

As a result of their excessive mannequin capability, Imaginative and prescient Transformer fashions have loved quite a lot of success in current occasions. Regardless of their efficiency, imaginative and prescient transformers fashions have one main flaw: their exceptional computation prowess comes at excessive computation prices, and it’s the explanation why imaginative and prescient transformers will not be the primary alternative for real-time purposes. To deal with this concern, a gaggle of builders launched EfficientViT, a household of high-speed imaginative and prescient transformers.
When engaged on EfficientViT, builders noticed that the velocity of the present transformer fashions is commonly bounded by inefficient reminiscence operations, particularly element-wise capabilities & tensor reshaping in MHSA or Multi-Head Self Consideration community. To deal with these inefficient reminiscence operations, EfficientViT builders have labored on a brand new constructing block utilizing a sandwich structure i.e the EfficientViT mannequin makes use of a single memory-bound Multi-Head Self Consideration community between environment friendly FFN layers that helps in enhancing reminiscence effectivity, and in addition enhancing the general channel communication. Moreover, the mannequin additionally discovers that focus maps usually have excessive similarities throughout heads that results in computational redundancy. To deal with the redundancy concern, the EfficientViT mannequin presents a cascaded group consideration module that feeds consideration heads with completely different splits of the complete function. The strategy not solely helps in saving computational prices, but in addition improves the eye variety of the mannequin.
Complete experiments carried out on the EfficientViT mannequin throughout completely different eventualities point out that the EfficientViT outperforms current environment friendly fashions for pc imaginative and prescient whereas putting an excellent trade-off between accuracy & velocity. So let’s take a deeper dive, and discover the EfficientViT mannequin in a bit of extra depth.
Imaginative and prescient Transformers stay one of the in style frameworks within the pc imaginative and prescient trade as a result of they provide superior efficiency, and excessive computational capabilities. Nevertheless, with continually enhancing accuracy & efficiency of the imaginative and prescient transformer fashions, the operational prices & computational overhead enhance as nicely. For instance, present fashions identified to supply state-of-the-art efficiency on ImageNet datasets like SwinV2, and V-MoE use 3B, and 14.7B parameters respectively. The sheer measurement of those fashions coupled with the computational prices & necessities make them virtually unsuitable for real-time gadgets & purposes.
The EfficientNet mannequin goals to discover the right way to enhance the efficiency of imaginative and prescient transformer fashions, and discovering the ideas concerned behind designing environment friendly & efficient transformer-based framework architectures. The EfficientViT mannequin is predicated on current imaginative and prescient transformer frameworks like Swim, and DeiT, and it analyzes three important components that have an effect on fashions interference speeds together with computation redundancy, reminiscence entry, and parameter utilization. Moreover, the mannequin observes that the velocity of imaginative and prescient transformer fashions in memory-bound, which implies that full utilization of computing energy in CPUs/GPUs is prohibited or restricted by reminiscence accessing delay, that leads to unfavorable impression on the runtime velocity of the transformers. Aspect-wise capabilities & tensor reshaping in MHSA or Multi-Head Self Consideration community are essentially the most memory-inefficient operations. The mannequin additional observes that optimally adjusting the ratio between FFN (feed ahead community) and MHSA, can assist in considerably decreasing the reminiscence entry time with out affecting the efficiency. Nevertheless, the mannequin additionally observes some redundancy within the consideration maps because of consideration head’s tendency to be taught related linear projections.
The mannequin is a closing cultivation of the findings through the analysis work for the EfficientViT. The mannequin encompasses a new black with a sandwich structure that applies a single memory-bound MHSA layer between the Feed Ahead Community or FFN layers. The method not solely reduces the time it takes to execute memory-bound operations in MHSA, but it surely additionally makes the whole course of extra reminiscence environment friendly by permitting extra FFN layers to facilitate the communication between completely different channels. The mannequin additionally makes use of a brand new CGA or Cascaded Group Consideration module that goals to make the computations simpler by decreasing the computational redundancy not solely within the consideration heads, but in addition will increase the depth of the community leading to elevated mannequin capability. Lastly, the mannequin expands the channel width of important community parts together with worth projections, whereas shrinking community parts with low worth like hidden dimensions within the feed ahead networks to redistribute the parameters within the framework.

As it may be seen within the above picture, the EfficientViT framework performs higher than present state-of-the-art CNN and ViT fashions by way of each accuracy, and velocity. However how did the EfficientViT framework handle to outperform among the present state-of-the-art frameworks? Let’s discover that out.
EfficientViT: Bettering the Effectivity of Imaginative and prescient Transformers
The EfficientViT mannequin goals to enhance the effectivity of the prevailing imaginative and prescient transformer fashions utilizing three views,
- Computational Redundancy.
- Reminiscence Entry.
- Parameter Utilization.
The mannequin goals to learn the way the above parameters have an effect on the effectivity of imaginative and prescient transformer fashions, and the right way to clear up them to realize higher outcomes with higher effectivity. Let’s speak about them in a bit extra depth.
Reminiscence Entry and Effectivity
One of many important components affecting the velocity of a mannequin is the reminiscence entry overhead or MAO. As it may be seen within the picture beneath, a number of operators in transformer together with element-wise addition, normalization, and frequent reshaping are memory-inefficient operations, as a result of they require entry to completely different reminiscence models which is a time consuming course of.
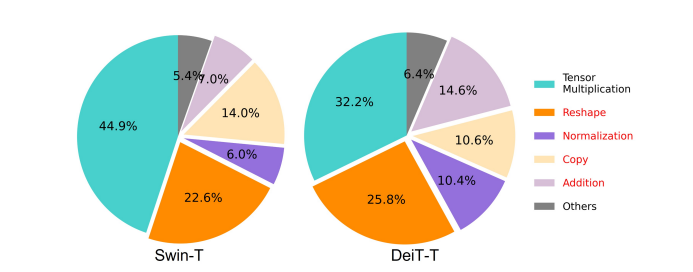
Though there are some current strategies that may simplify the usual softmax self consideration computations like low-rank approximation, and sparse consideration, they usually provide restricted acceleration, and degrade the accuracy.
However, the EfficientViT framework goals to chop down the reminiscence entry value by decreasing the quantity of memory-inefficient layers within the framework. The mannequin scales down the DeiT-T and Swin-T to small subnetworks with a better interference throughput of 1.25X and 1.5X, and compares the efficiency of those subnetworks with proportions of the MHSA layers. As it may be seen within the picture beneath, when carried out, the method boosts the accuracy of MHSA layers by about 20 to 40%.

Computation Effectivity
MHSA layers are inclined to embed the enter sequence into a number of subspaces or heads, and computes the eye maps individually, an method that’s identified to spice up efficiency. Nevertheless, consideration maps will not be computationally low cost, and to discover the computational prices, the EfficientViT mannequin explores the right way to cut back redundant consideration in smaller ViT fashions. The mannequin measures the utmost cosine similarity of every head & the remaining heads inside each block by coaching the width downscaled DeiT-T and Swim-T fashions with 1.25× inference speed-up. As it may be noticed within the picture beneath, there’s a excessive variety of similarity between consideration heads which means that mannequin incurs computation redundancy as a result of quite a few heads are inclined to be taught related projections of the precise full function.

To encourage the heads to be taught completely different patterns, the mannequin explicitly applies an intuitive answer by which every head is fed solely a portion of the complete function, a way that resembles the concept of group convolution. The mannequin trains completely different facets of the downscaled fashions that function modified MHSA layers.
Parameter Effectivity
Common ViT fashions inherit their design methods like utilizing an equal width for projections, setting enlargement ratio to 4 in FFN, and rising heads over phases from NLP transformers. The configurations of those parts should be re-designed rigorously for light-weight modules. The EfficientViT mannequin deploys Taylor structured pruning to search out the important parts within the Swim-T, and DeiT-T layers mechanically, and additional explores the underlying parameter allocation ideas. Beneath sure useful resource constraints, the pruning strategies take away unimportant channels, and preserve the essential ones to make sure highest attainable accuracy. The determine beneath compares the ratio of channels to the enter embeddings earlier than and after pruning on the Swin-T framework. It was noticed that: Baseline accuracy: 79.1%; pruned accuracy: 76.5%.

The above picture signifies that the primary two phases of the framework protect extra dimensions, whereas the final two phases protect a lot much less dimensions. It would imply {that a} typical channel configuration that doubles the channel after each stage or makes use of equal channels for all blocks, could lead to substantial redundancy within the closing few blocks.
Environment friendly Imaginative and prescient Transformer : Structure
On the premise of the learnings obtained through the above evaluation, builders labored on creating a brand new hierarchical mannequin that gives quick interference speeds, the EfficientViT mannequin. Let’s have an in depth take a look at the construction of the EfficientViT framework. The determine beneath offers you a generic thought of the EfficientViT framework.
Constructing Blocks of the EfficientViT Framework
The constructing block for the extra environment friendly imaginative and prescient transformer community is illustrated within the determine beneath.

The framework consists of a cascaded group consideration module, memory-efficient sandwich structure, and a parameter reallocation technique that concentrate on enhancing the effectivity of the mannequin by way of computation, reminiscence, and parameter, respectively. Let’s speak about them in better element.
Sandwich Format
The mannequin makes use of a brand new sandwich structure to construct a simpler & environment friendly reminiscence block for the framework. The sandwich structure makes use of much less memory-bound self-attention layers, and makes use of extra memory-efficient feed ahead networks for channel communication. To be extra particular, the mannequin applies a single self-attention layer for spatial mixing that’s sandwiched between the FFN layers. The design not solely helps in decreasing the reminiscence time consumption due to self-attention layers, but in addition permits efficient communication between completely different channels inside the community because of the usage of FFN layers. The mannequin additionally applies an additional interplay token layer earlier than every feed ahead community layer utilizing a DWConv or Misleading Convolution, and enhances mannequin capability by introducing inductive bias of the native structural info.
Cascaded Group Consideration
One of many main points with MHSA layers is the redundancy in consideration heads which makes computations extra inefficient. To resolve the difficulty, the mannequin proposes CGA or Cascaded Group Consideration for imaginative and prescient transformers, a brand new consideration module that takes inspiration from group convolutions in environment friendly CNNs. On this method, the mannequin feeds particular person heads with splits of the complete options, and due to this fact decomposes the eye computation explicitly throughout heads. Splitting the options as a substitute of feeding full options to every head saves computation, and makes the method extra environment friendly, and the mannequin continues to work on enhancing the accuracy & its capability even additional by encouraging the layers to be taught projections on options which have richer info.

Parameter Reallocation
To enhance the effectivity of parameters, the mannequin reallocates the parameters within the community by increasing the width of the channel of essential modules whereas shrinking the channel width of not so necessary modules. Primarily based on the Taylor evaluation, the mannequin both units small channel dimensions for projections in every head throughout each stage or the mannequin permits the projections to have the identical dimension because the enter. The enlargement ratio of the feed ahead community can also be introduced right down to 2 from 4 to assist with its parameter redundancy. The proposed reallocation technique that the EfficientViT framework implements, allots extra channels to necessary modules to permit them to be taught representations in a excessive dimensional house higher that minimizes the lack of function info. Moreover, to hurry up the interference course of & improve the effectivity of the mannequin even additional, the mannequin mechanically removes the redundant parameters in unimportant modules.

The overview of the EfficientViT framework will be defined within the above picture the place the elements,
- Structure of EfficientViT,
- Sandwich Format block,
- Cascaded Group Consideration.
EfficientViT : Community Architectures

The above picture summarizes the community structure of the EfficientViT framework. The mannequin introduces an overlapping patch embedding [20,80] that embeds 16×16 patches into C1 dimension tokens that enhances the mannequin’s capability to carry out higher in low-level visible illustration studying. The structure of the mannequin includes three phases the place every stage stacks the proposed constructing blocks of the EfficientViT framework, and the variety of tokens at every subsampling layer (2× subsampling of the decision) is decreased by 4X. To make subsampling extra environment friendly, the mannequin proposes a subsample block that additionally has the proposed sandwich structure with the exception that an inverted residual block replaces the eye layer to cut back the lack of info throughout sampling. Moreover, as a substitute of standard LayerNorm(LN), the mannequin makes use of BatchNorm(BN) as a result of BN will be folded into the previous linear or convolutional layers that offers it a runtime benefit over the LN.
EfficientViT Mannequin Household
The EfficientViT mannequin household consists of 6 fashions with completely different depth & width scales, and a set variety of heads is allotted for every stage. The fashions use fewer blocks within the preliminary phases when in comparison with the ultimate phases, a course of much like the one adopted by MobileNetV3 framework as a result of the method of early stage processing with bigger resolutions is time consuming. The width is elevated over phases with a small issue to cut back redundancy within the later phases. The desk hooked up beneath supplies the architectural particulars of the EfficientViT mannequin household the place C, L, and H seek advice from width, depth, and variety of heads within the specific stage.

EfficientViT: Mannequin Implementation and Outcomes
The EfficientViT mannequin has a complete batch measurement of two,048, is constructed with Timm & PyTorch, is skilled from scratch for 300 epochs utilizing 8 Nvidia V100 GPUs, makes use of a cosine studying charge scheduler, an AdamW optimizer, and conducts its picture classification experiment on ImageNet-1K. The enter pictures are randomly cropped & resized into decision of 224×224. For the experiments that contain downstream picture classification, the EfficientViT framework finetunes the mannequin for 300 epochs, and makes use of AdamW optimizer with a batch measurement of 256. The mannequin makes use of RetineNet for object detection on COCO, and proceeds to coach the fashions for an extra 12 epochs with the similar settings.
Outcomes on ImageNet
To investigate the efficiency of EfficientViT, it’s in contrast towards present ViT & CNN fashions on the ImageNet dataset. The outcomes from the comparability are reported within the following determine. As it may be seen that the EfficientViT mannequin household outperforms the present frameworks generally, and manages to realize a really perfect trade-off between velocity & accuracy.

Comparability with Environment friendly CNNs, and Environment friendly ViTs
The mannequin first compares its efficiency towards Environment friendly CNNs like EfficientNet and vanilla CNN frameworks like MobileNets. As it may be seen that when in comparison with MobileNet frameworks, the EfficientViT fashions get hold of a greater top-1 accuracy rating, whereas working 3.0X and a couple of.5X sooner on Intel CPU and V100 GPU respectively.
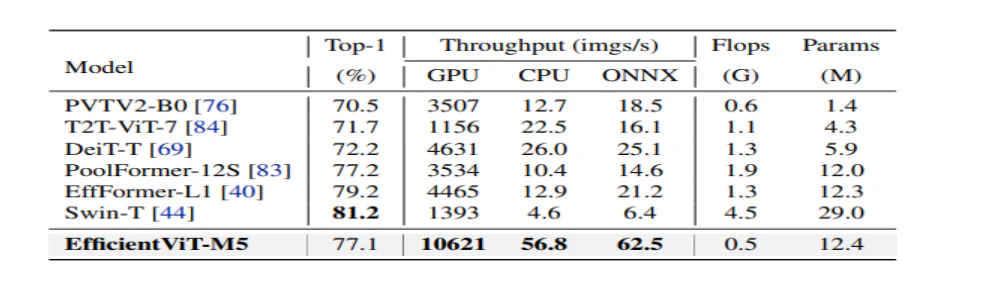
The above determine compares the EfficientViT mannequin efficiency with state-of-the-art large-scale ViT fashions working on the ImageNet-1K dataset.
Downstream Picture Classification
The EfficientViT mannequin is utilized on varied downstream duties to check the mannequin’s switch studying talents, and the beneath picture summarizes the outcomes of the experiment. As it may be noticed, the EfficientViT-M5 mannequin manages to realize higher or related outcomes throughout all datasets whereas sustaining a a lot greater throughput. The one exception is the Vehicles dataset, the place the EfficientViT mannequin fails to ship in accuracy.

Object Detection
To investigate EfficientViT’s skill to detect objects, it’s in contrast towards environment friendly fashions on the COCO object detection process, and the beneath picture summarizes the outcomes of the comparability.

Remaining Ideas
On this article, we’ve got talked about EfficientViT, a household of quick imaginative and prescient transformer fashions that use cascaded group consideration, and supply memory-efficient operations. In depth experiments performed to investigate the efficiency of the EfficientViT have proven promising outcomes because the EfficientViT mannequin outperforms present CNN and imaginative and prescient transformer fashions generally. We now have additionally tried to supply an evaluation on the components that play a task in affecting the interference velocity of imaginative and prescient transformers.