

Information science is a multidisciplinary area that depends on scientific strategies, statistics, and Synthetic Intelligence (AI) algorithms to extract knowledgable and significant insights from knowledge. At its core, knowledge science is all about discovering helpful patterns in knowledge and presenting them to inform a narrative or make knowledgeable choices.
About us: Viso.ai supplies a sturdy end-to-end no-code laptop imaginative and prescient answer – Viso Suite. Our software program helps a number of main organizations begin with laptop imaginative and prescient and implement deep studying fashions effectively with minimal overhead for numerous downstream duties. Get a demo right here.
Information Science Course of
Information Acquisition
Step one within the knowledge science course of is to outline the analysis purpose. The subsequent step is to accumulate applicable knowledge that may allow you to derive insights. Information might come from relational databases, spreadsheets, inventories, exterior APIs, and many others. Throughout this stage, it’s cheap to test that the information is within the appropriate format to your functions.
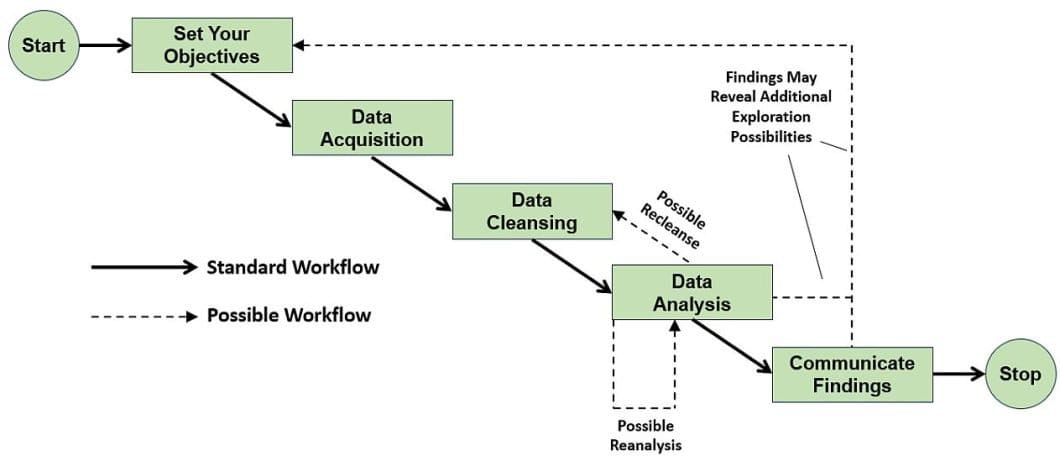
The forms of knowledge to accumulate are tailor-made in the direction of the kind of downside you wish to resolve. Subsequently, it’s essential to determine applicable datasets in the event that they exist already, or more than likely, create one ourselves. The information acquisition step might embrace sourcing knowledge throughout the group or leveraging exterior knowledge sources.
Information Preparation
The preparation of information entails three principal mini-steps. Information cleaning, knowledge transformation, and knowledge mixture. Furthermore, the information preparation step modifications the uncooked real-world knowledge. Then the scientists and analysts can analyze these knowledge with a pc, i.e. a machine studying algorithm.
First, you clear the datasets you’ve gotten obtained. You carry out this by figuring out lacking values, errors, outliers, and many others. Most machine studying algorithms can’t deal with lacking values, so changing or eradicating them is advisable. Additionally, on this section, we clear the outliers, i.e., knowledge factors removed from the noticed distribution.
Information transformation refers to aggregating knowledge, coping with categorical variables, and creating dummies to make sure consistency. Additionally, it reduces the variety of variables and retains essentially the most informative options. It discards the redundant options by scaling the information, and many others.
Information Exploration
The information exploration stage observes the information intently to grasp what it’s about. This step entails utilizing statistical metrics reminiscent of imply, median, mode, variance, and many others. to explain the information distribution. Frequent knowledge visualization strategies show the exploratory knowledge by bar charts, pie charts, histograms, line graphs, and many others.
By visualization, you possibly can determine anomalies in your knowledge and have a greater illustration of your knowledge content material. Anomalies within the exploratory knowledge evaluation are corrected by going again to the earlier step, knowledge preparation. As well as, knowledge exploration allows you to uncover patterns that you could be mix with area information and create new informative options.
Information Modeling
Within the knowledge modeling step, you’re taking a extra concerned strategy when accessing the information. Information modeling entails selecting an algorithm, normally from the associated fields of statistics, knowledge mining, or machine studying fashions. It then entails deciding which options to incorporate within the algorithm because the enter, executing the mannequin, and eventually evaluating the educated mannequin for efficiency.
You select options that present essentially the most variability throughout your knowledge distribution. You drop options that don’t drive the ultimate prediction or are uninformative. Methods reminiscent of Principal Element Evaluation (PCA) may also help to determine essential options.
The subsequent step entails selecting an applicable algorithm for the training activity. Totally different algorithms are higher suited to completely different studying issues. Logistic regression, Naive Bayes classifier, Help Vector Machines, choice bushes, and random forests are some common classification algorithms with good efficiency.
Linear regression and neural networks are sensible for regression duties. Numerous modeling algorithms exist, and scientists don’t know the perfect ones till they fight them. Subsequently, holding an open thoughts and relying closely on experimentation is essential.
Python Information Science Instruments and Libraries
Scikit-learn
Scikit-Be taught is the most well-liked machine-learning library within the Python programming ecosystem. Skicit is a mature Python library and comprises a number of algorithms for classification, regression, and clustering. Many widespread algorithms can be found in Scikit-Be taught and it exposes a constant interface to entry them.
Subsequently, studying easy methods to work with one classifier in Scikit-Be taught means you can work with different strategies. Additionally, it possesses strategies to coach a classifier whatever the underlying implementation.
You’d rely closely on Scikit-Be taught to your modeling duties as you dive deeper into knowledge science. Right here is a straightforward instance of making a classifier and coaching it on one of many bundled datasets.
# pattern choice tree classifier from sklearn import datasets from sklearn import metrics from sklearn.tree import DecisionTreeClassifier # load the iris datasets dataset = datasets.load_iris() # match a CART mannequin to the knowledge mannequin = DecisionTreeClassifier() mannequin.match(dataset.knowledge, dataset.goal) print(mannequin) # make predictions anticipated = dataset.goal predicted = mannequin.predict(dataset.knowledge) # summarize the match of the mannequin print(metrics.classification_report(anticipated, predicted)) print(metrics.confusion_matrix(anticipated, predicted))
Yow will discover extra details about Scikit-Be taught here.
NymPy – Numerical Python
NumPy is the principle numerical computing library for Python programming language. It supplies entry to a multidimensional array object and exposes a number of strategies that use operations over arrays. It helps linear algebra operations reminiscent of matrix multiplication, interior product, id operations, and many others.
NumPy interfaces with low-level libraries written in C and Fortran thereby producing sooner and extra environment friendly outputs. Because of this, Python management constructions like loops are usually not current in performing numerical computation (they’re considerably slower).
NumPy might be seen as a set of Python APIs that permits environment friendly scientific computing. E.g., NumPy arrays might be initiated by nested Python lists. The extent of nesting specifies the rank of the array.
import numpy as np a = np.array([[1, 2, 3], [4, 5, 6]]) # creates a rank 2 array print(kind(a)) print(a.form)
The array created is of rank 2 which implies that it’s a matrix. We will see this clearly from the dimensions of the array printed. It comprises 2 rows and three columns therefore measurement (m, n).
Yow will discover extra details about NumPy here.
ScyPy – Scientific Python
SciPy is a scientific computing library geared towards the fields of arithmetic, science, and engineering. It features along with NumPy and extends it by offering further modules for optimization, technical computing, statistics, sign processing, and many others.
Information science engineers make the most of SciPy principally together with different instruments within the ecosystem, like Pandas and Matplotlib. Right here is a straightforward utilization of SciPy that finds the inverse of a matrix.
from scipy import linalg z = np.array([[1,2],[3,4]]) print(linalg.inv(z))</code>
[ [-2. 1.]
[1.5 -0.5 ] ]
Yow will discover extra details about SciPy here.
Matplotlib
Matplotlib is a plotting library that integrates properly with NumPy and different numerical computation libraries in Python. Thus, it’s able to producing high quality plots and charts. Information scientists extensively use it in knowledge exploration the place visualization strategies are essential.
Matplotlib exposes an object-oriented API making it straightforward to create highly effective visualizations in Python. Word that to see the plot in Jupyter Notebooks it’s essential to use the Matplotlib inline magic command. Right here is an instance that makes use of Matplotlib to plot a sine waveform.
import matplotlib.pyplot as plt # compute the x and y coordinates for factors on a sine curve x = np.arange(0, 3 * np.pi, 0.1) y = np.sin(x) # plot the factors utilizing matplotlib plt.plot(x, y) plt.present() # Present plot by calling plt.present()
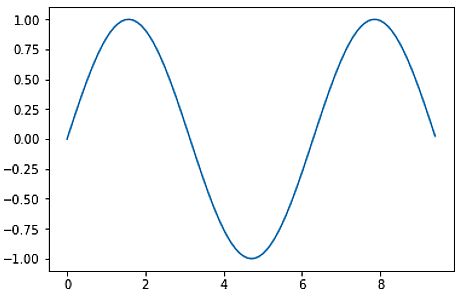
Yow will discover extra details about Matplotlib here.
Pandas
Pandas is a knowledge manipulation library in Python that gives high-performance knowledge constructions for time sequence knowledge. Information engineers make the most of Pandas extensively for knowledge evaluation and most knowledge loading, cleansing, and transformation duties. Information from the actual world is normally messy, comprises lacking values, and desires transformation.
Pandas settle for knowledge file varieties like CSV, Excel spreadsheets, Python pickle format, JSON, SQL, and many others. There exist two principal forms of Pandas knowledge constructions, sequence and knowledge body. Sequence is the information construction for a single knowledge column, whereas a knowledge body shops 2-dimensional knowledge, i.e. matrix. Subsequently, a knowledge body comprises knowledge saved in lots of columns.
The code under reveals easy methods to create a Sequence object in Pandas.
import pandas as pd s = pd.Sequence([1,3,5,np.nan,6,8]) print(s)
To create a knowledge body, you possibly can run the next code.
df = pd.DataFrame(np.random.randn(6,4), columns=listing('ABCD')) print(df)
Pandas hundreds the file codecs it helps into a knowledge body and manipulation of the information body happens utilizing Pandas strategies.
Yow will discover extra details about Pandas here.
Implementing Information Science Algorithms in Python
Binary and Multiclass Classification
A standard machine studying activity is to categorise a knowledge variable into two or extra classes. In binary classification, the scientists categorize the dataset into two courses. Consequently, they categorize knowledge into a number of courses based mostly on the classification guidelines in multi-class classification.
The Python code for the binary classification and its visualization is as under.
from mlxtend. consider import confusion_matrix y_target = [0, 0, 1, 0, 0, 1, 1, 1] y_predicted = [1, 0, 1, 0, 0, 0, 0, 1] cm = confusion_matrix(y_target=y_target, y_predicted=y_predicted) import matplotlib.pyplot as plt from mlxtend.plotting import plot_confusion_matrix fig, ax = plot_confusion_matrix(conf_mat=cm) plt.present()
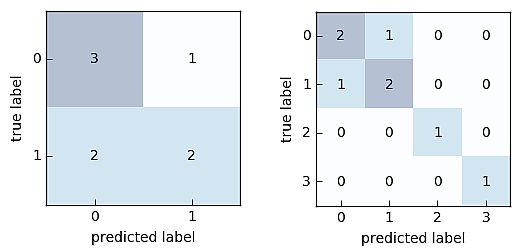
The Python code for the multi-class classification and its visualization is as under.
from mlxtend.consider import confusion_matrix y_target = [1, 1, 1, 0, 0, 2, 0, 3] y_predicted = [1, 0, 1, 0, 0, 2, 1, 3] cm = confusion_matrix(y_target=y_target, y_predicted=y_predicted, binary=False) import matplotlib.pyplot as plt from mlxtend.consider import confusion_matrix fig, ax = plot_confusion_matrix(conf_mat=cm) plt.present()
Resolution Timber Implementation
A choice tree is a machine studying algorithm that’s primarily used for classification that constructs a tree of potentialities. The branches within the tree symbolize choices and the leaves symbolize label classification.
The aim of a call tree is to create a construction the place samples in every department are homogenous or of the identical kind. It does this by splitting samples within the coaching knowledge in line with particular attributes that improve homogeneity in branches. Subsequently, the attributes type the choice node alongside which samples are separated.
We are going to current an instance utilizing Python, Scikit-Be taught, and choice bushes. We’d deal with a multi-class classification downside the place the problem is to categorise wine into three varieties utilizing options reminiscent of alcohol, colour depth, hue, and many others. The information we might use is from the wine recognition dataset by UC Irvine. Yow will discover the dataset and the accompanying code here.

First, we’ll load the dataset and use the Pandas head methodology to try it.
import numpy as np import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
dataset = pd.read_csv('wine.csv')
dataset.head(5)
options = dataset.drop(['Wine'], axis=1) labels = dataset['Wine']
To guage our mannequin properly, we divide the dataset right into a prepare and check break up. Then, the final step is to import the choice tree classifier and match it to our knowledge.
from sklearn.model_selection import train_test_split features_train, features_test, labels_train, labels_test= train_test_split(options, labels, test_size=0.25) from sklearn.tree import DecisionTreeClassifier classifier = DecisionTreeClassifier() classifier.match(features_train, labels_train)
Neural Community Implementation
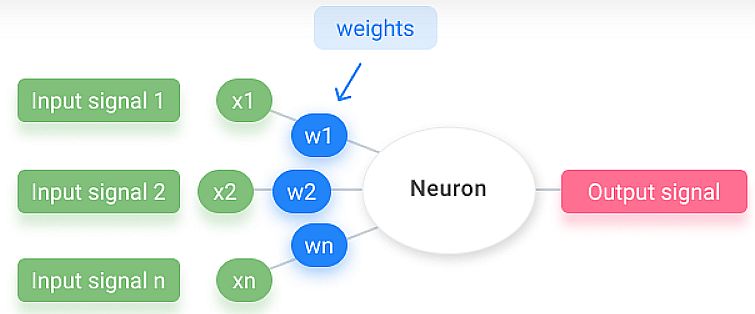
The neural community receives a number of enter alerts, and if the sum of the enter alerts exceeds a given threshold, it prompts a sign or stays calm in any other case. The algorithm learns the weights for the enter alerts to deduct the choice worth, which lets you differentiate between the 2 separate courses +1 and -1.
The next example is about iris flowers classification into two classes (class 1 and sophistication 2). Once we run the code – the perceptron iterates 5 instances. The bias and weights are: [[-0.04500809] [ 0.11048855]].
from mlxtend.knowledge import iris_data
from mlxtend.plotting import plot_decision_regions
from mlxtend.classifier import Perceptron
import matplotlib.pyplot as plt
# Loading Information
X, y = iris_data()
X = X[:, [0, 3]] # sepal size and petal width
X = X[0:100] # class 0 and sophistication 1
y = y[0:100] # class 0 and sophistication 1
# standardize
X[:,0] = (X[:,0] - X[:,0].imply()) / X[:,0].std()
X[:,1] = (X[:,1] - X[:,1].imply()) / X[:,1].std()
# Rosenblatt Perceptron
ppn = Perceptron(epochs=5, eta=0.05, random_seed=0, print_progress=3)
ppn.match(X, y)
plot_decision_regions(X, y, clf=ppn)
plt.title('Perceptron Rule')
plt.present()
print('Bias & Weights: %s' % ppn.w_)
plt.plot(vary(len(ppn.cost_)), ppn.cost_)
plt.xlabel('Iterations')
plt.ylabel('Missclassifications')
plt.present()
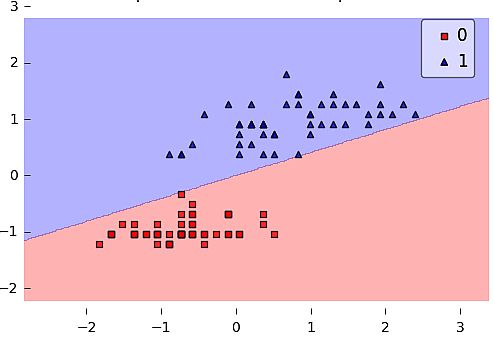
How can You profit from Information Analytics?
That was a fairly concise Python knowledge science tutorial. Information science in Python means that you can monitor your knowledge in actual time. You possibly can convey the information out of your deployed AI or machine studying purposes of information collectively in cloud dashboards.
Viso.ai allows you to discover your knowledge by way of advert hoc queries and dynamic drill-downs. With a single click on, you possibly can dive from overview to granular and uncover the basis trigger driving your numbers.
If you wish to discover extra comparable subjects, take a look at our different blogs: