

Function Extraction is the method of reworking uncooked knowledge, usually unorganized, into significant options, that are used to coach machine studying fashions. In at this time’s digital world, machine studying algorithms are used broadly for credit score danger prediction, inventory market forecasting, early illness detection, and so on. The accuracy and efficiency of those fashions depend on the standard of the enter options. On this weblog, we’ll introduce you to function engineering, why we want it and the completely different machine studying strategies accessible to execute it.
What’s Function Extraction in Machine Studying?
We offer coaching knowledge to machine studying fashions to assist the algorithm study underlying patterns to foretell the goal/output. The enter coaching knowledge is known as ‘options’, vectors representing the info’s traits. For instance, let’s say the target is to construct a mannequin to foretell the sale of all air conditioners on an e-commerce web site. What knowledge can be helpful on this case? It will assist to know the product options like its power-saving mode, ranking, guarantee interval, set up service, seasons within the area, and so on. Among the many sea of data accessible, choosing solely the numerous and important options for enter known as function extraction.
The kind of options and extraction strategies additionally range relying on the enter knowledge kind. Whereas working with tabular knowledge, now we have each numerical (e.g. Age, No of merchandise, and categorical options (Gender, Nation, and so on). In deep studying fashions that use picture knowledge, options embody detected edges, pixel knowledge, publicity, and so on. In NLP fashions based mostly on textual content datasets, options may be the frequency of particular phrases, sentence similarity, and so on.
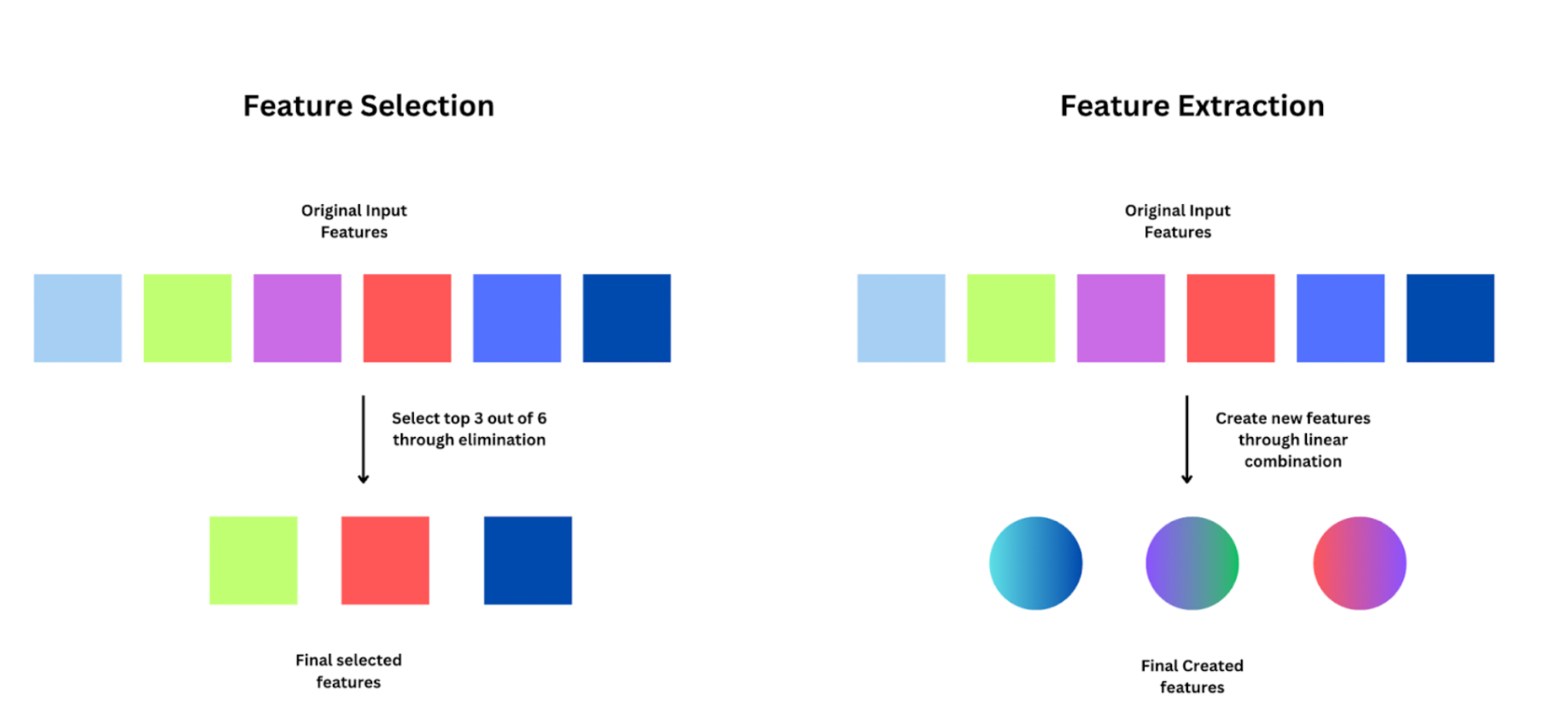
What’s the distinction between function choice and have extraction?
Learners usually get confused between function choice and have extraction. Function choice is just selecting the most effective ‘Ok’ options from accessible ‘n’ variables, and eliminating the remainder. Whereas, function extraction entails creating new options by means of mixtures of the prevailing options.
Earlier than we dive into the varied strategies for function extraction, that you must perceive why we want it, and the advantages it might deliver.
Why do we want Function Extraction?
In any knowledge science pipeline, function extraction is finished after knowledge assortment and cleansing. One of many easiest however correct guidelines in machine studying: Rubbish IN = Rubbish OUT! Let’s check out why function engineering is required, and the way it advantages constructing a extra environment friendly and correct mannequin.
- Keep away from Noise & Redundant Data: Uncooked knowledge can have quite a lot of noise as a result of gaps, and handbook errors in knowledge assortment. You might also have a number of variables that present the identical data, turning into redundant. For instance, if each peak and weight are included as options, together with their product (BMI) will make one of many authentic options redundant. Redundant variables don’t add extra worth to the mannequin, as an alternative could trigger overfitting. Function extraction helps in eradicating noise, and redundancy to create a sturdy mannequin with extracted options.
- Dimensionality Discount: Dimensionality refers back to the variety of enter options in your machine-learning mannequin. Excessive dimensionality could result in overfitting and elevated computation prices. Function extraction offers us with strategies to rework the info right into a lower-dimensional house whereas retaining the important data by lowering the variety of options.
- Improved & Sooner Mannequin Efficiency: Function extraction strategies enable you create related and informative options, that present variability to the mannequin. By optimizing the function set, we will velocity up mannequin coaching and prediction processes. That is particularly useful when the mannequin is operating in real-time and wishes scalability to deal with fluctuating knowledge volumes.
- Higher Mannequin Explainability: Simplifying the function house and specializing in related patterns enhance the general explainability (or interpretability) of the mannequin. Interpretability is essential to know which components influenced the mannequin’s determination, to make sure there isn’t any bias. Improved explainability makes it simpler to justify compliance and knowledge privateness rules in monetary and healthcare fashions.
With a diminished set of options, knowledge visualization strategies are more practical in capturing developments between options and output. Other than these, function extraction permits domain-specific data and insights to be included into the modeling course of. Whereas creating options, you must also take the assistance of area specialists.
Principal Part Evaluation (PCA) for Function Extraction
PCA or Principal Part Evaluation is likely one of the broadly used strategies to battle the “curse of dimensionality”. Let’s say now we have 200 options in a dataset, will all of them have the identical influence on the mannequin prediction? No. Completely different subsets of options have completely different variances within the mannequin output. PCA goals to cut back the dimension whereas additionally sustaining mannequin efficiency, by retaining options that present most variance.
How does PCA work?
Step one in PCA is to standardize the info. Subsequent, it computes a covariance matrix that reveals how every variable interacts with different variables within the dataset. From the covariance matrix,
PCA selects the instructions of most variance, additionally known as “principal elements” by means of Eigenvalue decomposition. These elements are used to rework the high-dimensional knowledge right into a lower-dimensional house.
The right way to Implement PCA utilizing scikit study?
I’ll be utilizing a climate dataset to foretell the chance of rain for example to indicate easy methods to implement PCA. You may obtain the dataset from Kaggle. This dataset incorporates about 10 years of every day climate observations from many areas throughout Australia. Rain Tomorrow is the goal variable to foretell.
Step 1: Begin by importing the important packages as a part of the preprocessing steps.
# Import crucial packages import numpy as np import pandas as pd import seaborn as sb import matplotlib.pyplot as plt from sklearn import preprocessing # To get MinMax Scaler perform
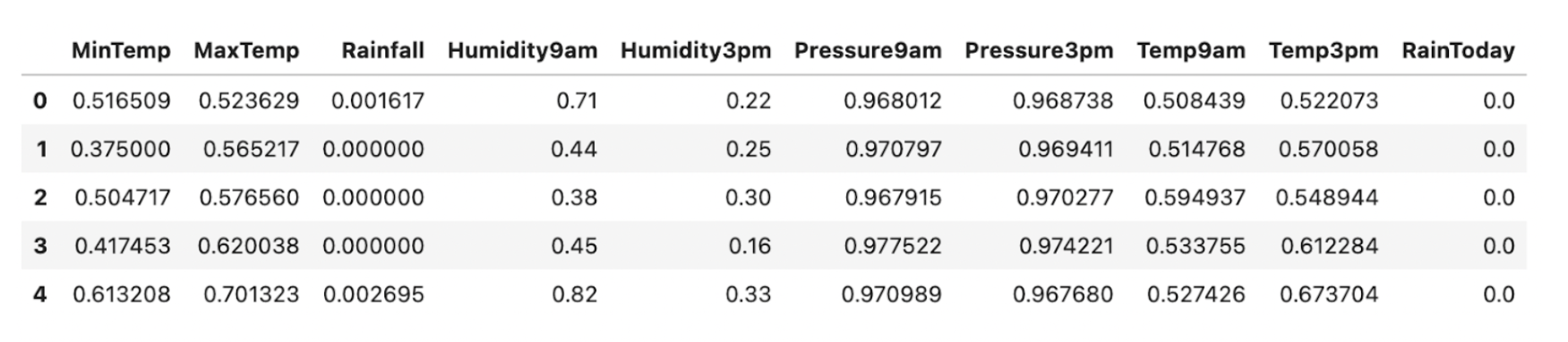
Step 2: Subsequent, learn the CSV file into an information body and cut up it into Options and Goal. We’re utilizing the Min Max scaler perform from sklearn to standardize the info uniformly.
# Learn the CSV file
knowledge = pd.read_csv('../enter/weatherAUS.csv')
# Break up the goal var (Y) and the options (X)
Y = knowledge.RainTomorrow
X = knowledge.drop(['RainTomorrow'], axis=1)
# Scaling the dataset
min_max_scaler = preprocessing.MinMaxScaler()
X_scaled = pd.DataFrame(min_max_scaler.fit_transform(X), columns = X.columns)
X_scaled.head()
Step 3: Initialize the PCA class from sklearn.decomposition module. You may cross the scaled options to ‘pca.match()’ perform as proven under.
# Initializing PCA and becoming from sklearn.decomposition import PCA pca = PCA() pca.match(X_scaled)
PCA will then compute the variance for various principal elements. The ‘pca.explained_variance_ratio_’ captures this data. Let’s plot this to visualise how variance differs throughout function house.
plt.plot(pca.explained_variance_ratio_, linewidth=2)
plt.axis('tight')
plt.xlabel('Variety of Feautres')
plt.ylabel('Variance Ratio')
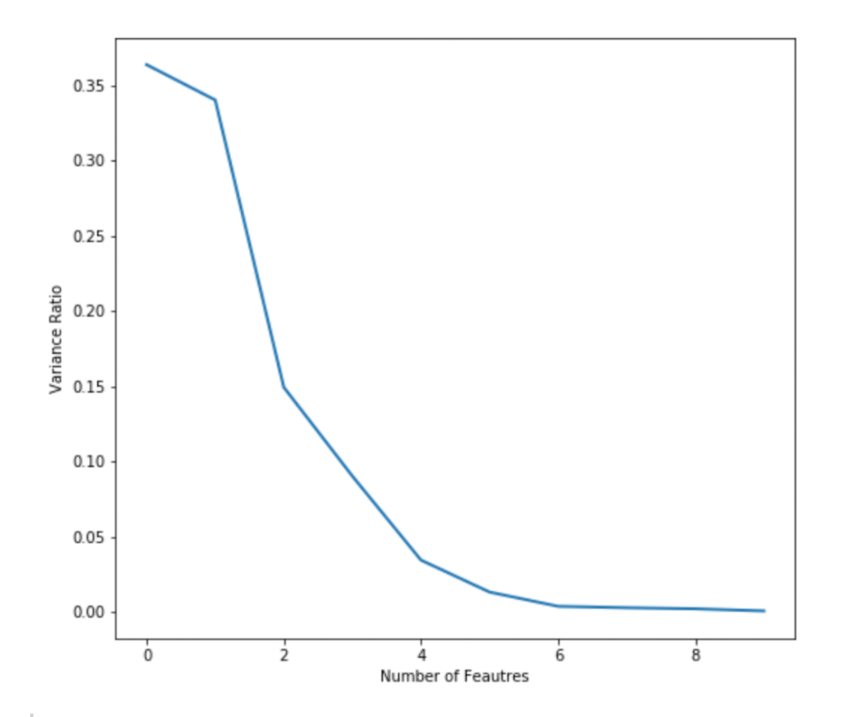
From the plot, you may see that the highest 3-4 options can seize most variance. The curve is nearly flat past 5 options. You may this plot to determine what number of remaining options you wish to extract from PCA. I’m selecting 3 on this case.
Step 4: Now, initialize PCA once more by offering the parameter ‘n_components’ as 3. This parameter denotes the variety of principal elements or dimensions that you simply’d like to cut back the function house to.
pca = PCA(n_components=3) pca.fit_transform(x_train)
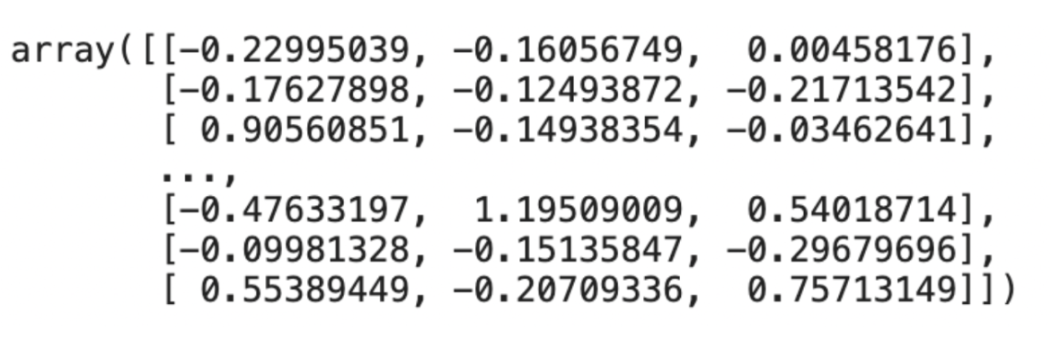
We’ve got diminished our dataset to three options as proven above. If you wish to examine the full variance captured by the chosen elements, you may calculate the sum of the defined variance.
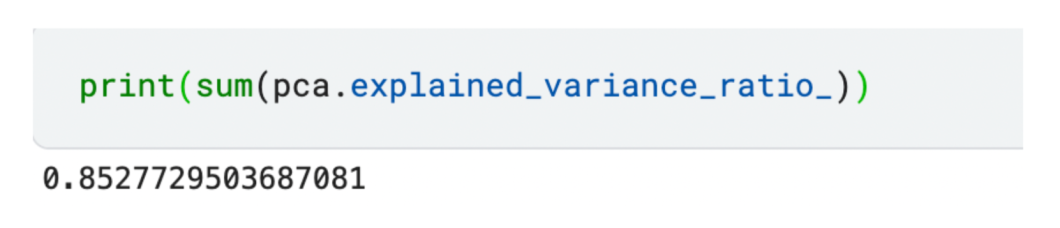
The diminished set of three options captures 85% variance amongst all options!
It’s finest to make use of PCA when the variety of options is simply too enormous to visualise or interpret clearly. PCA can even deal with multilaterally, however it’s delicate to outliers current. Guarantee the info is cleaned by eradicating outliers, scaling, and standardizing.
LDA for Function Extraction
Linear Discriminant Evaluation (LDA) is a statistical method broadly used for dimensionality discount in classification issues. The goal is to discover a set of linear mixtures of options that finest separate the lessons within the knowledge.
How is LDA completely different from PCA?
PCA targets solely maximizing knowledge variance, which is finest in regression issues. LDA targets to maximise the variations between lessons, which is good for multi-classification issues.
Let’s take a fast look into how LDA works:
- LDA requires the enter knowledge to be usually distributed and computes covariance matrices
- Subsequent, LDA calculates two varieties of scatter matrices:
- Between-class scatter matrix: It’s computed to measure the unfold between completely different lessons.
- Inside-class scatter matrix: It computes the unfold inside every class.
- Eigenvalue Decomposition: LDA then performs eigenvalue decomposition on the matrix to acquire its eigenvectors and eigenvalues.
- The eigenvectors comparable to the biggest eigenvalues are chosen. These eigenvectors are the instructions within the function house that maximize class separability. We undertaking the unique knowledge throughout these instructions to acquire the diminished function house.
The right way to Implement LDA on Classification Duties?
Let’s create some artificial knowledge to play with. You should use the ‘make_classification()’ perform from scikit study for this. Check with the code snippet under. As soon as the info is created, let’s visualize it utilizing a 3D plot.
from sklearn.datasets import make_classification options, output = make_classification( n_features=10, n_classes=4, n_samples=1500, n_informative=2, random_state=5, n_clusters_per_class=1, ) # Plot the 3D visualization fig = px.scatter_3d(x=X[:, 0], y=X[:, 1], z=X[:, 2], coloration=y, opacity=0.8) fig.present()
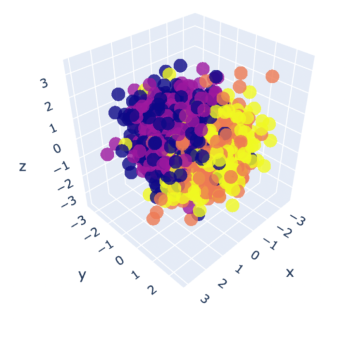
Within the visualization, we will see 4 completely different colours for every class. It appears unattainable to search out any patterns presently. Subsequent, import the LDA module from discriminant_analysis of scikit study. Just like PCA, that you must present what number of diminished options you need by means of the ‘n_components’ parameter.
From sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# Initialize LDA
lda = LinearDiscriminantAnalysis(n_components=3)
post_lda_features = lda.match(options, output).remodel(options)
print("variety of options(authentic):", X.form[1])
print("variety of options that was diminished:", post_flda_features.form[1])
OUTPUT: >> variety of options(authentic): 10 >> variety of options that was diminished: 3
We’ve got efficiently diminished the function house to three. You can even examine the variance captured by every function utilizing the under command:
lda.explained_variance_ratio_

Now, let’s visualization the diminished function house utilizing the under script:
fig = px.scatter(x=post_lda_features[:, 0], y=post_lda_features[:, 1], coloration=y) fig.update_layout( title="After LDA on function house", ) fig.present()
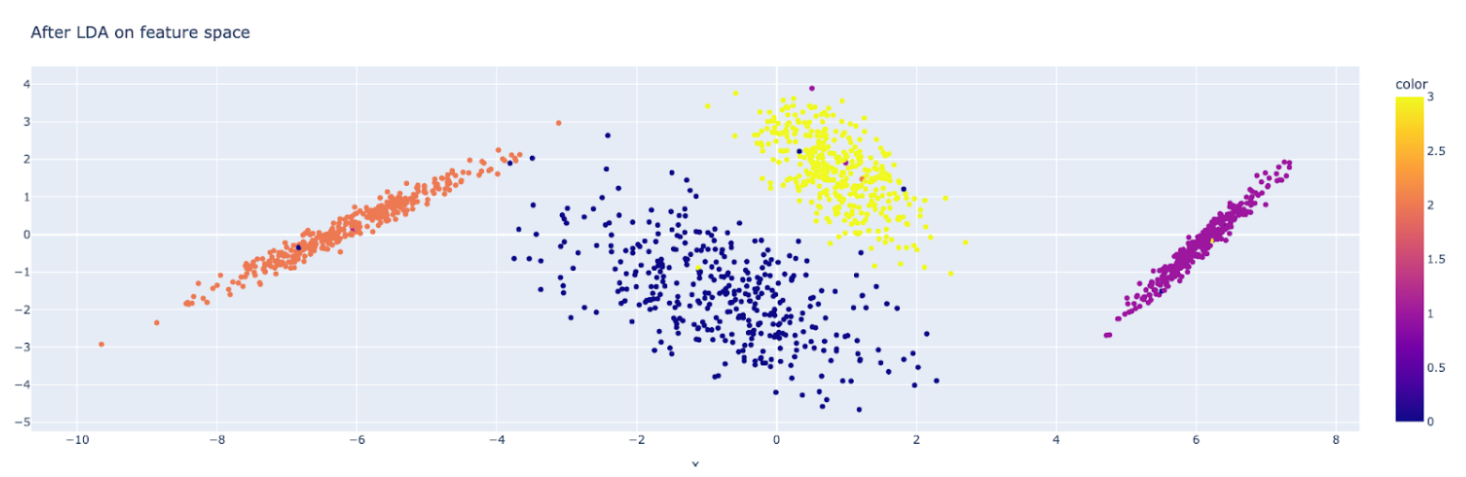
You may clearly see how LDA helped in separating the lessons! Be happy to experiment with a special variety of options, elements, and so on.
Function Extraction with t-SNE
t-SNE stands for t-distributed Stochastic Neighbor Embedding. It’s a non-linear method and is most well-liked for visualizing high-dimensional knowledge. This technique goals to protect the connection between knowledge factors whereas lowering the function house.
How does the algorithm work?
First, every knowledge level within the dataset is represented by a function vector. Subsequent, t-SNE calculates 2 chance distributions for every pair of information factors:
- The primary distribution represents the similarities between knowledge factors within the high-dimensional house
- The second distribution represents the similarities within the low-dimensional house
The algorithm then Minimizes the distinction between the 2 distributions, utilizing a price perform. Mapping to decrease dimensions: Lastly, it maps the info factors to the lower-dimensional house whereas preserving the native relationships.
Right here’s a code snippet to shortly implement t-SNE utilizing scikit study.
from sklearn.manifold import TSNE tsne = TSNE(n_components=3, random_state=42) X_tsne = tsne.fit_transform(X) tsne.kl_divergence_
Let’s shortly plot the function house diminished by t-SNE.
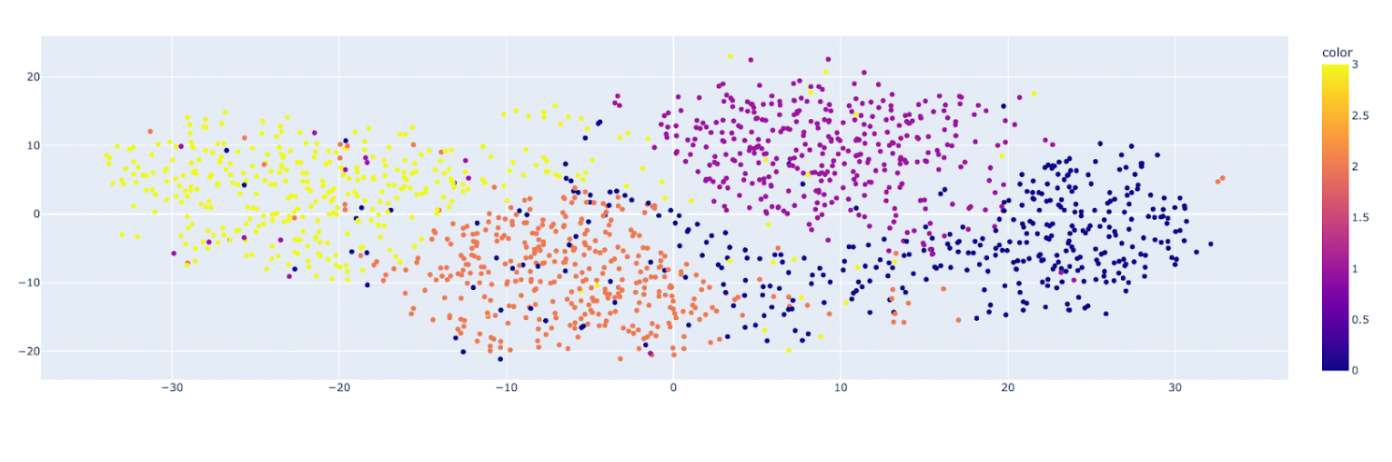
You may see the clusters for various lessons of the unique knowledge set and their distribution. Because it preserves native relationships, it’s the finest technique for visualizing clusters and patterns.
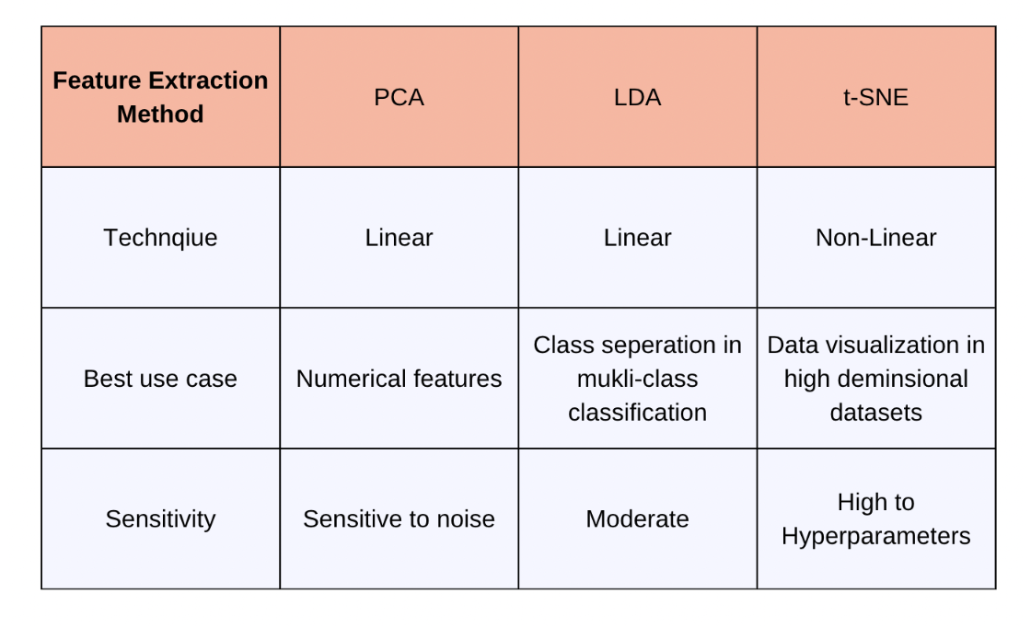
Specialised Function Extraction Methods
The strategies mentioned above are for tabular knowledge. Whereas coping with textual content or picture knowledge, now we have specialised function extraction strategies. I’ll briefly go over some common strategies:
- Function Extraction in Pure Language Processing (NLP): NLP fashions are constructed on massive corpora of textual content knowledge. Bag-of-Phrases (BoW) is a way that Represents textual content knowledge by counting the frequency of every phrase in a doc. Time period Frequency-Inverse Doc Frequency (TF-IDF) can be used. Methods like Latent Dirichlet Allocation (LDA) or Non-Detrimental Matrix Factorization (NMF) are helpful for extracting matters. They’re utilized in NLP duties like doc clustering, summarization, and content material advice.
- Function Extraction in Laptop Imaginative and prescient: In laptop imaginative and prescient, duties like picture processing classification, and object detection are highly regarded. The Histogram of Oriented Gradients (HOG) Computes histograms of gradient orientation in localized parts of a picture. Function Pyramid Networks (FPN) can mix options at completely different resolutions. Scale-Invariant Function Remodel (SIFT) can detect native options in photographs, strong to adjustments in scale, rotation, and illumination.
Conclusion
Function extraction is a vital a part of getting ready high quality enter knowledge and optimizing the sources. We are able to additionally reuse pre-trained function extractors or representations in associated duties, saving enormous bills. I hope you had a very good learn on the completely different strategies accessible in Python. When deciding which technique to make use of, take into account the precise targets of your evaluation and the character of your knowledge. If you’re primarily desirous about lowering dimensionality whereas retaining as a lot variance as attainable, PCA is an efficient selection. In case your goal is to maximise class separability for classification duties, LDA could also be extra applicable. For visualizing advanced numerical datasets and uncovering native constructions, t-SNE is the go-to selection.