

This text will talk about Depth Something V2, a sensible resolution for strong monocular depth estimation. Depth Something mannequin goals to create a easy but highly effective basis mannequin that works nicely with any picture below any circumstances. The dataset was considerably expanded utilizing a knowledge engine to gather and routinely annotate round 62 million unlabeled photographs to realize this. This massive-scale knowledge helps scale back generalization errors.
This highly effective mannequin makes use of two key methods to make the info scaling efficient. First, a more difficult optimization goal is about utilizing knowledge augmentation instruments, which pushes the mannequin to be taught extra strong representations. Second, auxiliary supervision is added to assist the mannequin inherit wealthy semantic information from pre-trained encoders. The mannequin’s zero-shot capabilities had been extensively examined on six public datasets and random images, displaying spectacular generalization means.
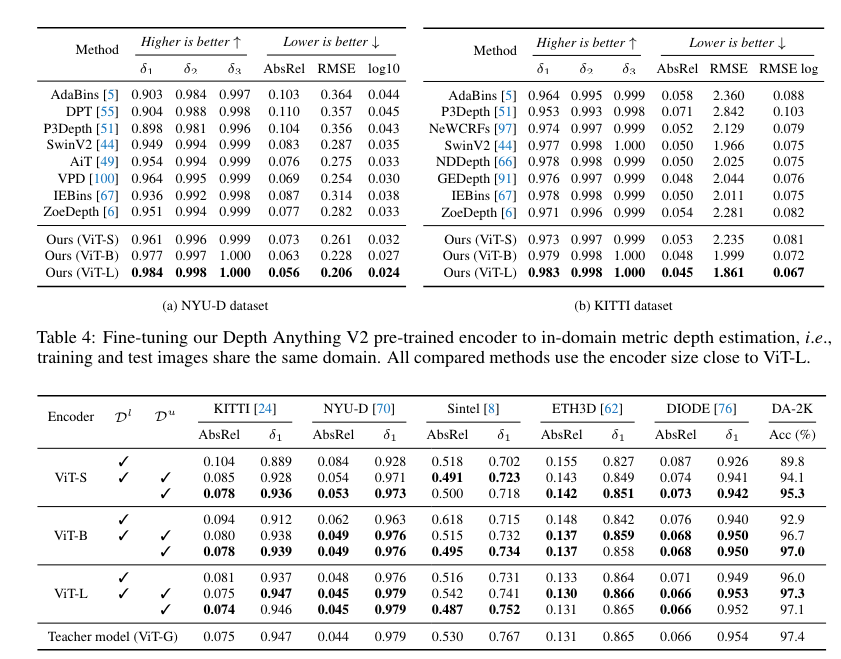
High quality-tuning with metric depth info from NYUv2 and KITTI has additionally set new state-of-the-art benchmarks. This improved depth mannequin additionally enhances depth-conditioned ControlNet considerably.
Associated Works on Monocular Depth Estimation (MDE)
Current developments in monocular depth estimation have shifted in direction of zero-shot relative depth estimation and improved modeling strategies like Secure Diffusion for denoising depth. Works equivalent to MiDaS and Metric3D have collected thousands and thousands of labeled photographs, addressing the problem of dataset scaling. Depth Something V1 enhanced robustness by leveraging 62 million unlabeled photographs and highlighted the restrictions of labeled actual knowledge, advocating for artificial knowledge to enhance depth precision. This strategy integrates large-scale pseudo-labeled actual photographs and scales up trainer fashions to sort out generalization points from artificial knowledge. In semi-supervised studying, the main target has moved to real-world purposes, aiming to reinforce efficiency by incorporating giant quantities of unlabeled knowledge. Information distillation on this context emphasizes transferring information by prediction-level distillation utilizing unlabeled actual photographs, showcasing the significance of large-scale unlabeled knowledge and bigger trainer fashions for efficient information switch throughout totally different mannequin scales.
Strengths of the Mannequin
The analysis goals to assemble a flexible analysis benchmark for relative monocular depth estimation that may:-
1) Present exact depth relationship
2) Cowl intensive scenes
3) Comprises principally high-resolution photographs for contemporary utilization.
The analysis paper additionally goals to construct a basis mannequin for MDE that has the next strengths:
- Ship strong predictions for complicated scenes, together with intricate layouts, clear objects like glass, and reflective surfaces equivalent to mirrors and screens.
- Seize tremendous particulars within the predicted depth maps, corresponding to the precision of Marigold, together with skinny objects like chair legs and small holes.
- Supply a variety of mannequin scales and environment friendly inference capabilities to help varied purposes.
- Be extremely adaptable and appropriate for switch studying, permitting for fine-tuning downstream duties. As an illustration, Depth Something V1 has been the pre-trained mannequin of selection for all main groups within the third MDEC1.
What’s Monocular Depth Estimation (MDE)?
Monocular depth estimation is a approach to decide how far-off issues are in an image taken with only one digicam.

Think about taking a look at a photograph and with the ability to inform which objects are near you and which of them are far-off. Monocular depth estimation makes use of pc algorithms to do that routinely. It seems to be at visible clues within the image, like the scale and overlap of objects, to estimate their distances.
This expertise is beneficial in lots of areas, equivalent to self-driving automobiles, digital actuality, and robots, the place it is necessary to know the depth of objects within the surroundings to navigate and work together safely.
The 2 most important classes are:
- Absolute depth estimation: This activity variant, or metric depth estimation, goals to supply actual depth measurements from the digicam in meters or toes. Absolute depth estimation fashions produce depth maps with numerical values representing real-world distances.
- Relative depth estimation: Relative depth estimation predicts the relative order of objects or factors in a scene with out offering actual measurements. These fashions produce depth maps that present which elements of the scene are nearer or farther from one another with out specifying the distances in meters or toes.
Mannequin Framework
The mannequin pipeline to coach the Depth Something V2, contains three main steps:
- Coaching a trainer mannequin that’s primarily based on DINOv2-G encoder on high-quality artificial photographs.
- Producing correct pseudo-depth on large-scale unlabeled actual photographs.
- Coaching a remaining scholar mannequin on the pseudo-labeled actual photographs for strong generalization.
Right here’s an easier clarification of the coaching course of for Depth Something V2:
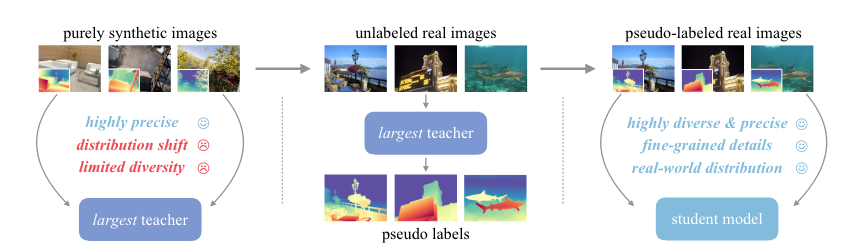
- Mannequin Structure: Depth Something V2 makes use of the Dense Prediction Transformer (DPT) because the depth decoder, which is constructed on high of DINOv2 encoders.
- Picture Processing: All photographs are resized so their shortest facet is 518 pixels, after which a random 518×518 crop is taken. To be able to standardize the enter measurement for coaching.
- Coaching the Instructor Mannequin: The trainer mannequin is first educated on artificial photographs. On this stage:
- Batch Dimension: A batch measurement of 64 is used.
- Iterations: The mannequin is educated for 160,000 iterations.
- Optimizer: The Adam optimizer is used.
- Studying Charges: The training fee for the encoder is about to 5e-6, and for the decoder, it is 5e-5.
- Coaching on Pseudo-Labeled Actual Pictures: Within the third stage, the mannequin is educated on pseudo-labeled actual photographs generated by the trainer mannequin. On this stage:
- Batch Dimension: A bigger batch measurement of 192 is used.
- Iterations: The mannequin is educated for 480,000 iterations.
- Optimizer: The identical Adam optimizer is used.
- Studying Charges: The training charges stay the identical as within the earlier stage.
- Dataset Dealing with: Throughout each coaching levels, the datasets are usually not balanced however are merely concatenated, which means they’re mixed with none changes to their proportions.
- Loss Perform Weights: The burden ratio of the loss capabilities Lssi (self-supervised loss) and Lgm (floor reality matching loss) is about to 1:2. This implies Lgm is given twice the significance in comparison with Lssi throughout coaching.
This strategy helps make sure that the mannequin is powerful and performs nicely throughout several types of photographs.
To confirm the mannequin efficiency the Depth Something V2 mannequin has been in comparison with Depth Something V1 and MiDaS V3.1 utilizing 5 take a look at dataset. The mannequin comes out superior to MiDaS. Nevertheless, barely inferior to V1.
Paperspace Demonstration
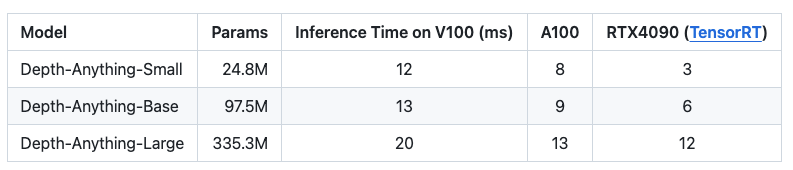
Depth Something affords a sensible resolution for monocular depth estimation; the mannequin has been educated on 1.5M labeled and over 62M unlabeled photographs.
The listing beneath comprises mannequin particulars for depth estimation and their respective inference occasions.
For this demonstration, we’ll suggest using an NVIDIA RTX A4000. The NVIDIA RTX A4000 is a high-performance skilled graphics card designed for creators and builders. The NVIDIA Ampere structure options 16GB of GDDR6 reminiscence, 6144 CUDA cores, 192 third-generation tensor Cores, and 48 RT cores. The RTX A4000 delivers distinctive efficiency in demanding workflows, together with 3D rendering, AI, and knowledge visualization, making it a great selection for structure, media, and scientific analysis professionals.
Paperspace additionally affords highly effective H100 GPUs. To get essentially the most out of Depth Something and your Digital Machine, we suggest recreating this on a Paperspace by DigitalOcean Core H100 Machine.
Convey this venture to life
Allow us to run the code beneath to examine the GPU
!nvidia-smi
Subsequent, clone the repo and import the required libraries.
from PIL import Picture
import requests!git clone https://github.com/LiheYoung/Depth-Somethingcd Depth-SomethingSet up the necessities.txt file.
!pip set up -r necessities.txt!python run.py --encoder vitl --img-path /notebooks/Picture/picture.png --outdir depth_visArguments:
--img-path: 1) specify a listing containing all the specified photographs, 2) specify a single picture, or 3) specify a textual content file that lists all of the picture paths.- Setting
--pred-onlysaves solely the expected depth map. With out this feature, the default conduct is to visualise the picture and depth map facet by facet. - Setting
--grayscalesaves the depth map in grayscale. With out this feature, a shade palette is utilized to the depth map by default.
If you wish to use Depth Something on movies:
!python run_video.py --encoder vitl --video-path belongings/examples_video --outdir video_depth_visRun the Gradio Demo:-
To run the gradio demo domestically:-
!python app.pyObserve: For those who encounter KeyError: ‘depth_anything’, please set up the newest transformers from supply:
!pip set up git+https://github.com/huggingface/transformers.gitListed here are just a few examples demonstrating how we utilized the depth estimation mannequin to investigate varied photographs.

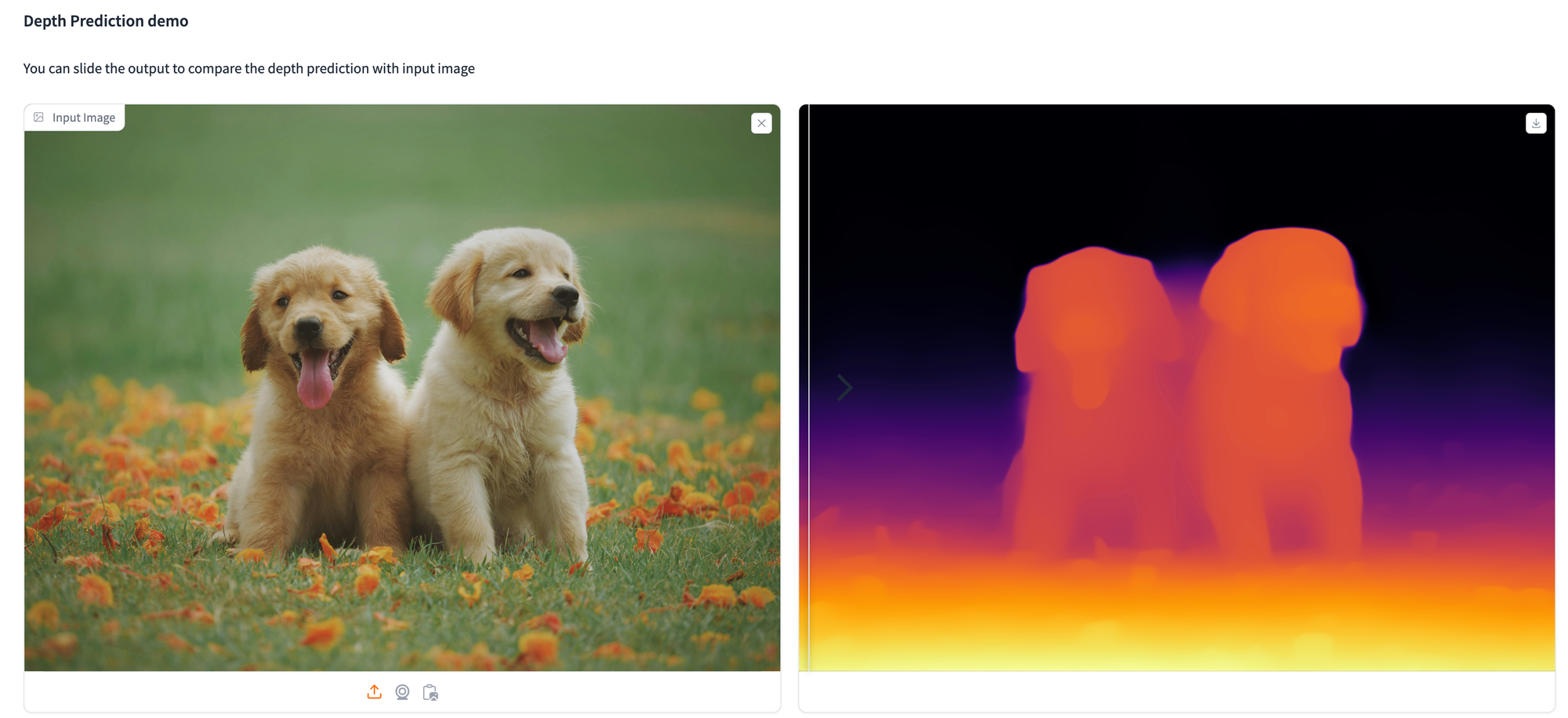
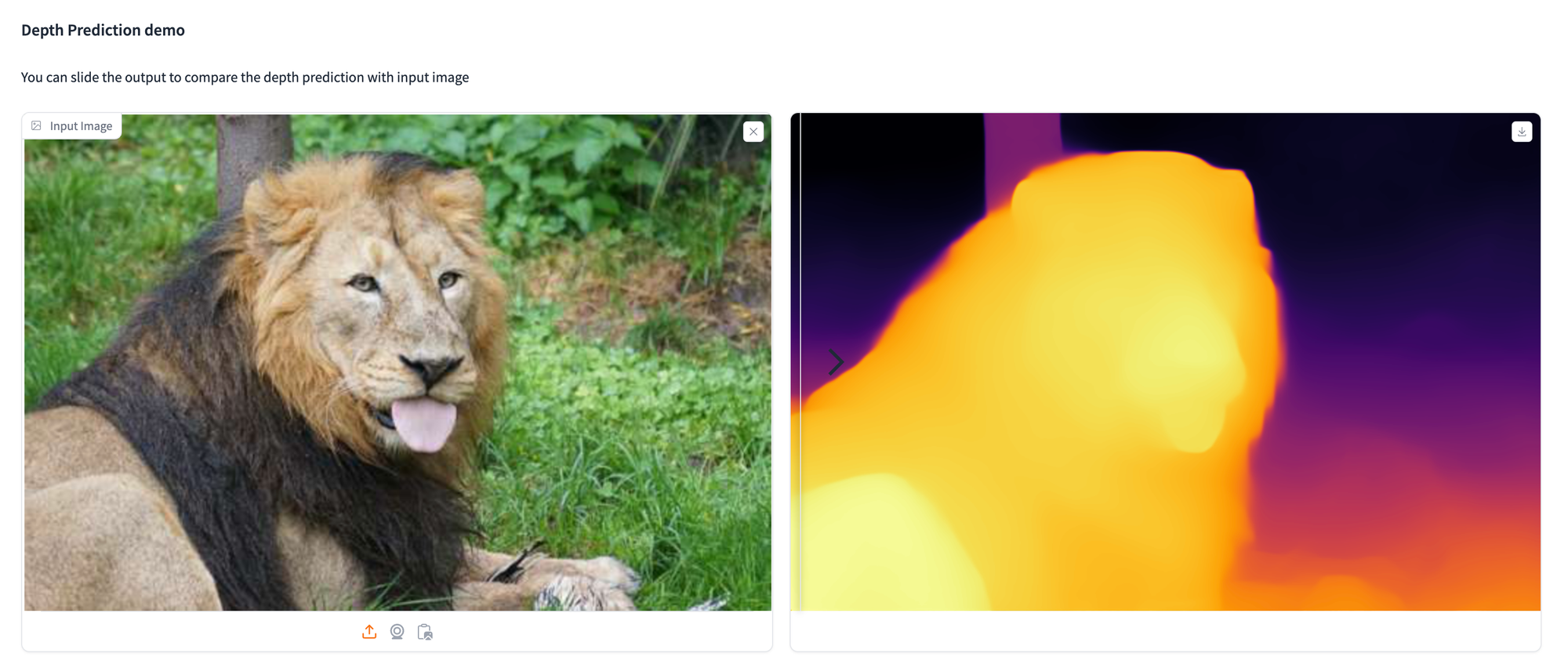
Options of the Mannequin
The fashions supply dependable relative depth estimation for any picture, as indicated within the above photographs. For metric depth estimation, the Depth Something mannequin is finetuned utilizing the metric depth knowledge from NYUv2 or KITTI, enabling sturdy efficiency in each in-domain and zero-shot eventualities. Particulars will be discovered right here.
Moreover, the depth-conditioned ControlNet is re-trained primarily based on Depth Something, providing a extra exact synthesis than the earlier MiDaS-based model. This new ControlNet can be utilized in ControlNet WebUI or ComfyUI’s ControlNet. The Depth Something encoder may also be fine-tuned for high-level notion duties equivalent to semantic segmentation, attaining 86.2 mIoU on Cityscapes and 59.4 mIoU on ADE20K. Extra info is offered right here.
Purposes of Depth Something Mannequin
Monocular depth estimation has a variety of purposes, together with 3D reconstruction, navigation, and autonomous driving. Along with these conventional makes use of, fashionable purposes are exploring AI-generated content material equivalent to photographs, movies, and 3D scenes. DepthAnything v2 goals to excel in key efficiency metrics, together with capturing tremendous particulars, dealing with clear objects, managing reflections, deciphering complicated scenes, guaranteeing effectivity, and offering sturdy transferability throughout totally different domains.
Concluding Ideas
Depth Something V2 is launched as a extra superior basis mannequin for monocular depth estimation. This mannequin stands out as a consequence of its capabilities in offering highly effective and fine-grained depth prediction, supporting varied purposes. The depth something mannequin sizes ranges from 25 million to 1.3 billion parameters, and serves as a wonderful base for fine-tuning in downstream duties.
Future Traits:
- Integration with Different AI Applied sciences: Combining MDE fashions with different AI applied sciences like GANs (Generative Adversarial Networks) and NLP (Pure Language Processing) for extra superior purposes in AR/VR, robotics, and autonomous techniques.
- Broader Software Spectrum: Increasing using monocular depth estimation in areas equivalent to medical imaging, augmented actuality, and superior driver-assistance techniques (ADAS).
- Actual-Time Depth Estimation: Developments in direction of attaining real-time depth estimation on edge gadgets, making it extra accessible and sensible for on a regular basis purposes.
- Cross-Area Generalization: Growing fashions that may generalize higher throughout totally different domains with out requiring intensive retraining, enhancing their adaptability and robustness.
- Consumer-Pleasant Instruments and Interfaces: Creating extra user-friendly instruments and interfaces that permit non-experts to leverage highly effective MDE fashions for varied purposes.