

A data Graph is a data base that makes use of graph knowledge construction to retailer and function on the information. It gives well-organized human data and in addition powers purposes reminiscent of search engines like google (Google and Bing), question-answering, and advice methods.
A data graph (semantic community) represents the knowledge (storing not simply knowledge but additionally its which means and context). This includes defining entities, summary ideas—and their interrelations in a machine- and human-understandable format.
This permits for deducing new, implicit data from present knowledge, surpassing conventional databases. By leveraging the graph’s interconnected semantics to uncover hidden insights, the data base can reply advanced queries that transcend explicitly saved info.
Historical past of Information Graphs
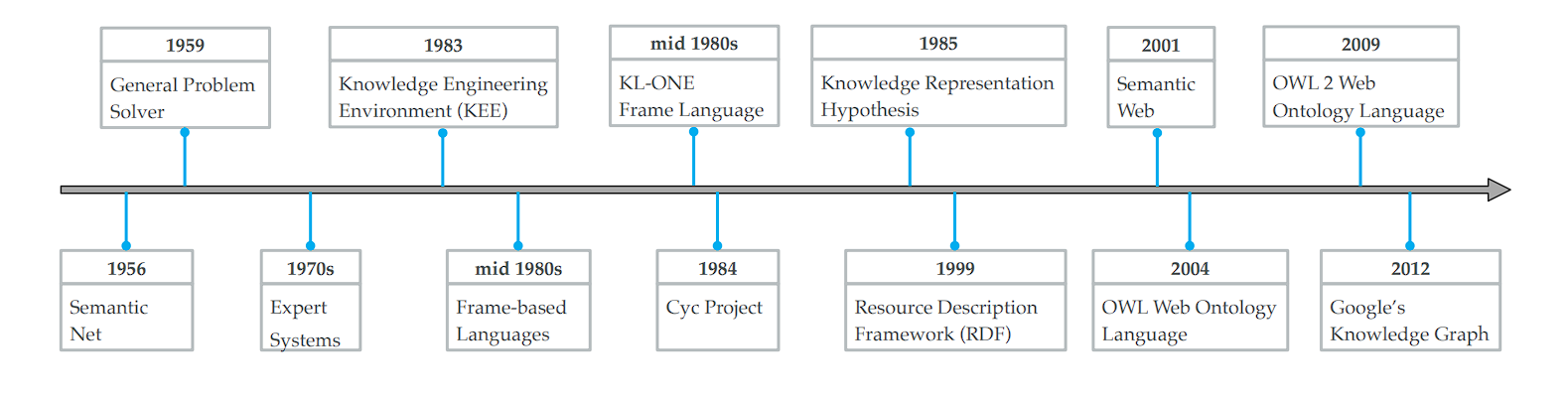
Through the years, these methods have considerably advanced in complexity and capabilities. Here’s a fast recap of all of the advances made in data bases:
- Early Foundations:
- In 1956, Richens laid the groundwork for graphical data illustration by proposing the semantic internet, marking the inception of visualizing data connections.
- The period of Information-Primarily based Programs:
- MYCIN (developed within the early Nineteen Seventies), is an skilled system for medical analysis that depends on a rule-based data base comprising round 600 guidelines.
- Evolution of Information Illustration:
- The Cyc challenge (1984): The challenge goals to assemble the essential ideas and guidelines about how the world works.
- Semantic Net Requirements (2001):
- The introduction of requirements just like the Useful resource Description Framework (RDF) and the Net Ontology Language (OWL) marked vital developments within the Semantic Net, establishing key protocols for data illustration and change.
- The Emergence of Open Information Bases:
- Launch of a number of open data bases, together with WordNet, DBpedia, YAGO, and Freebase, broadening entry to structured data.
- Fashionable Structured Information:
- The time period “data graph” got here into reputation in 2012 following its adoption by Google’s search engine, highlighting a data fusion framework referred to as the Information Vault (Google Information Graph) for developing large-scale data graphs.
- Following Google’s instance, Fb, LinkedIn, Airbnb, Microsoft, Amazon, Uber, and eBay have explored data graph applied sciences, additional popularizing the time period.
Constructing Block of Knowlege Graphs
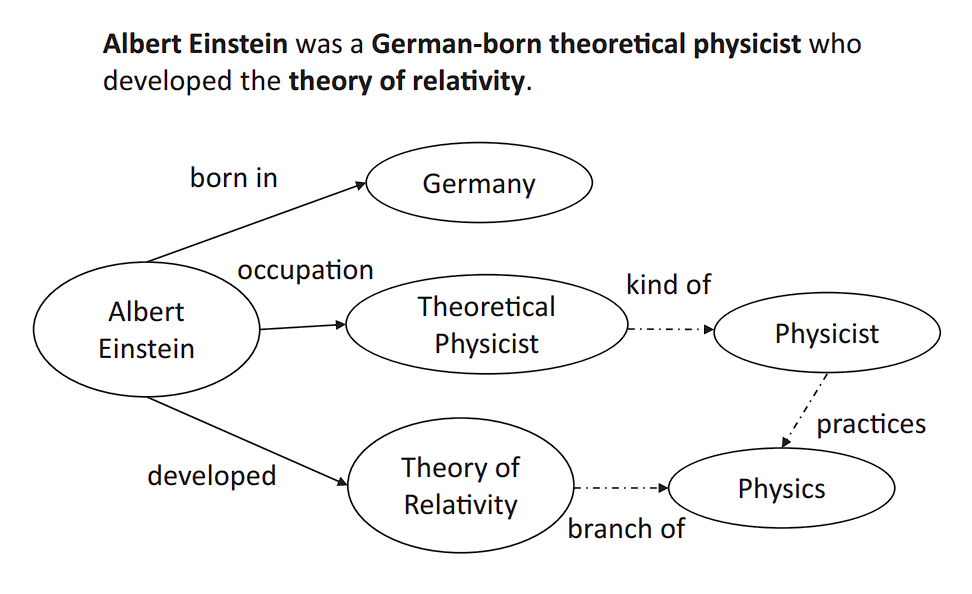
The core elements of a data graph are entities (nodes) and relationships (edges), which collectively kind the foundational construction of those graphs:
Entities (Nodes)
Nodes characterize the real-world entities, ideas, or situations that the graph is modeling. Entities in a data graph typically characterize issues in the actual world or summary ideas that one can distinctly determine.
- Individuals: People, reminiscent of “Marie Curie” or “Neil Armstrong”
- Locations: Areas like “Eiffel Tower” or “Canada”
Relationships (Edges)
Edges are the connections between entities throughout the data graph. They outline how entities are associated to one another and describe the character of their connection. Listed below are a couple of examples of edges.
- Works at: Connecting an individual to a corporation, indicating employment
- Positioned in: Linking a spot or entity to its geographical location or containment inside one other place
- Married to: Indicating a conjugal relationship between two folks.
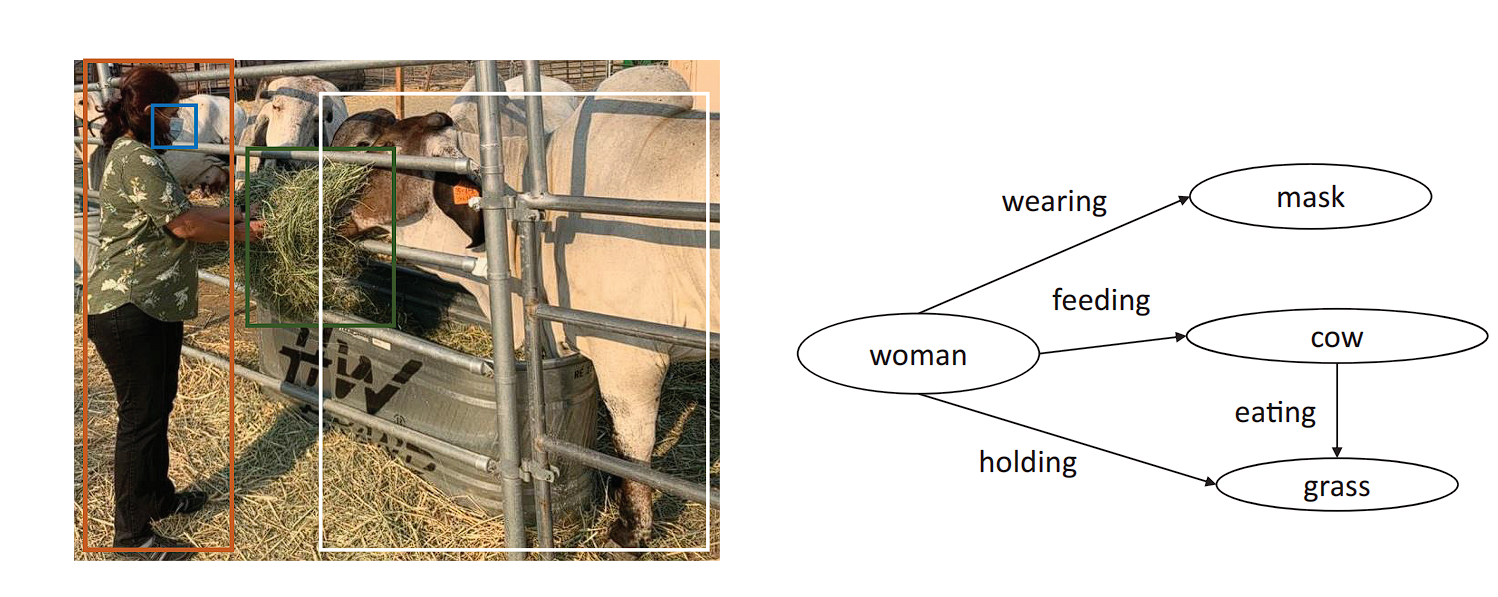
When two nodes are linked utilizing an edge, this construction is named a triple.
Building of Information Graphs
KGs are fashioned by a collection of steps. Listed below are these:
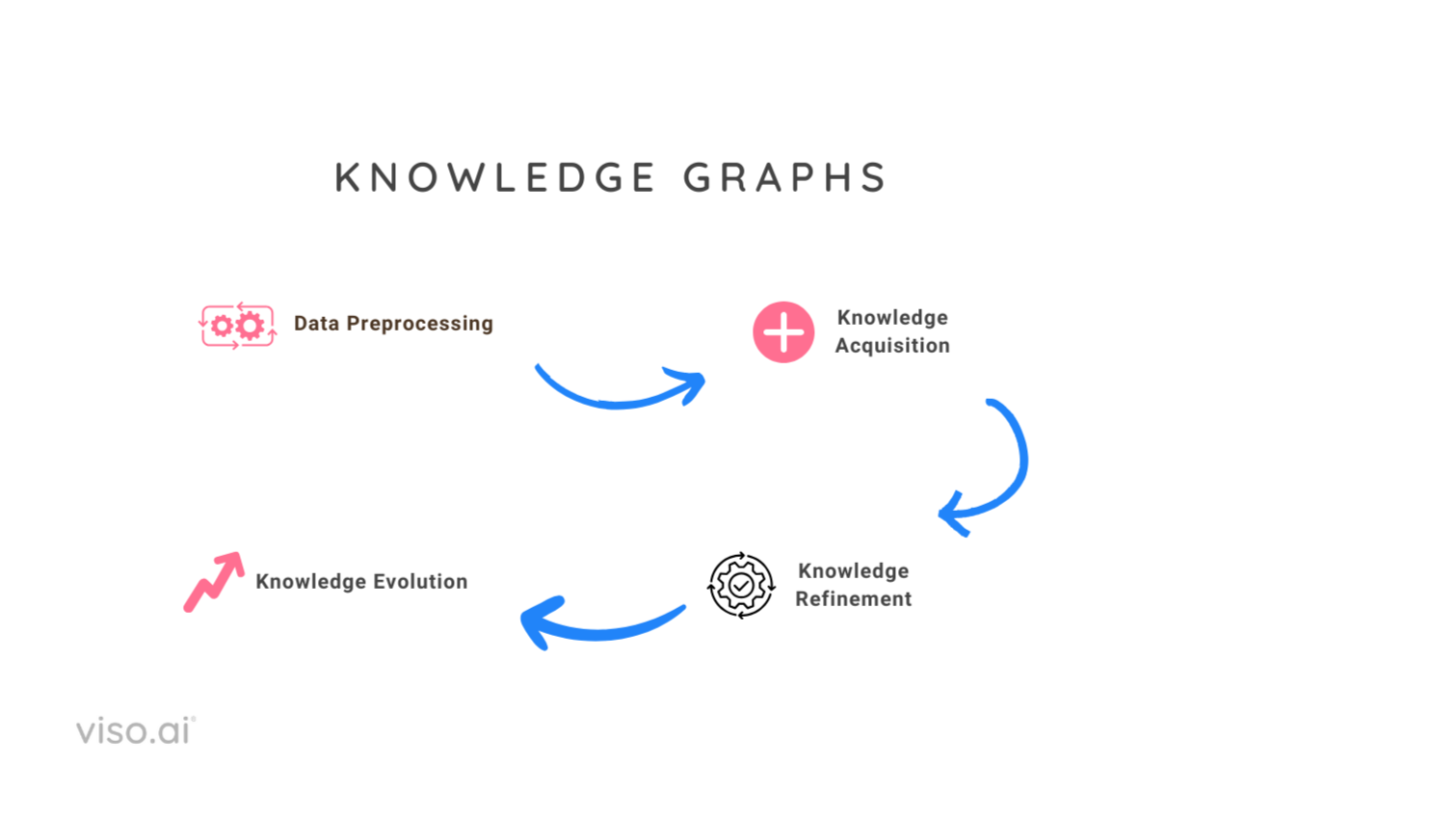
- Information Preprocessing: Step one includes gathering the information (normally scrapped from the web). Then pre-processing the semi-structured knowledge to remodel it into noise-free paperwork prepared for additional evaluation and data extraction.
- Information Acquisition: Information acquisition goals to assemble data graphs from unstructured textual content and different structured or semi-structured sources, full an present data graph, and uncover and acknowledge entities and relations. It consists of the next subtasks:
- Information graph completion: This goals at robotically predicting lacking hyperlinks for large-scale data graphs.
- Entity Discovery: It has additional subtypes:
- Entity Recognition
- Entity Typing
- Entity Disambiguation or Entity linking (EL)
- Relation extraction
- Information Refinement: The following part, after constructing the preliminary graph, focuses on refining this uncooked data construction, referred to as data refinement. This step addresses points in uncooked data graphs constructed from unstructured or semi-structured knowledge. These points embody sparsity (lacking info) and incompleteness (inaccurate or corrupted info). The important thing duties concerned in data graph refinement are:
- Information Graph Completion: Filling in lacking triples and deriving new triples primarily based on present ones.
- Information Graph Fusion: Integrating info from a number of data graphs.
- Information Evolution: The ultimate step addresses the dynamic nature of information. It includes updating the data graph to replicate new findings, resolving contradictions with newly acquired info, and increasing the graph.
Information Preprocessing
Information preprocessing is a vital step in creating data graphs from textual content knowledge. Correct knowledge preprocessing enhances the accuracy and effectivity of machine studying fashions utilized in subsequent steps. This includes:
- Noise Removing: This consists of stripping out irrelevant content material, reminiscent of HTML tags, ads, or boilerplate textual content, to concentrate on the significant content material.
- Normalization: Standardizing textual content by changing it to a uniform case, eradicating accents, and resolving abbreviations can cut back the complexity of ML and AI fashions.
- Tokenization and Half-of-Speech Tagging: Breaking down textual content into phrases or phrases and figuring out their roles helps in understanding the construction of sentences, which is essential for entity and relation extraction.
Information Sorts
Primarily based on the group of knowledge, it may be broadly categorised into structured, semi-structured, and unstructured knowledge. Deep Studying algorithms are primarily used to course of and perceive unstructured and semi-structured knowledge.
- Structured knowledge is very organized and formatted in a manner that straightforward, easy search algorithms or different search operations can simply search. It follows a inflexible schema, organizing the information into tables with rows and columns. Every column specifies a datatype, and every row corresponds to a report. Relational databases (RDBMS) reminiscent of MySQL and PostgreSQL handle this sort of knowledge. Preprocessing typically includes cleansing, normalization, and have engineering.
- Semi-Structured Information: Semi-structured knowledge doesn’t reside in relational databases. It doesn’t match neatly into tables, rows, and columns. Nevertheless, it accommodates tags or different markers—examples: XML information, JSON paperwork, e-mail messages, and NoSQL databases like MongoDB that retailer knowledge in a format known as BSON (binary JSON). Instruments reminiscent of Stunning Soup are used to extract related info.
- Unstructured knowledge refers to info that lacks a predefined knowledge mannequin or isn’t organized in a predefined method. It represents the most typical type of knowledge and consists of examples reminiscent of photos, movies, audio, and PDF information. Unstructured knowledge preprocessing is extra advanced and may contain textual content cleansing, and have extraction. NLP libraries (reminiscent of SpaCy) and varied machine studying algorithms are used to course of this sort of knowledge.
Information Acquisition in KG
Information acquisition is step one within the development of information graphs, involving the extraction of entities, resolving their coreferences, and figuring out the relationships between them.
Entity Discovery
Entity discovery lays the inspiration for developing data graphs by figuring out and categorizing entities inside knowledge, which includes:
- Named Entity Recognition (NER): NER is the method of figuring out and classifying key parts in textual content into predefined classes such because the names of individuals, organizations, areas, expressions of instances, portions, financial values, percentages, and so on.
- Entity Typing (ET): Categorizes entities into extra fine-grained sorts (e.g., scientists, artists). Data loss happens if ET duties will not be carried out, e.g., Donald Trump is a politician and a businessman.
- Entity Linking (EL): Connects entity mentions to corresponding objects in a data graph.
NER in Unstructured Information
Named Entity Recognition (NER) performs an important function in info extraction, aiming to determine and classify named entities (folks, areas, organizations, and so on.) inside textual content knowledge.
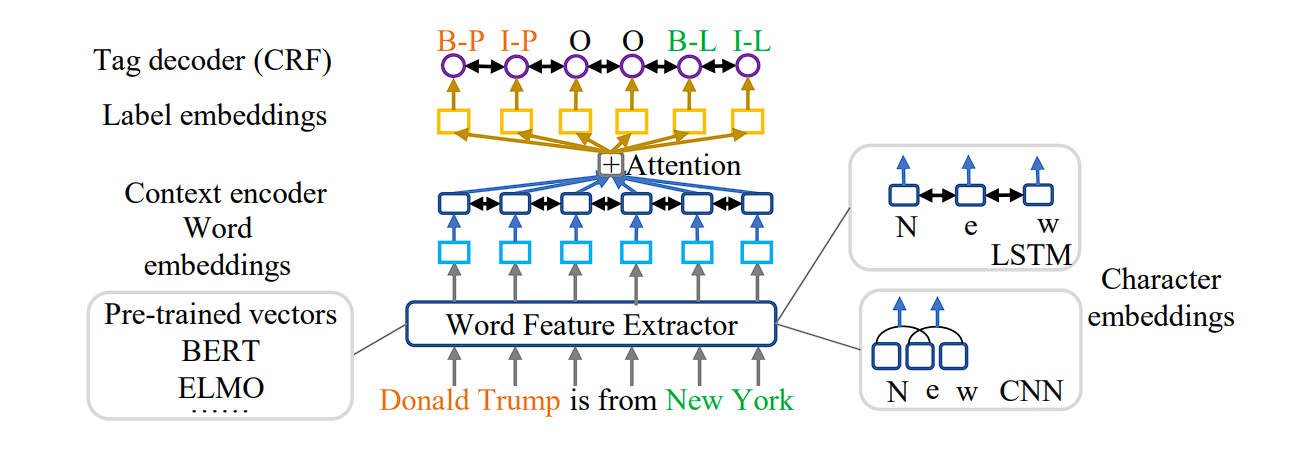
Deep studying fashions are revolutionizing NER, particularly for unstructured knowledge. These fashions deal with NER as a sequence-to-sequence (seq2seq) drawback, remodeling phrase sequences into labeled sequences (phrase + entity sort).
- Context Encoders: Deep studying architectures make use of varied encoders (CNNs, LSTMs, and so on.) to seize contextual info from the enter sentence. These encoders generate contextual embeddings that characterize phrase which means in relation to surrounding phrases.
- Consideration Mechanisms: Consideration mechanisms additional improve deep studying fashions by specializing in particular components of the enter sequence which can be most related to predicting the entity tag for a selected phrase.
- Pre-trained Language Fashions: Using pre-trained language fashions like BERT or ELMo injects wealthy background data into the NER course of. These fashions present pre-trained phrase embeddings that seize semantic relationships between phrases, enhancing NER efficiency.
Entity Typing
Entity Recognition (NER) identifies entities inside textual content knowledge, in distinction, Entity Typing (ET) assigns a extra particular, fine-grained sort to those entities, like classifying “Donald Trump” as each a “politician” and a “businessman.”
Worthwhile particulars about entities are misplaced with out ET. As an illustration, merely recognizing “Donald Trump” doesn’t reveal his varied roles. Fantastic-grained typing closely depends on context. For instance, “Manchester United” may consult with the soccer workforce or the town itself relying on the encircling textual content.
Much like Named Entity Recognition (NER), consideration mechanisms can concentrate on essentially the most related components of a sentence in Entity Typing (ET) to foretell the entity sort. This helps the mannequin determine the particular phrases or phrases that contribute most to understanding the entity’s function.
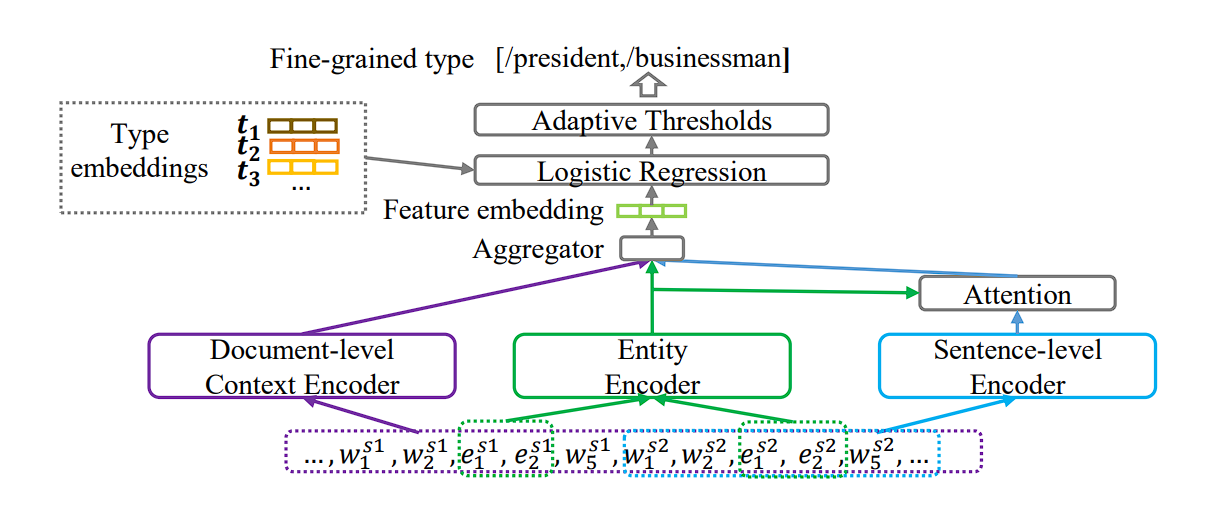
Entity Linking
Entity Linking (EL), also called entity disambiguation, performs a significant function in enriching info extraction.
It connects textual mentions of entities in knowledge to their corresponding entries inside a Information Graph (KG). For instance, the sentence “Tesla is constructing a brand new manufacturing facility.” EL helps disambiguate “Tesla” – is it the automobile producer, the scientist, or one thing else completely?
Relation Extraction
Relation extraction is the duty of detecting and classifying semantic relationships between entities inside a textual content. For instance, within the sentence “Barack Obama was born in Hawaii,” relation extraction would determine “Barack Obama” and “Hawaii” as entities and classify their relationship as “born in.”
Relation Extraction (RE) performs an important function in populating Information Graphs (KGs) by figuring out relationships between entities talked about in textual content knowledge.
Deep Studying Architectures for Relation Extraction Duties:
- CopyAttention: This mannequin incorporates a novel mechanism. It not solely generates new phrases for the relation and object entity however can even “copy” phrases immediately from the enter sentence. That is significantly useful for relation phrases that use present vocabulary from the textual content itself.
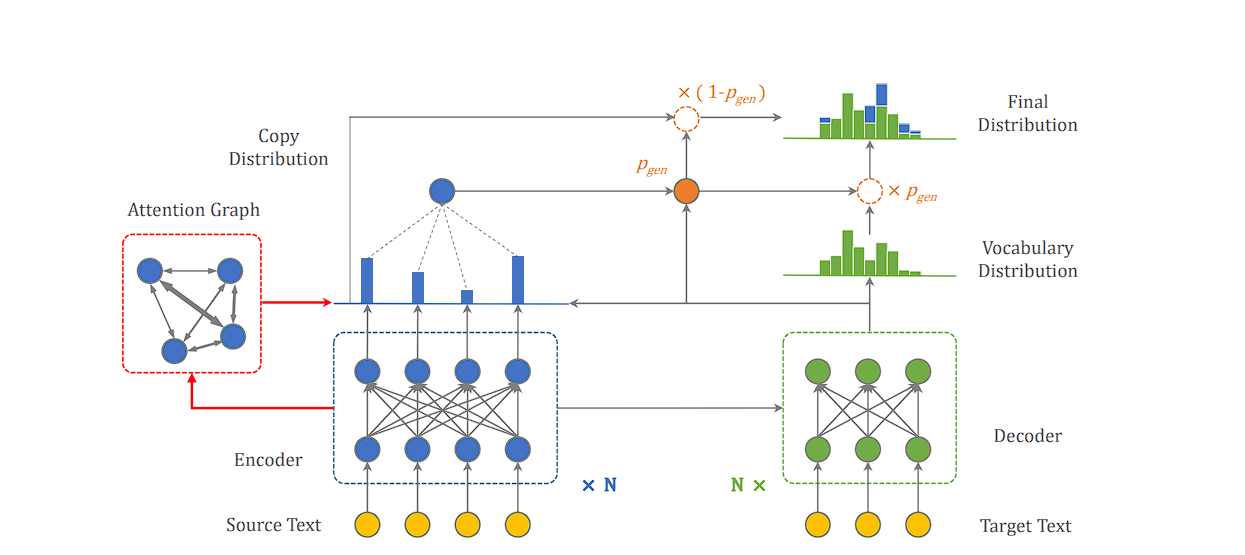
Instruments and Applied sciences for constructing and managing data graphs
Constructing and managing data graphs includes a mixture of software program instruments, libraries, and frameworks. Every software is suited to totally different features of the method we mentioned above. Listed below are to call a couple of.
Graph Databases(Neo4j): A graph database that gives a robust and versatile platform for constructing data graphs, with assist for Cypher question language.
Graph Visualization and Evaluation (Gephi): Gephi is an open-source community evaluation and visualization software program package deal written in Java, designed to permit customers to intuitively discover and analyze every kind of networks and complicated methods. Nice for researchers, knowledge analysts, and anybody needing to visualise and discover the construction of enormous networks and data graphs.
Information Extraction and Processing(Stunning Soup & Scrapy): Python libraries for net scraping knowledge from net pages.
Named Entity Recognition and Relationship Extraction:
- SpaCy: SpaCy is an open-source pure language processing (NLP) library in Python, providing highly effective capabilities for named entity recognition (NER), dependency parsing, and extra.
- Stanford NLP: The Stanford NLP Group’s software program gives a set of pure language evaluation instruments that may take uncooked textual content enter and provides the bottom types of phrases, their components of speech, and parse bushes, amongst different issues.
- TensorFlow and PyTorch: Machine studying frameworks that can be utilized for constructing fashions to boost data graph illustration.