

Carry this undertaking to life
Data2Vec
The self-supervised studying paradigm has made a major breakthrough by enabling machine studying fashions to be taught utilizing multi-modal, labeled information. Many ML functions typically depend on the illustration capabilities of fashions. However, usually, current algorithms have sure limitations, as they apply to solely a single downstream activity (imaginative and prescient, speech, or textual content) or mode. This paradigm could be very totally different from how people be taught. To allow this stage of machine intelligence, the theoretical normal AI, the goal of ML mannequin growth ought to be a standard framework to know various kinds of information (picture, textual content, or audio).
Data2Vec by Meta AI is a lately launched mannequin which introduces a standard framework to coach on various kinds of information inputs. Presently, it helps 3 varieties of modalities: Textual content, Speech, and Imaginative and prescient (pictures). The target behind such a normal studying framework is to preserve analysis developments from one modality drawback to a different. For instance, it permits language understanding to picture classification of the speech translation activity.
How does it work?
Data2Vec trains the information (of any modality) in two separate modes: Pupil mode and Instructor mode. For Instructor mode, the spine mannequin (which is totally different for every modality and corresponds to the information sort) first creates embeddings similar to the complete enter information whose function is to function targets (labels). For pupil mode, the identical spine mannequin creates embeddings to the masked model of enter information, with which it tries to foretell the complete information representations. Keep in mind, the spine mannequin is totally different for various kinds of information (textual content, audio, or imaginative and prescient) in a single Data2Vec mannequin.
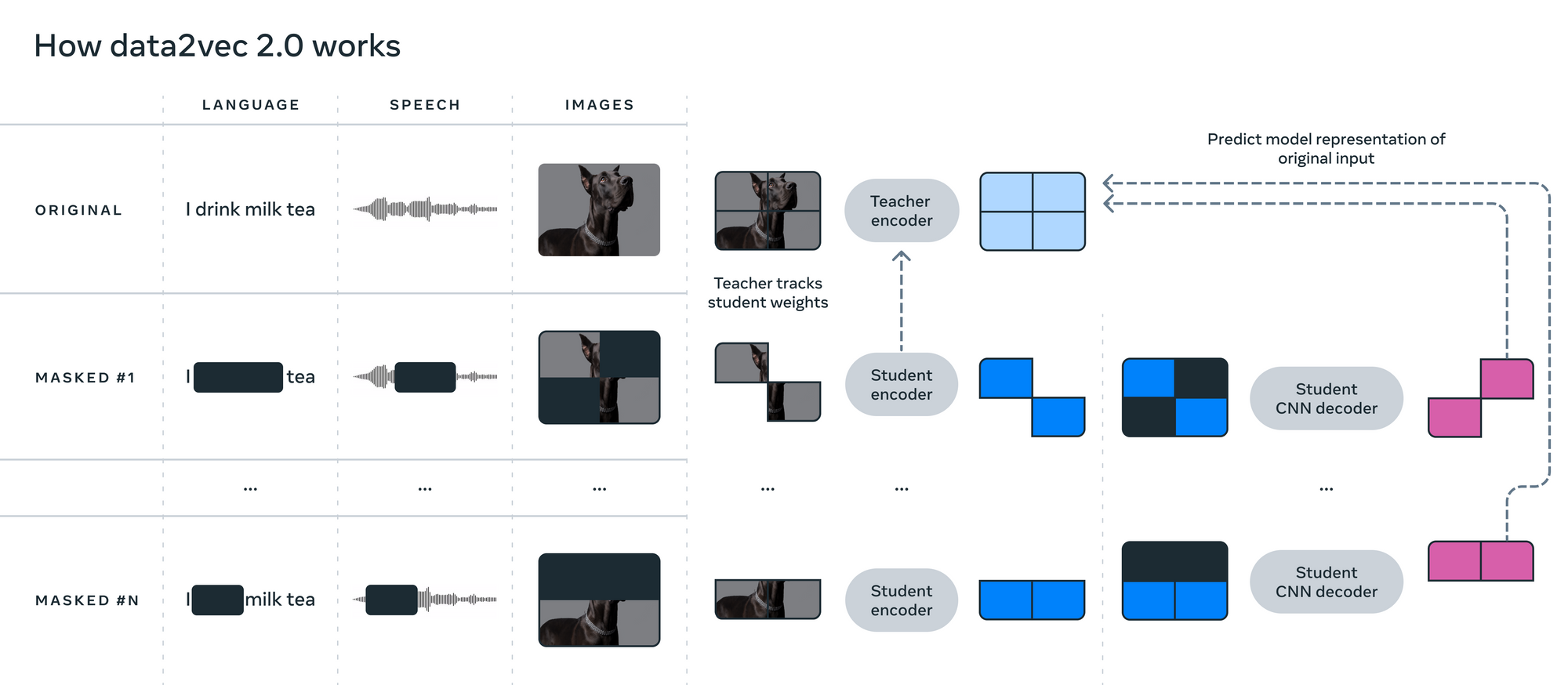
In trainer mode, the goal is taken because the weighted sum of all of the options within the single pattern. For instance, within the case of picture information, the spine mannequin generates representations of 4 totally different patches of the picture and takes a weighted common of every of them. The coaching targets are based mostly on averaging the highest Ok Feed-Ahead module blocks of the trainer encoder community, the place Ok is a hyperparameter.
From the above determine, we will see that the components of the enter information are masked in pupil mode. The coed encoder community creates a illustration of solely unmasked enter information. Then the mannequin attaches the fixed embeddings rather than the masked information patch. Now, this resultant embedding is handed via the coed decoder community which tries to foretell the goal illustration (created from the trainer encoder community). For studying, solely the masked enter illustration is in contrast between the trainer and pupil community.
Instructor encoder community weights ∆ are exponentially transferring averages of pupil encoder weights θ. Weights will be represented formulaically with ∆ = τ ∆ + (1 − τ ) θ , the place τ is a hyperparameter that will increase linearly. L2 loss is used for studying between goal illustration (from the trainer community) y and the masked illustration (from the coed community) f(x) .
As said earlier, the Data2Vec mannequin makes use of totally different spine fashions relying on the kind of information being fed. For imaginative and prescient, it makes use of the Imaginative and prescient Transformer (ViT), which acts as a function encoder for patches of dimension 16×16. For speech, it makes use of the Multi-Layer Convolutional Community. For textual content, it makes use of embeddings discovered from byte-pair encoding.
Comparability with current algorithms
Within the paper, the outcomes of Data2Vec are in contrast with the state-of-the-art illustration studying algorithms in laptop imaginative and prescient, speech processing, and pure language processing. The comparability is carried out based mostly on accuracy for picture classification, phrase error price for speech recognition, and GLUE for the pure language understanding activity. The under plots signify the efficiency of Data2Vec v1 & v2 with different state-of-the-art fashions from the corresponding modality.
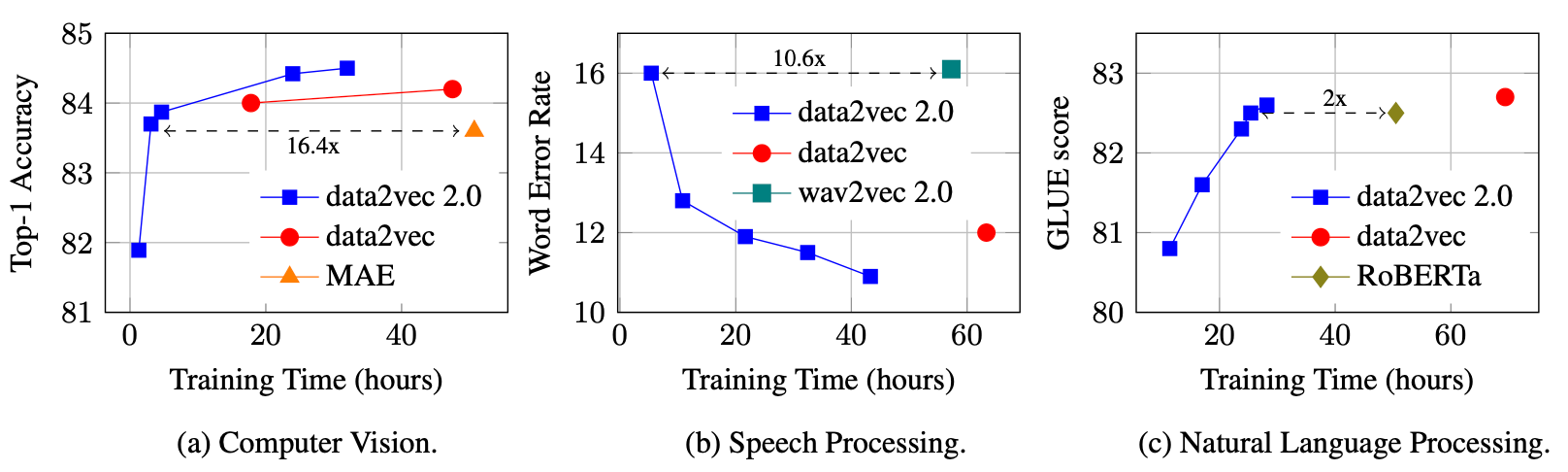
Within the above plots, we will discover that Data2Vec 2.0 performs one of the best in all 3 modality duties. We will additionally observe that it trains sooner.
Watch out to not mistake the 2 variations of Data2Vec. Each have the identical underlying structure, however v2 has made some computation modifications for sooner coaching.
Attempt it your self
Carry this undertaking to life
Allow us to now stroll via how one can prepare the mannequin utilizing the datasets described within the paper, and use it on your personal functions. For this activity, we’ll get this working in a Gradient Pocket book right here on Paperspace. To navigate to the codebase, click on on the “Run on Gradient” button above or on the prime of this weblog.
Setup
The file installations.sh comprises all the required code to put in the required dependencies. Word that your system will need to have CUDA to coach Data2Vec. Additionally, chances are you’ll require a unique model torch based mostly on the model of CUDA. If you’re working this on Paperspace Gradient Pocket book, then the default model of CUDA is 11.6 which is suitable with this code. If you’re working it elsewhere, please verify your CUDA model utilizing nvcc --version. If the model differs from ours, chances are you’ll need to change variations of PyTorch libraries within the first line of installations.sh by trying on the compatibility desk.
To put in all of the dependencies, run the under command:
bash installations.sh
The above command clones fairseq repository and set up fairseq package deal which is used to execute the coaching and validation pipeline. It additionally installs the apex package deal which permits sooner coaching on CUDA-compatible gadgets. Furthermore, it installs additional dependencies talked about in necessities.txt file.
Downloading datasets & Begin coaching
As soon as now we have put in all of the dependencies, we will obtain the datasets and begin coaching the fashions.
The datasets listing comprises the required scripts to obtain the information and make it prepared for coaching. Presently, this repository helps downloading 3 varieties of datasets ImageNet (Imaginative and prescient), LibriSpeech (Speech), and OpenWebText (Textual content).
We now have already arrange bash scripts for you which can mechanically obtain the dataset for you and can begin the coaching. scripts listing on this repo comprises these bash scripts corresponding to a couple of the various duties which Data2Vec helps. You may take a look at certainly one of these activity bash scripts to know what it does. These bash scripts are suitable with Paperspace Gradient Pocket book.
💡
This may take a very long time and require vital cupboard space, so it’s not really useful to run this on a Free GPU powered Paperspace Pocket book.
To obtain information information and begin coaching, you’ll be able to execute the under instructions similar to the duty you need to run it for:
# Downloads ImageNet and begins coaching data2vec_multi with it.
bash scripts/train_data2vec_multi_image.sh
# Downloads OpenWebText and begins coaching data2vec_multi with it.
bash scripts/train_data2vec_multi_text.sh
# Downloads LibriSpeech and begins coaching data2vec_multi with it.
bash scripts/train_data2vec_multi_speech.sh
Word that you could be need to change a few of the arguments in these activity scripts based mostly in your system. Since now we have a single GPU on Gradient Pocket book, the arg distributed_training.distributed_world_size=1 for us which you’ll be able to change based mostly in your requirement. You might need to know all of the out there args from the config file similar to the duty in data2vec/config/v2.
Checkpoints & Future utilization
As soon as now we have downloaded the dataset and began the coaching, the checkpoints can be saved within the corresponding sub-directory of the listing checkpoints. You might need to obtain the publicly out there checkpoints from the unique fairseq repository. If you’re coaching the mannequin, observe that the coaching will solely be stopped when the minimal threshold situation between the goal and predicted variable distinction is met. It means there is no such thing as a predefined variety of epochs for coaching. Though, you’ll be able to cease the coaching manually if you wish to interrupt the coaching in between and use the final checkpoint.
To make use of the mannequin for inference, you need to use under code:
import torch
from data2vec.fashions.data2vec2 import D2vModalitiesConfig
from data2vec.fashions.data2vec2 import Data2VecMultiConfig
from data2vec.fashions.data2vec2 import Data2VecMultiModel
# Load checkpoint
ckpt = torch.load(CHECKPOINT_PATH)
# Create config and cargo mannequin
cfg = Data2VecMultiConfig()
mannequin = Data2VecMultiModel(cfg, modalities=D2vModalitiesConfig.picture)
mannequin.load_state_dict(ckpt)
mannequin.eval()
# Producing prediction from information
pred = mannequin(BATCHED_DATA_OBJECT)
Word that it is advisable load the checkpoint of the corresponding activity to generate a prediction. It means which you can’t generate predictions on picture information utilizing the checkpoint generated from coaching audio information.
Conclusion
Data2Vec is a really highly effective framework that unifies studying schemes for various kinds of information. On account of this, it considerably improves the efficiency of downstream duties, particularly for multimodal fashions. On this weblog, we walked via the target & the structure of the Data2Vec mannequin, in contrast the outcomes obtained from Data2Vec with different state-of-the-art fashions, and mentioned methods to arrange the surroundings & prepare Data2Vec on Gradient Pocket book.
Be sure you check out every of the mannequin varieties utilizing Gradient’s big selection of obtainable machine varieties!