

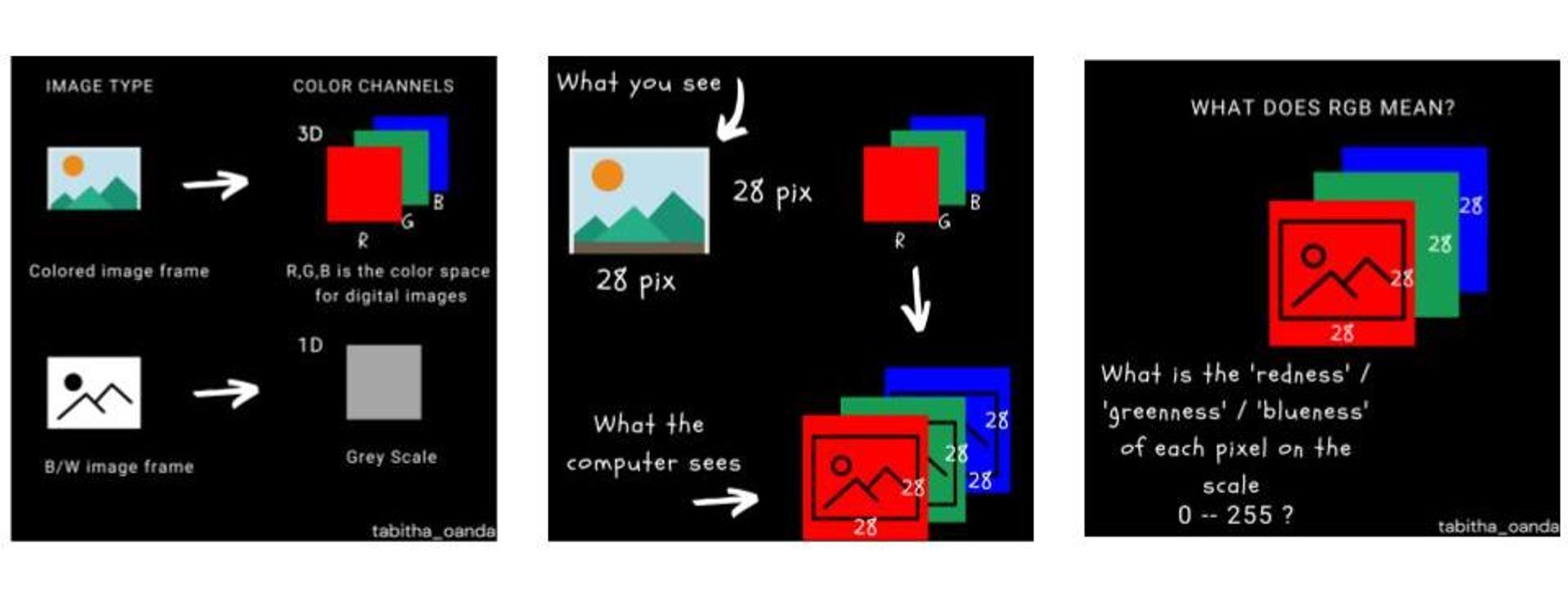
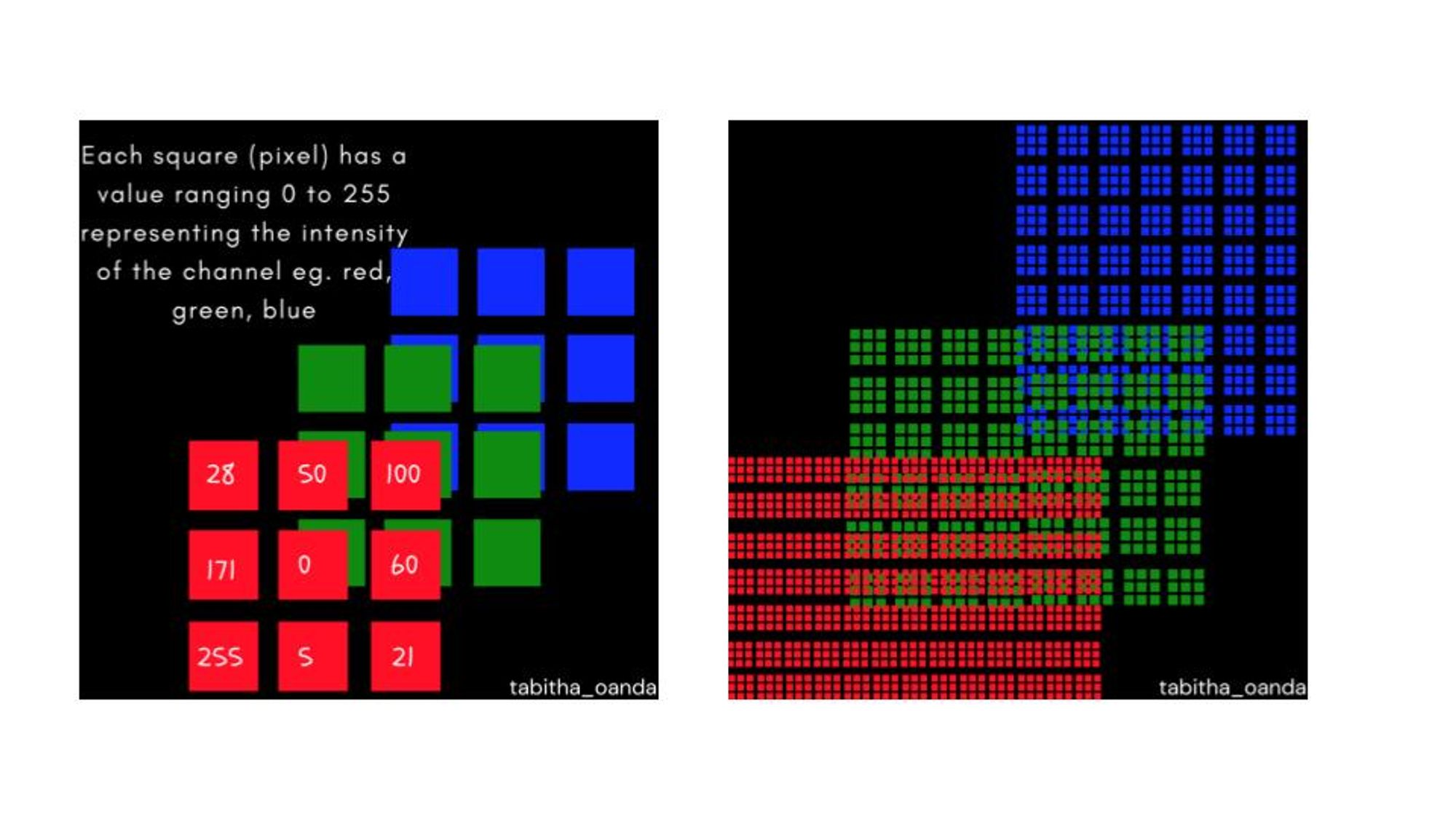
Photos are matrices that include numerical values describing pixels in these coordinates. Colourful photographs include 3 colour channels crimson, inexperienced, and blue (RGB) which implies that the picture is represented by 3 matrices which are concatenated. Grayscale photographs include a single channel which means the picture is represented by a single matrix.
Picture illustration is a job that includes changing a picture matrix (grayscale or RGB) from its regular dimensions right into a decrease dimension whereas sustaining crucial options of the picture. The explanation we wish to analyze a picture in decrease dimensions is that it saves on computation when analyzing the values of the picture matrix. Whereas this may not be a powerful concern when you might have a single picture, the necessity to effectively compute values is available in when analyzing hundreds of photographs which is commonly the case in machine studying for pc imaginative and prescient. Right here is an instance, beneath within the picture on the left, the algorithm analyzes 27 options. Within the picture within the center, the algorithm analyzes hundreds of photographs relying on the picture dimensions
In addition to saving on computing prices, it is very important be aware that not each side of a picture is necessary for its characterization. Right here is an instance, when you have two photographs, a black picture and a black picture with a white dot within the heart, discovering the variations between these two photographs just isn’t closely influenced by the black pixels within the high left of every picture.
What are we analyzing in a picture?
After we have a look at a gaggle of photographs we will simply see similarities and dissimilarities. A few of these are structural (mild depth, blur, spec noise) or conceptual (an image of a tree vs that of a automobile). Earlier than we used deep studying algorithms to carry out function extraction independently, there have been devoted instruments in pc imaginative and prescient that could possibly be used to research picture options. The 2 strategies I’ll spotlight are manually designed kernels and Singular Worth Decomposition.
Conventional Pc Imaginative and prescient Strategies
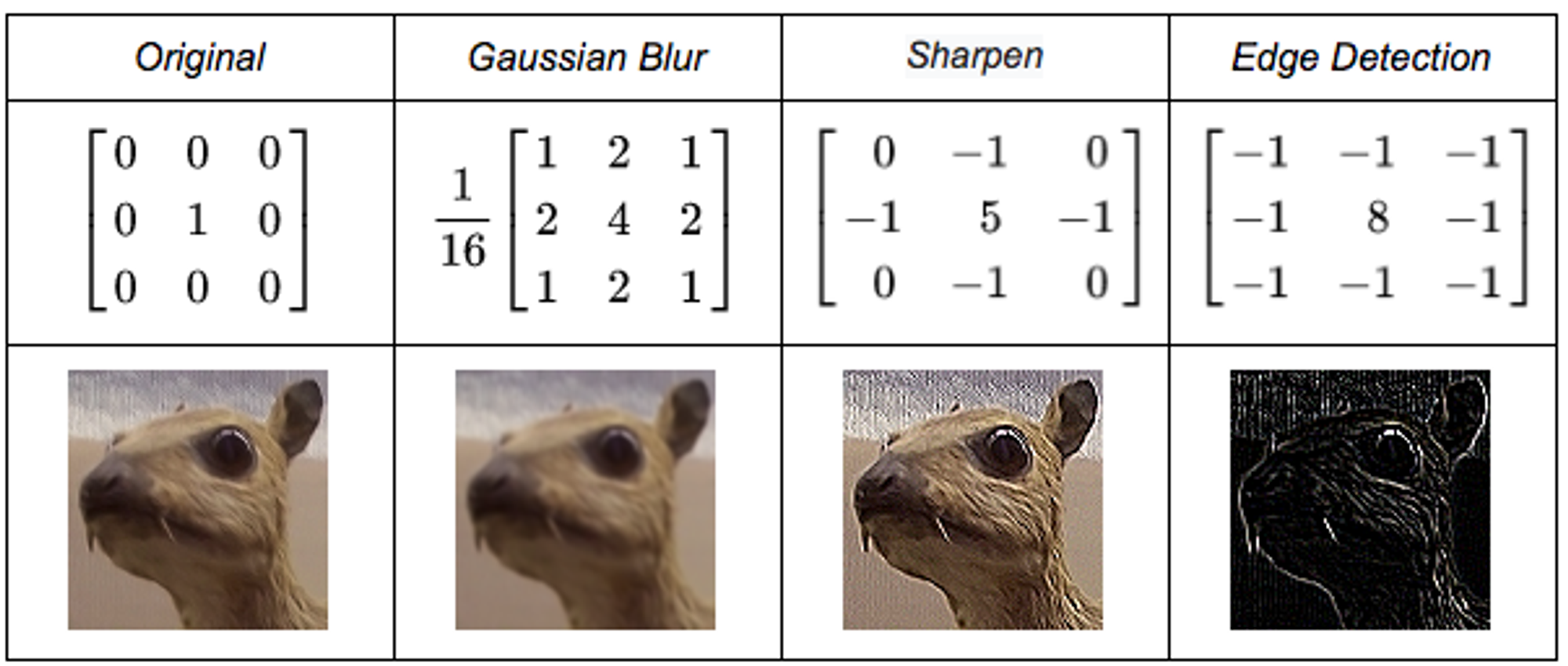
Designing kernels: It includes designing a sq. matrix of numerical values after which performing a convolution operation on the enter photographs to get the options extracted by the kernel.
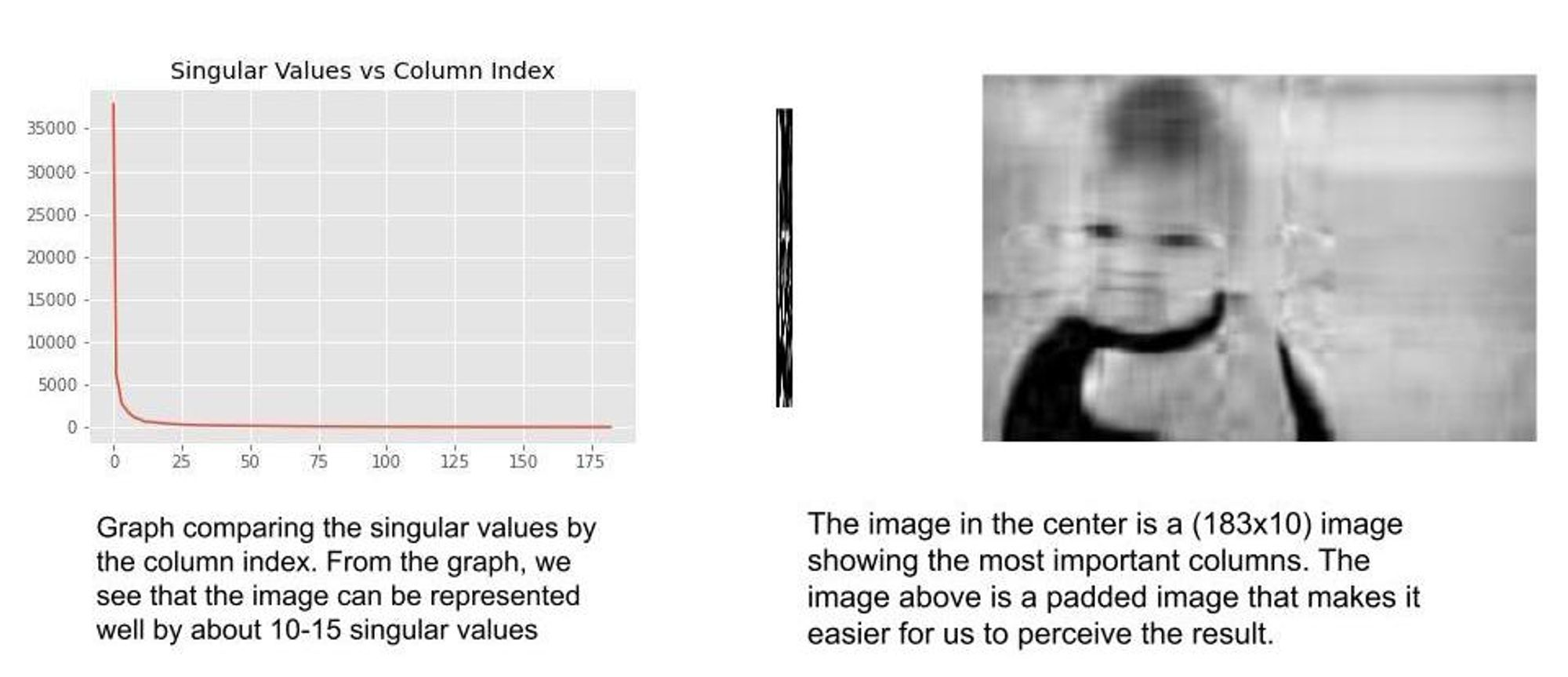
Singular Worth Decomposition: To start, we assume all the pictures are grayscale. This can be a matrix decomposition technique that reduces the matrix into 3 completely different matrices $USigma V^T$ . $U textual content{ and }V^T$ characterize the vectors of the picture matrix whereas $Sigma$ represents the singular values. The very best singular values characterize crucial columns of the picture matrix. Subsequently, if we wish to characterize the picture matrix by the 20 most necessary values, we’ll merely recreate the picture matrix from the decomposition utilizing the 20 highest singular values. $Picture = USigma_{20} V^T$. Beneath is an instance of a picture represented by its 10 most necessary columns.

Fashionable Pc Imaginative and prescient Strategies

Effectively, after we have a look at the picture above that represents the MNIST dataset there are numerous facets that stick out to us as people. Taking a look at it you discover the heavy pixelation or the sharp distinction between the colour of the form of the numbers and the white background. Let’s use the quantity 2 picture from the dataset for instance.
Fashionable machine studying strategies depend on deep studying algorithms to find out crucial options of the enter photographs. If we take the pattern, quantity 2, and move it by means of a deep convolutional neural community (DCNN), the community learns to infer crucial options of the picture. Because the enter knowledge passes from the enter layer to deeper layers within the community the scale of the picture get diminished because the mannequin picks out crucial options and shops them as function maps that get handed from layer to layer.
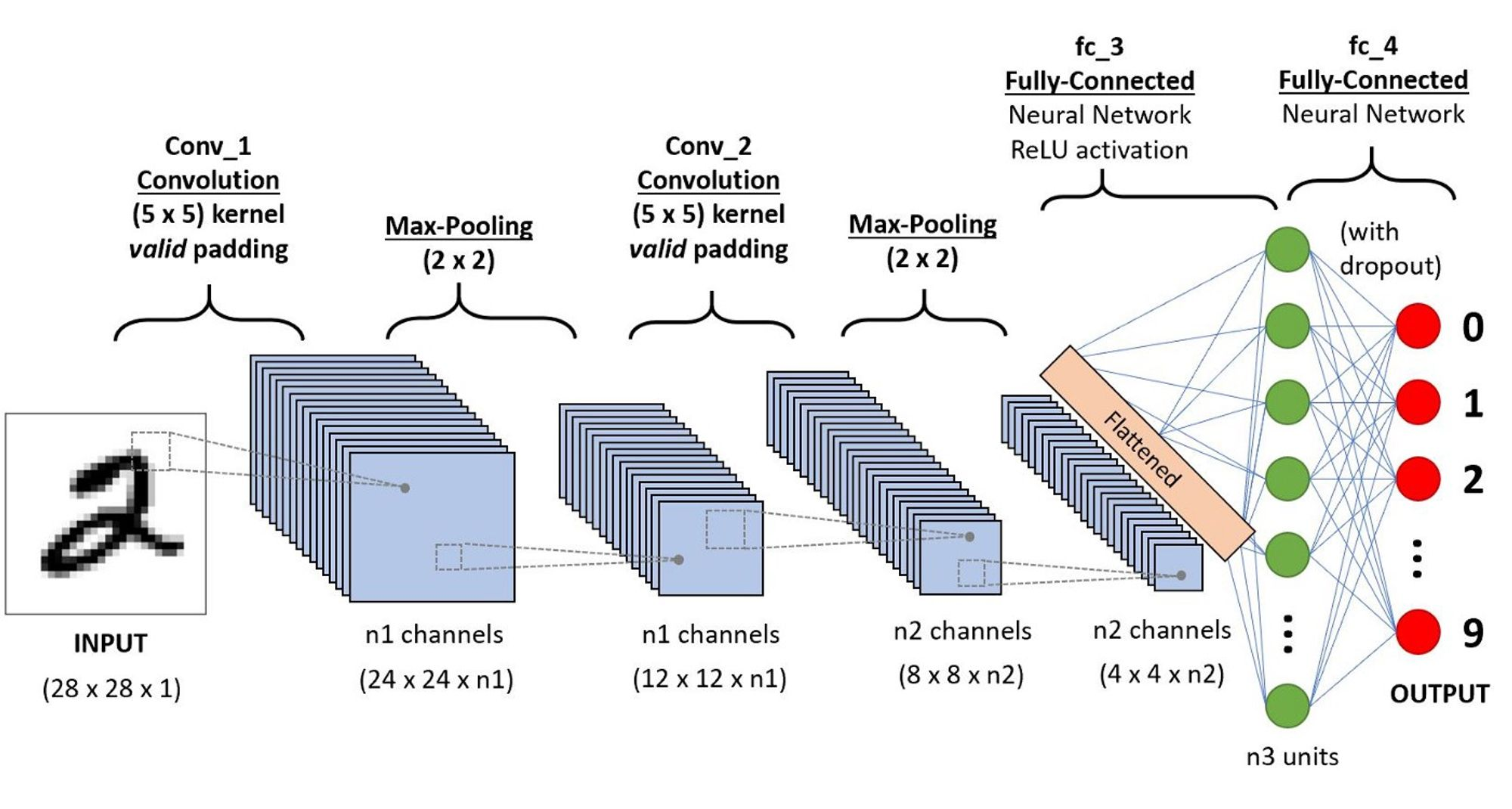
The paper by Liu, Jian, et al. helps visualize the transformations that go on when picture knowledge is handed right into a DCNN. This helps to know that the picture is not essentially being cropped in each layer or being resized however you may think about it as a filtration course of.

Throughout coaching, machine studying algorithms are uncovered to a whole lot of various knowledge within the coaching set. A mannequin is deemed as profitable if it is ready to extract essentially the most important patterns of the dataset which on their very own can meaningfully describe the info. If the educational job is supervised, the objective of the mannequin is to obtain enter knowledge, extract and analyze the significant options, after which predict a label based mostly on the enter. If the educational job is unsupervised there may be much more emphasis on studying patterns within the coaching dataset. In unsupervised studying, we don’t ask the mannequin for a label prediction however for a abstract of the dataset patterns.
The significance of Picture Illustration in Picture Era
The duty of picture technology is unsupervised. The varied fashions used: GANs, Diffusion Fashions, Autoregressive Fashions, and many others. produce photographs that resemble the coaching knowledge however will not be an identical to the coaching knowledge.

With a purpose to consider the picture high quality and constancy of the generated photographs we have to have a strategy to characterize the uncooked RGB photographs in a decrease dimension and evaluate them to actual photographs utilizing statistical strategies.
Constancy: The flexibility of the generated photographs to be much like the coaching photographs
Picture High quality: How practical the pictures look
Earlier strategies for picture function illustration embrace utilizing the Inception Rating(IS) and Frechet Inception Distance (FID) rating that are based mostly on the InceptionV3 mannequin. The thought behind each IS and FID is that InceptionV3 was effectively suited to carry out function extraction on the generated photographs and characterize them in decrease dimensions for classification or distribution comparability. InceptionV3 was effectively geared up as a result of on the time that IS and FID metrics had been launched, the InceptionV3 mannequin was thought-about excessive capability and ImageNet coaching knowledge was among the many largest and most numerous benchmark datasets.
Since then there have been a number of developments within the deep studying pc imaginative and prescient house. In the present day the very best capability classification community is CLIP which was educated on about 400 million picture and caption pairs scrapped from the web. CLIP’s efficiency as a pretrained classifier and as a zero-shot classifier is past exceptional. It’s protected to say, CLIP is much extra strong at function extraction and picture illustration than any of its predecessors.
How does CLIP Work?
The objective of CLIP is to get a extremely good illustration of photographs in an effort to discover the connection between the picture and the identical textual content.
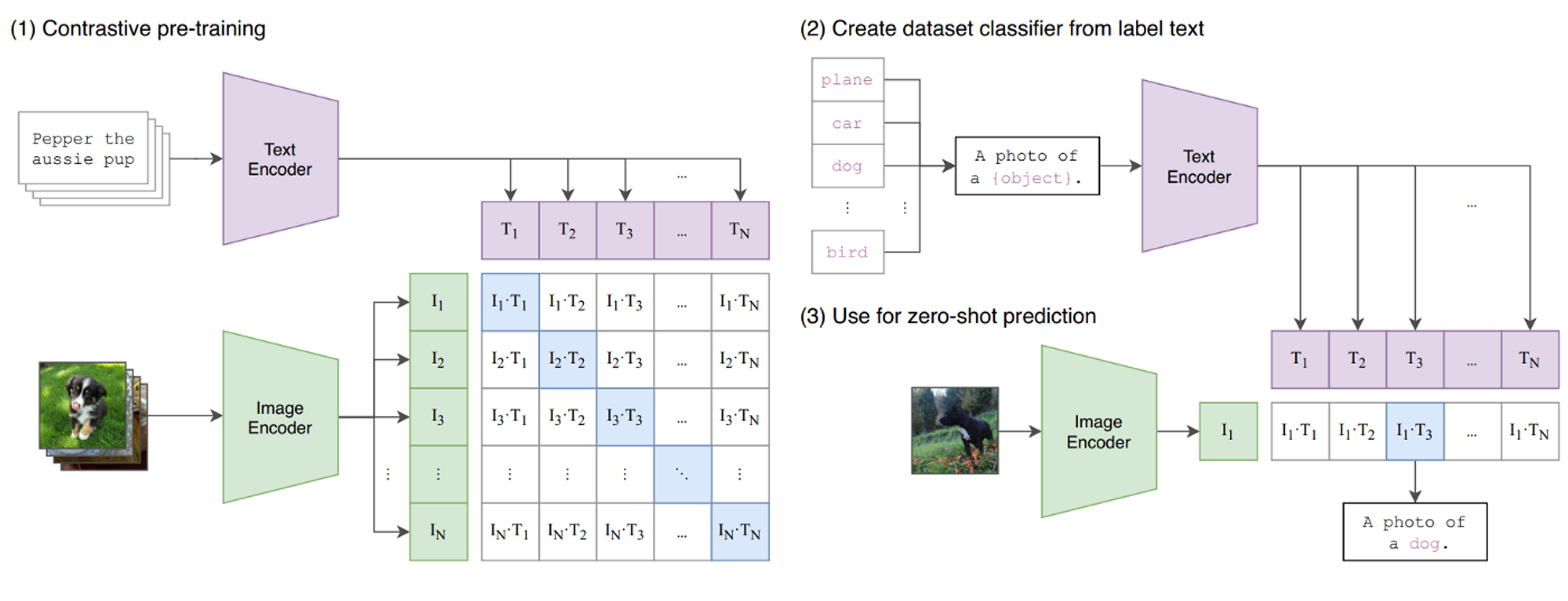
Throughout Coaching:
- The mannequin takes a batch of photographs and passes them by means of a picture encoder to get the illustration vectors $I_1 …I_n$
- The mannequin takes a batch of textual content captions and passes them by means of a textual content encoder to generate illustration vectors $T_1…T_n$
- The contrastive goal is ready to ask, “Given this picture $I_i$, which of those textual content vectors $T_1…t_n$ matches $I_i$ essentially the most. It’s known as a contrastive goal as a result of the match $I_k textual content{ and } T_k$ is in contrast in opposition to all different attainable mixtures of $I_k textual content{ and } T_j$ the place ${j neq okay}$
- The objective throughout coaching is to maximise the match between $I_k textual content{ and } T_k$ and reduce the match between $I_ktext{ and }t_{j neq okay}$
- The dot merchandise $I_iT_i$ is interpreted as a logit worth due to this fact in an effort to discover the proper textual content caption for a picture we might move the vector $[I_1T_1, I_1T_2,I_1T_3…..I_1T_N]$ right into a softmax operate and decide the very best worth as similar to the label (identical to in regular classification)
- Throughout coaching, softmax classification is carried out within the horizontal and vertical instructions. Horizontal → Picture classification, Vertical → Textual content classification
Throughout Inference:
- Go a picture by means of the picture encoder to get the vector illustration of the picture
- Get all of the attainable labels in your classification job and convert them into textual content prompts
- Encode the textual content prompts utilizing the textual content encoder
- The mannequin then performs the dot product between every immediate vector and the picture vector. The very best product worth determines the corresponding textual content immediate for the enter picture.
Now that we all know how CLIP works, it turns into clearer how we will get picture representations from the mannequin. We use the picture encoder of the pretrained mannequin!
With correct picture representations, we will analyze the standard of generated photographs to the next diploma than with InceptionV3. Recall, CLIP is educated on extra photographs and extra courses.
CLIP Rating
That is a picture captioning analysis metric that has gained reputation in current picture technology papers. It was initially designed to be a quick reference-free technique to evaluate the standard of machine-predicted picture captions by benefiting from CLIP’s massive function embedding house.
The authentic CLIP Rating permits you to measure the cosine similarity between a picture function vector and a caption function vector. Given a set weight worth $w =2.5$, the CLIP picture encoding as $v$, and the CLIP textual embedding as $c$, they compute the CLIP rating as:
$textual content{CLIP-S}(textbf{c,v}) = w*max(cos(textbf{c,v}),0)$
This could be an important metric should you wished to evaluate the picture options based mostly on textual content. I believe this sort of evaluation can be nice for pc imaginative and prescient tasks geared toward explainability. If we will match options with human-readable textual content, we acquire a greater understanding of the picture past the visible queues.
In cases the place we aren’t involved with the textual content captions related to the textual content, we merely move the pictures we wish to consider into the CLIP picture encoder to get the picture function vectors. We then calculate the cosine similarity between all of the attainable pairs of picture vectors after which common by the variety of attainable vectors. This technique was developed by Gal, Rinon, et al. and computes the “common pair-wise CLIP-space cosine-similarity between the generated photographs and the pictures of the concept-specific coaching set” in batches of 64 photographs.
Citations:
- Radford, Alec, et al. “Studying transferable visible fashions from pure language supervision.” Worldwide convention on machine studying. PMLR, 2021.
- Hessel, Jack, et al. “Clipscore: A reference-free analysis metric for picture captioning.” arXiv preprint arXiv:2104.08718 (2021).
- Gal, Rinon, et al. “A picture is value one phrase: Personalizing text-to-image technology utilizing textual inversion.” arXiv preprint arXiv:2208.01618 (2022).
- Sauer, Axel, et al. “StyleGAN-T: Unlocking the Energy of GANs for Quick Massive-Scale Textual content-to-Picture Synthesis.” arXiv preprint arXiv:2301.09515 (2023).
- Liu, Jian, et al. “CNN-based hidden-layer topological construction design and optimization strategies for picture classification.” Neural Processing Letters 54.4 (2022): 2831-2842.