

Just lately, Massive Imaginative and prescient Language Fashions (LVLMs) corresponding to LLava and MiniGPT-4 have demonstrated the flexibility to know photos and obtain excessive accuracy and effectivity in a number of visible duties. Whereas LVLMs excel at recognizing widespread objects attributable to their intensive coaching datasets, they lack particular area information and have a restricted understanding of localized particulars inside photos. This limits their effectiveness in Industrial Anomaly Detection (IAD) duties. Then again, present IAD frameworks can solely establish sources of anomalies and require guide threshold settings to differentiate between regular and anomalous samples, thereby limiting their sensible implementation.
The first function of an IAD framework is to detect and localize anomalies in industrial eventualities and product photos. Nevertheless, as a result of unpredictability and rarity of real-world picture samples, fashions are sometimes skilled solely on regular information. They differentiate anomalous samples from regular ones primarily based on deviations from the standard samples. At the moment, IAD frameworks and fashions primarily present anomaly scores for check samples. Furthermore, distinguishing between regular and anomalous cases for every class of things requires the guide specification of thresholds, rendering them unsuitable for real-world functions.

To discover the use and implementation of Massive Imaginative and prescient Language Fashions in addressing the challenges posed by IAD frameworks, AnomalyGPT, a novel IAD method primarily based on LVLM, was launched. AnomalyGPT can detect and localize anomalies with out the necessity for guide threshold settings. Moreover, AnomalyGPT also can provide pertinent details about the picture to have interaction interactively with customers, permitting them to ask follow-up questions primarily based on the anomaly or their particular wants.
Trade Anomaly Detection and Massive Imaginative and prescient Language Fashions
Present IAD frameworks could be categorized into two classes.
- Reconstruction-based IAD.
- Function Embedding-based IAD.
In a Reconstruction-based IAD framework, the first goal is to reconstruct anomaly samples to their respective regular counterpart samples, and detect anomalies by reconstruction error calculation. SCADN, RIAD, AnoDDPM, and InTra make use of the completely different reconstruction frameworks starting from Generative Adversarial Networks (GAN) and autoencoders, to diffusion mannequin & transformers.
Then again, in a Function Embedding-based IAD framework, the first motive is to concentrate on modeling the function embedding of regular information. Strategies like PatchSSVD tries to discover a hypersphere that may encapsulate regular samples tightly, whereas frameworks like PyramidFlow and Cfl mission regular samples onto a Gaussian distribution utilizing normalizing flows. CFA and PatchCore frameworks have established a reminiscence financial institution of regular samples from patch embeddings, and use the space between the check pattern embedding regular embedding to detect anomalies.
Each these strategies observe the “one class one mannequin”, a studying paradigm that requires a considerable amount of regular samples to study the distributions of every object class. The requirement for a considerable amount of regular samples make it impractical for novel object classes, and with restricted functions in dynamic product environments. Then again, the AnomalyGPT framework makes use of an in-context studying paradigm for object classes, permitting it to allow interference solely with a handful of regular samples.
Shifting forward, we’ve Massive Imaginative and prescient Language Fashions or LVLMs. LLMs or Massive Language Fashions have loved large success within the NLP trade, and they’re now being explored for his or her functions in visible duties. The BLIP-2 framework leverages Q-former to enter visible options from Imaginative and prescient Transformer into the Flan-T5 mannequin. Moreover, the MiniGPT framework connects the picture phase of the BLIP-2 framework and the Vicuna mannequin with a linear layer, and performs a two-stage finetuning course of utilizing image-text information. These approaches point out that LLM frameworks may need some functions for visible duties. Nevertheless, these fashions have been skilled on common information, they usually lack the required domain-specific experience for widespread functions.
How Does AnomalyGPT Work?
AnomalyGPT at its core is a novel conversational IAD massive imaginative and prescient language mannequin designed primarily for detecting industrial anomalies and pinpointing their actual location utilizing photos. The AnomalyGPT framework makes use of a LLM and a pre-trained picture encoder to align photos with their corresponding textual descriptions utilizing stimulated anomaly information. The mannequin introduces a decoder module, and a immediate learner module to reinforce the efficiency of the IAD programs, and obtain pixel-level localization output.
Mannequin Structure
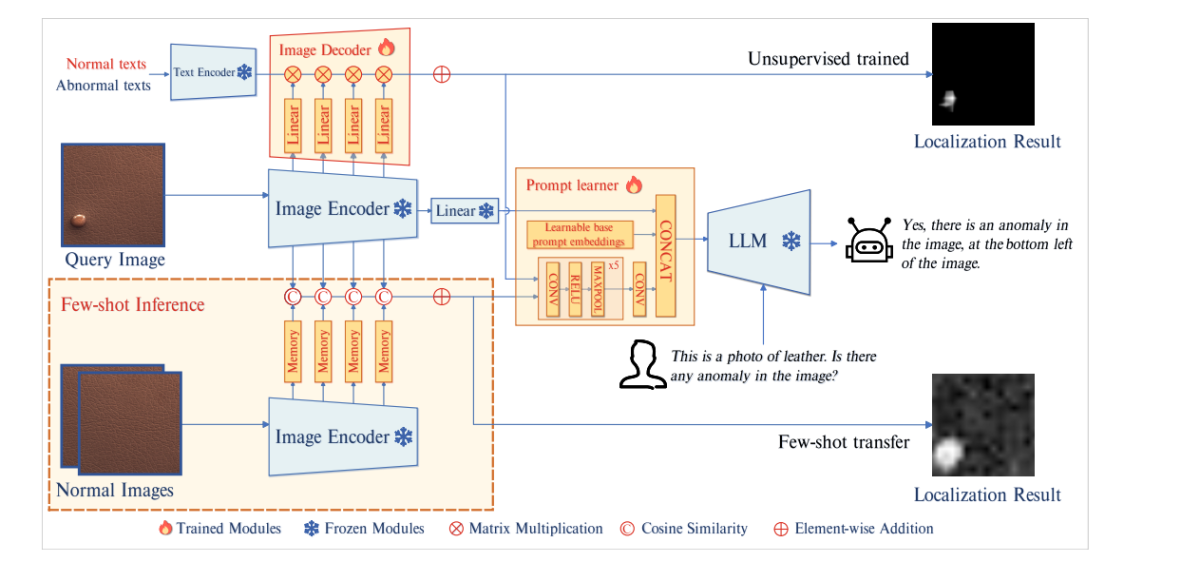
The above picture depicts the structure of AnomalyGPT. The mannequin first passes the question picture to the frozen picture encoder. The mannequin then extracts patch-level options from the intermediate layers, and feeds these options to a picture decoder to compute their similarity with irregular and regular texts to acquire the outcomes for localization. The immediate learner then converts them into immediate embeddings which are appropriate for use as inputs into the LLM alongside the person textual content inputs. The LLM mannequin then leverages the immediate embeddings, picture inputs, and user-provided textual inputs to detect anomalies, and pinpoint their location, and create end-responses for the person.
Decoder
To realize pixel-level anomaly localization, the AnomalyGPT mannequin deploys a light-weight function matching primarily based picture decoder that helps each few-shot IAD frameworks, and unsupervised IAD frameworks. The design of the decoder utilized in AnomalyGPT is impressed by WinCLIP, PatchCore, and APRIL-GAN frameworks. The mannequin partitions the picture encoder into 4 levels, and extracts the intermediate patch degree options by each stage.
Nevertheless, these intermediate options haven’t been via the ultimate image-text alignment which is why they can’t be in contrast immediately with options. To sort out this subject, the AnomalyGPT mannequin introduces further layers to mission intermediate options, and align them with textual content options that symbolize regular and irregular semantics.
Immediate Learner
The AnomalyGPT framework introduces a immediate learner that makes an attempt to remodel the localization outcome into immediate embeddings to leverage fine-grained semantics from photos, and in addition maintains the semantic consistency between the decoder & LLM outputs. Moreover, the mannequin incorporates learnable immediate embeddings, unrelated to decoder outputs, into the immediate learner to supply further data for the IAD activity. Lastly, the mannequin feeds the embeddings and authentic picture data to the LLM.
The immediate learner consists of learnable base immediate embeddings, and a convolutional neural community. The community converts the localization outcome into immediate embeddings, and types a set of immediate embeddings which are then mixed with the picture embeddings into the LLM.
Anomaly Simulation
The AnomalyGPT mannequin adopts the NSA technique to simulate anomalous information. The NSA technique makes use of the Lower-paste method through the use of the Poisson picture modifying technique to alleviate the discontinuity launched by pasting picture segments. Lower-paste is a generally used method in IAD frameworks to generate simulated anomaly photos.
The Lower-paste technique entails cropping a block area from a picture randomly, and pasting it right into a random location in one other picture, thus making a portion of simulated anomaly. These simulated anomaly samples can improve the efficiency of IAD fashions, however there’s a downside, as they’ll usually produce noticeable discontinuities. The Poisson modifying technique goals to seamlessly clone an object from one picture to a different by fixing the Poisson partial differential equations.

The above picture illustrates the comparability between Poisson and Lower-paste picture modifying. As it may be seen, there are seen discontinuities within the cut-paste technique, whereas the outcomes from Poisson modifying appear extra pure.
Query and Reply Content material
To conduct immediate tuning on the Massive Imaginative and prescient Language Mannequin, the AnomalyGPT mannequin generates a corresponding textual question on the idea of the anomaly picture. Every question consists of two main elements. The primary a part of the question consists of an outline of the enter picture that gives details about the objects current within the picture together with their anticipated attributes. The second a part of the question is to detect the presence of anomalies throughout the object, or checking if there’s an anomaly within the picture.
The LVLM first responds to the question of if there’s an anomaly within the picture? If the mannequin detects anomalies, it continues to specify the situation and the variety of the anomalous areas. The mannequin divides the picture right into a 3×3 grid of distinct areas to permit the LVLM to verbally point out the place of the anomalies as proven within the determine beneath.

The LVLM mannequin is fed the descriptive information of the enter with foundational information of the enter picture that aids the mannequin’s comprehension of picture elements higher.
Datasets and Analysis Metrics
The mannequin conducts its experiments totally on the VisA and MVTec-AD datasets. The MVTech-AD dataset consists of 3629 photos for coaching functions, and 1725 photos for testing which are break up throughout 15 completely different classes which is why it is without doubt one of the hottest dataset for IAD frameworks. The coaching picture options regular photos solely whereas the testing photos function each regular and anomalous photos. Then again, the VisA dataset consists of 9621 regular photos, and practically 1200 anomalous photos which are break up throughout 12 completely different classes.
Shifting alongside, similar to the prevailing IAD framework, the AnomalyGPT mannequin employs the AUC or Space Below the Receiver Working Traits as its analysis metric, with pixel-level and image-level AUC used to evaluate anomaly localization efficiency, and anomaly detection respectively. Nevertheless, the mannequin additionally makes use of image-level accuracy to judge the efficiency of its proposed method as a result of it uniquely permits to find out the presence of anomalies with out the requirement of organising the thresholds manually.
Outcomes
Quantitative Outcomes
Few-Shot Industrial Anomaly Detection
The AnomalyGPT mannequin compares its outcomes with prior few-shot IAD frameworks together with PaDiM, SPADE, WinCLIP, and PatchCore because the baselines.

The above determine compares the outcomes of the AnomalyGPT mannequin compared with few-shot IAD frameworks. Throughout each datasets, the tactic adopted by AnomalyGPT outperforms the approaches adopted by earlier fashions by way of image-level AUC, and in addition returns good accuracy.
Unsupervised Industrial Anomaly Detection
In an unsupervised coaching setting with a lot of regular samples, AnomalyGPT trains a single mannequin on samples obtained from all lessons inside a dataset. The builders of AnomalyGPT have opted for the UniAD framework as a result of it’s skilled underneath the identical setup, and can act as a baseline for comparability. Moreover, the mannequin additionally compares in opposition to JNLD and PaDim frameworks utilizing the identical unified setting.

The above determine compares the efficiency of AnomalyGPT when in comparison with different frameworks.
Qualitative Outcomes

The above picture illustrates the efficiency of the AnomalyGPT mannequin in unsupervised anomaly detection technique whereas the determine beneath demonstrates the efficiency of the mannequin within the 1-shot in-context studying.

The AnomalyGPT mannequin is able to indicating the presence of anomalies, marking their location, and offering pixel-level localization outcomes. When the mannequin is in 1-shot in-context studying technique, the localization efficiency of the mannequin is barely decrease when in comparison with unsupervised studying technique due to absence of coaching.
Conclusion
AnomalyGPT is a novel conversational IAD-vision language mannequin designed to leverage the highly effective capabilities of enormous imaginative and prescient language fashions. It can’t solely establish anomalies in a picture but in addition pinpoint their actual places. Moreover, AnomalyGPT facilitates multi-turn dialogues targeted on anomaly detection and showcases excellent efficiency in few-shot in-context studying. AnomalyGPT delves into the potential functions of LVLMs in anomaly detection, introducing new concepts and prospects for the IAD trade.