

Convolution Neural Networks (CNNs) are highly effective instruments that may course of any information that appears like a picture (matrices) and discover necessary info from it, nevertheless, in customary CNNs, each channel is given the identical significance. That is what Squeeze and Excite Community improves, it dynamically provides significance to sure channels solely (an consideration mechanism for channel correlation).
Commonplace CNNs summary and extract options of a picture with preliminary layers studying about edges and texture and last layers extracting shapes of objects, carried out by convolving learnable filters or kernels, nevertheless not all convolution filters are equally necessary for any given process, and consequently, a variety of computation and efficiency is misplaced as a consequence of this.
For instance, in a picture containing a cat, some channels may seize particulars like fur texture, whereas others may give attention to the general form of the cat, which will be much like different animals. Hypothetically, to carry out higher, the community might reap higher outcomes if it prioritizes channels containing fur texture.
On this weblog, we’ll look in-depth at how Squeeze and Excitation blocks enable dynamic weighting of channel significance and create adaptive correlations between them. For conciseness, we’ll confer with Squeeze and Excite Networks as “SE
Introduction to Squeeze and Excite Networks
Squeeze and Excite Community are particular blocks that may be added to any preexisting deep studying structure akin to VGG-16 or ResNet-50. When added to a Community, SE Community dynamically adapts and recalibrates the significance of a channel.
Within the authentic analysis paper printed, the authors present {that a} ResNet-50 when mixed with SENet (3.87 GFLOPs) achieves accuracy that’s equal to what the unique ResNet-101 (7.60GFLOPs) achieves. This implies half of the computation is required with the SENet built-in mannequin, which is sort of spectacular.
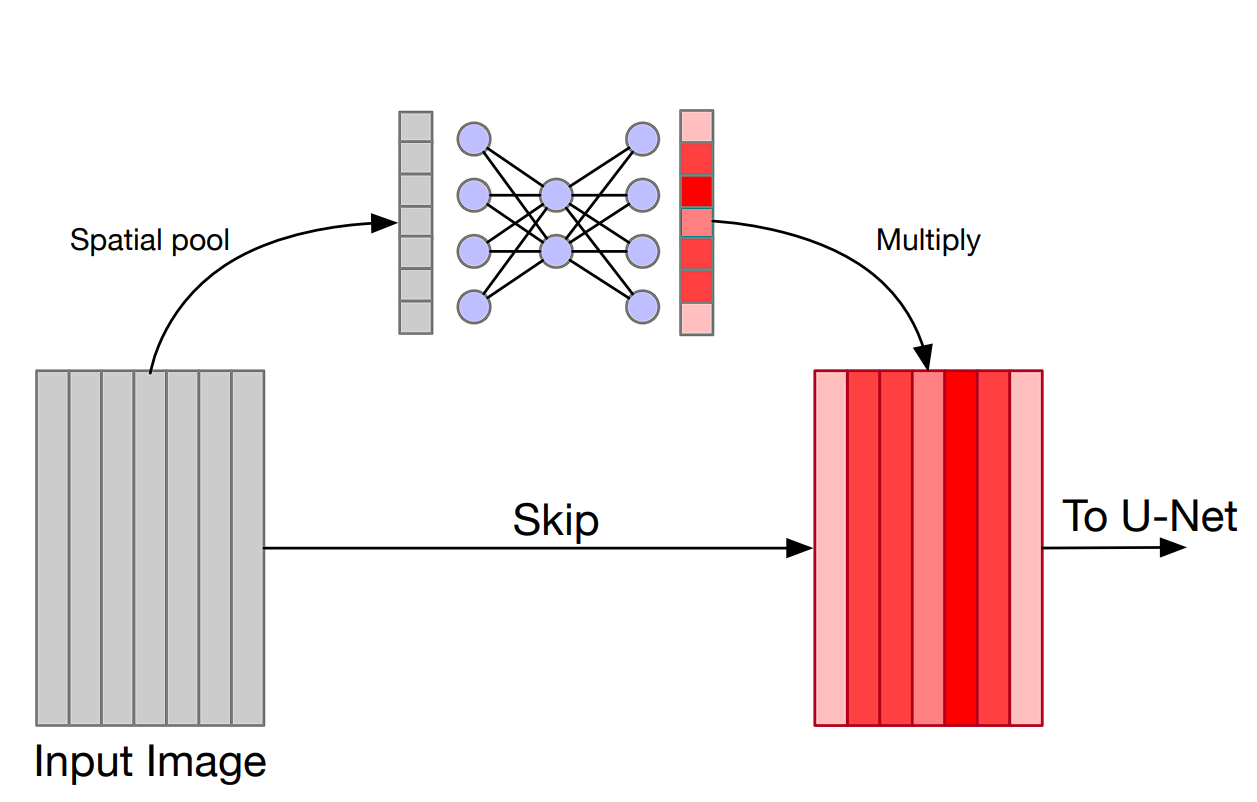
SE Community will be divided into three steps, squeeze, excite, and scale, right here is how they work:
- Squeeze: This primary step within the community captures the worldwide info from every channel. It makes use of international common pooling to squeeze every channel of the function map right into a single numeric worth. This worth represents the exercise of that channel.
- Excite: The second step is a small absolutely related neural community that analyzes the significance of every channel primarily based on the knowledge captured within the earlier step. The output of the excitation step is a set of weights for every channel that tells what channel is necessary.
- Scale: On the finish, the weights are multiplied with the unique channels or function map, scaling every channel based on its significance. Channels that show to be necessary for the community are amplified, whereas the not necessary channel is suppressed and given much less significance.
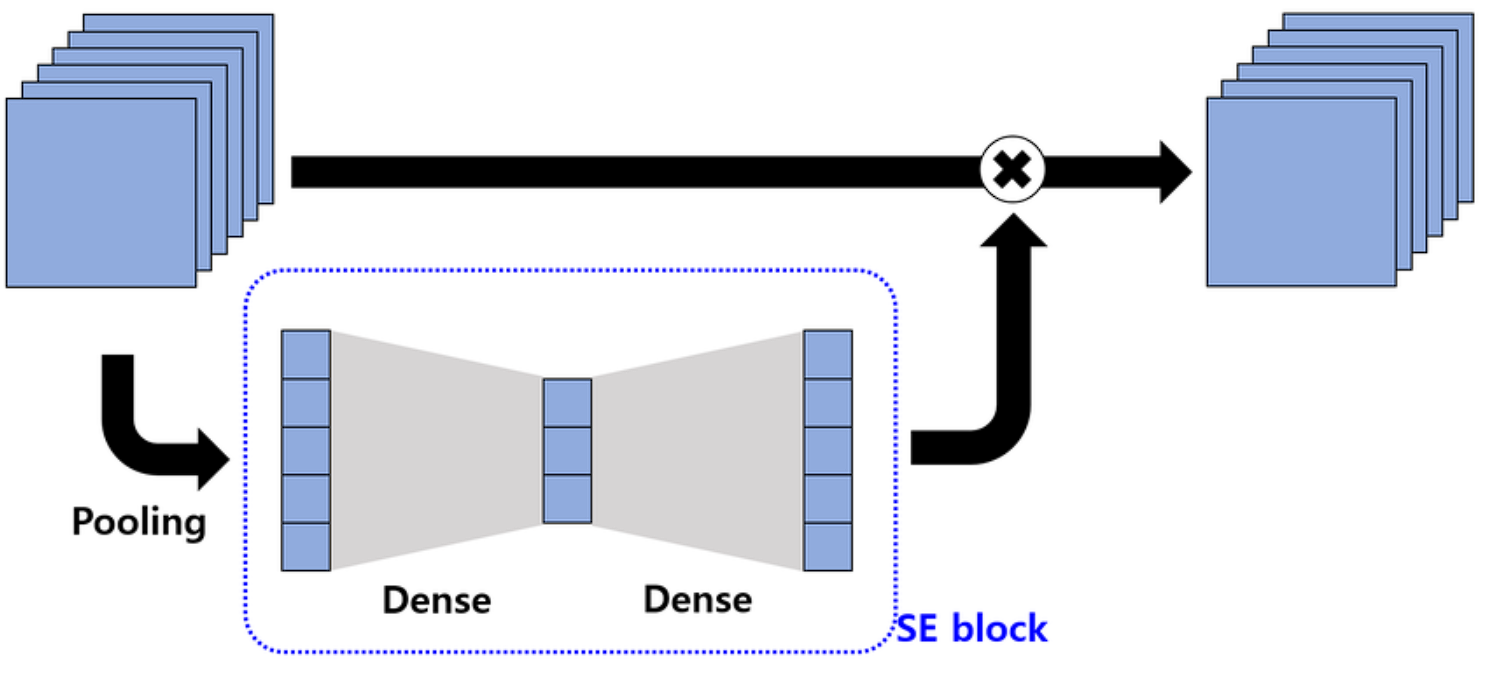
General, that is an summary of how the SE community works. Now let’s deeper into the technical particulars.
How does SENet Work?
Squeeze Operation
The Squeeze operation condenses the knowledge from every channel right into a single vector utilizing international common pooling.
The worldwide common pooling (GAP) layer is a vital step within the means of SENet, customary pooling layers (akin to max pooling) present in CNNs scale back the dimensionality of the enter whereas retaining essentially the most outstanding options, in distinction, GAP reduces every channel of the function map to a single worth by taking the typical of all parts in that channel.
How GAP Aggregates Function Maps
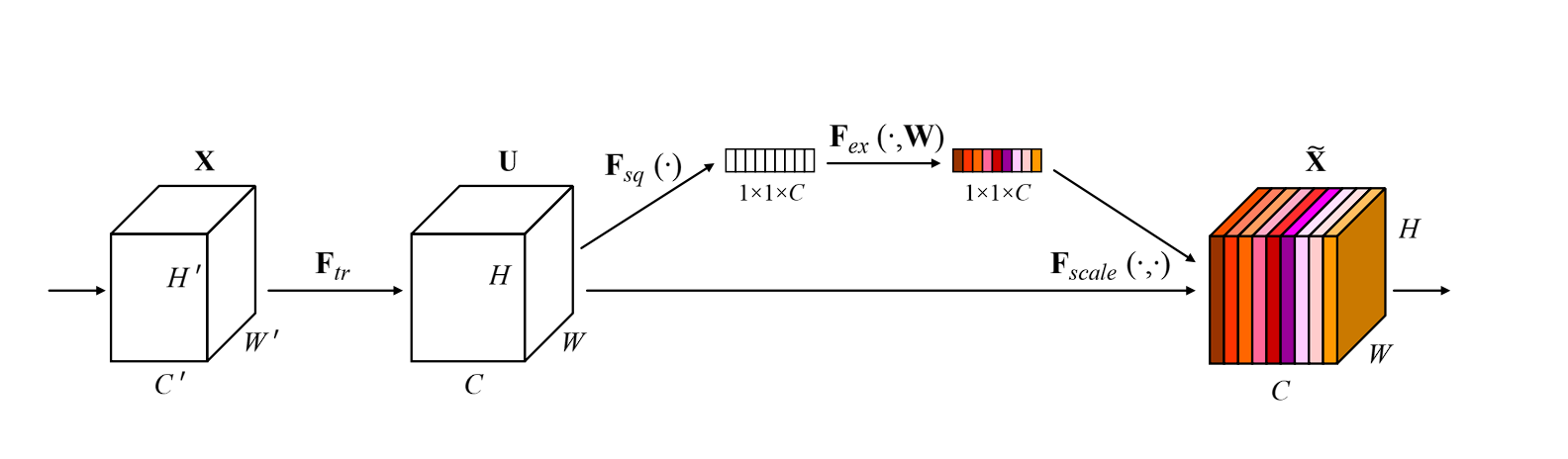
- Function Map Enter: Suppose we’ve a function map F from a convolutional layer with dimensions H×W×C, the place H is the peak, W is the width, and C is the variety of channels.
- International Common Pooling: The GAP layer processes every channel independently. For every channel c within the function map F, GAP computes the typical of all parts in that channel. Mathematically, this may be represented as:
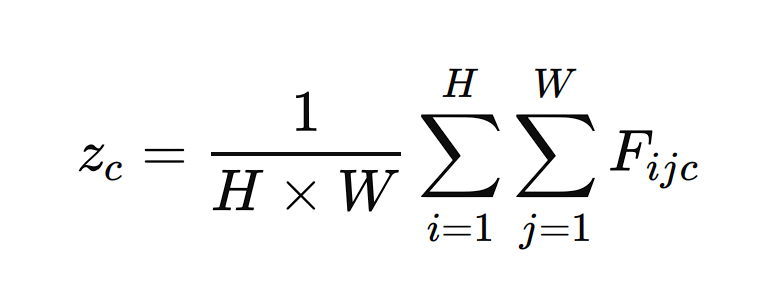
Right here, zc is the output of the GAP layer for channel c, and Fijc is the worth of the function map at place (I,j) for channel c.
Output Vector: The results of the GAP layer is a vector z with a size equal to the variety of channels C. This vector captures the worldwide spatial info of every channel by summarizing its contents with a single worth.
Instance: If a function map has dimensions 7×7×512, the GAP layer will remodel it right into a 1×1×512 vector by averaging the values in every 7×7 grid for all 512 channels.
Excite Operation
As soon as the worldwide common pooling is finished on channels, leading to a single vector for every channel. The following step the SE community performs is excitation.
On this, utilizing a totally related Neural Community, channel dependencies are obtained. That is the place the necessary and fewer necessary channels are distinguished. Right here is how it’s carried out:
Enter vector z is the output vector from GAP.
The 2 absolutely related neural community layers scale back the dimensionality of the enter vector to a smaller measurement C/r, the place r is the discount ratio (a hyperparameter that may be adjusted). This dimensionality discount step helps in capturing the channel dependencies.
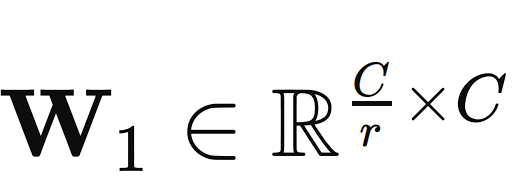
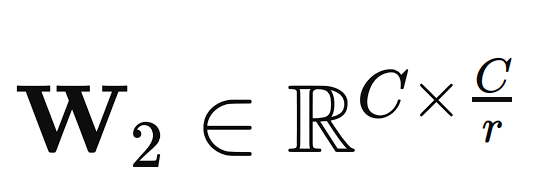
The primary layer is a ReLU (Rectified Linear Unit) activation operate that’s utilized to the output of the primary FC layer to introduce non-linearity
s= ReLU(s)
The second layer is one other absolutely related layer
Lastly, the Sigmoid activation operate is utilized to scale and smoothen out the weights based on their significance. Sigmoid activation outputs a worth between 0 and 1.
w=σ(w)
Scale Operation
The Scale operation makes use of the output from the Excitation step to rescale the unique function maps. First, the output from the sigmoid is reshaped to match the variety of channels, broadcasting w throughout dimensions H and W.
The ultimate step is the recalibration of the channels. That is accomplished by element-wise multiplication. Every channel is multiplied by the corresponding weight.
Fijk=wokay⋅Fijk
Right here, Fijk is the worth of the unique function map at place (i,j) in channel okay, and is the burden for channel okay. The output of this operate is the recalibrated function map worth.
The Excite operation in SENet leverages absolutely related layers and activation features to seize and mannequin channel dependencies that generate a set of significance weights for every channel.
The Scale operation then makes use of these weights to recalibrate the unique function maps, enhancing the community’s representational energy and bettering efficiency on varied duties.
Integration with Current Networks
Squeeze and Excite Networks (SENets) are simply adaptable and will be simply built-in into current convolutional neural community (CNN) architectures, because the SE blocks function independently of the convolution operation in no matter structure you’re utilizing.
Furthermore, speaking about efficiency and computation, the SE block introduces negligible added computational price and parameters, as we’ve seen that it’s simply a few absolutely related layers and easy operations akin to GAP and element-wise multiplication.
These processes are low-cost when it comes to computation. Nonetheless, the advantages in accuracy they supply are nice.
Some fashions the place SE Nets have been built-in into
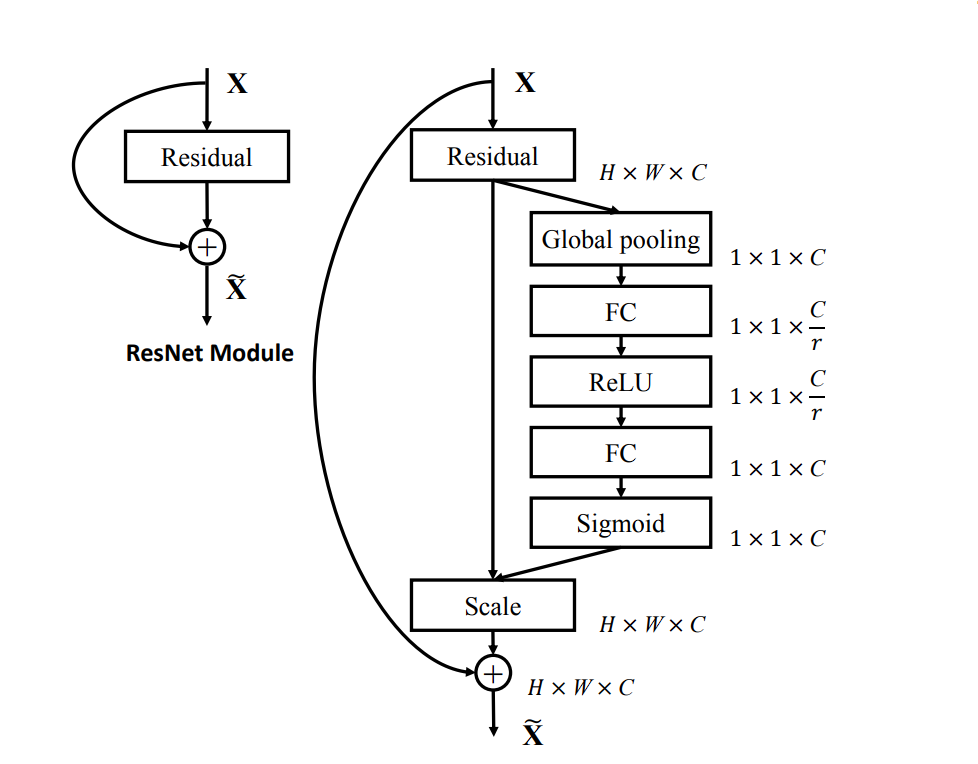
SE-ResNet: In ResNet, SE blocks are added to the residual blocks of ResNet. After every residual block, the SE block recalibrates the output function maps. The results of including SE blocks is seen with the rise within the efficiency on picture classification duties.
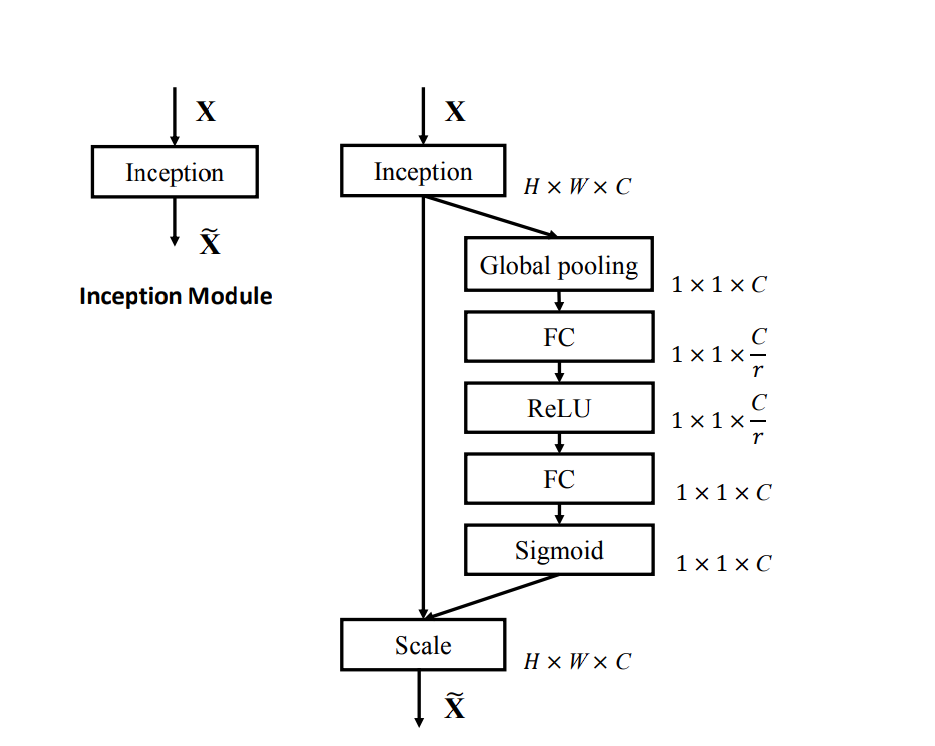
SE-Inception: In SE-Inception, SE blocks are built-in into the Inception modules. The SE block recalibrates the function maps from the totally different convolutional paths inside every Inception module.
SE-MobileNet: In SE-MobileNet, SE blocks are added to the depthwise separable convolutions in MobileNet. The SE block recalibrates the output of the depthwise convolution earlier than passing it to the pointwise convolution.
SE-VGG: In SE-VGG, SE blocks are inserted after every group of convolutional layers. That’s, an SE block is added after every pair of convolutional layers adopted by a pooling layer.
Benchmarks and Testing

Cell Internet
- The unique MobileNet has a top-1 error of 29.4%. After re-implementation, this error is decreased to twenty-eight.4%. Nonetheless, once we couple it with SENet, the top-1 error drastically reduces to 25.3%, exhibiting a big enchancment.
- The highest-5 error is 9.4% for the re-implemented MobileNet, which improves to 7.7% with SENet.
- Nonetheless, utilizing the SENet will increase the computation price from 569 to 572 MFLOPs with SENet, which is sort of good for the accuracy enchancment achieved.
ShuffleNet
- The unique ShuffleNet has a top-1 error of 32.6%. The re-implemented model maintains the identical top-1 error. When enhanced with SENet, the top-1 error reduces to 31.0%, exhibiting an enchancment.
- The highest-5 error is 12.5% for the re-implemented ShuffleNet, which improves to 11.1% with SENet.
- The computational price will increase barely from 140 to 142 MFLOPs with SENet.
In each MobileNet and ShuffleNet fashions, the addition of the SENet block considerably improves the top-1 and top-5 errors.
Advantages of SENet
Squeeze and Excite Networks (SENet) provide a number of benefits. Listed below are among the advantages we will see with SENet:
Improved Efficiency
SENet improves the accuracy of picture classification duties by specializing in the channels that contribute essentially the most to the detection process. This is rather like including an consideration mechanism to channels (SE blocks present perception into the significance of various channels by assigning weights to them). This leads to elevated illustration by the community, as the higher layers are targeted extra and additional improved.
Negligible computation overhead
The SE blocks introduce a really small variety of further parameters compared to scaling a mannequin. That is attainable as a result of SENet makes use of International common pooling that summarizes the mannequin channel-wise and is a few easy operations.
Straightforward Integration with current fashions
SE blocks seamlessly combine into current CNN architectures, akin to ResNet, Inception, MobileNet, VGG, and DenseNet.
Furthermore, these blocks will be utilized as many instances as desired:
- In varied elements of the community
- From the sooner layers to the ultimate layers of the community
- Adapting to steady various duties carried out all through the deep studying mannequin you combine SE into
Strong Mannequin
Lastly, SENet makes the mannequin tolerant in direction of noise, as a result of it downgrades the channels that is perhaps contributing negatively to the mannequin efficiency. Thus, making the mannequin finally generalize on the given process higher.
What’s Subsequent with Squeeze and Excite Networks
On this weblog, we regarded on the structure and advantages of Squeeze and Excite Networks (SENet), which function an added enhance to the already developed mannequin. That is attainable as a result of idea of “squeeze” and “excite” operations which makes the mannequin give attention to the significance of various channels in function maps, that is totally different from customary CNNs which use fastened weights throughout all channels and provides equal significance to all of the channels.
We then regarded in-depth into the squeeze, excite, and scale operation. The place the SE block first performs a world common pooling layer, that compresses every channel right into a single worth. Then the absolutely related layers and activation features mannequin the connection between channels. Lastly, the dimensions operation rescales the significance of every channel by multiplying the output weight from the excitation step.
Moreover, we additionally checked out how SENet will be built-in into current networks akin to ResNet, Inception, MobileNet, VGG, and DenseNet with minimally elevated computations.
General, the SE block leads to improved efficiency, robustness, and generalizability of the present mannequin.