


Transformers are the backbones to power-up fashions like BERT, the GPT collection, and ViT. Nonetheless, its consideration mechanism has quadratic complexity, making it difficult for lengthy sequences. To deal with this, numerous token mixers with linear complexity have been developed.
Lately, RNN-based fashions have gained consideration for his or her environment friendly coaching and inference on lengthy sequences and have proven promise as backbones for giant language fashions.
Impressed by these capabilities, researchers have explored utilizing Mamba in visible recognition duties, resulting in fashions like Imaginative and prescient Mamba, VMamba, LocalMamba, and PlainMamba. Regardless of this, experiments reveal that state house mannequin or SSM-based fashions for imaginative and prescient underperform in comparison with state-of-the-art convolutional and attention-based fashions.
This latest paper doesn’t concentrate on designing new visible Mamba fashions. As an alternative, investigates a important analysis query: Is Mamba essential for visible recognition duties?
What’s Mamba?
Mamba is a deep studying structure developed by researchers from Carnegie Mellon College and Princeton College, designed to handle the constraints of transformer fashions, particularly for lengthy sequences. It makes use of the Structured State House sequence (S4) mannequin, combining strengths from continuous-time, recurrent, and convolutional fashions to effectively deal with lengthy dependencies and irregularly sampled knowledge.
Lately, researchers have tailored Mamba for pc imaginative and prescient duties, just like how Imaginative and prescient Transformers (ViT) are used. Imaginative and prescient Mamba (ViM) improves effectivity by using a bidirectional state house mannequin (SSM), addressing the excessive computational calls for of conventional Transformers, particularly for high-resolution photographs.
Mamba Structure:
Mamba enhances the S4 mannequin by introducing a novel choice mechanism that adapts parameters based mostly on enter, permitting it to concentrate on related info inside sequences. This time-varying framework improves computational effectivity.
Mamba additionally employs a hardware-aware algorithm for environment friendly computation on trendy {hardware} like GPUs, optimizing efficiency and reminiscence utilization. The structure integrates SSM design with MLP blocks, making it appropriate for numerous knowledge sorts, together with language, audio, and genomics.
Paperspace GPUs present a strong and versatile cloud-based resolution for coaching and deploying deep studying fashions, making them well-suited for duties like these involving the Mamba structure. With high-performance GPUs, Paperspace permits researchers to effectively deal with the computational calls for of Mamba fashions, notably when coping with lengthy sequences and complicated token mixing operations.
The platform helps standard deep studying libraries like PyTorch, enabling seamless integration and streamlined workflows. Using Paperspace GPUs can considerably speed up the coaching course of, improve mannequin efficiency, and facilitate large-scale experimentation and improvement of superior fashions.
Mamba Variants:
- MambaByte: A token-free language mannequin that processes uncooked byte sequences, eliminating tokenization and its related biases.
- Mamba Combination of Specialists (MOE): Integrates Combination of Specialists with Mamba, enhancing effectivity and scalability by alternating Mamba and MOE layers.
- Imaginative and prescient Mamba (ViM):
ViM adapts SSMs for visible knowledge processing, utilizing bidirectional Mamba blocks for visible sequence encoding. This reduces computational calls for and exhibits improved efficiency on duties like ImageNet classification, COCO object detection, and ADE20k semantic segmentation. - Jamba:
Developed by AI21 Labs, Jamba is a hybrid transformer and Mamba SSM structure with 52 billion parameters and a context window of 256k tokens.
Demo utilizing Paperspace
Deliver this undertaking to life
Earlier than we begin working with the mannequin, we are going to clone the repo and set up few essential packages,
!pip set up timm==0.6.11
!git clone https://github.com/yuweihao/MambaOut.git
!pip set up gradioMoreover, now we have added a hyperlink that can be utilized to entry the pocket book that runs the steps and can carry out inferences with MambaOut.
cd /MambaOutThe cell beneath will make it easier to run the gradio net app.
!python gradio_demo/app.pyMambaOut Demo utilizing Paperspace
RNN-like fashions and causal consideration
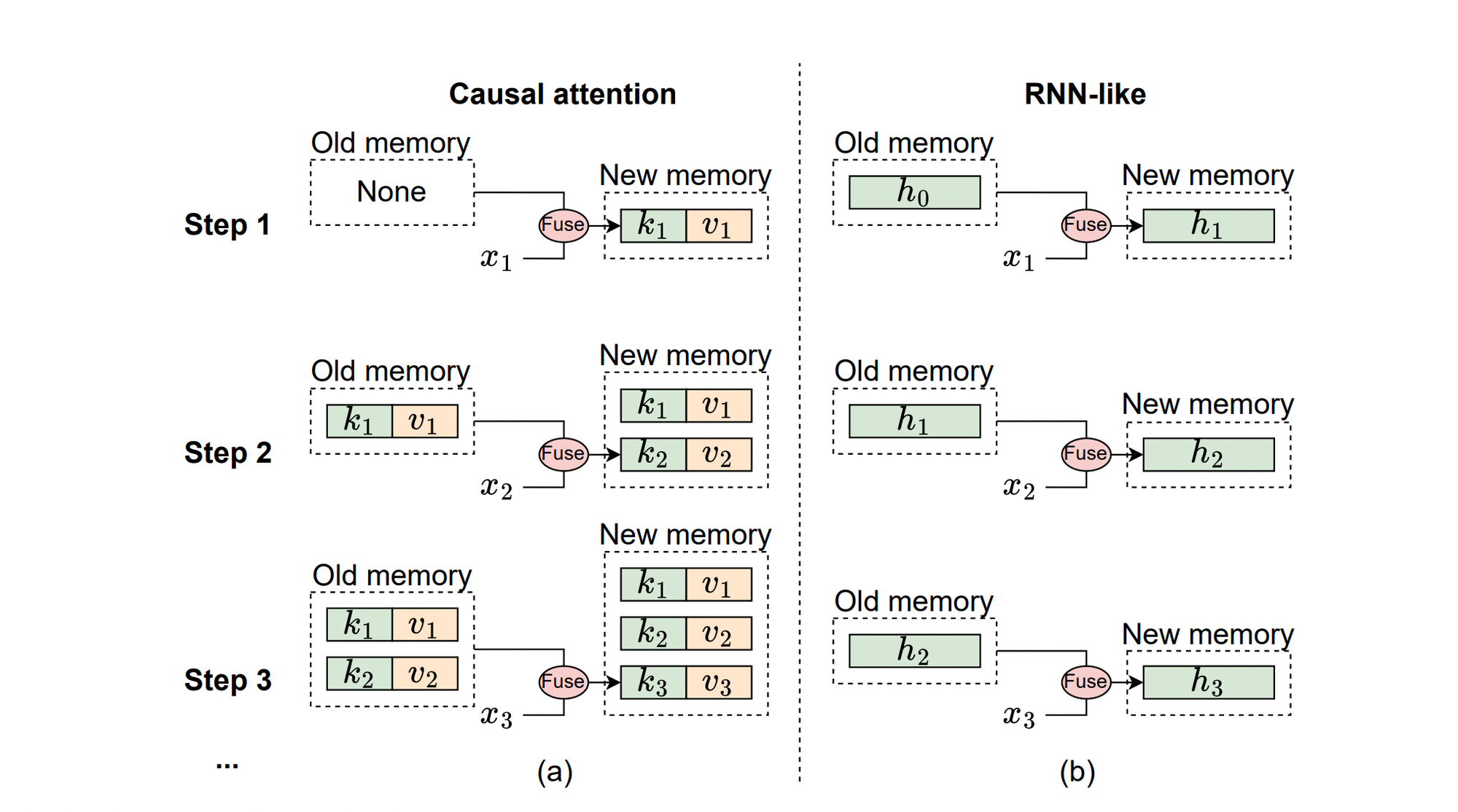
The beneath illustration explains the mechanism of causal consideration and RNN-like fashions from a reminiscence perspective, the place xi represents the enter token on the i-th step.
(a) Causal Consideration: Shops all earlier tokens’ keys (ok) and values (v) as reminiscence. The reminiscence is up to date by regularly including the present token’s key and worth, making it lossless. Nonetheless, the computational complexity of integrating previous reminiscence with present tokens will increase because the sequence lengthens. Thus, consideration works properly with quick sequences however struggles with longer ones.
(b) RNN-like Fashions: Compress earlier tokens right into a fixed-size hidden state (h) that serves as reminiscence. This fastened measurement means RNN reminiscence is inherently lossy and might’t match the lossless reminiscence capability of consideration fashions. Nonetheless, RNN-like fashions excel in processing lengthy sequences, because the complexity of merging previous reminiscence with present enter stays fixed, no matter sequence size.
Mamba is especially well-suited for duties that require causal token mixing attributable to its recurrent properties. Particularly, Mamba excels in duties with the next traits:
- The duty entails processing lengthy sequences.
- The duty requires causal token mixing.
The subsequent query rises is does visible recognition duties have very lengthy sequences?
For picture classification on ImageNet, the everyday enter picture measurement is 224×224, leading to 196 tokens with a patch measurement of 16×16. This quantity is far smaller than the thresholds for long-sequence duties, so ImageNet classification isn’t thought-about a long-sequence job.
For object detection and occasion segmentation on COCO, with a picture measurement of 800×1280, and for semantic segmentation on ADE20K (ADE20K is a widely-used dataset for the semantic segmentation job, consisting of 150 semantic classes. The dataset consists of 20,000 photographs within the coaching set and a pair of,000 photographs within the validation set), with a picture measurement of 512×2048, the variety of tokens is round 4,000 with a patch measurement of 16×16. Since 4,000 tokens exceed the brink for small sequences and are near the bottom threshold, each COCO detection and ADE20K segmentation are thought-about long-sequence duties.
Framework of MambaOut
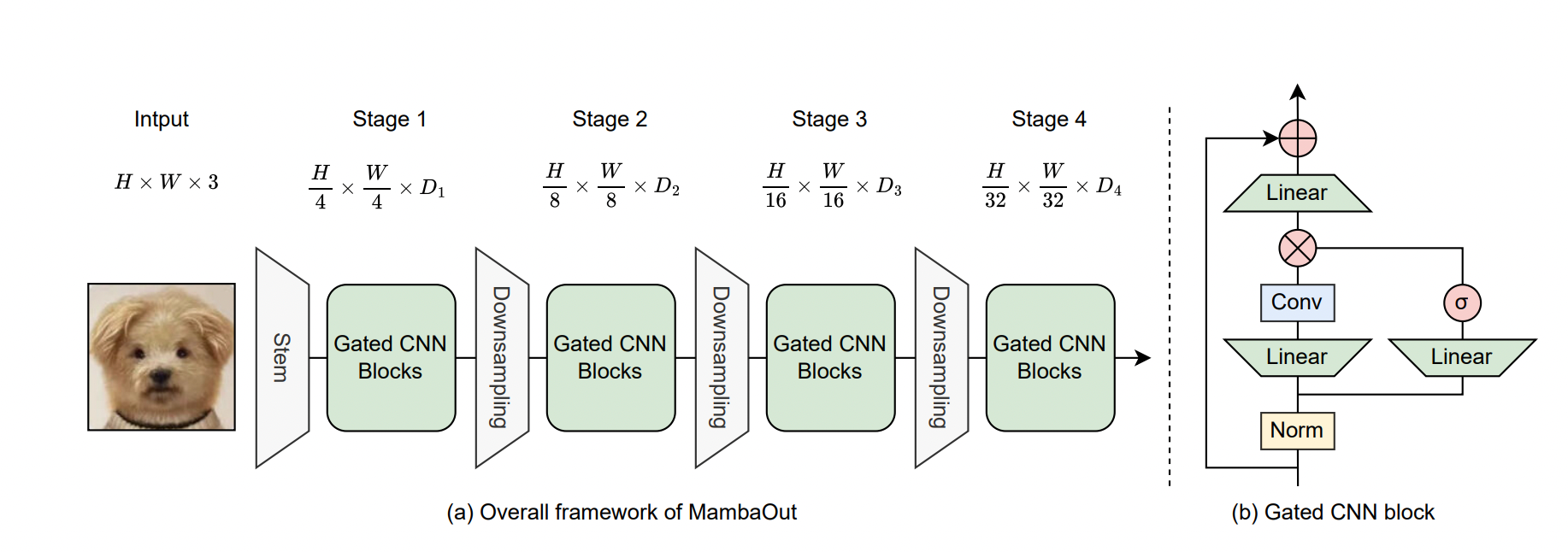
Fig (a) represents general Framework of MambaOut for Visible Recognition:
MambaOut is designed for visible recognition and follows a hierarchical structure just like ResNet. It consists of 4 phases, every with totally different channel dimensions, denoted as Di. This hierarchical construction permits the mannequin to course of visible info at a number of ranges of abstraction, enhancing its capacity to acknowledge advanced patterns in photographs.
(b) Structure of the Gated CNN Block:
The Gated CNN block is a part throughout the MambaOut framework. It differs from the Mamba block in that it doesn’t embody the State House Mannequin (SSM). Whereas each blocks use convolutional neural networks (CNNs) with gating mechanisms to manage info circulate, the absence of SSM within the Gated CNN block means it doesn’t have the identical capability for dealing with lengthy sequences and temporal dependencies because the Mamba block, which includes SSM for these functions.
The first distinction between the Gated CNN and the Mamba block lies within the presence of the State House Mannequin (SSM).
In MambaOut, a depthwise convolution with a 7×7 kernel measurement is used because the token mixer of the Gated CNN, just like ConvNeXt. Much like ResNet, MambaOut is constructed utilizing a 4-stage framework by stacking Gated CNN blocks at every stage, as illustrated in Determine.
Earlier than we transfer additional listed here are the speculation concerning the need of introducing Mamba for visible recognition.
Speculation 1: It isn’t essential to introduce SSM for picture classification on ImageNet, as this job doesn’t meet Attribute 1 or Attribute 2.
Speculation 2: It’s nonetheless worthwhile to additional discover the potential of SSM for visible detection and segmentation since these duties align with Attribute 1, regardless of not fulfilling Attribute 2.
Coaching
Picture classification on ImageNet
- ImageNet is used because the benchmark for picture classification, with 1.3 million coaching photographs and 50,000 validation photographs.
- Coaching follows the DeiT scheme with out distillation, together with numerous knowledge augmentation strategies and regularization strategies.
- AdamW optimizer is used for coaching, with a studying charge scaling rule of lr = batchsize/1024 * 10^-3, leading to a studying charge of 0.004 with a batch measurement of 4096.
- MambaOut fashions are applied utilizing PyTorch and timm libraries and educated on TPU v3.
Outcomes
- MambaOut fashions, which don’t incorporate SSM, constantly outperform visible Mamba fashions throughout all mannequin sizes on ImageNet.
- For instance, the MambaOut-Small mannequin achieves a top-1 accuracy of 84.1%, outperforming LocalVMamba-S by 0.4% whereas requiring solely 79% of the MACs.
- These outcomes assist Speculation 1 , suggesting that introducing SSM for picture classification on ImageNet is pointless.
- Visible Mamba fashions at the moment lag considerably behind state-of-the-art convolution and a spotlight fashions on ImageNet.
- As an example, CAFormer-M36 outperforms all visible Mamba fashions of comparable measurement by greater than 1% accuracy.
- Future analysis aiming to problem Speculation 1 might have to develop visible Mamba fashions with token mixers of convolution and SSM to attain state-of-the-art efficiency on ImageNet.
Object detection & occasion segmentation on COCO
- COCO 2017 is used because the benchmark for object detection and occasion segmentation.
- MambaOut is utilized because the spine inside Masks R-CNN, initialized with weights pre-trained on ImageNet.
- Coaching follows the usual 1× schedule of 12 epochs, with coaching photographs resized to have a shorter facet of 800 pixels and an extended facet not exceeding 1333 pixels.
- The AdamW optimizer is employed with a studying charge of 0.0001 and a complete batch measurement of 16.
- Implementation is completed utilizing the PyTorch and mmdetection libraries, with FP16 precision utilized to save lots of coaching prices.
- Experiments are carried out on 4 NVIDIA 4090 GPUs.
Outcomes
- Whereas MambaOut can outperform some visible Mamba fashions in object detection and occasion segmentation on COCO, it nonetheless lags behind state-of-the-art visible Mambas like VMamba and LocalVMamba.
- For instance, MambaOut-Tiny because the spine for Masks R-CNN trails VMamba-T by 1.4 APb and 1.1 APm.
- This efficiency distinction highlights the advantages of integrating Mamba in long-sequence visible duties, supporting Speculation 2.
- Nonetheless, visible Mamba nonetheless exhibits a major efficiency hole in comparison with state-of-the-art convolution-attention-hybrid fashions like TransNeXt. Visible Mamba must show its effectiveness by outperforming different state-of-the-art fashions in visible detection duties.
Semantic segmentation on ADE20K
- ADE20K is used because the benchmark for the semantic segmentation job, comprising 150 semantic classes with 20,000 photographs within the coaching set and a pair of,000 photographs within the validation set.
- Mamba is utilized because the spine for UperNet, with initialization from ImageNet pre-trained weights.
- Coaching is carried out utilizing the AdamW optimizer with a studying charge of 0.0001 and a batch measurement of 16 for 160,000 iterations.
- Implementation is completed utilizing the PyTorch and mmsegmentation libraries, with experiments carried out on 4 NVIDIA 4090 GPUs, using FP16 precision to reinforce coaching pace.
Outcomes
- Much like object detection on COCO, the efficiency development for semantic segmentation on ADE20K exhibits that MambaOut can outperform some visible Mamba fashions however can not match the outcomes of state-of-the-art Mamba fashions.
- For instance, LocalVMamba-T surpasses MambaOut-Tiny by 0.5 mIoU in each single scale (SS) and multi-scale (MS) evaluations, additional supporting Speculation 2 empirically.
- Moreover, visible Mamba fashions proceed to exhibit notable efficiency deficits in comparison with extra superior hybrid fashions that combine convolution and a spotlight mechanisms, resembling SG-Former and TransNeXt.
- Visible Mamba must additional show its strengths in long-sequence modeling by attaining stronger efficiency within the visible segmentation job.
Conclusion
Mamba mechanism is greatest suited to duties with lengthy sequences and autoregressive traits. Mamba exhibits potential for visible detection and segmentation duties, which do align with long-sequence traits. MambaOut fashions that surpass all visible Mamba fashions on ImageNet, but nonetheless lag behind state-of-the-art visible Mamba fashions.
Nonetheless, attributable to computational useful resource limitations, this paper focuses on verifying the Mamba idea for visible duties. Future analysis might additional discover Mamba and RNN ideas, in addition to the mixing of RNN and Transformer for giant language fashions (LLMs) and enormous multimodal fashions (LMMs), probably resulting in new developments in these areas.