

In lots of Synthetic Intelligence (AI) functions equivalent to Pure Language Processing (NLP) and Pc Imaginative and prescient (CV), there’s a want for a unified pre-training framework (e.g. Florence-2) that may operate autonomously. The present datasets for specialised functions nonetheless want human labeling, which limits the event of foundational fashions for complicated CV-related duties.
Microsoft researchers created the Florence-2 mannequin (2023) that’s able to dealing with many pc imaginative and prescient duties. It efficiently solves the shortage of a unified mannequin structure and weak coaching information.
About us: Viso.ai gives the end-to-end Pc Imaginative and prescient Infrastructure, Viso Suite. It’s a robust all-in-one answer for AI imaginative and prescient. Corporations worldwide use it to develop and ship real-world functions dramatically quicker. Get a demo in your firm.
Historical past of Florence-2 mannequin
In a nutshell, basis fashions are fashions which are pre-trained on some common duties (usually in self-supervised mode). In any other case, it’s not possible to seek out a number of labeled information for totally supervised studying. They are often simply tailored to numerous new duties (with or with out fine-tuning/extra coaching), inside context studying.
Researchers launched the time period ‘basis’ as a result of they’re the foundations for a lot of different issues/challenges. There are benefits to this course of (it’s straightforward to construct one thing new) and drawbacks (many will endure from a foul basis).
These fashions usually are not elementary for AI since they don’t seem to be a foundation for understanding or constructing intelligence or consciousness. To use basis fashions in CV duties, Microsoft researchers divided the vary of duties into three teams:
- House (scene classification, object detection)
- Time (statics, dynamics)
- Modality (RGB, depth).
Then they outlined the muse mannequin for CV as a pre-trained mannequin and adapters for fixing all issues on this House-Time-Modality with the power to switch the zero studying kind.
They offered their work as a brand new paradigm for constructing a imaginative and prescient basis mannequin and referred to as it Florence-2 (the birthplace of the Renaissance). They think about it an ecosystem of 4 massive areas:
- Knowledge gathering
- Mannequin pre-training
- Activity diversifications
- Coaching infrastructure
What’s the Florence-2 mannequin?
Xiao et al. (Microsoft, 2023) developed the Florence-2 according to NLP goals of versatile mannequin growth with a standard base. Florence-2 combines a multi-sequence studying paradigm and customary imaginative and prescient language modeling for a wide range of CV duties.
Florence-2 redefines efficiency requirements with its distinctive zero-shot and fine-tuning capabilities. It performs duties like captioning, expression interpretation, visible grounding, and object detection. Moreover, Florence-2 surpasses present specialised fashions and units new benchmarks utilizing publicly out there human-annotated information.
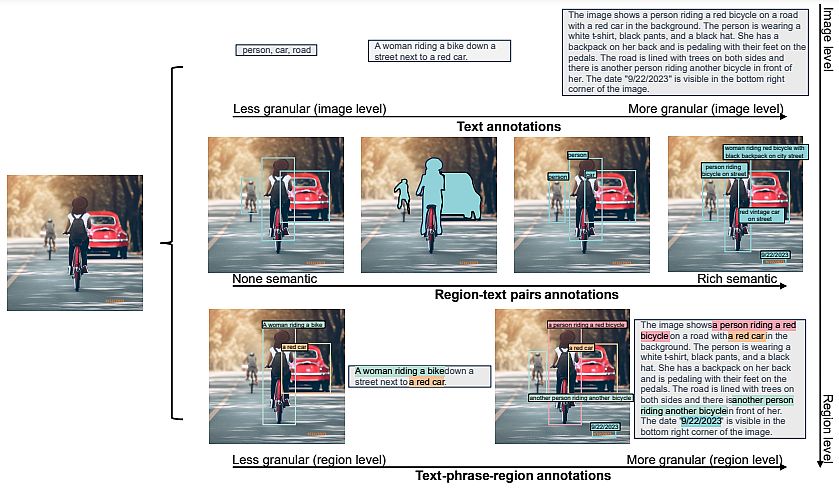
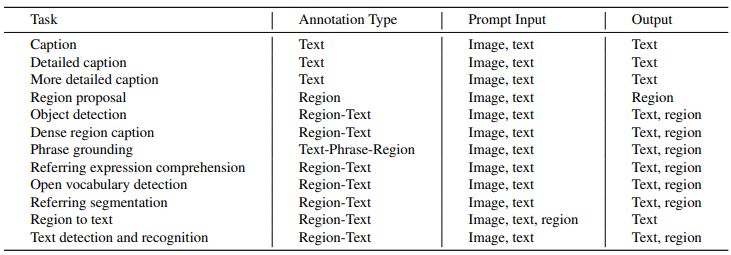
Florence-2 makes use of a multi-sequence structure to unravel varied pc imaginative and prescient duties. Each process is dealt with as a transiting downside, through which the mannequin creates the suitable output reply given an enter picture and a task-specific immediate.
Duties can include geographical or textual content information, and the mannequin adjusts its processing in response to the duty’s necessities. Researchers included location tokens within the tokenizer’s vocabulary listing for duties particular to a given area. These tokens present a number of codecs, together with field, quad, and polygon illustration.

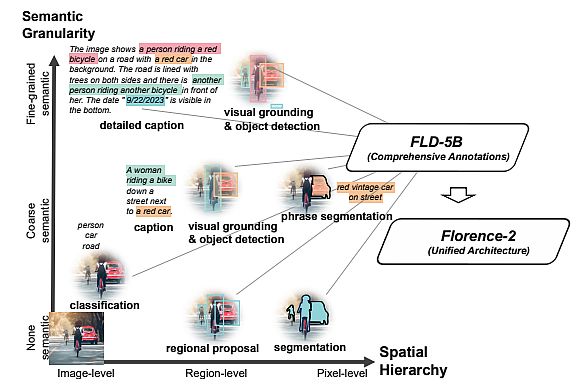
- Understanding photos, and language descriptions that seize high-level semantics and facilitate an intensive comprehension of visuals. Exemplar duties embrace picture classification, captioning, and visible query answering.
- Area recognition duties, enabling object recognition and entity localization inside photos. They seize relationships between objects and their spatial context. As an example, object detection, occasion segmentation, and referring expression are such duties.
- Granular visual-semantic duties require a granular understanding of each textual content and picture. They contain finding the picture areas that correspond to the textual content phrases, equivalent to objects, attributes, or relations.
Florence-2 Structure and Knowledge Engine
Being a common illustration mannequin, Florence-2 can clear up completely different CV duties with a single set of weights and a unified illustration structure. Because the determine under reveals, Florence-2 applies a multi-sequence studying algorithm, unifying all duties beneath a standard CV modeling aim.
The one mannequin takes photos coupled with process prompts as directions and generates the fascinating labels in textual content varieties. It makes use of a imaginative and prescient encoder to transform photos into visible token data. To generate the response, the tokens are paired with textual content data and processed by a transformer-based en/de-coder.
Microsoft researchers formulated every process as a translation downside: given an enter picture and a task-specific immediate, they created the right output response. Relying on the duty, the immediate and response may be both textual content or area.
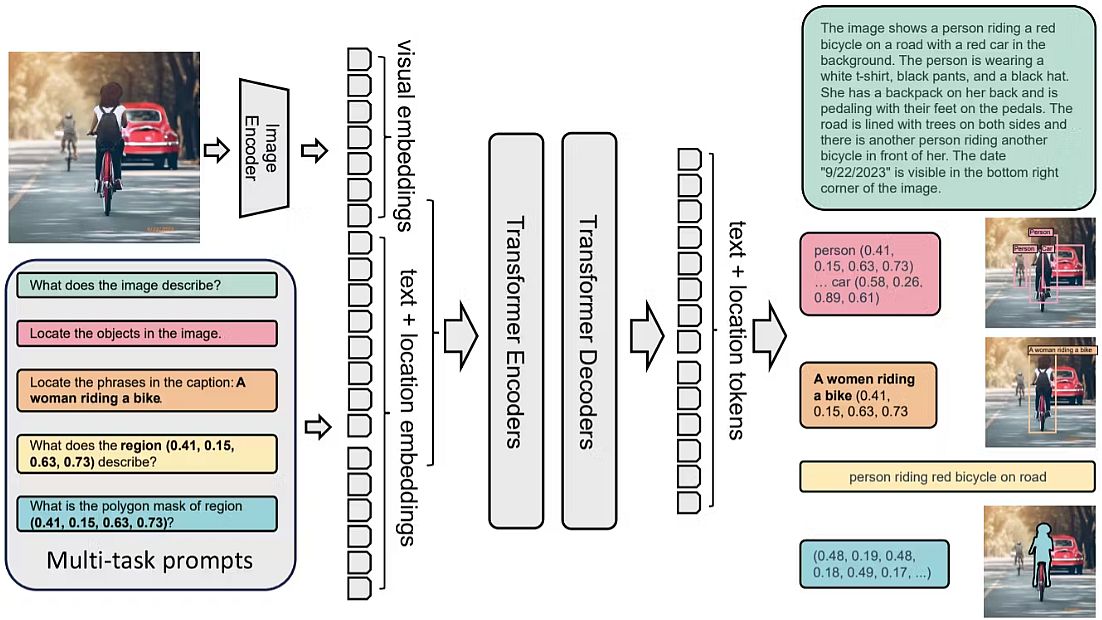
- Textual content: When the immediate or reply is apparent textual content with out particular formatting, they maintained it of their closing multi-sequence format.
- Area: For region-specific duties, they added location tokens to the token’s vocabulary listing, representing numerical coordinates. They created 1000 bins and represented areas utilizing codecs appropriate for the duty necessities.
Knowledge Engine in Florence-2
To coach their Florence-2 structure, researchers utilized a unified, large-volume, multitask dataset containing completely different picture information facets. Due to the shortage of such information, they’ve developed a brand new multitask picture dataset.
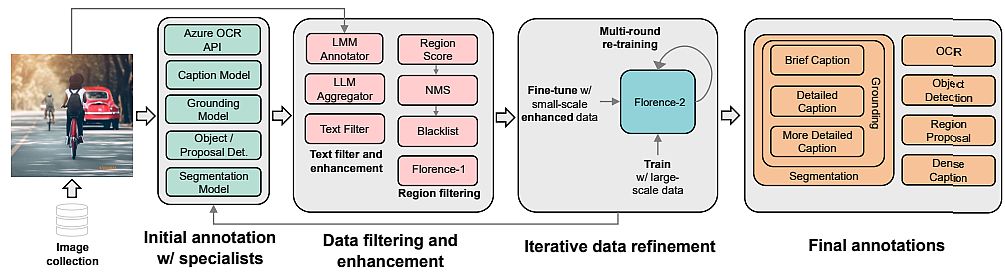
Technical Challenges within the Mannequin Improvement
There are difficulties with picture descriptions as a result of completely different photos find yourself beneath one description, and in FLD-900M for 350 M descriptions, there may be multiple picture.
This impacts the extent of the coaching process. In normal descriptive studying, it’s assumed that every image-text pair has a novel description, and all different descriptions are thought-about unfavourable examples.
The researchers used unified image-text contrastive studying (UniCL, 2022). This Contrastive Studying is unified within the sense that in a standard image-description-label area it combines two studying paradigms:
- Discriminative (mapping a picture to a label, supervised studying) and
- Pre-training in an image-text (mapping an outline to a novel label, contrastive studying).
The structure has a picture encoder and a textual content encoder. The characteristic vectors from the encoders’ outputs are normalized and fed right into a bidirectional goal operate. Moreover, one element is accountable for supervised image-to-text contrastive loss, and the second is in the other way for supervised text-to-image contrastive loss.
The fashions themselves are a regular 12-layer textual content transformer for textual content (256 M parameters) and a hierarchical Imaginative and prescient Transformer for photos. It’s a particular modification of the Swin Transformer with convolutional embeddings like CvT, (635 M parameters).
In whole, the mannequin has 893 M parameters. They educated for 10 days on 512 machines A100-40Gb. After pre-training, they educated Florence-2 with a number of varieties of adapters.
Experiments and Outcomes
Researchers educated Florence-2 on finer-grained representations by detection. To do that, they added the dynamic head adapter, which is a specialised consideration mechanism for the top that does detection. They did recognition with the tensor options, by stage, place, and channel.
They educated on the FLOD-9M dataset (Florence Object detection Dataset), into which a number of present ones have been merged, together with COCO, LVIS, and OpenImages. Furthermore, they generated pseudo-bounding bins. In whole, there have been 8.9M photos, 25190 object classes, and 33.4M bounding bins.
This was educated on image-text matching (ITM) loss and the traditional Roberto MLM loss. Then in addition they fine-tuned it for the VQA process and one other adapter for video recognition, the place they took the CoSwin picture encoder and changed 2D layers with 3D ones, convolutions, merge operators, and so forth.
Throughout initialization, they duplicated the pre-trained weights from 2D into new ones. There was some extra coaching right here the place fine-tuning for the duty was instantly accomplished.
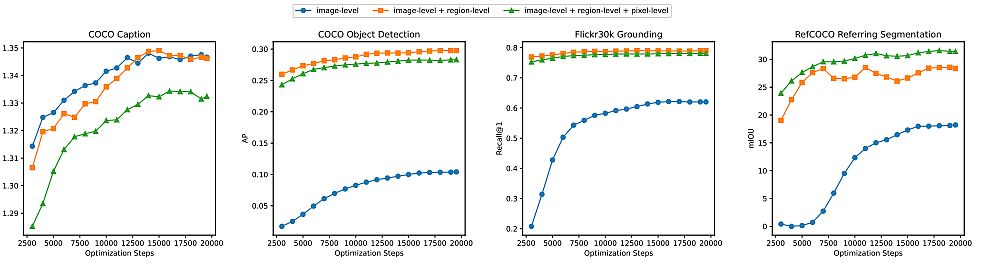
In fine-tuning Florence-2 beneath ImageNet, it’s barely worse than SoTA, but in addition thrice smaller. For a number of photographs of cross-domain classification, it beat the benchmark chief, though the latter used ensemble and different tips.
For image-text retrieval in zero-shot, it matches or surpasses earlier outcomes, and in fine-tuning, it beats with a considerably smaller variety of epochs. It beats in object detection, VQA, and video motion recognition too.
Functions of Florence-2 in Varied Industries
Mixed text-region-image annotation may be useful in a number of industries and right here we enlist its attainable functions:
Medical Imaging
Medical practitioners use imaging with MRI, X-rays, and CT scans to detect anatomical options and anomalies. Then they apply text-image annotation to categorise and annotate medical photos. This aids within the extra exact and efficient prognosis and therapy of sufferers.
Florence-2 with its text-image annotation can acknowledge patterns and find fractures, tumors, abscesses, and a wide range of different situations. Mixed annotation has the potential to scale back affected person wait occasions, unlock expensive scanner slots, and improve the accuracy of diagnoses.
Transport
Textual content-image annotation is essential within the growth of site visitors and transport programs. With the assistance of Florence-2 annotation, autonomous vehicles can acknowledge and interpret their environment, enabling them to make appropriate selections.

Annotation helps to tell apart several types of roads, equivalent to metropolis streets and highways, and to establish gadgets (pedestrians, site visitors alerts, and different vehicles). Figuring out object borders, areas, and orientations, in addition to tagging automobiles, individuals, site visitors indicators, and highway markings, are essential duties.
Agriculture
Precision agriculture is a comparatively new discipline that mixes conventional farming strategies with know-how to extend manufacturing, profitability, and sustainability. It makes use of robotics, drones, GPS sensors, and autonomous automobiles to hurry up fully handbook farming operations.
Textual content-image annotation is utilized in many duties, together with enhancing soil situations, forecasting agricultural yields, and assessing plant well being. Florence-2 can play a big position in these processes by enabling CV algorithms to acknowledge specific indicators like human farmers.
Safety and Surveillance
Textual content-image annotation makes use of 2D/3D bounding bins to establish people or objects from the group. Florence-2 exactly labels the individuals or gadgets by drawing a field round them. By observing human behaviors and placing them in distinct boundary bins, it will possibly detect crimes.

The cameras along with labeled prepare datasets are able to recognizing faces. Cameras establish individuals along with car varieties, colours, weapons, instruments, and different equipment, which Florence-2 will annotate.
What’s subsequent for Florence-2?
Florence-2 units the stage for the event of pc imaginative and prescient fashions sooner or later. It reveals an unlimited potential for multitask studying and the mixing of textual and visible data, making it an modern CV mannequin. Due to this fact, it gives a productive answer for a variety of functions with out requiring a number of fine-tuning.
The mannequin is able to dealing with duties starting from granular semantic changes to picture understanding. By showcasing the effectivity of a number of sequence studying, Florence-2’s structure raises the usual for full illustration studying.
Florence-2’s performances present alternatives for researchers to go farther into the fields of multi-task studying and cross-modal recognition as we observe the quickly altering AI panorama.
Examine different CV fashions right here: