEs pattern some extent from the Gaussian distribution outlined by the parameters produced by the encoder. This sampling step introduces randomness into the method, which is essential for the generative side of VAEs.
- Decoder: The sampled level is then handed to the decoder, which makes an attempt to reconstruct the unique enter from this sampled latent illustration. The reconstruction is not going to be good, partly due to the randomness launched throughout sampling, however it is going to be just like the unique enter.
Generative Adversarial Networks (GANs)
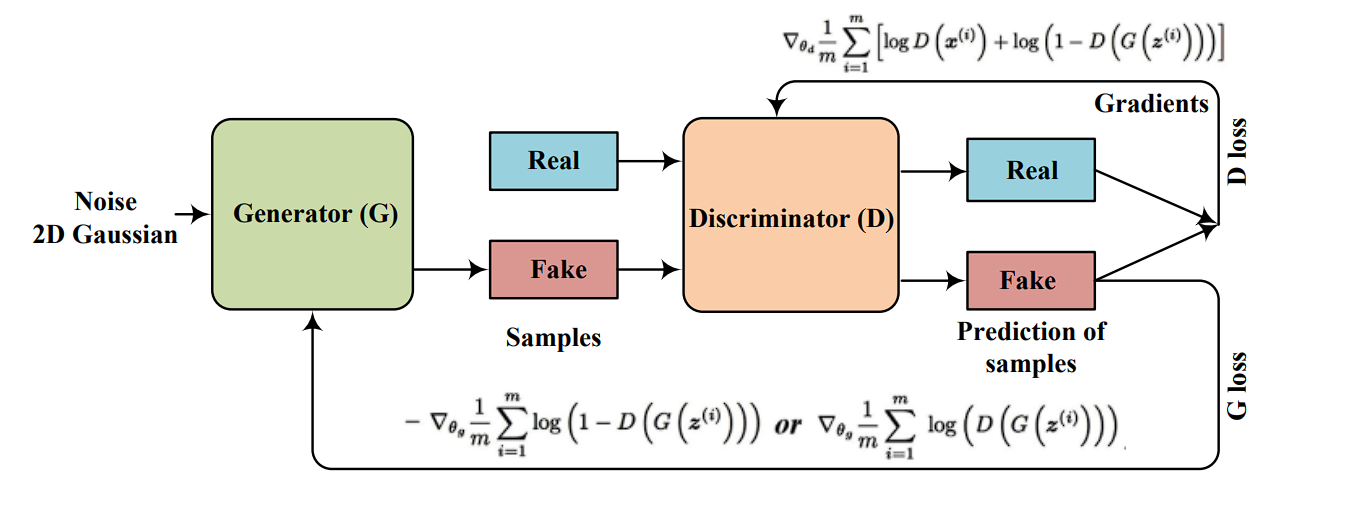
Generative Adversarial Networks (GANs), launched by Ian Goodfellow and colleagues in 2014, are a sort of synthetic intelligence algorithm utilized in unsupervised machine studying.
They contain two neural networks: the generator, which goals to create knowledge resembling actual knowledge, and the discriminator, which tries to distinguish between actual and generated knowledge. These networks are educated collectively in a aggressive game-like course of.
- Generator: The generator community takes random noise as enter and generates samples that resemble the distribution of the actual knowledge. Its aim is to provide knowledge so convincing that the discriminator can’t inform it other than precise knowledge.
- Discriminator: The discriminator community is a classifier that tries to tell apart between actual knowledge and faux knowledge produced by the generator. It’s educated on a mix of actual knowledge and the pretend knowledge generated by the generator, studying to make this distinction.
Transformers
Transformers have revolutionized pure language processing (NLP), providing vital enhancements over earlier fashions like RNNs and LSTMs for duties like textual content translation, sentiment evaluation, and question-answering.
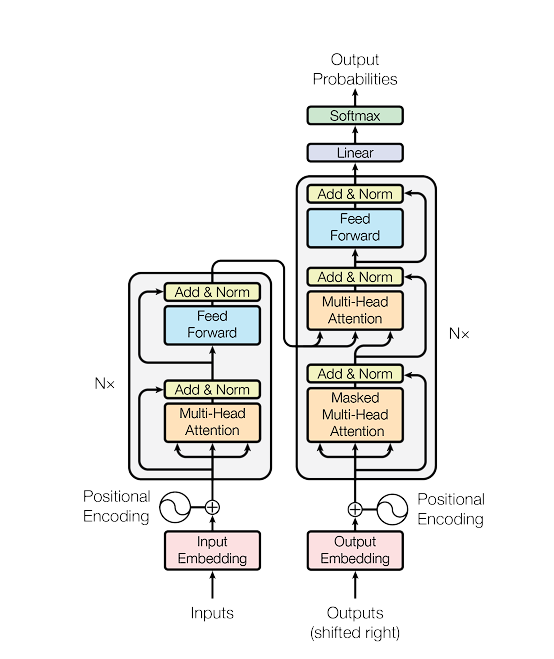
The core innovation of the Transformer is the self-attention mechanism, which permits the mannequin to weigh the significance of various elements of the enter knowledge in a different way, enabling it to study advanced representations of sequential knowledge.
A Transformer mannequin consists of an encoder and a decoder, every consisting of a stack of equivalent layers.
- Encoder: Processes the enter knowledge (e.g., a sentence) and transforms it right into a steady illustration that holds the discovered info of that enter.
- Decoder: Takes the encoder’s output and generates the ultimate output sequence, step-by-step, utilizing the encoder’s illustration and what it has produced to date.
Each the encoder and decoder are made up of a number of layers that embrace self-attention mechanisms.
Self-Consideration is the power of the mannequin to affiliate every phrase within the enter sequence with each different phrase to raised perceive the context and relationships throughout the knowledge. It calculates the eye scores, indicating how a lot focus to placed on different elements of the enter sequence when processing a selected half.
In contrast to sequential fashions like RNNs, the Transformer treats enter knowledge as a complete, permitting it to seize context from each instructions (left and proper of every phrase in NLP duties) concurrently. This results in extra nuanced and contextually wealthy representations.
Graph Neural Networks
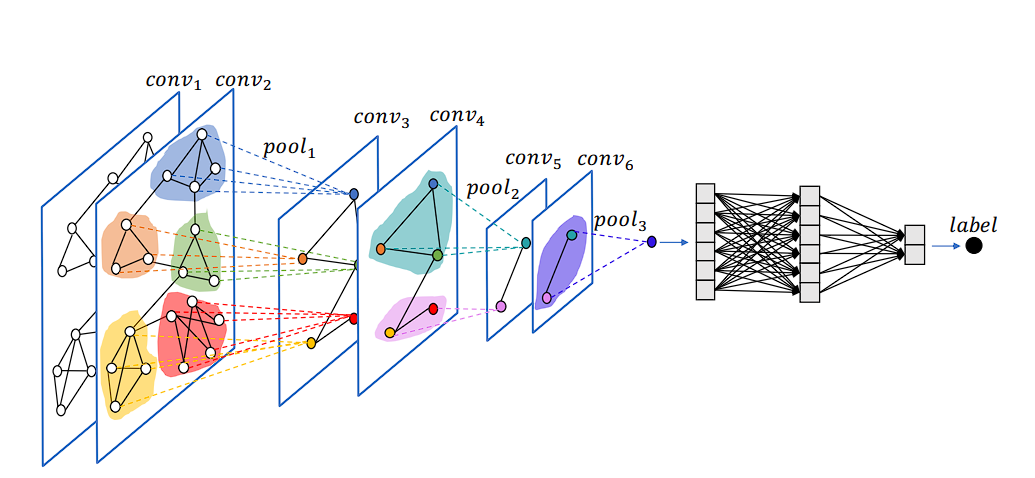
Graph Neural Networks (GNNs) are designed to carry out illustration studying on graph-structured knowledge.
The principle concept behind GNNs is to study a illustration (embedding) for every node and edge, which captures the node’s attributes and the structural info of its neighborhood. The core element of GNNs is message passing. By stacking a number of message-passing layers, GNNs seize speedy neighbor info and options from the neighborhood.
This leads to node embeddings or representations that mirror each native graph topology and world construction. The ultimate node embeddings can then be used for varied duties akin to node classification, hyperlink prediction, and graph classification.
Switch Studying
In switch studying, you first practice a mannequin on a really giant and complete dataset. This preliminary coaching permits the mannequin to study a wealthy illustration of options, weights, and biases. Then, you utilize this discovered illustration as a place to begin for a second mannequin, which can not have as a lot coaching knowledge accessible.
As an example, within the discipline of laptop imaginative and prescient, fashions typically endure pre-training on the ImageNet dataset, which incorporates over 1,000,000 annotated pictures. This course of helps the mannequin to study wealthy options.
Moreover, after this pre-training part, you may fine-tune the mannequin on a smaller, task-specific dataset. Throughout this fine-tuning part, the mannequin adapts the overall options it discovered throughout pre-training to the specifics of the brand new job.
Purposes of Illustration Studying
Pc Imaginative and prescient
- Characteristic Extraction: In conventional laptop imaginative and prescient methods, characteristic extraction was a guide course of, nevertheless DL-based fashions like CNNs streamlined characteristic extraction. CNNs and Autoencoders carry out edge detection, texture evaluation, or colour histograms by themselves.
- Generalization and Switch Studying: Illustration Studying has facilitated the creation of strong fashions like YOLO and EfficientNet for object detection, and semantic segmentation.
Pure Language Processing (NLP)
- Language Fashions: NLP fashions like BERT and GPT use illustration studying to grasp the context and semantics of phrases in sentences, considerably bettering efficiency on duties like textual content classification, sentiment evaluation, machine translation, and query answering.
- Phrase Embeddings: Strategies like Word2Vec and GloVe study dense vector representations of phrases primarily based on their co-occurrence info, capturing semantic similarity and enabling improved efficiency in nearly all NLP duties.
Audio and Speech Processing
- Speech Recognition: Speech Recognition makes use of illustration studying to remodel uncooked audio waveforms into informative options. These options seize the essence of phonetics and language, finally enabling correct speech-to-text conversion.
- Music Technology: Fashions study representations of musical patterns, after which generate new items of music which are stylistically in step with the coaching knowledge.
Healthcare
- Illness Analysis: Illustration studying extracts significant options from medical pictures (like X-rays, and MRIs) or digital well being data, aiding within the prognosis of illnesses akin to most cancers.
- Genomics: Studying representations of genetic sequences aids in understanding gene operate, predicting gene expression ranges, and figuring out genetic markers related to illnesses.
What’s Subsequent?
Get began with enterprise-grade laptop imaginative and prescient. Viso Suite permits ML groups to seamlessly combine laptop imaginative and prescient into their workflows in a matter of days – drastically shortening the time-to-value of the appliance. Be taught extra by reserving a demo with us.