

Get began with Steady Diffusion on Paperspace’s Free GPUs!
We all know that machine studying is a subfield of synthetic intelligence by which we prepare laptop algorithms to be taught patterns within the coaching knowledge so as to make selections on unseen knowledge. Machine studying has paved the way in which for duties like picture classification, object detection and segmentation inside pictures, and just lately picture era. The duty of picture era falls underneath the artistic side of laptop imaginative and prescient. It includes creating algorithms that synthesize picture knowledge that mimics the distribution of actual picture knowledge {that a} machine studying mannequin was educated on. Picture era fashions are educated in an unsupervised style which results in fashions which are extremely skewed towards discovering patterns within the knowledge distribution with out the necessity to think about a proper or unsuitable reply. Because of this, there is no such thing as a specific right reply, or on this case picture, relating to evaluating the generated pictures. As people, now we have an inherent algorithm that we will use to judge the standard of a picture. If I offered the 2 pictures under and requested you, “Which of those pictures seems to be higher?”, you’d reply by saying “A” or “B” based mostly on the completely different appeals of every picture.

Suppose I requested you, “Which of the pictures under seems to be extra real looking?” You would choose “A” or “B” based mostly on whichever picture reminded you extra of somebody or one thing you could have seen earlier than in actual life.

For the ultimate query I may ask, “Which of those pictures seems to be extra just like the reference picture?”. Once more you’d reply by saying “A” or “B” based mostly on what you deemed as an important points of the reference picture and discovering the picture with the least variations alongside these very points.

In all the questions above I’ve requested in regards to the unbiased picture high quality, the picture high quality with respect to the true world, and the picture high quality with respect to a reference. These are the three completely different points that researchers think about when making an attempt to judge the correctness of generated pictures. Whereas answering the questions above you may need considered numerous picture options when deciding on your chosen reply. It may need been variations in mild depth, the sharpness or lack thereof of the traces, the symmetry within the content material objects, or the blurriness of the thing backgrounds. All of those are legitimate options to level out whereas highlighting picture similarity or dissimilarity. As people we will use pure language to speak, “that image seems to be means off” or “the feel on that particular person’s pores and skin appeared eerie”. In relation to laptop imaginative and prescient algorithms, we’d like a technique to quantify the variations between generated pictures and actual pictures in a means that corresponds with human judgment. On this article, I’ll spotlight a few of these metrics which are generally used within the area right now.
Observe: I assume that the viewers has a high-level familiarity with generative fashions.
CONTENT VARIANT METRICS
These are metrics which are helpful when the generated picture can take completely different content material objects per enter noise vector. Because of this there is no such thing as a proper reply.
Inception Rating (IS)
The inception rating is a metric designed to measure the picture high quality and variety of generated pictures. It was initially created as an goal metric for generative adversarial networks (GAN). So as to measure the picture high quality, generated pictures are fed right into a pretrained picture classifier community so as to acquire the likelihood rating for every class. If the likelihood scores are broadly distributed then the generated picture is of low high quality. The instinct right here is that if there’s a excessive likelihood that the picture may belong to a number of courses, then the mannequin can not clearly outline what object is contained within the picture. A large likelihood distribution is often known as “excessive entropy”. What we intention for is low entropy. Within the unique paper, the generated pictures are fed right into a pretrained picture classifier community (InceptionNet) which was educated on the CIFAR10 dataset.
$entropy = -sum(p_icdot log(p_i))$
Frechet Inception Distance (FID)
Not like the Inception Rating, the FID compares the distribution of generated pictures with the distribution of actual pictures. Step one includes calculating the characteristic vector of every picture in every area utilizing the InceptionNet v3 mannequin which is used for picture classification. FID compares the imply and commonplace deviation of the gaussian distributions containing characteristic vectors obtained from the deepest layer in Inception v3. Excessive-quality and extremely real looking pictures are inclined to have low FID scores that means that their low dimension characteristic vectors are extra just like these of actual pictures of the identical kind e.g faces to faces, birds to birds, and many others. The calculation is:
$d^2 = ||mu_1-mu_2||^2 + Tr(C_1 + C_2 – 2sqrt{C_1cdot C_2})$
Machine Studying Mastery did an awesome job explaining the completely different phrases:
- The “mu_1” and “mu_2” confer with the feature-wise imply of the true and generated pictures, e.g. 2,048 ingredient vectors the place every ingredient is the imply characteristic noticed throughout the pictures.
- The C_1 and C_2 are the covariance matrix for the true and generated characteristic vectors, also known as sigma.
- The ||mu_1 – mu_2||^2 refers back to the sum squared distinction between the 2 imply vectors. Tr refers back to the hint linear algebra operation, e.g. the sum of the weather alongside the primary diagonal of the sq. matrix.
- The sqrt is the sq. root of the sq. matrix, given because the product between the 2 covariance matrices.
The authors of the unique paper proved that FID was superior to the inception rating as a result of it was extra delicate to refined modifications within the picture i.e. gaussian blur, gaussian blur, salt & pepper noise, ImageNet contamination
Get began with Steady Diffusion on Paperspace’s Free GPUs!
CONTENT INVARIANT METRICS
These are metrics which are finest used when there is just one right reply for the content material within the pictures. An instance of a mannequin that makes use of these metrics is a NeRF mannequin which generates viewpoints for various viewpoints. For every viewpoint, there is just one acceptable notion of the objects within the scene. Utilizing content material invariant metrics you may inform whether or not a picture has noise that forestalls it from wanting like the bottom fact picture.
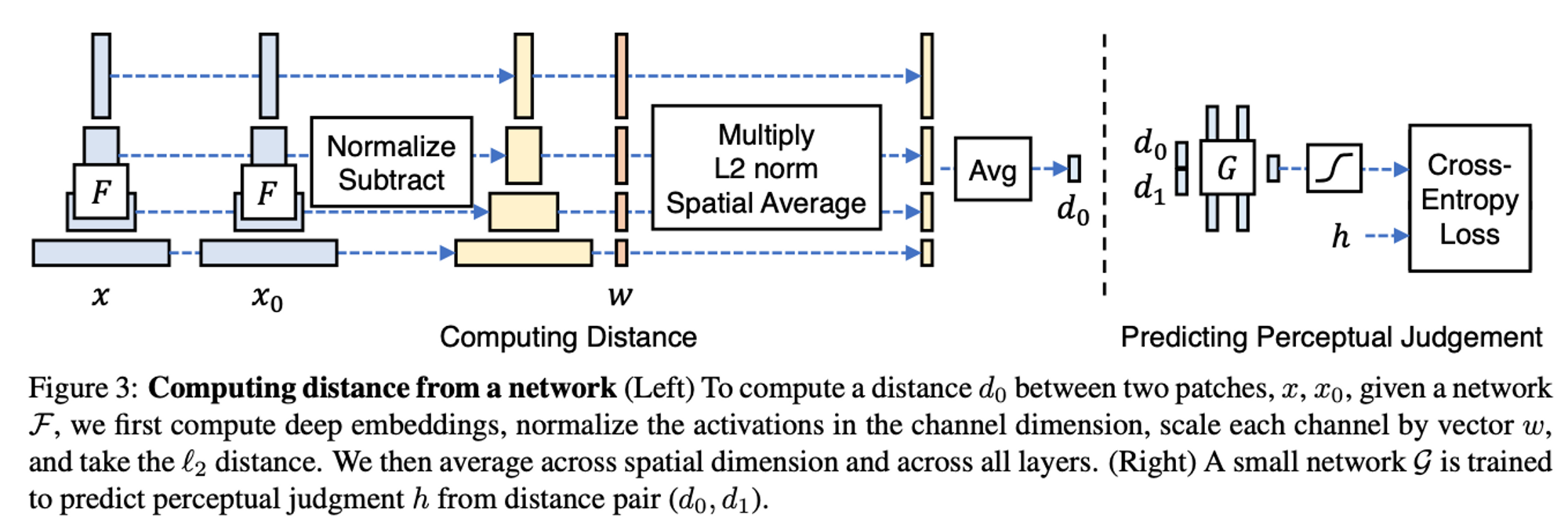
Realized Perceptual Picture Patch Similarity (LPIPS)
That is one other goal metric for calculating the structural similarity of high-dimensional pictures whose pixel values are contextually depending on each other. Like FID, LPIPS takes benefit of inner activations of deep convolutional networks due to their helpful representational skill for low-dimension vectors. Not like earlier metrics, LPIPS measures perceptual similarity versus high quality evaluation. LPIPS measures the space in VGGNet characteristic area as a “perceptual loss” for picture regression issues.
So as to use the deep options of a community to seek out the space $d_o$ between a reference $x$ and a pair of distorted patches $x_0, x_1$ given a community $F$ the authors make use of the next steps:
- compute deep embeddings by passing $x$ into $F$
- normalize the activations within the channel dimension
- scale every channel by vector $w$
- take the $l_2$ distance
Structured Similarity Index Metric (SSIM, MSSIM)
L2 Distance makes use of pixel variations to measure the structural variations between two pictures (pattern and reference). So as to outdo earlier strategies, the authors created a metric that mimicked the human visible notion system which is very able to figuring out structural data from a scene. The SSIM metric identifies 3 metrics from a picture: Luminance $l(x,y)$ , Distinction $c(x,y)$, and Construction $s(x,y)$. The specifics on easy methods to calculate the three particular person metrics is right here
$SSIM(x,y) = [l(x,y)]^{alpha}cdot[c(x,y)]^betacdot[s(x,y)]^gamma$
the place $alpha>0, beta> 0, gamma>0$ denote the relative significance of every of the metrics to simplify the expression
As an alternative of taking world measurements of the entire picture some implementations of SSIM take measurements of areas of the picture after which common out the scores. This methodology is called Imply Structural Similarity Index (MSSIM) and has confirmed to be extra sturdy.
$MSSIM(X,Y) = frac{1}{M}sum_{j=1}^{M}SSIM(x_j,y_j)$
Peak Sign-to-Noise Ratio (PSNR)
“Sign-to-noise ratio is a measure utilized in science and engineering that compares the extent of a desired sign to the extent of background noise. SNR is outlined because the ratio of sign energy to noise energy, typically expressed in decibels. A ratio larger than 1:1 signifies extra sign than noise” (Wikipedia) PSNR is often used to quantify reconstruction high quality for pictures and movies topic to lossy compression.
PSNR is calculated utilizing the imply squared error (MSE) or L2 distance as described under:
$PSNR = 20 cdot log_{10}( MAX_I) – 10 cdot log_{10}(MSE)$
$MAX_I$ is the utmost attainable pixel worth of the picture. a better PSNR usually signifies that the reconstruction is of upper high quality
Bringing all of it collectively
Content material variant metrics have the capability to judge the similarity/dissimilarity of pictures whose content material differs as a result of they make the most of deep characteristic representations of the pictures. The essence of those vectors is that they numerically inform us an important options related to a pattern picture. Inception Rating solutions the query “How real looking is that this picture relative to the pretrained mannequin?” as a result of it evaluates the conditional likelihood distribution which solely components within the coaching knowledge, the unique variety of courses, and the power of the Inception V3 mannequin.
FID is extra versatile and asks the query, “How comparable is that this group of pictures relative to this different group of pictures?” FID takes the deepest layer of the inception v3 mannequin versus the classifier output as in Inception Rating. On this case, you aren’t certain by the kind and variety of courses of the classifier. Whereas analyzing the FID method, I noticed that averaging the characteristic vectors to get the sum squared distance in $||mu_1-mu_2||^2$ implies that FID will seemingly be skewed if the distribution of any group (1 or 2) is just too large. As an illustration, if you’re evaluating pictures of fruits and each your ground-truth and generated datasets have a disproportionately great amount of orange footage relative to the opposite fruits, then FID is unlikely to focus on poorly generated strawberries and avocados. FID is plagued with the bulk guidelines problem relating to domains with excessive variation. Now fruits are trivial, however what occurs when you’re individuals’s faces or most cancers tumors?
The LPIPS metric is on the border of those content material variant/invariant metrics as a result of on one hand it makes use of deep options and could possibly be thought-about virtually a regional FID metric but it surely was designed for the aim of assessing structural similarity in “similar content-based“ pictures. LPIPS solutions the query, “Did the construction of this patch change, and by how a lot?” Whereas I is perhaps tempted to imagine that this metric may be capable to give us a fine-grained model of the FID rating, I’m afraid that my experiments from UniFace present that even with nice variations of FID the LPIPS rating exhibits little or no variation. Moreover, whereas LPIPS mentions that their patch-wise implementation mirrors the patchwise implementation of convolution, LPIPS doesn’t merge the output options of the patches of a picture as does the convolution activity with the characteristic vectors which are output. On this regard, LPIPS loses the worldwide context of the enter picture which FID captures.
Then again, content material invariant metrics are finest when used on pictures with the identical object content material. We’ve got seen from the completely different metrics above that some metrics measure structural variations between pictures on a pixel-wise foundation (PSNR, SSIM, MSSIM) whereas others accomplish that on a deep characteristic vector foundation (LPIPS). In each of those instances, the metrics concerned are evaluating pictures which have noise added to photographs which have a corresponding “clear” an identical model. These metrics can be utilized for supervised studying duties as a result of a floor fact exists. These metrics reply the query, “How noisy is that this generated picture as in comparison with the bottom fact picture?”
In pixel-wise metrics like PSNR, SSIM, & MSSIM, the metrics assume pixel independence which implies that they don’t think about the context of the picture. It might make sense to make use of these metrics when evaluating two pictures with the identical object contents by which one has some gaussian noise, however not two pictures of comparatively comparable pictures e.g two completely different footage of a lion within the Sahara.
So why did I embrace these metrics in the event that they aren’t helpful for many content material variant generative fashions? As a result of they’re used to coach NERF fashions to synthesize pictures of objects from completely different viewpoints. NERFs be taught on a static set of enter pictures and their corresponding views after which as soon as educated, the NERF can synthesize a picture from a brand new viewpoint with out entry to the ground-truth picture (if any).
Concluding ideas
In abstract, we will use the metrics above to reply the next questions on two teams of pictures:
Inception Rating: “How real looking is that this picture relative to the pretrained mannequin?”
FID Rating: “How comparable is that this group of pictures relative to this different group of pictures?”
LPIPS Rating: “Did the construction of this patch change, and by how a lot?”
SSIM, MSSIM, PSNR: “How noisy is that this generated picture as in comparison with the bottom fact picture?”
The utility of those metrics will differ based mostly on the character of the duty you might be dealing with.
CITATIONS:
- Salimans, Tim, et al. “Improved methods for coaching gans.” Advances in neural data processing techniques 29 (2016).APA
- Zhang, Richard, et al. “The unreasonable effectiveness of deep options as a perceptual metric.” Proceedings of the IEEE convention on laptop imaginative and prescient and sample recognition. 2018.
- Heusel, Martin, et al. “Gans educated by a two time-scale replace rule converge to an area nash equilibrium.” Advances in neural data processing techniques 30 (2017).
- Wang, Zhou, et al. “Picture high quality evaluation: from error visibility to structural similarity.” IEEE transactions on picture processing 13.4 (2004): 600-612.
- “Peak Sign-to-Noise Ratio.” Wikipedia, Wikimedia Basis, 22 Aug. 2022, https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio.
- Datta, Pranjal. “All about Structural Similarity Index (SSIM): Idea + Code in Pytorch.” Medium, SRM MIC, 4 Mar. 2021, https://medium.com/srm-mic/all-about-structural-similarity-index-ssim-theory-code-in-pytorch-6551b455541e.