

Autoencoders are a robust device utilized in machine studying for function extraction, knowledge compression, and picture reconstruction. These neural networks have made vital contributions to laptop imaginative and prescient, pure language processing, and anomaly detection, amongst different fields. An autoencoder mannequin has the flexibility to mechanically study advanced options from enter knowledge. This has made them a well-liked technique for bettering the accuracy of classification and prediction duties.
On this article, we’ll discover the basics of autoencoders and their various purposes within the subject of machine studying.
- The fundamentals of autoencoders, together with the kinds and architectures.
- How autoencoders are used with real-world examples
- We’ll discover the completely different purposes of autoencoders in laptop imaginative and prescient.
About us: Viso.ai powers the main end-to-end Pc Imaginative and prescient Platform Viso Suite. Our answer allows organizations to quickly construct and scale laptop imaginative and prescient purposes. Get a demo in your firm.
What’s an Autoencoder?
Clarification and Definition of Autoencoders
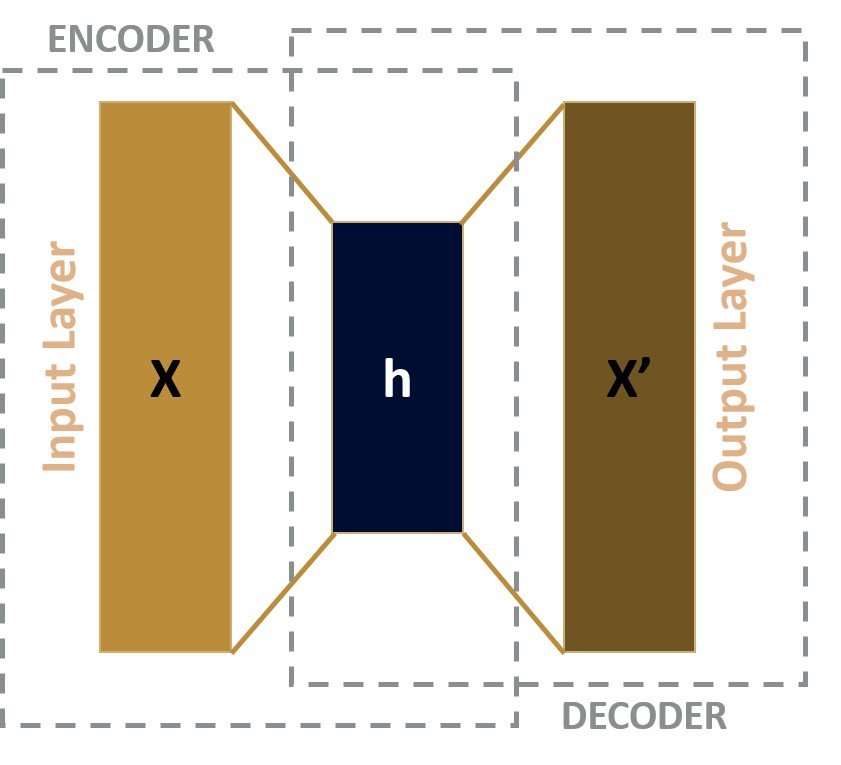
Autoencoders are neural networks that may study to compress and reconstruct enter knowledge, equivalent to photographs, utilizing a hidden layer of neurons. An autoencoder mannequin consists of two components: an encoder and a decoder.
The encoder takes the enter knowledge and compresses it right into a lower-dimensional illustration referred to as the latent area. The decoder then reconstructs the enter knowledge from the latent area illustration. In an optimum situation, the autoencoder performs as near good reconstruction as potential.
Loss operate and Reconstruction Loss
Loss features play a important position in coaching autoencoders and figuring out their efficiency. Essentially the most generally used loss operate for autoencoders is the reconstruction loss. It’s used to measure the distinction between the mannequin enter and output.
The reconstruction error is calculated utilizing varied loss features, equivalent to imply squared error, binary cross-entropy, or categorical cross-entropy. The utilized technique relies on the kind of knowledge being reconstructed.
The reconstruction loss is then used to replace the weights of the community throughout backpropagation to reduce the distinction between the enter and the output. The aim is to attain a low reconstruction loss. A low loss signifies that the mannequin can successfully seize the salient options of the enter knowledge and reconstruct it precisely.
Dimensionality discount
Dimensionality discount is the method of lowering the variety of dimensions within the encoded illustration of the enter knowledge. Autoencoders can study to carry out dimensionality discount by coaching the encoder community to map the enter knowledge to a lower-dimensional latent area. Then, the decoder community is skilled to reconstruct the unique enter knowledge from the latent area illustration.
The dimensions of the latent area is often a lot smaller than the dimensions of the enter knowledge, permitting for environment friendly storage and computation of the information. By dimensionality discount, autoencoders can even assist to take away noise and irrelevant options. That is helpful for bettering the efficiency of downstream duties equivalent to knowledge classification or clustering.
The preferred Autoencoder fashions
There are a number of varieties of autoencoder fashions, every with its personal distinctive strategy to studying these compressed representations:
- Autoencoding fashions: These are the best kind of autoencoder mannequin. They study to encode enter knowledge right into a lower-dimensional illustration. Then, they decode this illustration again into the unique enter.
- Contractive autoencoder: One of these autoencoder mannequin is designed to study a compressed illustration of the enter knowledge whereas being proof against small perturbations within the enter. That is achieved by including a regularization time period to the coaching goal. This time period penalizes the community for altering the output with respect to small modifications within the enter.
- Convolutional autoencoder (CAE): A Convolutional Autoencoder (CAE) is a kind of neural community that makes use of convolutional layers for encoding and decoding of photographs. This autoencoder kind goals to study a compressed illustration of a picture by minimizing the reconstruction error between the enter and output of the community. Such fashions are generally used for picture technology duties, picture denoising, compression, and picture reconstruction.
- Sparse autoencoder: A sparse autoencoder is much like an everyday autoencoder, however with an added constraint on the encoding course of. In a sparse autoencoder, the encoder community is skilled to provide sparse encoding vectors, which have many zero values. This forces the community to establish solely an important options of the enter knowledge.
- Denoising autoencoder: One of these autoencoder is designed to study to reconstruct an enter from a corrupted model of the enter. The corrupted enter is created by including noise to the unique enter, and the community is skilled to take away the noise and reconstruct the unique enter. For instance, BART is a well-liked denoising autoencoder for pretraining sequence-to-sequence fashions. The mannequin was skilled by corrupting textual content with an arbitrary noising operate and studying a mannequin to reconstruct the unique textual content. It is extremely efficient for pure language technology, textual content translation, textual content technology and comprehension duties.
- Variational autoencoders (VAE): Variational autoencoders are a kind of generative mannequin that learns a probabilistic illustration of the enter knowledge. A VAE mannequin is skilled to study a mapping from the enter knowledge to a likelihood distribution in a lower-dimensional latent area, after which to generate new samples from this distribution. VAEs are generally utilized in picture and textual content technology duties.
- Video Autoencoder: Video Autoencoder have been launched for studying representations in a self-supervised method. For instance, a model was developed that may study representations of 3D construction and digicam pose in a sequence of video frames as enter (see Pose Estimation). Therefore, Video Autoencoder will be skilled immediately utilizing a pixel reconstruction loss, with none floor fact 3D or digicam pose annotations. This autoencoder kind can be utilized for digicam pose estimation and video technology by movement following.
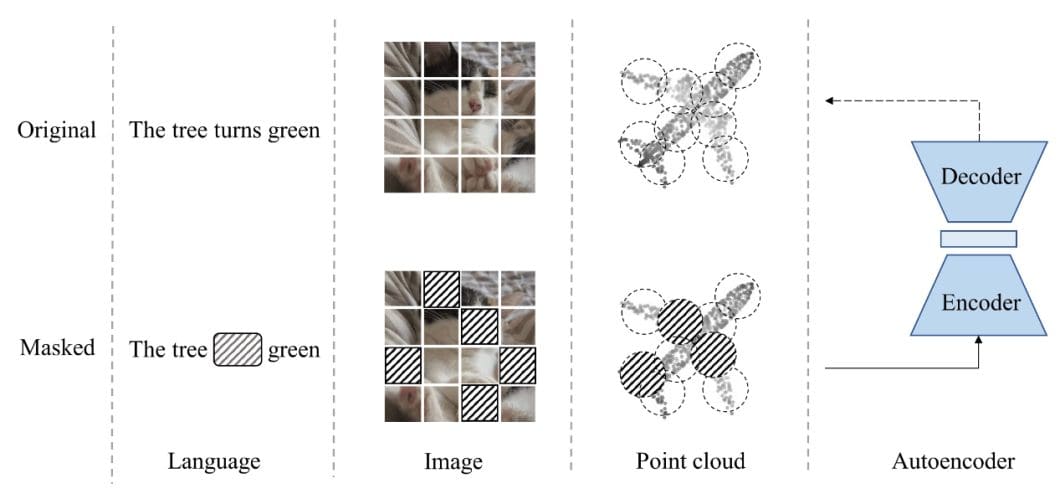
- Masked Autoencoders (MAE): A masked autoencoder is a straightforward autoencoding strategy that reconstructs the unique sign given its partial remark. A MAE variant consists of masked autoencoders for level cloud self-supervised studying, named Point-MAE. This strategy has proven nice effectiveness and excessive generalization functionality on varied duties, together with object classification, few-show studying, and part-segmentation. Particularly, Level-MAE outperforms all the opposite self-supervised studying strategies.
How Autoencoders work in Pc Imaginative and prescient
Autoencoder fashions are generally used for picture processing duties in laptop imaginative and prescient. On this use case, the enter is a picture and the output is a reconstructed picture. The mannequin learns to encode the picture right into a compressed illustration. Then, the mannequin decodes this illustration to generate a brand new picture that’s as shut as potential to the unique enter.
Enter and output are two vital elements of an autoencoder mannequin. The enter to an autoencoder is the information that we need to encode and decode. And the output is the reconstructed knowledge that the mannequin produces after encoding and decoding the enter.
The primary goal of an autoencoder is to reconstruct the enter as precisely as potential. That is achieved by feeding the enter knowledge by means of a collection of layers (together with hidden layers) that encode and decode the enter. The mannequin then compares the reconstructed output to the unique enter and adjusts its parameters to reduce the distinction between them.
Along with reconstructing the enter, autoencoder fashions additionally study a compressed illustration of the enter knowledge. This compressed illustration is created by the bottleneck layer of the mannequin, which has fewer neurons than the enter and output layers. By studying this compressed illustration, the mannequin can seize an important options of the enter knowledge in a lower-dimensional area.
Step-by-step strategy of autoencoders
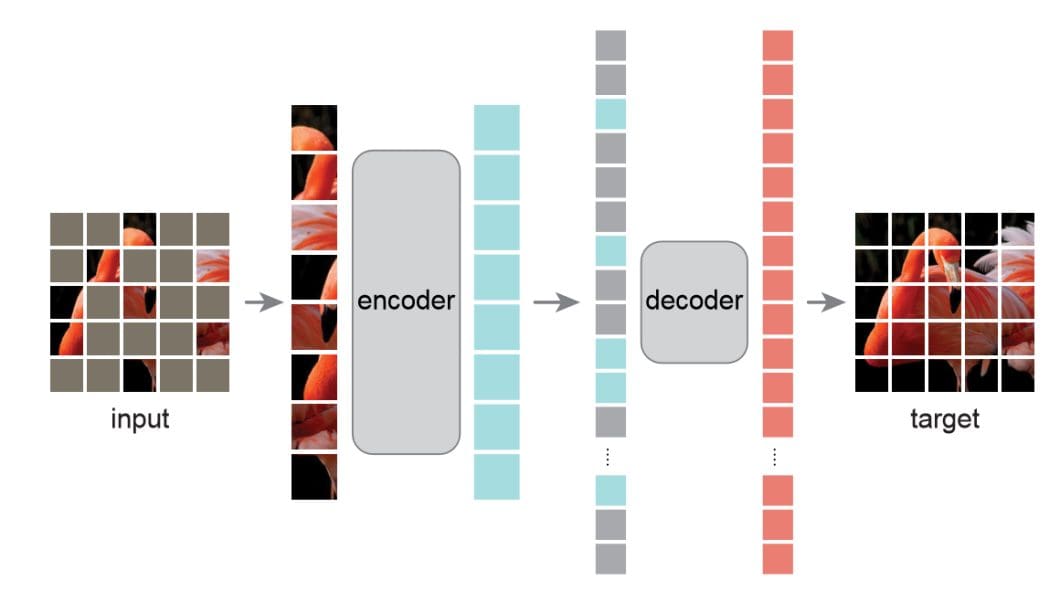
Autoencoders extract options from photographs in a step-by-step course of as follows:
- Enter Picture: The autoencoder takes a picture as enter, which is often represented as a matrix of pixel values. The enter picture will be of any measurement, however it’s sometimes normalized to enhance the efficiency of the autoencoder.
- Encoding: The autoencoder compresses the enter picture right into a lower-dimensional illustration, referred to as the latent area, utilizing the encoder. The encoder is a collection of convolutional layers that extract completely different ranges of options from the enter picture. Every layer applies a set of filters to the enter picture and outputs a function map that highlights particular patterns and constructions within the picture.
- Latent Illustration: The output of the encoder is a compressed illustration of the enter picture within the latent area. This latent illustration captures an important options of the enter picture and is often a smaller dimensional illustration of the enter picture.
- Decoding: The autoencoder reconstructs the enter picture from the latent illustration utilizing the decoder. The decoder is a set of a number of deconvolutional layers that step by step enhance the dimensions of the function maps till the ultimate output is similar measurement because the enter picture. Each layer applies a set of filters that up-sample the function maps, leading to a reconstructed picture.
- Output Picture: The output of the decoder is a reconstructed picture that’s much like the enter picture. Nevertheless, the reconstructed picture is probably not equivalent to the enter picture for the reason that autoencoder has discovered to seize an important options of the enter picture within the latent illustration.
By compressing and reconstructing enter photographs, autoencoders extract an important options of the photographs within the latent area. These options can then be used for duties equivalent to picture classification, object detection, and picture retrieval.
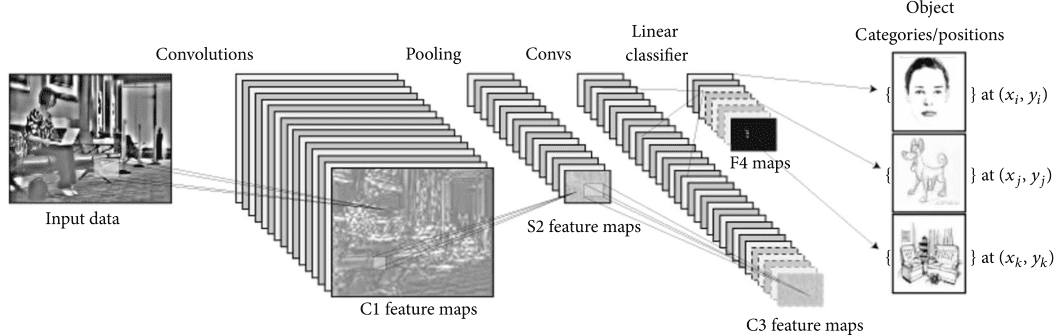
Limitations and Advantages of Autoencoders for Pc Imaginative and prescient
Conventional function extraction strategies contain the necessity to manually design function descriptors that seize vital patterns and constructions in photographs. These function descriptors are then used to coach machine studying fashions for duties equivalent to picture classification and object detection.
Nevertheless, designing function descriptors manually could be a time-consuming and error-prone course of that won’t seize all of the vital options in a picture.
Benefits of Autoencoders
Benefits of Autoencoders over conventional function extraction strategies embrace:
- First, autoencoders study options mechanically from the enter knowledge, making them more practical in capturing advanced patterns and constructions in photographs (sample recognition). That is significantly helpful when coping with massive and sophisticated datasets the place manually designing function descriptors is probably not sensible and even potential.
- Second, autoencoders are appropriate for studying extra strong options that generalize higher to new knowledge. Different function extraction strategies typically depend on handcrafted options that won’t generalize nicely to new knowledge. Autoencoders, however, study options which might be optimized for the precise dataset, leading to extra strong options that may generalize nicely to new knowledge.
- Lastly, autoencoders are capable of study extra advanced and summary options that is probably not potential with conventional function extraction strategies. For instance, autoencoders can study options that seize the general construction of a picture, such because the presence of sure objects or the general format of the scene. These kinds of options could also be troublesome to seize utilizing conventional function extraction strategies, which generally depend on low-level options equivalent to edges and textures.
Disadvantages of Autoencoders
Disadvantages of autoencoders embrace the next limitations:
- One main limitation is that autoencoders will be computationally costly (see price of laptop imaginative and prescient), significantly when coping with massive datasets and sophisticated fashions.
- Moreover, autoencoders could also be vulnerable to overfitting, the place the mannequin learns to seize noise or different artifacts within the coaching knowledge that don’t generalize nicely to new knowledge.
Actual-world Purposes of Autoencoders
The next checklist reveals duties solved with autoencoder within the present analysis literature:
| Process | Description | Papers | Share |
|---|---|---|---|
| Anomaly Detection | Figuring out knowledge factors that deviate from the norm | 39 | 6.24% |
| Picture Denoising | Eradicating noise from corrupted knowledge | 27 | 4.32% |
| Time Sequence | Analyzing and predicting sequential knowledge | 21 | 3.36% |
| Self-Supervised Studying | Studying representations from unlabeled knowledge | 21 | 3.36% |
| Semantic Segmentation | Segmenting a picture into significant components | 16 | 2.56% |
| Disentanglement | Separating underlying elements of variation | 14 | 2.24% |
| Picture Technology | Producing new photographs from discovered distributions | 14 | 2.24% |
| Unsupervised Anomaly Detection | Figuring out anomalies with out labeled knowledge | 12 | 1.92% |
| Picture Classification | Assigning an enter picture to a predefined class | 10 | 1.60% |

Autoencoder Pc Imaginative and prescient Purposes
Autoencoders have been utilized in varied laptop imaginative and prescient purposes, together with picture denoising, picture compression, picture retrieval, and picture technology. For instance, in medical imaging, autoencoders have been used to enhance the standard of MRI photographs by eradicating noise and artifacts.
Different issues that may be solved with autoencoders embrace facial recognition, anomaly detection, or function detection. Visible anomaly detection is vital in lots of purposes, equivalent to AI prognosis help in healthcare, and high quality assurance in industrial manufacturing purposes.
In laptop imaginative and prescient, autoencoders are additionally extensively used for unsupervised function studying, which will help enhance the accuracy of supervised studying fashions. For extra, learn our article about supervised vs. unsupervised studying.

Picture technology with Autoencoders
Variational autoencoders, particularly, have been used for picture technology duties, equivalent to producing life like photographs of faces or landscapes. By sampling from the latent area, variational autoencoders can produce an infinite variety of new photographs which might be much like the coaching knowledge.
For instance, the favored generative machine studying mannequin DALL-E makes use of a variational autoencoder for AI picture technology. It consists of two parts, an autoencoder, and a transformer. The discrete autoencoder learns to precisely signify photographs in a compressed latent area and the transformer learns the correlations between languages and the discrete picture illustration.

Future and Outlook
Autoencoders have great potential in laptop imaginative and prescient, and ongoing analysis is exploring methods to beat their limitations. For instance, new regularization methods, equivalent to dropout and batch normalization, will help forestall overfitting.
Moreover, developments in AI {hardware}, equivalent to the event of specialised {hardware} for neural networks, will help enhance the scalability of autoencoder fashions.
In Pc Imaginative and prescient Analysis, groups are consistently creating new strategies to cut back overfitting, enhance effectivity, enhance interpretability, enhance knowledge augmentation, and increase autoencoders’ capabilities to extra advanced duties.
Conclusion
In conclusion, autoencoders are versatile and highly effective device in machine studying, with various purposes in laptop imaginative and prescient. They’ll mechanically study advanced options from enter knowledge, and extract helpful data by means of dimensionality discount.
Whereas autoencoders have limitations equivalent to computational expense and potential overfitting, they provide vital advantages over conventional function extraction strategies. Ongoing analysis is exploring methods to enhance autoencoder fashions, together with new regularization methods and {hardware} developments.
Autoencoders have great potential for future growth, and their capabilities in laptop imaginative and prescient are solely anticipated to increase.
Examine associated matters and weblog articles: