

EfficientNet is a Convolutional Neural Community (CNN) structure that makes use of a compound scaling methodology to uniformly scale depth, width, and backbone, offering excessive accuracy with computational effectivity.
CNNs (Convolutional Neural Networks) energy laptop imaginative and prescient duties like object detection and picture classification. Their potential to study from uncooked photographs has led to breakthroughs in autonomous autos, medical analysis, and facial recognition. Nonetheless, as the dimensions and complexity of datasets develop, CNNs have to develop into deeper and extra complicated to keep up excessive accuracy.
Rising the complexity of CNNs results in higher accuracy, which calls for extra computational sources.
This elevated computational demand makes CNN impractical for real-time functions, and use on units with restricted processing capabilities (smartphones and IoT units). That is the issue EfficientNet tries to resolve. It gives an answer for sustainable and environment friendly scaling of CNNs.
Introducing Viso Suite. Viso Suite is the end-to-end laptop imaginative and prescient platform for enterprises. By consolidating your complete machine studying pipeline right into a single infrastructure. Viso Suite permits ML groups to handle and management your complete software lifecycle. Be taught extra about Viso Suite by reserving a demo with our workforce.
The Path to EfficientNet
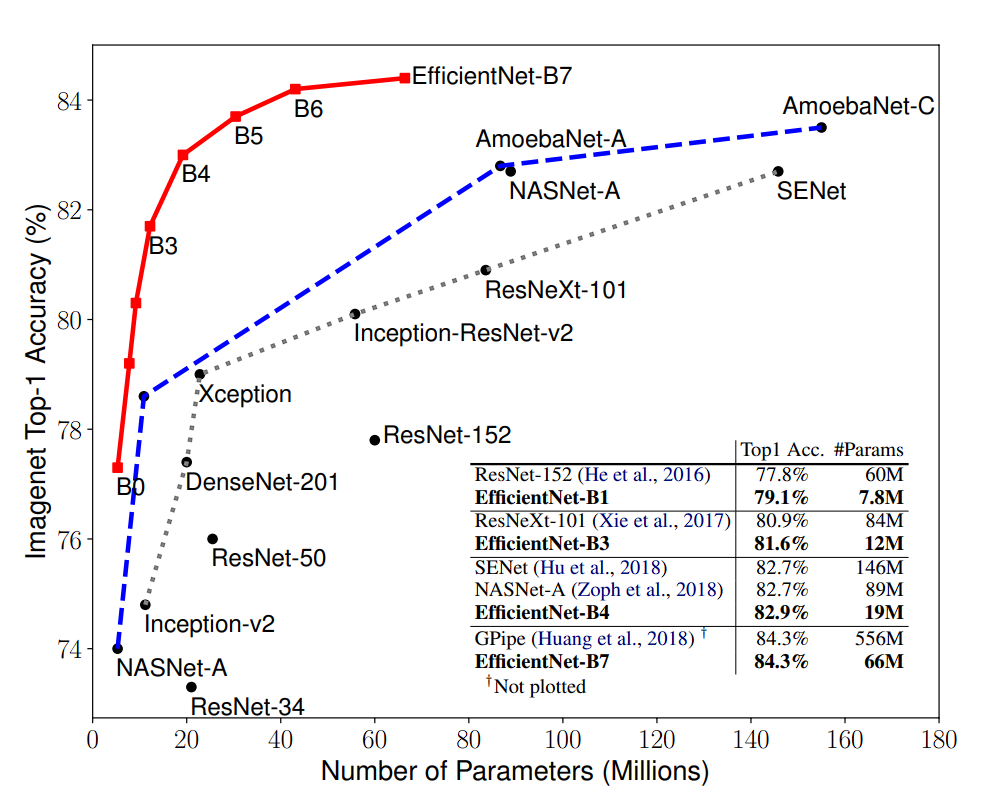
The favored technique of accelerating accuracy via rising mannequin measurement yielded spectacular outcomes up to now, with fashions like GPipe attaining state-of-the-art accuracy on the ImageNet dataset.
From GoogleNet to GPipe (2018), ImageNet top-1 accuracy jumped from 74.8% to 84.3%, together with parameter counts (going from 6.8M to 557M), resulting in extreme computational calls for.
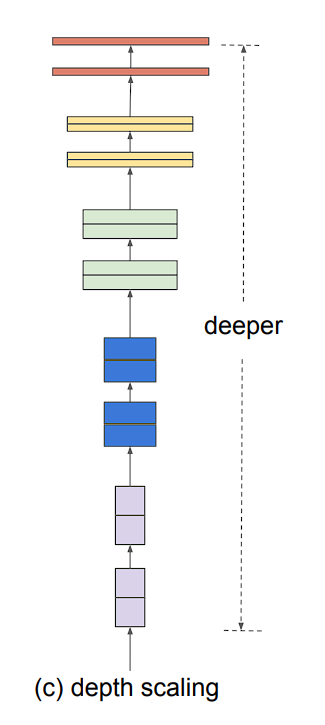
Mannequin scaling may be achieved in 3 ways: by rising mannequin depth, width, or picture decision.
- Depth (d): Scaling community depth is essentially the most generally used methodology. The thought is straightforward, deeper ConvNet captures richer and extra complicated options and in addition generalizes higher. Nonetheless, this resolution comes with an issue, the vanishing gradient downside.
- Width (w): That is utilized in smaller fashions. Widening a mannequin permits it to seize extra fine-grained options. Nonetheless, extra-wide fashions are unable to seize higher-level options.
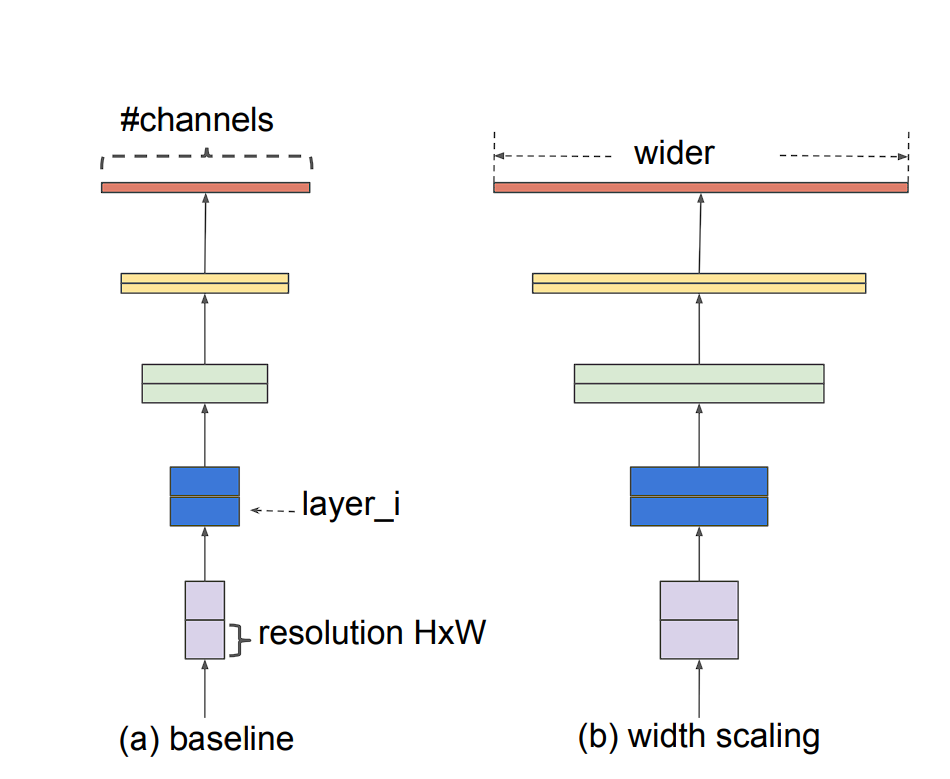
- Picture decision (r): Increased decision photographs allow the mannequin to seize extra fine-grained patterns. Earlier fashions used 224 x 224 measurement photographs, and newer fashions have a tendency to make use of the next decision. Nonetheless, larger decision additionally results in elevated computation necessities.
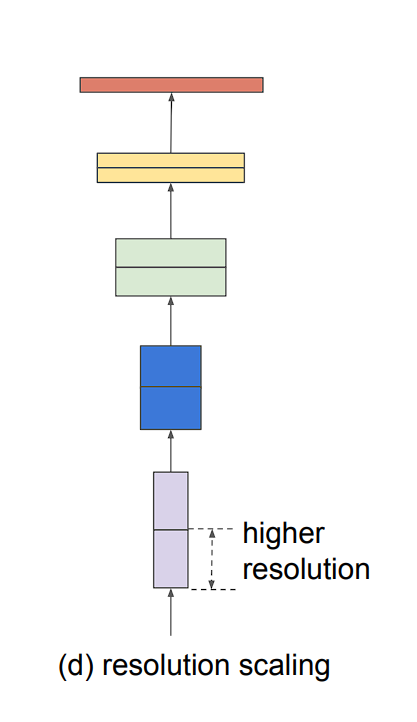
Downside with Scaling
As we have now seen, scaling a mannequin has been a go-to methodology, however it comes with overhead computation prices. Right here is why:
Extra Parameters: Rising depth (including layers) or width (including channels inside layers) results in a big improve within the variety of parameters within the community. Every parameter requires computation throughout coaching and prediction. Extra parameters translate to extra calculations, rising the general computational burden.
Furthermore, scaling additionally results in Reminiscence Bottleneck as bigger fashions with extra parameters require extra reminiscence to retailer the mannequin weights and activations throughout processing.
What’s EfficientNet?
EfficientNet proposes a easy and extremely efficient compound scaling methodology, which permits it to simply scale up a baseline ConvNet to any goal useful resource constraints, in a extra principled and environment friendly means.
What’s Compound Scaling?
The creator of EfficientNet noticed that totally different scaling dimensions (depth, width, picture measurement) will not be unbiased.
Excessive-resolution photographs require deeper networks to seize large-scale options with extra pixels. Moreover, wider networks are wanted to seize the finer particulars current in these high-resolution photographs. To pursue higher accuracy and effectivity, it’s vital to stability all dimensions of community width, depth, and backbone throughout ConvNet scaling.
Nonetheless, scaling CNNs utilizing specific ratios yields a greater outcome. That is what compound scaling does.
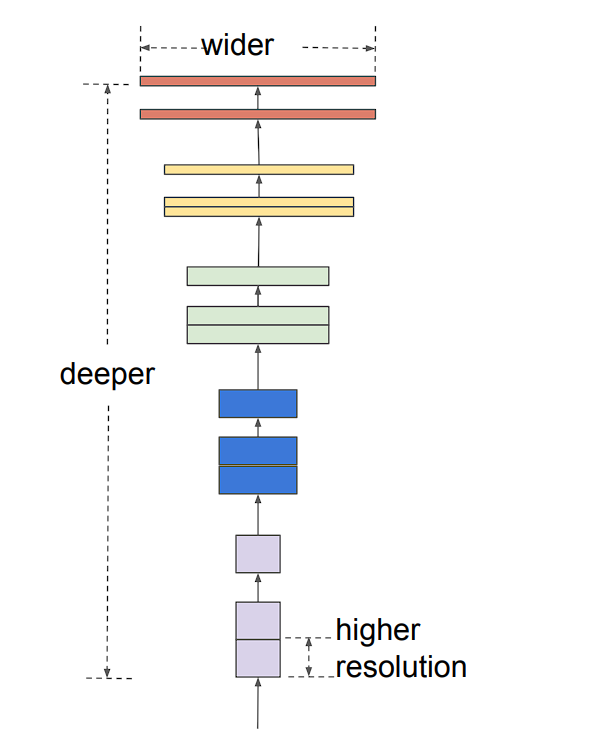
The compound scaling coefficient methodology uniformly scales all three dimensions (depth, width, and backbone) in a proportional method utilizing a predefined compound coefficient ɸ.
Right here is the mathematical expression for the compound scaling methodology:
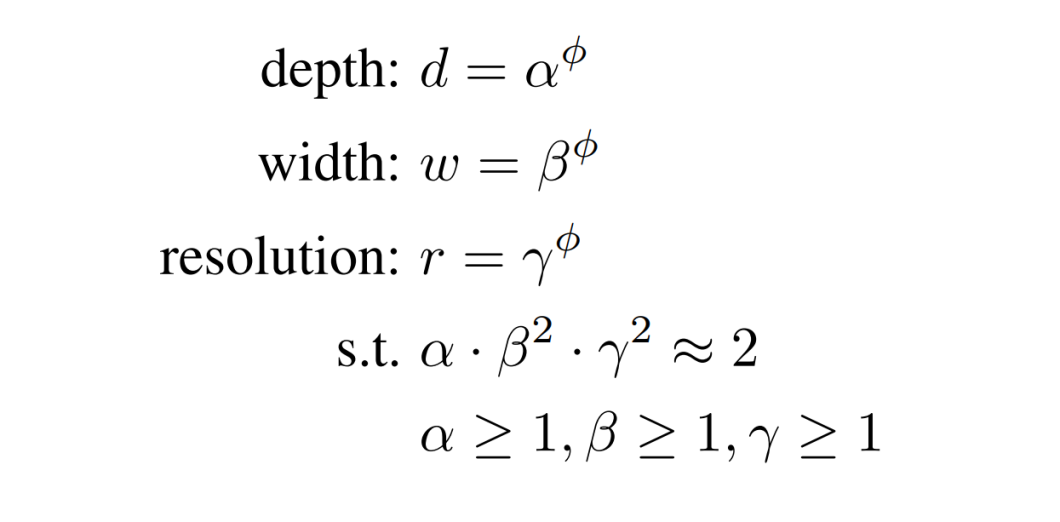
α: Scaling issue for community depth (usually between 1 and a couple of)
β: Scaling issue for community width (usually between 1 and a couple of)
γ: Scaling issue for picture decision (usually between 1 and 1.5)
ɸ (phi): Compound coefficient (constructive integer) that controls the general scaling issue.
This equation tells us how a lot to scale the mannequin (depth, width, decision) which yields most efficiency.
Advantages of Compound Scaling
- Optimum Useful resource Utilization: By scaling all three dimensions proportionally, EfficientNet avoids the constraints of single-axis scaling (vanishing gradients or saturation).
- Flexibility: The predefined coefficients permit for making a household of EfficientNet fashions (B0, B1, B2, and so forth.) with various capacities. Every mannequin gives a distinct accuracy-efficiency trade-off, making them appropriate for numerous functions.
- Effectivity Features: In comparison with conventional scaling, compound scaling achieves related or higher accuracy with considerably fewer parameters and FLOPs (FLoating-point Operations Per Second), making them superb for resource-constrained units.
Furthermore, the benefit of compound scaling may be visualized utilizing an activation map.
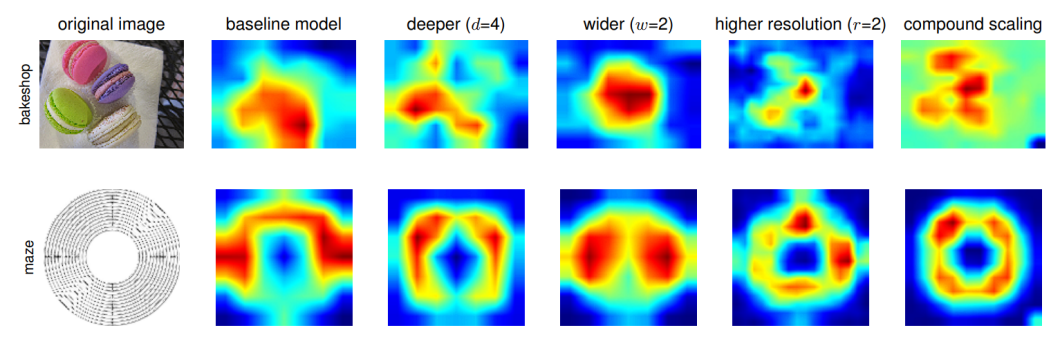
Nonetheless, to develop an environment friendly CNN mannequin that may be scaled, the creator of EfficientNet created a novel baseline community, known as the EfficientNets. This baseline community is then additional scaled in steps to acquire a household of bigger networks (EfficientNet-B0 to EfficientNet-B7).
The EfficientNet Household
EfficientNet consists of 8 fashions, going from EfficientNet-B0 to EfficientNet-B7.
EfficientNet-B0 is the muse upon which your complete EfficientNet household is constructed. It’s the smallest and best mannequin throughout the EfficientNet variants.
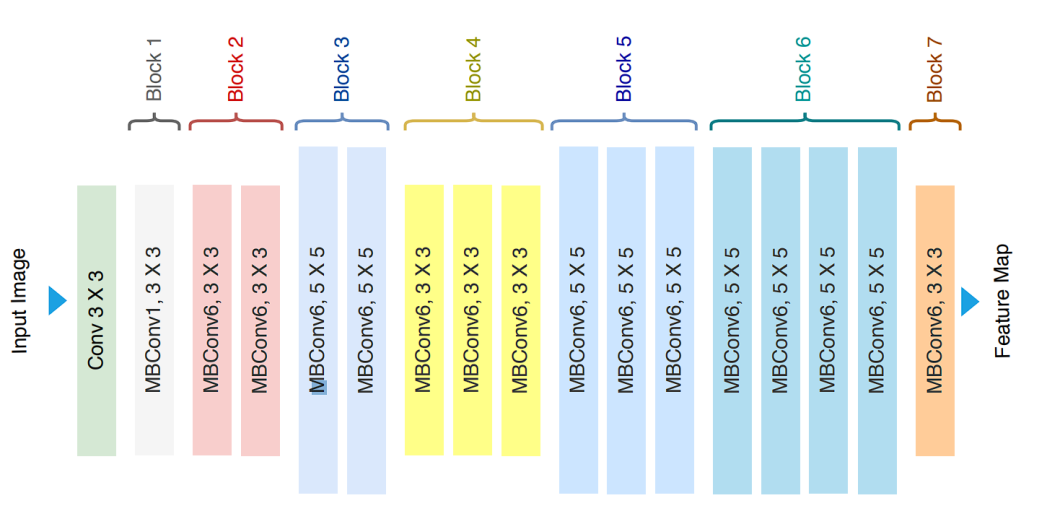
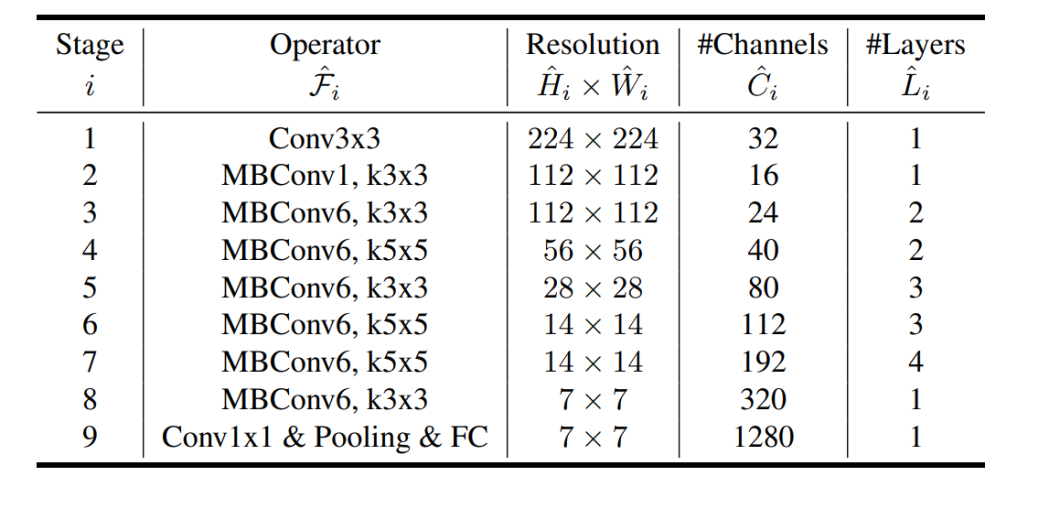
EfficientNet Structure
EfficientNet-B0, found via Neural Architectural Search (NAS) is the baseline mannequin. The principle parts of the structure are:
- MBConv block (Cell Inverted Bottleneck Convolution)
- Squeeze-and-excitation optimization
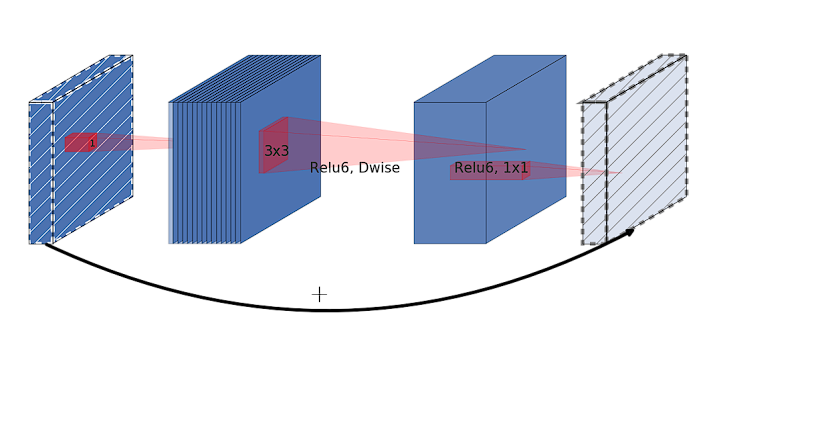
What’s the MBConv Block?
The MBConv block is an advanced inverted residual block impressed by MobileNetv2.
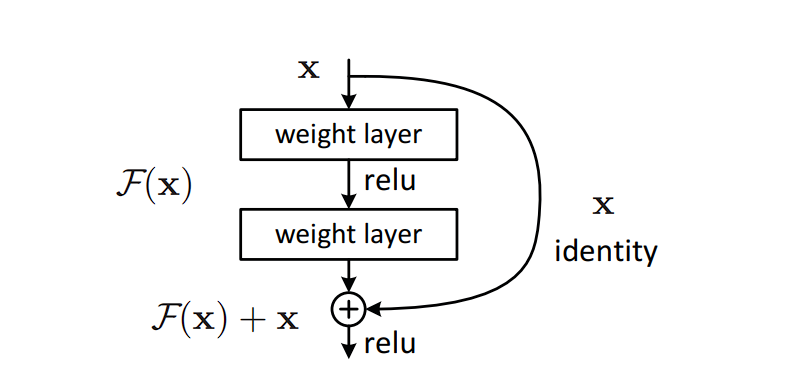
What’s a Residual Community?
Residual networks (ResNets) are a kind of CNN structure that addresses the vanishing gradient downside, because the community will get deeper, the gradient diminishes. ResNets solves this downside and permits for coaching very deep networks. That is achieved by including the unique enter to the output of the transformation utilized by the layer, enhancing gradient circulation via the community.
What’s an inverted residual block?
In residual blocks utilized in ResNets, the primary pathway includes convolutions that cut back the dimensionality of the enter function map. A shortcut or residual connection then provides the unique enter to the output of this convolutional pathway. This course of permits the gradients to circulation via the community extra freely.
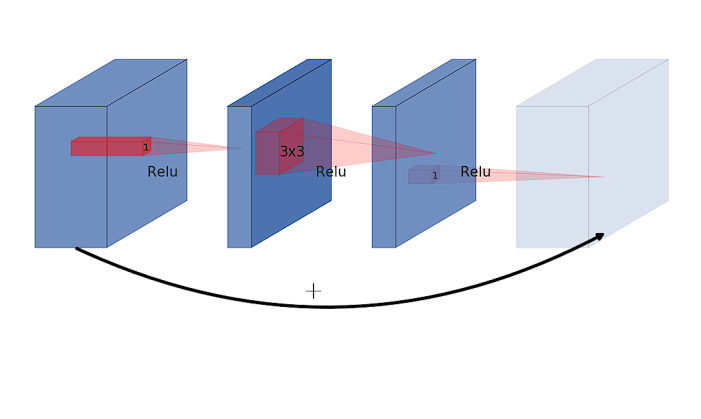
Nonetheless, an inverted residual block begins by increasing the enter function map right into a higher-dimensional house utilizing a 1×1 convolution then applies a depthwise convolution on this expanded house and eventually makes use of one other 1×1 convolution that initiatives the function map again to a lower-dimensional house, the identical because the enter dimension. The “inverted” facet comes from this enlargement of dimensionality in the beginning of the block and discount on the finish, which is reverse to the normal method the place enlargement occurs in direction of the top of the residual block.
What’s Squeeze-and-Excitation?
Squeeze-and-Excitation (SE) merely permits the mannequin to emphasise helpful options, and suppress the much less helpful ones. That is executed in two steps:
- Squeeze: This section aggregates the spatial dimensions (width and peak) of the function maps throughout every channel right into a single worth, utilizing world common pooling. This ends in a compact function descriptor that summarizes the worldwide distribution for every channel, lowering every channel to a single scalar worth.
- Excitation: On this step, the mannequin utilizing a full-connected layer utilized after the squeeze step, produces a group of per channel weight (activations or scores). The ultimate step is to use these discovered significance scores to the unique enter function map, channel-wise, successfully scaling every channel by its corresponding rating.
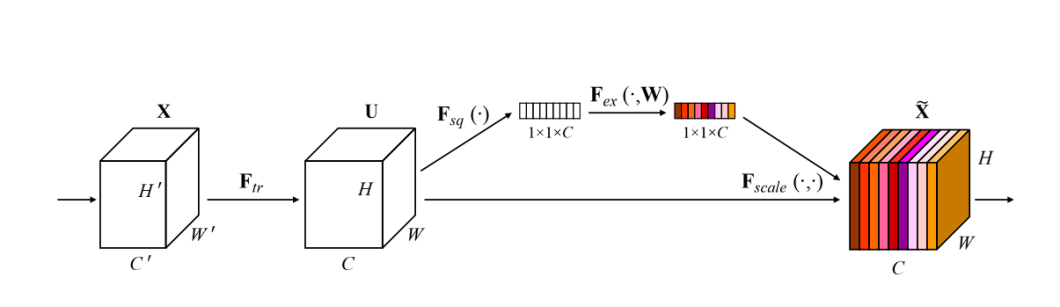
This course of permits the community to emphasise extra related options and diminish much less essential ones, dynamically adjusting the function maps primarily based on the discovered content material of the enter photographs.
Furthermore, EfficientNet additionally incorporates the Swish activation operate as a part of its design to enhance accuracy and effectivity.
What’s the Swish Activation Perform?
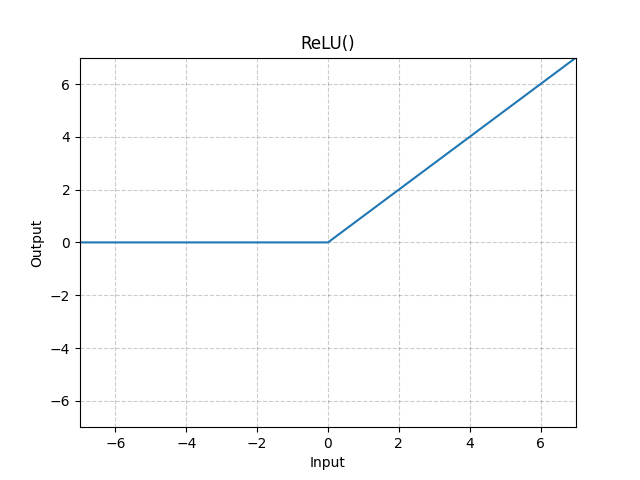
Swish is a clean steady operate, not like Rectified Linear Unit (ReLU) which is a piecewise linear operate. Swish permits a small variety of unfavourable weights to be propagated via, whereas ReLU thresholds all unfavourable weights to zero.
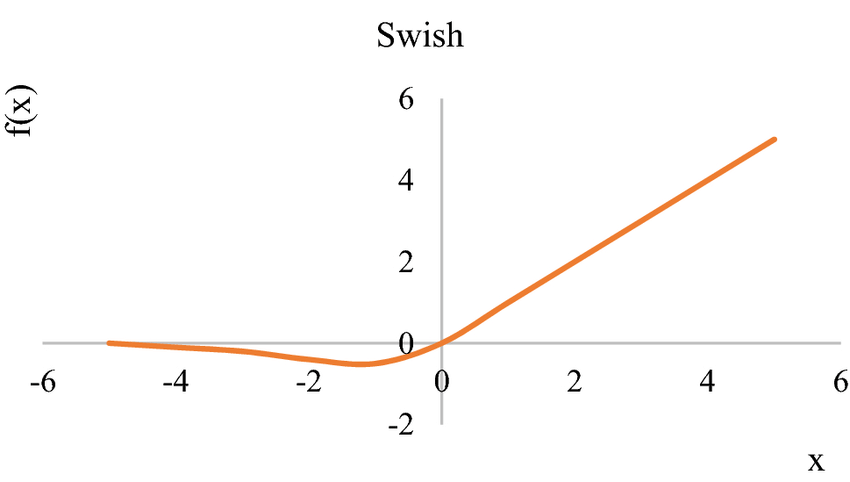
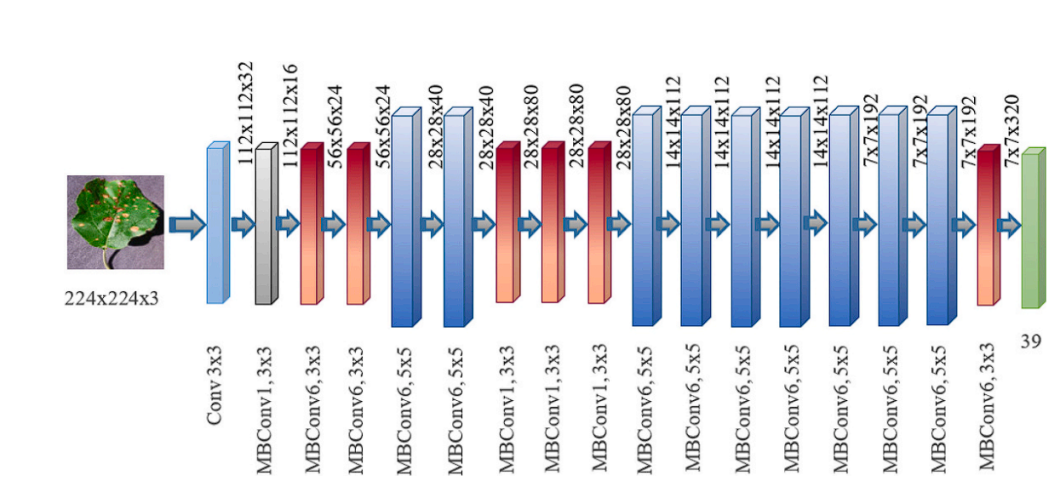
EfficientNet incorporates all of the above components into its structure. Lastly, the structure seems like this:
Efficiency and Benchmarks
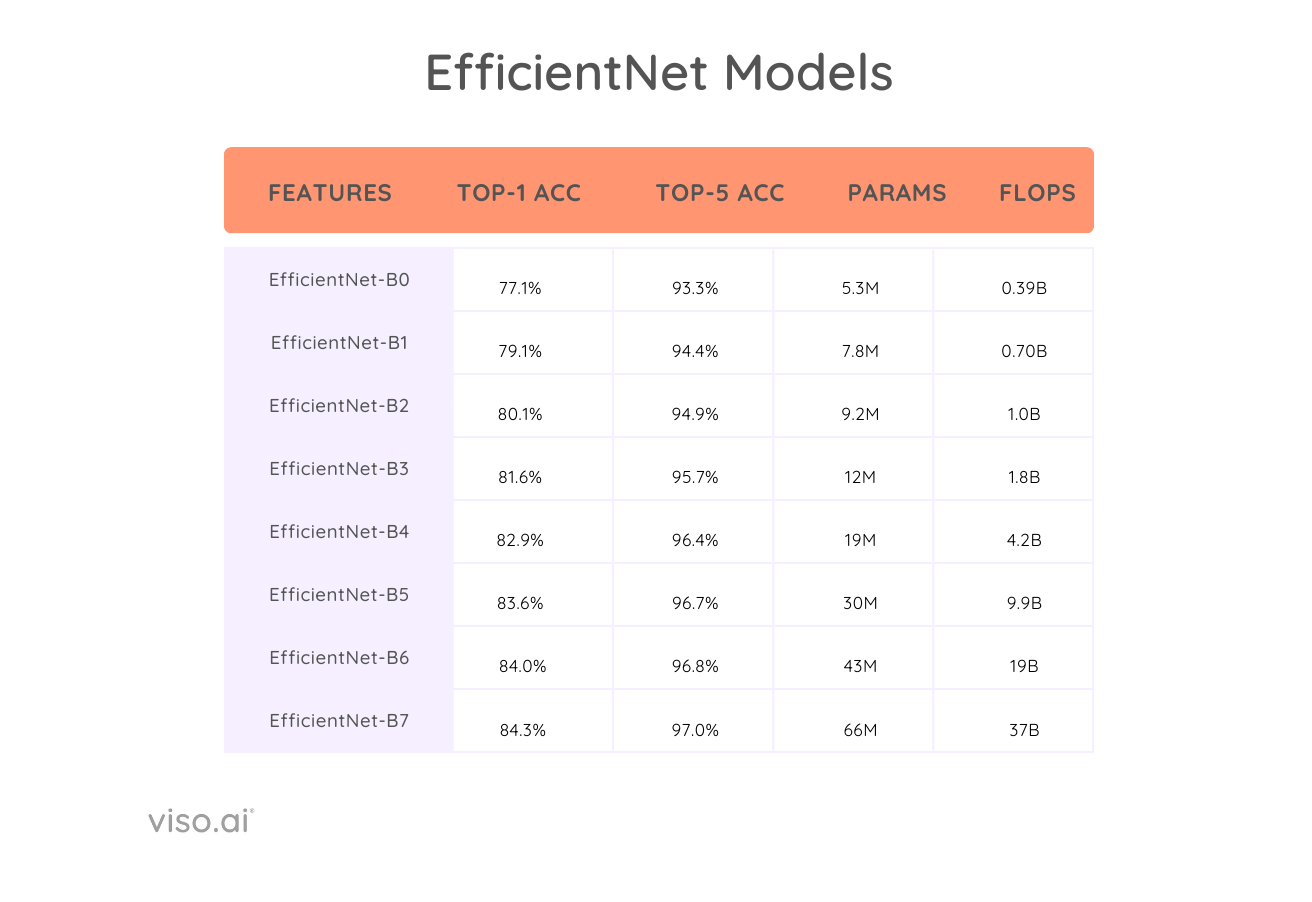
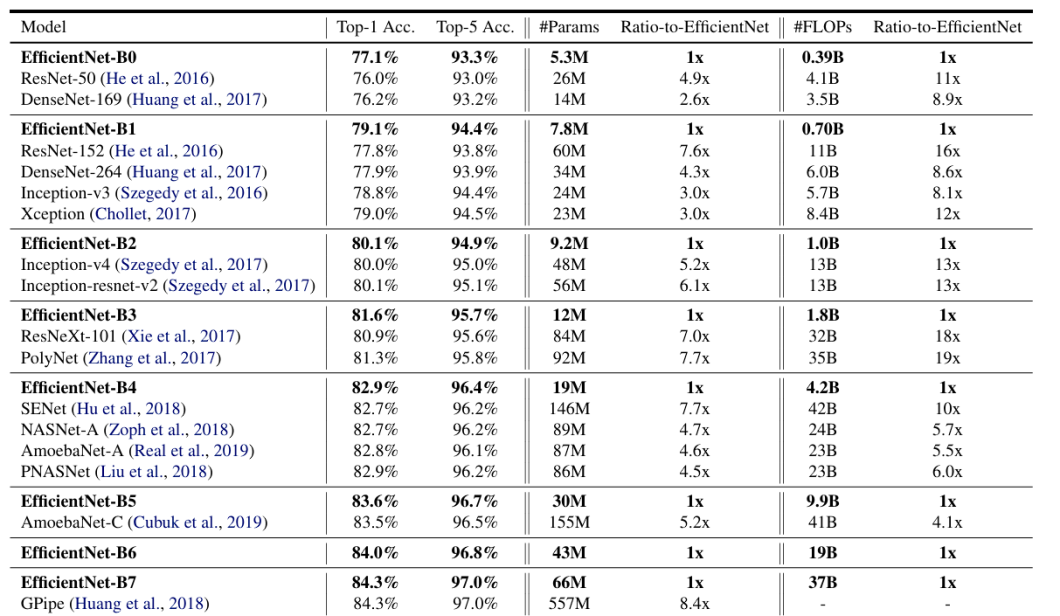
The EfficientNet household, ranging from EfficientNet-B0 to EfficientNet-B7 and past, gives a spread of fashions that scale in complexity and accuracy. Listed below are some key efficiency benchmarks for EfficientNet on the ImageNet dataset, reflecting the stability between effectivity and accuracy.
The benchmarks obtained are carried out on the ImageNet dataset. Listed below are just a few key insights from the benchmark:
- Increased accuracy with fewer parameters: EfficientNet fashions obtain excessive accuracy with fewer parameters and decrease FLOPs than different convolutional neural networks (CNNs). For instance, EfficientNet-B0 achieves 77.1% top-1 accuracy on ImageNet with solely 5.3M parameters, whereas ResNet-50 achieves 76.0% top-1 accuracy with 26M parameters. Moreover, the B-7 mannequin performs at par with Gpipe, however with means fewer parameters ( 66M vs 557M).
- Fewer Computations: EfficientNet fashions can obtain related accuracy to different CNNs with considerably fewer FLOPs. For instance, EfficientNet-B1 achieves 79.1% top-1 accuracy on ImageNet with 0.70 billion FLOPs, whereas Inception-v3 achieves 78.8% top-1 accuracy with 5.7 billion FLOPs.
Because the EfficientNet mannequin measurement will increase (B0 to B7), the accuracy and FLOPs additionally improve. Nonetheless, the rise in accuracy is smaller for the bigger fashions. For instance, EfficientNet-B0 achieves 77.1% top-1 accuracy, whereas EfficientNet-B7 achieves 84.3% top-1 accuracy.
Purposes Of EfficientNet
EfficientNet’s power lies in its potential to realize excessive accuracy whereas sustaining effectivity. This makes it an essential device in eventualities the place computational sources are restricted. Listed below are a few of the use instances for EfficientNet fashions:
- Human Emotion Evaluation on Cell Units: Video-based facial evaluation of the affective habits of people executed utilizing the EfficientNet mannequin on Cell Units, which achieved an F1-score of 0.38. Learn here.

- Well being and Drugs: Use of B0 mannequin for most cancers analysis which obtained an accuracy of 91.18%. Learn here.
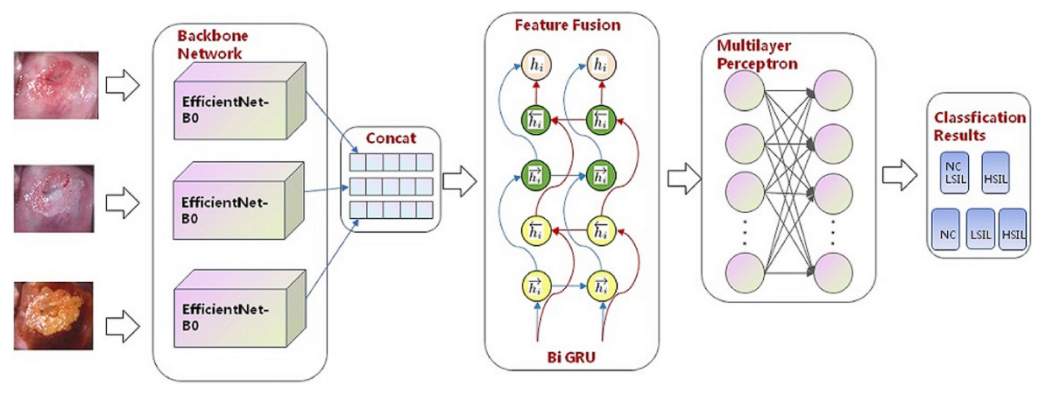
- Plant Leaf illness: Plant leaf illness classification executed utilizing a deep studying mannequin confirmed that the B5 and B4 fashions of EfficientNet structure achieved the very best values in comparison with different deep studying fashions in unique and augmented datasets with 99.91% for accuracy and 99.39% for precision respectively.
- Cell and Edge Computing: EfficientNet’s light-weight structure, particularly the B0 and B1 variants, makes it good for deployment on cellular units and edge computing platforms with restricted computational sources. This permits EfficientNet for use in real-time functions like augmented actuality, enhancing cellular pictures, and performing real-time video evaluation.
- Embedded Programs: EfficientNet fashions can be utilized in resource-constrained embedded techniques for duties like picture recognition in drones or robots. Their effectivity permits for on-board processing with out requiring highly effective {hardware}.
- Sooner Expertise: EfficientNet’s effectivity permits for sooner processing on cellular units, resulting in a smoother consumer expertise in functions like picture recognition or augmented actuality, furthermore with decreased battery consumption.