

Generative fashions are machine studying algorithms that may create new information much like present information. Picture modifying is a rising use of generative fashions; it entails creating new pictures or modifying present ones. We’ll begin by defining a couple of vital phrases:
GAN Inversion → Given an enter picture $x$, we infer a latent code w, which is used to reconstruct $x$ as precisely as potential when forwarded by the generator $G$.
Latent Area Manipulation → For a given latent code $w$, we infer a brand new latent code, $w’$, such that the synthesized picture $G(w’)$ portrays a semantically significant edit of $G(w)$
To change a picture utilizing a pre-trained picture era mannequin, we would wish to first invert the enter picture into the latent house. To efficiently invert a picture one must discover a latent code that reconstructs the enter picture precisely and permits for its significant manipulation. There are 2 elements of high-quality inversion strategies:
The generator ought to correctly reconstruct the given picture with the fashion code obtained from the inversion. With the intention to decide if there was a correct reconstruction of a picture we concentrate on 2 properties:
- Distortion: that is the per-image input-output similarity
- Perceptual high quality: it is a measure of the photorealism of a picture
- Editability: it must be potential to greatest leverage the modifying capabilities of the latent house to acquire significant and real looking edits of the given picture
Inversion strategies function within the other ways highlighted under:
- Studying an encoder that maps a given picture to latent house (e.g. an autoencoder) → This methodology is quick, however it struggles to generalize past the coaching methodology
- Choose an preliminary random latent code, and optimize it utilizing gradient descent to reduce the error for the given picture
- Utilizing a hybrid strategy combining each aforementioned strategies
Optimizing the latent vector achieves low distortion, however it takes an extended time to invert the picture and the photographs are much less editable (tradeoff with editability).
With the intention to discover a significant path within the high-dimensional latent house, latest works have proposed:
- Having one latent vector dealing with the id, and one other vector dealing with the pose, expression, and illumination of the picture.
- Taking a low-resolution picture and looking out the latent house for a high-resolution model of the picture utilizing direct optimization.
- Performing image-to-image translation by straight encoding enter pictures into the latent codes representing the specified transformation.
On this weblog put up, I’ll assessment among the landmark GAN inversion strategies that influenced the present generative fashions in the present day. A number of these strategies reference StyleGAN; it’s because it has had a monumental affect within the picture era area. Recall that StyleGAN consists of a mapping operate that maps a latent code z into a method code w and a generator that takes within the fashion code, replicates it a number of instances relying on the specified decision, after which generates a picture.
1. Encoder for Enhancing (E4E)
The e4e encoder is particularly designed to output latent codes that guarantee additional modifying past the fashion house, $S$. On this mission, they describe the distribution of the W latent house because the vary of the mapping operate. As a result of it’s not possible to invert each actual picture into StyleGAN’s latent house, the expressiveness of the generator will be elevated by inputting okay totally different fashion codes as a substitute of a single vector. okay is the variety of fashion inputs of the generator. This new house is called $W^okay$. Much more expressive energy will be achieved by inputting fashion codes which are exterior the vary of StyleGAN’s mapping operate. This extension will be utilized by taking a single fashion code and changing it, or taking okay totally different fashion codes. These extensions are denoted by $W_$ and $W^okay$ respectively. (The favored $W+$ house is just $W^{okay=18}$).
Distortion-Editability & Distortion-Notion Tradeoff
$W_^okay$ achieves decrease distortion than W which is extra editable. W is extra ‘well-behaved’ and has higher perceptual high quality in comparison with $W_^okay$. Nevertheless, the mixed results of the upper dimensionality of $W_*^okay$ and the robustness of the StyleGAN structure have far larger expressive energy. These tradeoffs are managed by the proximity to W. On this mission, they differentiate between totally different areas of the latent house.
How Did They Design Their Encoder?
They design an encoder that infers latent codes within the house of $W_^okay$. They design two ideas that be sure that the encoder maps into areas in $W_^okay$ that lie near $W$. These embrace:
- Limiting the Variance Between the Completely different Type Codes (encouraging them to be similar)
To attain this they use a progressive coaching scheme. Widespread encoders are educated to study every latent code $w_i$ individually and concurrently by mapping from the picture straight into the latent house $W_^okay$. Conversely, this encoder infers a single latent code $w$, and a set of offsets from $w$ for the totally different inputs. Firstly of coaching the encoder is educated to deduce a single $W_$ code. The community then progressively grows to study totally different $triangle_i$ for every $i$ sequentially. With the intention to explicitly drive proximity to $W_*$, we add an $L_2$ delta-regularization loss - Minimizing Deviation From $W^okay$
To encourage the person fashion codes to lie inside the precise distribution of $W$, they undertake a latent discriminator (educated adversarially) to discriminate actual samples from the W house (from StyleGAN’s mapping operate) and the encoder’s discovered latent codes.
This latent discriminator addresses the problem of studying to deduce latent codes that belong to a distribution that can not be explicitly modeled. The discriminator encourages the encoder to deduce latent codes that lie inside $W$ versus $W_*$.
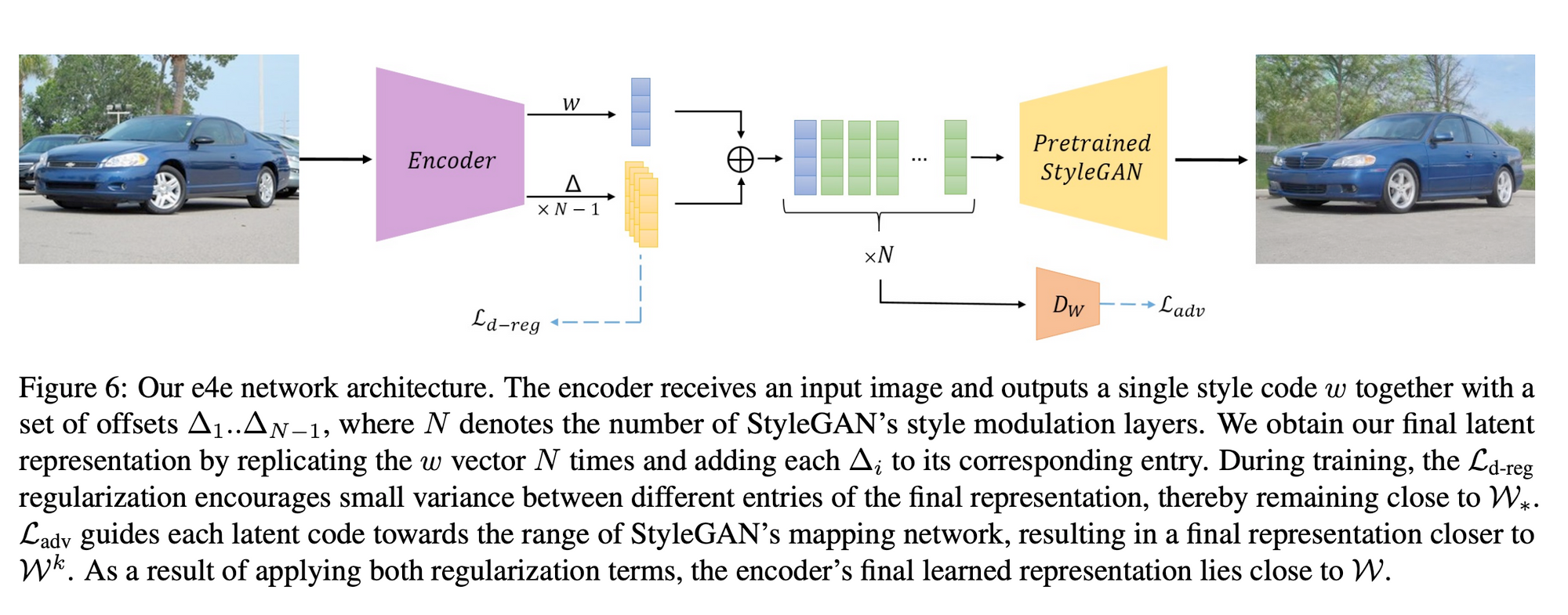
Though this encoder is impressed by the Pixel2Pixel (pSp) encoder which outputs N fashion codes in parallel, it solely outputs a single base fashion code and a sequence of $N-1$ offset vectors. The offsets are summed up with the bottom fashion code to get the ultimate N fashion codes that are then fed right into a pretrained StyleGAN2 generator to acquire the reconstructed picture.
Losses
They prepare the encoder with losses that guarantee low distortion, and losses that explicitly encourage the generated fashion codes to stay near $W$, thereby growing the perceptual high quality and editability of the generated pictures.
- Distortion:
With the intention to keep low distortion, they concentrate on id loss – which is particularly designed to help within the correct inversion of actual pictures within the facial area. Impressed by the id loss, they created a novel loss operate, $textbf{L_{sim}}$ to search out the cosine similarity between the characteristic embeddings of the reconstructed picture and its supply picture. They use a ResNet-50 community educated on MOCOv2 to extract the characteristic vectors of the supply and reconstructed picture.
Along with the $L_{sim}$ loss in addition they implement the $textbf{L_2}$ loss and the LPIPS loss operate to measure structural similarities between each pictures. The summation of those 3 leads to the finalized distortion loss. - Perceptual High quality and Editability:
They apply a delta-regularization loss to make sure proximity to $W_*$ when studying the offsets $triangle_i$. Additionally they use an adversarial loss utilizing our latent discriminator, which inspires every discovered fashion code to lie inside the distribution $W$.
2. Image2StyleGAN
On this mission, the authors explored the sensitivity of StyleGAN embeddings to affine transformations (translation, resizing, and rotation), and concluded that these transformations have a degrading impact on the generated pictures e.g blurring and degradation of finer particulars.
When evaluating the totally different latent areas Z and W, the authors famous that it was difficult to embed pictures into W or Z straight. They proposed to embed into an prolonged latent house, coined W + . W + is a concatenation of 18 totally different 512-dimensional w vectors, one for every layer of the StyleGAN structure, that may every obtain enter through AdaIn. This enabled a lot of helpful capabilities from the beforehand extra inflexible, albeit highly effective, structure.
Picture Morphing → Given two embedded pictures with their respective la- tent vectors w1 and w2, morphing is computed by linear interpolation, $w = λw1 + (1 − λ)w2, λ ∈ (0, 1)$, and subsequent picture era utilizing the brand new code w to successfully add perceptual modifications to the output.
Type Switch → Given two latent codes w1 and w2, fashion switch is computed by a crossover operation. They apply one latent code for the primary 9 layers and one other code for the final 9 layers. StyleGAN is ready to switch the low-level options i.e. shade and texture, however fails on duties transferring the contextual construction of the picture.
Expression Transformation → Given three enter vectors $w1,w2,w3$, expression switch is computed as $w=w1+λ(w3−w2)$:
- $w1$: latent code of the goal picture
- $w2$: corresponds to a impartial expression of the supply picture
- $w3$: corresponds to a extra distinct expression
To eradicate the noise (e.g. background noise), they heuristically set a decrease sure threshold on the $L_2$− norm of the channels of distinction latent code, under which, the channel is changed by a zero vector.
How Do We Embed an Picture Into W+?
Ranging from an acceptable initialization $w$, we seek for an optimized vector $w∗$ that minimizes the loss operate that measures the similarity between the given picture and the picture generated from $w∗$.
3. StyleCLIP
This mission goals to offer a extra intuitive methodology for picture modifying within the latent house. The authors observe that prior picture manipulation methods relied on manually analyzing the outcomes, an extensively annotated dataset, and pre-trained classifiers (like in Type Area). One other observe is that it’s only potential to have picture manipulations alongside a preset semantic path which is limiting to a consumer’s creativity.
They proposed a couple of methods to assist obtain this aim:
- Textual content-guided latent optimization the place the CLIP mannequin is used as a loss community
- A latent residual mapper, educated for a selected textual content immediate → When given a place to begin within the latent house, the mapper yields a neighborhood step in latent house
- A way for mapping a textual content immediate into an input-agnostic path in StyleGAN’s fashion house, offering management over the manipulation energy in addition to the diploma of disentanglement
Technique 1: Latent Optimization
Given a supply code $w in W+$, and a directive in pure language, or a textual content immediate t, they generated a picture from $G(w)$, after which discovered the cosine distance between the CLIP embeddings of the 2 arguments offered to the discriminator $D(G(w),t)$.
The similarity of the generated picture to the enter picture is managed by the $L_2$ distance within the latent house and by the id loss. $R$ is a pre-trained ArcFace community for face recognition, and the operation $langle R(G(w_S)), R(G(w)) rangle$ computes the cosine similarity between its arguments.
They confirmed they might optimize this downside utilizing gradient descent by back-propagating the gradient of the adversarial goal operate, by the mounted StyleGAN generator and the CLIP picture encoder.
For this methodology, the enter pictures are inverted into the $W+$ house utilizing the e4e encoder. Visible modifications that extremely edit the picture have a decrease id rating, however could have a secure or excessive CLIP cosine rating.
This modifying methodology is flexible as a result of it optimizes for every text-image pair, however it takes a number of minutes to optimize for a single pattern. Moreover, it is rather delicate to the values in its parameters.
Technique 2: Latent Residual Mapper
On this methodology, a mapping community is educated for a selected textual content immediate t, to deduce a manipulation step $M_t(w)$ within the $W+$ house for any given latent picture embedding.
Primarily based on the design of the StyleGAN generator, whose layers comprise totally different ranges of particulars (coarse, medium, high quality), the authors design their mapper community accordingly with three absolutely linked networks for every degree of element. The networks can be utilized in unison or solely a subset can be utilized.
The loss operate ensures that the attributes are manipulated based on the textual content immediate whereas sustaining the opposite visible attributes of the picture. They use the CLIP loss to measure the faithfulness to the textual content immediate, they usually use the $L_2$ distance to measure the id loss besides when the edit is supposed to alter the id loss.
The mapper determines a customized manipulation step for every enter picture, and subsequently determines the extent to which the path of the step varies over totally different inputs.
To check this mapper:
- They inverted the CelebA check set utilizing the e4e encoder to acquire the latent vectors and handed these vectors into a number of educated mappers.
- They computed the cosine similarity between all pairs of the ensuing manipulation instructions (The pairs talked about listed below are the enter textual content immediate and the edited picture)
- The cosine similarity rating has a considerably excessive that means. Sufficient that, though the mapper infers manipulation steps which are tailored to the enter picture, the instructions given for the coaching picture will not be that totally different from the instructions given for the check picture. No matter the place to begin (enter picture), the path of the manipulation step for every textual content immediate is basically the identical for all inputs.
- There isn’t loads of variation on this methodology though the inference time tends to be quick (it is a slight drawback). Due to the shortage of variation in manipulation instructions, the mapper additionally doesn’t do too properly with fine-frained disentangled manipulation.
Technique 3: International Mapper
They suggest a way for mapping a single textual content immediate right into a single, international path in StyleGAN’s Type Area $S$ which is probably the most disentangled latent house. Given a textual content immediate indicating a desired attribute, they sought a manipulation path $∆s$, such that $G(s + α∆s)$ yielded a picture the place that attribute is launched or amplified, with out considerably affecting different attributes. In consequence, the situation and id loss are low. They used the time period $alpha$ to indicate the manipulation energy
Easy methods to Create a International Mapper?
- They used CLIP’s language encoder to encode the textual content edit instruction, and map this right into a manipulation path $∆s$ in $S$. To get a secure $∆t$ from pure language requires some degree of immediate engineering.
- With the intention to get $∆s$ from $∆t$, they’ll assess the relevance of every fashion channel to the goal attribute.
An vital observe that the authors make is that it’s potential for the textual content embedding and the picture embeddings to exist in numerous manifolds. A picture could comprise extra visible attributes than will be encoded by a single textual content immediate, and vice versa.
Though there isn’t a selected mapping between the textual content and picture manifolds the instructions of change inside the CLIP house for a text-image pair are roughly collinear (Giant cosine similarity) after normalizing their vectors.
- Given a pair of pictures $G(s) textual content{ and } G(s+α∆s)$, they denote their picture embeddings $I$ as $i textual content{ and } i + ∆i$ respectively, the distinction between the 2 pictures within the CLIP house is $triangle i$.
- Given a textual content instruction $triangle t$ and assuming collinearity between $triangle t$ and $triangle i$, we will decide a manipulation path $triangle s$ by assessing the relevance of every channel in $S$ to the path $triangle i$.
Easy methods to Yield a Type Area $S$ Manipulation Course $triangle s$?
- The aim is to assemble a method house manipulation path $triangle s$ that may yield a change $triangle i$ that’s collinear with the goal path $triangle t$
- They assessed the relevance of every channel $c$ of $S$ to a given path $triangle i$ in CLIP’s becoming a member of embedding house
- They denoted the CLIP house path between the photographs $triangle i$ as $triangle i_c$. Due to this fact, the relevance of channel c to the goal manipulation, $R_c(triangle i)$ was proven because the imply projection of $triangle i_c textual content{ onto } triangle i$
- As soon as they estimated the relevance of every channel $R_c$, they might ignore the channels whose $R_c$ falls under a sure threshold $beta$
- The $beta$ variable is used to regulate the diploma of disentangled manipulation → Utilizing greater threshold values leads to extra disentangled manipulations, however on the similar time, the visible impact of the manipulation is decreased.
Instance of this from the paper 🔽

Abstract
There are a lot of extra strategies which were proposed for GAN picture inversion, nonetheless, I hope that the few highlighted on this article get you within the rhythm of understanding some fundamentals of picture inversion. An awesome subsequent step can be understanding how picture styling info is embedded into the diffusion course of within the state-of-the-art diffusion fashions and contrasting that with GAN inversion.