

YOLO (You Solely Look As soon as) is a household of object detection fashions fashionable for his or her real-time processing capabilities, delivering excessive accuracy and pace on cellular and edge gadgets. Launched in 2020, YOLOv4 enhances the efficiency of its predecessor, YOLOv3, by bridging the hole between accuracy and pace.
Whereas lots of the most correct object detection fashions require a number of GPUs working in parallel, YOLOv4 may be operated on a single GPU with 8GB of VRAM, such because the GTX 1080 Ti, which makes widespread use of the mannequin potential.
On this weblog, we’ll look deeper into the structure of YOLOv4 what adjustments had been made that made it potential to be run in a single GPU, and eventually have a look at a few of its real-life functions.
The YOLO Household of Fashions
The primary YOLO mannequin was launched again in 2016 by a group of researchers, marking a big development in object detection know-how. In contrast to the two-stage fashions fashionable on the time, which had been gradual and resource-intensive, YOLO launched a one-stage strategy to object detection.
YOLOv1
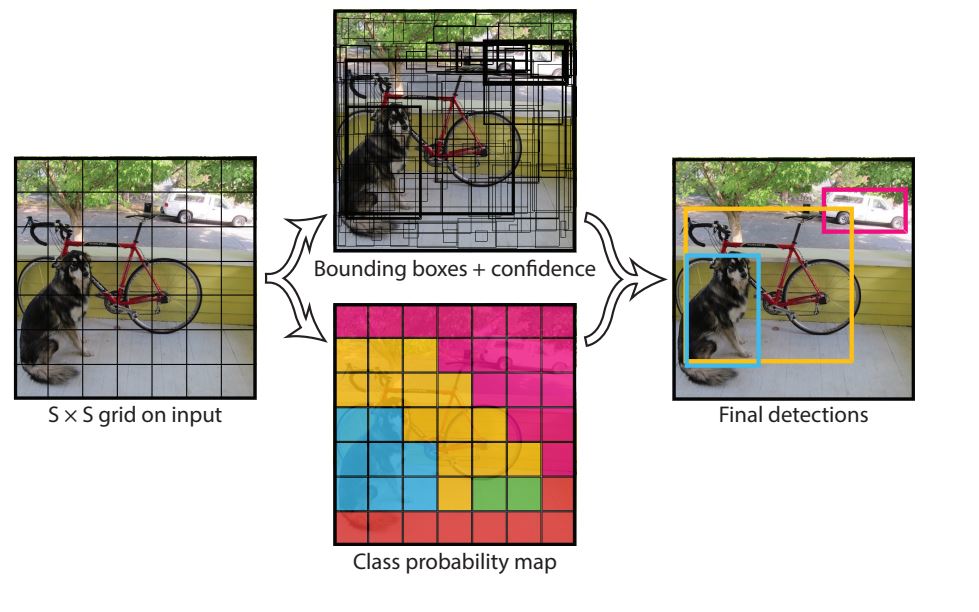
The structure of YOLOv1 was impressed by GoogLeNet and divided the enter dimension picture right into a 7×7 grid. Every grid cell predicted bounding packing containers and confidence scores for a number of objects in a single cross. With this, it was capable of run at over 45 frames per second and made real-time functions potential. Nonetheless, accuracy was poorer in comparison with two-stage fashions resembling Sooner RCNN.
YOLOv2
The YOLOv2 object detector mannequin was Launched in 2016 and improved upon its predecessor with higher accuracy whereas sustaining the identical pace. Essentially the most notable change was the introduction of predefined anchor packing containers into the mannequin for higher bounding field predictions. This alteration considerably improved the mannequin’s imply common precision (mAP), notably for smaller objects.
YOLOv3

YOLOv3 was launched in 2018 and launched a deeper spine community, the Darknet-53, which had 53 convolutional layers. This deeper community helped with higher characteristic extraction. Moreover, it launched Objectness scores for bounding packing containers (predicting whether or not the bounding field comprises an object or background). Moreover, the mannequin launched Spatial Pyramid Pooling (SPP), which elevated the receptive area of the mannequin.
Key Innovation launched in YOLOv4
YOLOv4 improved the effectivity of its predecessor and made it potential for it to be educated and run on a single GPU. General the structure adjustments made all through the YOLOv4 are as follows:
- CSPDarknet53 as spine: Changed the Darknet-53 spine utilized in YOLOv3 with CSP Darknet53
- PANet: YOLOv4 changed the Characteristic Pyramid Community (FPN) utilized in YOLOv3 with PANet
- Self-Adversarial Coaching (SAT)
Moreover, the authors did intensive analysis on discovering one of the simplest ways to coach and run the mannequin. They categorized these experiments as Bag of Freebies (BoF) and Bag of Specials (BoS).
Bag of Freebies are adjustments that happen through the coaching course of solely and assist enhance the mannequin efficiency, subsequently it solely will increase the coaching time whereas leaving the inference time the identical. Whereas, Bag of Specials introduces adjustments that barely improve inference computation necessities however supply higher accuracy acquire. With this, a person might choose what freebies they should use whereas additionally being conscious of its prices when it comes to coaching time and inference pace in opposition to accuracy.
Structure of YOLOv4
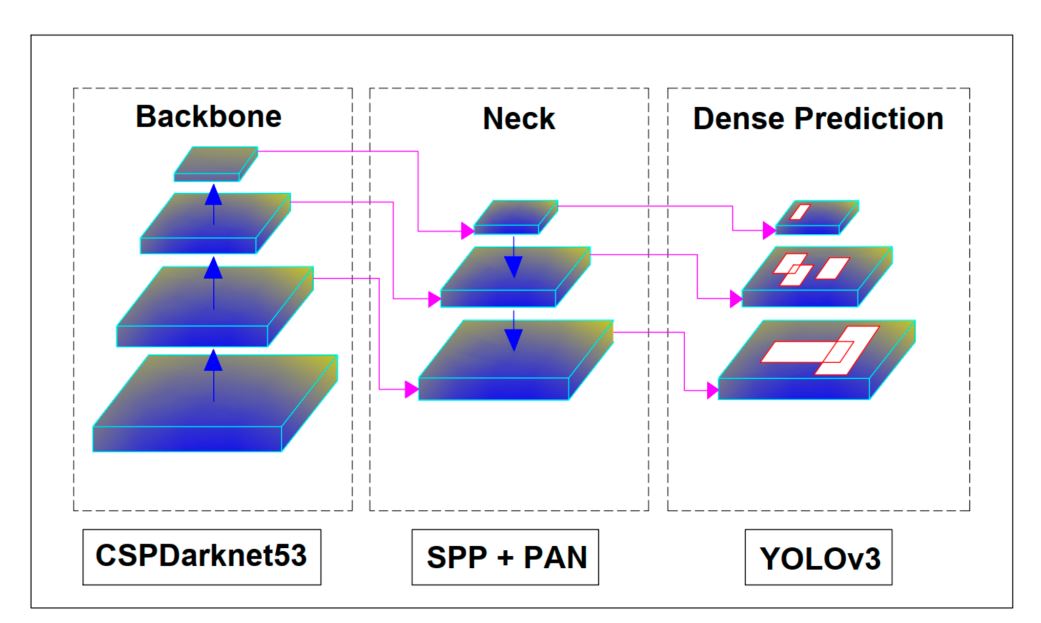
Though the structure of YOLOv4 appears advanced at first, general the mannequin has the next important parts:
- Spine: CSPDarkNet53
- Neck: SSP + PANet
- Head: YOLOv3
Other than these, every little thing is left as much as the person to resolve what they should use with Bag of Freebies and Bag of Specials.
CSPDarkNet53 Spine
A Spine is a time period used within the YOLO household of fashions. In YOLO fashions, the only real function is to extract options from pictures and cross them ahead to the mannequin for object detection and classification. The spine is a CNN structure made up of a number of layers. In YOLOv4, the researchers additionally supply a number of selections for spine networks, resembling ResNeXt50, EfficientNet-B3, and Darknet-53 which has 53 convolution layers.
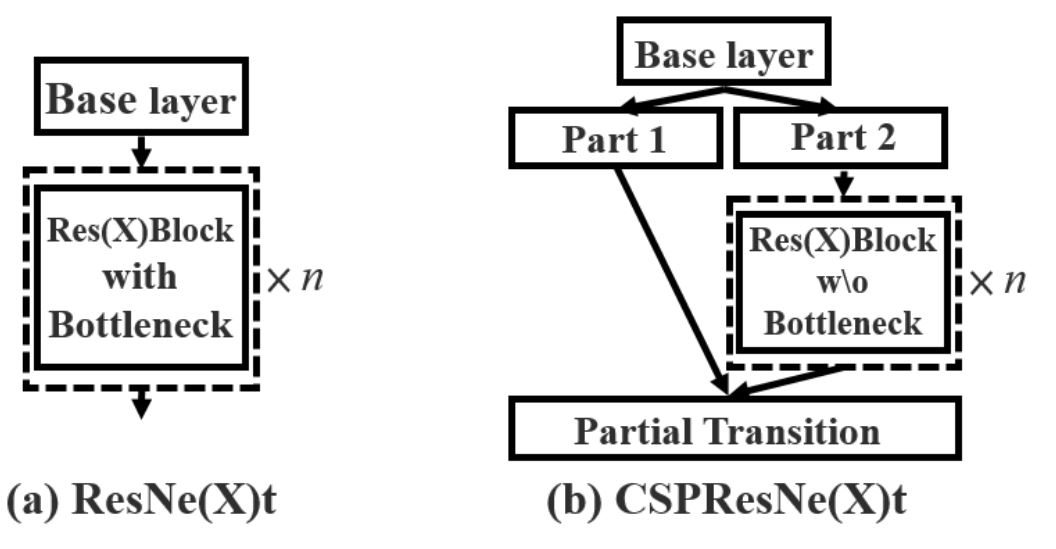
YOLOv4 makes use of a modified model of the unique Darknet-53, known as CSPNetDarkNet53, and is a vital part of YOLOv4. It builds upon the Darknet-53 structure and introduces a Cross-Stage Partial (CSP) technique to reinforce efficiency in object detection duties.
The CSP technique divides the characteristic maps into two components. One half flows by way of a sequence of residual blocks whereas the opposite bypasses them, and concatenates them later within the community. Though Darknet (impressed by ResNet makes use of an identical design within the type of residual connections) the distinction lies as well as and concatenation. Residual connections add characteristic maps, whereas CSP concatenates them.
Concatenation characteristic maps aspect by aspect alongside the channel dimension improve the variety of channels. For instance, concatenating two characteristic maps every with 32 channels leads to a brand new characteristic map with 64 channels. Resulting from this nature, options are preserved higher and improves the thing detection mannequin accuracy.
Additionally, the CSP technique makes use of much less RAM, as half of the characteristic maps undergo the community. Resulting from this, CSP methods have been proven to scale back computation wants by 20%.
SSP and PANet Neck
The neck in YOLO fashions collects characteristic maps from totally different phases of the spine and passes them all the way down to the top. The YOLOv4 mannequin makes use of a customized neck that consists of a modified model of PANet, spatial pyramid pooling (SPP), and spatial consideration module (SAM).
SPP
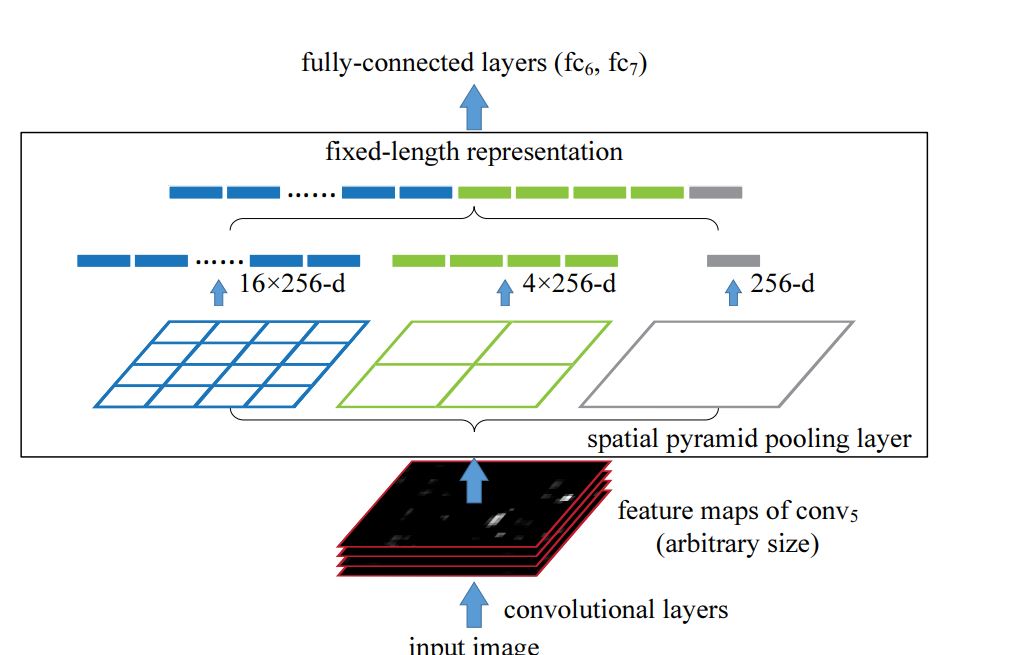
Within the conventional Spatial Pyramid Pooling (SPP), fixed-size max pooling is utilized to divide the characteristic map into areas of various sizes (e.g., 1×1, 2×2, 4×4), and every area is pooled independently. The ensuing pooled outputs are then flattened and mixed right into a single characteristic vector to provide a fixed-length characteristic vector that doesn’t retain spatial dimensions. This strategy is right for classification duties, however not for object detection, the place the receptive area is vital.
In YOLOv4 that is modified and makes use of fixed-size pooling kernels with totally different sizes (e.g., 1×1, 5×5, 9×9, and 13×13) however retains the identical spatial dimensions of the characteristic map.
Every pooling operation produces a separate output, which is then concatenated alongside the channel dimension quite than being flattened. Through the use of massive pooling kernels (like 13×13) in YOLOv4, the SPP block expands the receptive area whereas preserving spatial particulars, permitting the mannequin to higher detect objects of varied sizes (massive and small objects). Moreover, this strategy provides minimal computational overhead, supporting YOLOv4 for real-time detection.
PAN
YOLOv3 made use of FPN, nevertheless it was changed with a modified PAN in YOLOv4. PAN builds on the FPN construction by including a bottom-up pathway along with the top-down pathway. This bottom-up path aggregates and passes options from decrease ranges again up by way of the community, which reinforces lower-level options with contextual data and enriches high-level options with spatial particulars.
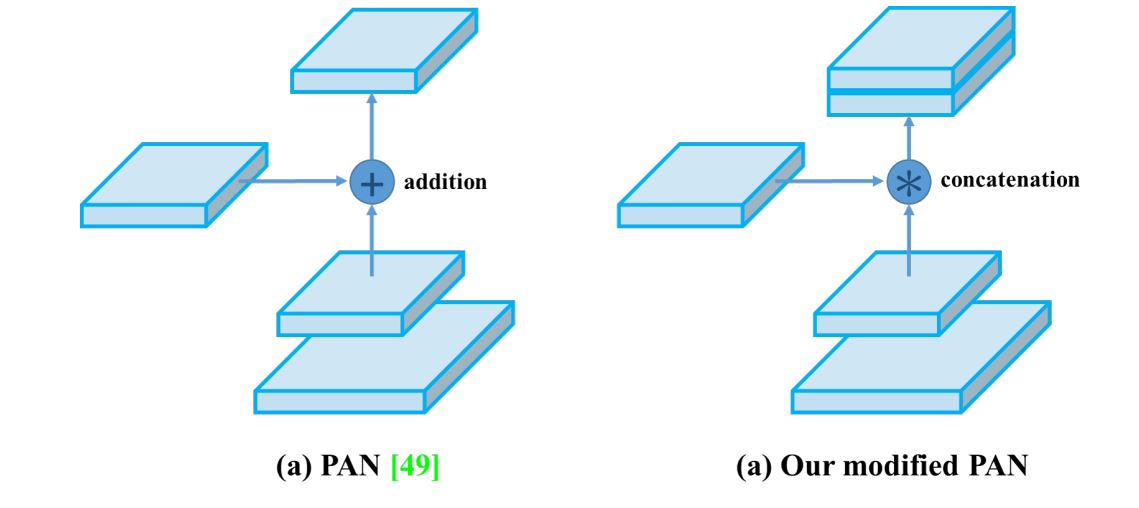
Nonetheless, in YOLOv4, the unique PANet was modified and used concatenation as a substitute of aggregation. This permits it to make use of multi-scale options effectively.
Modified SAM
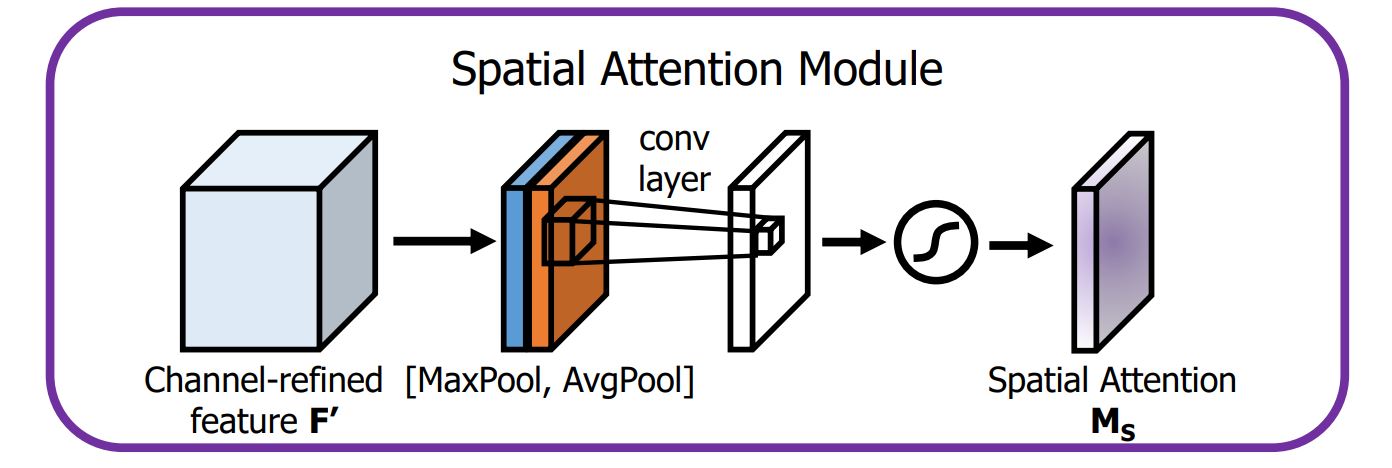
The usual SAM approach makes use of each most and common pooling operations to create separate characteristic maps that assist deal with vital areas of the enter.
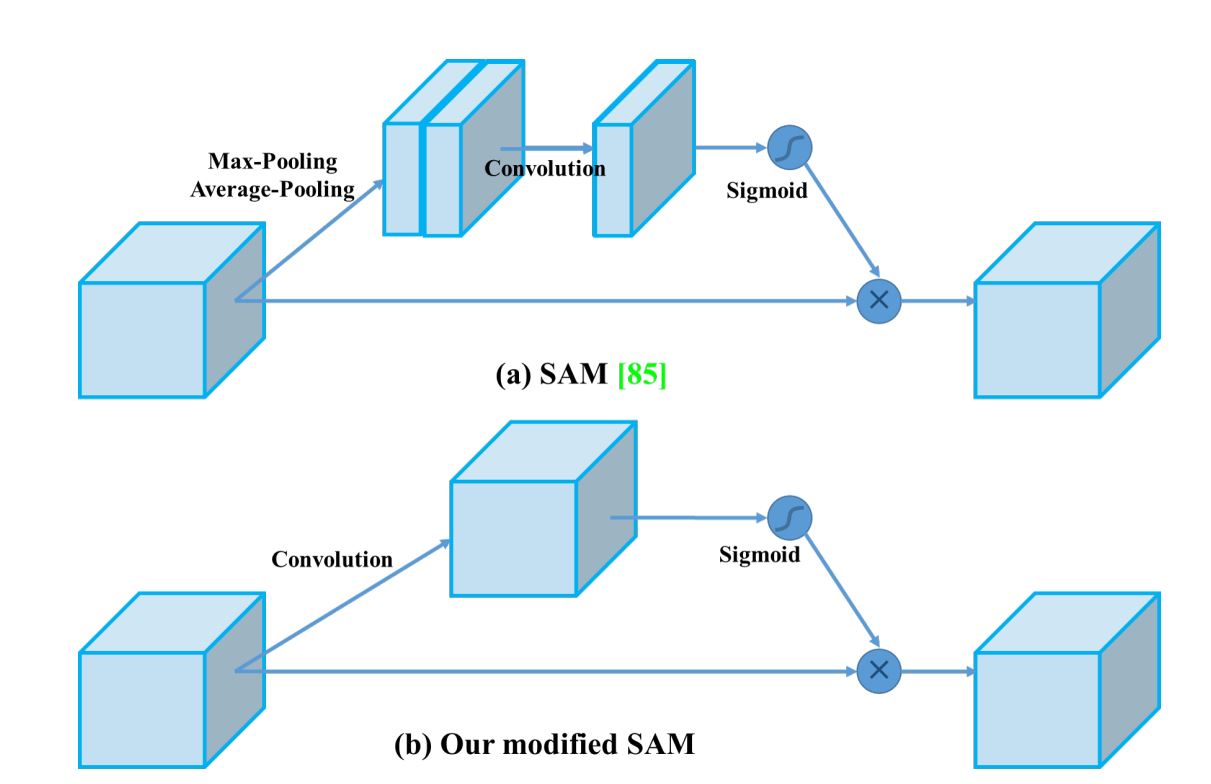
Nonetheless, in YOLOv4, these pooling operations are omitted (as a result of they scale back data contained in characteristic maps). As a substitute, the modified SAM immediately processes the enter characteristic maps by making use of convolutional layers adopted by a sigmoid activation operate to generate consideration maps.
How does a Commonplace SAM work?
The Spatial Consideration Module (SAM) is vital for its position in permitting the mannequin to deal with options which are vital for detection and miserable the irrelevant options.
- Pooling Operation: SAM begins by processing the enter characteristic maps in YOLO layers by way of two varieties of pooling operations—common pooling and max pooling.
- Common Pooling produces a characteristic map that represents the typical activation throughout channels.
- Max Pooling captures probably the most vital activation, emphasizing the strongest options.
- Concatenation: The outputs from common and max pooling are concatenated to kind a mixed characteristic descriptor. This step outputs each international and native data from the characteristic maps.
- Convolution Layer: The concatenated characteristic descriptor is then handed by way of a Convolution Neural Community. The convolutional operation helps to be taught spatial relationships and additional refines the eye map.
- Sigmoid Activation: A sigmoid activation operate is utilized to the output of the convolution layer, leading to a spatial consideration map. Lastly, this consideration map is multiplied element-wise with the unique enter characteristic map.
YOLOv3 Head
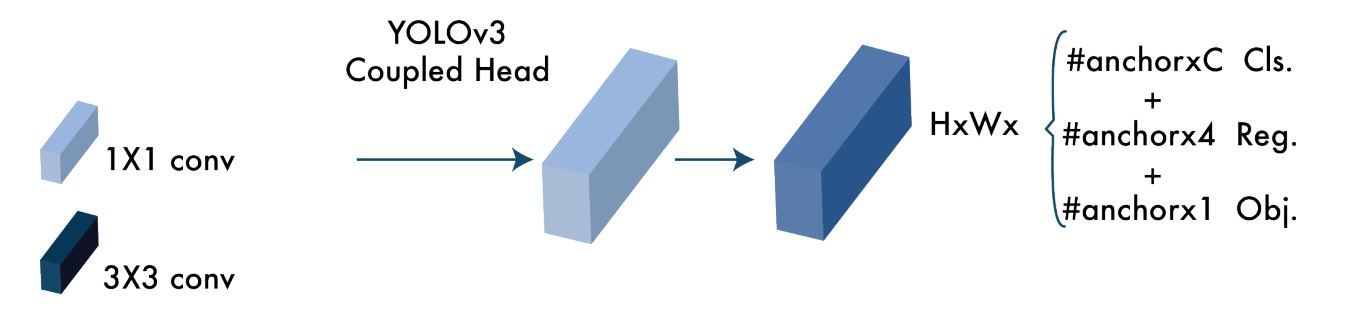
The pinnacle of YOLO fashions is the place object detection and classification occurs. Regardless of YOLOv4 being the successor it retains the top of YOLOv3, which implies it additionally produces anchor field predictions and bounding field regression.
Due to this fact, we are able to see that the optimizations carried out within the spine and neck of YOLOv4 are the explanation we see a noticeable enchancment in effectivity and pace.
What’s Self-Adversarial Coaching (SAT)
Self Adversarial Coaching (SAT) in YOLOv4 is a knowledge augmentation approach utilized in coaching pictures (practice knowledge) to reinforce the mannequin’s robustness and enhance generalization.
How SAT Works
The essential concept of adversarial coaching is to enhance the mannequin’s resilience by exposing it to adversarial examples throughout coaching. These examples are created to mislead the mannequin into making incorrect predictions.
In step one, the community learns to change the unique picture to make it seem as if the specified object just isn’t current. Within the second step, the modified pictures are used for coaching, the place the community makes an attempt to detect objects in these altered pictures in opposition to floor reality. This system intelligently alters pictures in such a method that pushes the mannequin to be taught higher and generalize itself for pictures not included within the coaching set.
Actual-Life Software of Software of YOLOv4
YOLOv4 has been utilized in a variety of functions and situations, together with use in embedded programs. A few of these are:
- Harvesting Oil Palm: A gaggle of researchers used YOLOv4 paired with a digicam and laptop computer gadget with an Intel Core i7-8750H processor and GeForce DTX 1070 graphic card, to detect ripe fruit branches. In the course of the testing part, they achieved 87.9 % imply Common Precision (mAP) and 82 % recall price whereas working at a real-time pace of 21 FPS.

Ripe palm tree detection utilizing YOLOv4 –source - Animal Monitoring: On this examine, the researchers used YOLOv4 to detect foxes and monitor their motion and exercise. Utilizing CV, the researchers had been capable of robotically analyze the movies and monitor animal exercise with out human interference.

Silver fox detection utilizing YOLOv4 –source - Pest Management: Correct and environment friendly real-time detection of orchard pests is vital to enhance the financial advantages of the fruit trade. Because of this, researchers educated the YOLOv4 mannequin for the clever identification of agricultural pests. The mAP obtained was at 92.86%, and a detection time of 12.22ms, which is right for real-time detection.

Pest detection –source - Poth Gap Detection: Pothole restore is a vital problem and job in street upkeep, as guide operation is labor-intensive and time-consuming. Because of this, researchers educated YOLOv4 and YOLOv4-tiny to automate the inspection course of and obtained an mAP of 77.7%, 78.7%

Pothole detection utilizing YOLOv4 –source - Practice detection: Detection of a fast-moving practice in real-time is essential for the protection of the practice and folks round practice tracks. A gaggle of researchers constructed a customized object detection mannequin based mostly on YOLOv4 for fast-moving trains, and achieved an accuracy of 95.74%, with 42.04 frames per second, which implies detecting an image solely takes 0.024s.
What’s Subsequent
On this weblog, we seemed into the structure of the YOLO v4 mannequin, and the way it permits coaching and working object detection fashions utilizing a single GPU. Moreover, we checked out further options the researchers launched termed as Bag of Freebies and Bag of Specials. General, the mannequin introduces three key options. The usage of the CSPDarkNet53 as spine, modified SSP, and PANet. Lastly, we additionally checked out how researchers have included the mode for varied CV functions.