

Sequence fashions are CNN-based deep studying fashions designed to course of sequential information. The info, the place the context is offered by the earlier components, is necessary for prediction in contrast to the plain CNNs, which course of information organized right into a grid-like construction (photographs).
Purposes of Sequence modeling are seen in varied fields. For instance, it’s utilized in Pure Language Processing (NLP) for language translation, textual content era, and sentiment classification. It’s extensively utilized in speech recognition the place the spoken language is transformed into textual type, for instance in music era and forecasting shares.
On this weblog, we are going to delve into varied varieties of sequential architectures, how they work and differ from one another, and look into their purposes.
About Us: At Viso.ai, we energy Viso Suite, essentially the most full end-to-end pc imaginative and prescient platform. We offer all the pc imaginative and prescient companies and AI imaginative and prescient expertise you’ll want. Get in contact with our crew of AI consultants and schedule a demo to see the important thing options.
Historical past of Sequence Fashions
The evolution of sequence fashions mirrors the general progress in deep studying, marked by gradual enhancements and vital breakthroughs to beat the hurdles of processing sequential information. The sequence fashions have enabled machines to deal with and generate intricate information sequences with ever-growing accuracy and effectivity. We are going to talk about the next sequence fashions on this weblog:
- Recurrent Neural Networks (RNNs): The idea of RNNs was launched by John Hopfields and others within the Eighties.
- Lengthy Brief-Time period Reminiscence (LSTM): In 1997, Sepp Hochreiter and Jürgen Schmidhuber proposed LSTM community fashions.
- Gated Recurrent Unit (GRU): Kyunghyun Cho and his colleagues launched GRUs in 2014, a simplified variation of LSTM.
- Transformers: The Transformer mannequin was launched by Vaswani et al. in 2017, creating a serious shift in sequence modeling.
Sequence Mannequin 1: Recurrent Neural Networks (RNN)
RNNs are merely a feed-forward community that has an inner reminiscence that helps in predicting the following factor in sequence. This reminiscence function is obtained because of the recurrent nature of RNNs, the place it makes use of a hidden state to collect context in regards to the sequence given as enter.
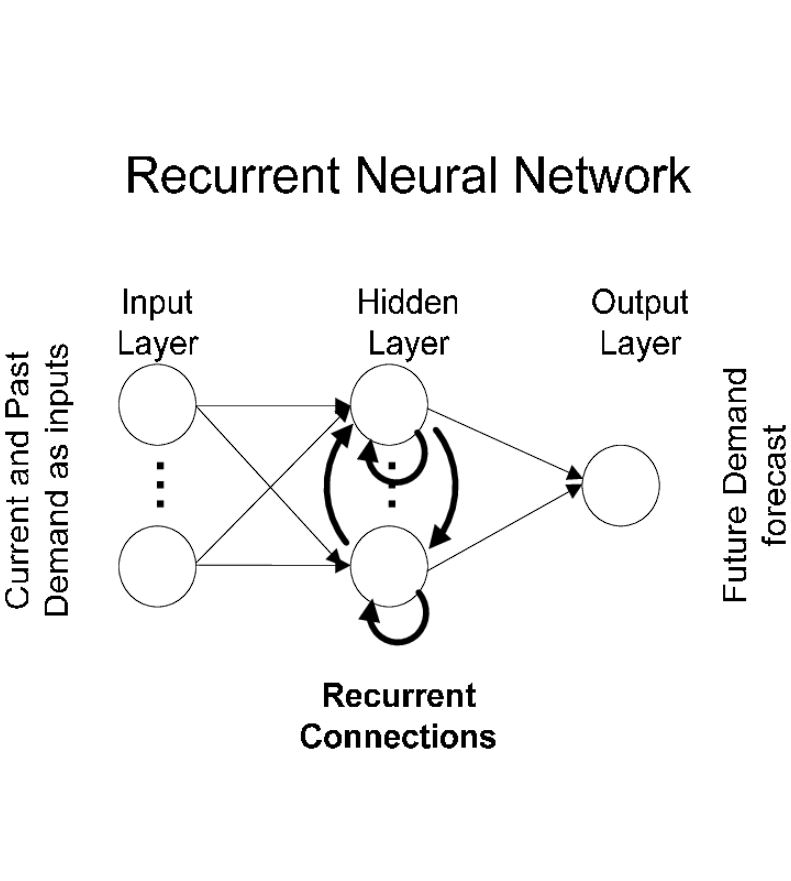
Not like feed-forward networks that merely carry out transformations on the enter offered, RNNs use their inner reminiscence to course of inputs. Due to this fact regardless of the mannequin has discovered within the earlier time step influences its prediction.
This nature of RNNs is what makes them helpful for purposes comparable to predicting the following phrase (google autocomplete) and speech recognition. As a result of to be able to predict the following phrase, it’s essential to know what the earlier phrase was.
Allow us to now have a look at the structure of RNNs.
Enter
Enter given to the mannequin at time step t is normally denoted as x_t
For instance, if we take the phrase “kittens”, the place every letter is taken into account as a separate time step.
Hidden State
That is the necessary a part of RNN that permits it to deal with sequential information. A hidden state at time t is represented as h_t which acts as a reminiscence. Due to this fact, whereas making predictions, the mannequin considers what it has discovered over time (the hidden state) and combines it with the present enter.
RNNs vs Feed Ahead Community
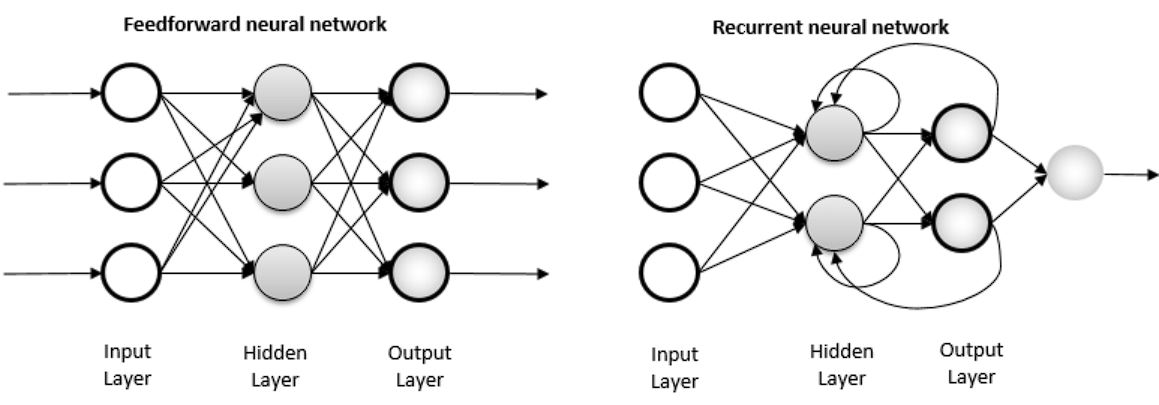
In a typical feed-forward neural community or Multi-Layer Perceptron, the information flows solely in a single course, from the enter layer, by the hidden layers, and to the output layer. There are not any loops within the community, and the output of any layer doesn’t have an effect on that very same layer sooner or later. Every enter is unbiased and doesn’t have an effect on the following enter, in different phrases, there are not any long-term dependencies.
In distinction in a RNN mannequin, the data cycles by a loop. When the mannequin makes a prediction, it considers the present enter and what it has discovered from the earlier inputs.
Weights
There are 3 completely different weights utilized in RNNs:
- Enter-to-Hidden Weights (W_xh): These weights join the enter to the hidden state.
- Hidden-to-Hidden Weights (W_hh): These weights join the earlier hidden state to the present hidden state and are discovered by the community.
- Hidden-to-Output Weights (W_hy): These weights join the hidden state to the output.
Bias Vectors
Two bias vectors are used, one for the hidden state and the opposite for the output.
Activation Capabilities
The 2 features used are tanh and ReLU, the place tanh is used for the hidden state.
A single move within the community seems to be like this:
At time step t, given enter x_t and former hidden state h_t-1:
- The community computes the intermediate worth z_t utilizing the enter, earlier hidden state, weights, and biases.
- It then applies the activation perform tanh to z_t to get the brand new hidden state h_t
- The community then computes the output y_t utilizing the brand new hidden state, output weights, and output biases.
This course of is repeated for every time step within the sequence and the following letter or phrase is predicted within the sequence.
Backpropagation by time
A backward move in a neural community is used to replace the weights to attenuate the loss. Nonetheless in RNNs, it is a bit more advanced than a typical feed-forward community, subsequently the usual backpropagation algorithm is custom-made to include the recurrent nature of RNNs.
In a feed-forward community, backpropagation seems to be like this:
- Ahead Go: The mannequin computes the activations and outputs of every layer, one after the other.
- Backward Go: Then it computes the gradients of the loss with respect to the weights and repeats the method for all of the layers.
- Parameter Replace: Replace the weights and biases utilizing the gradient descent algorithm.
Nonetheless, in RNNs, this course of is adjusted to include the sequential information. To study to foretell the following phrase accurately, the mannequin must study what weights within the earlier time steps led to the right or incorrect prediction.
Due to this fact, an unrolling course of is carried out. Unrolling the RNNs implies that for every time step, the complete RNN is unrolled, representing the weights at that individual time step. For instance, if we have now t time steps, then there will probably be t unrolled variations.
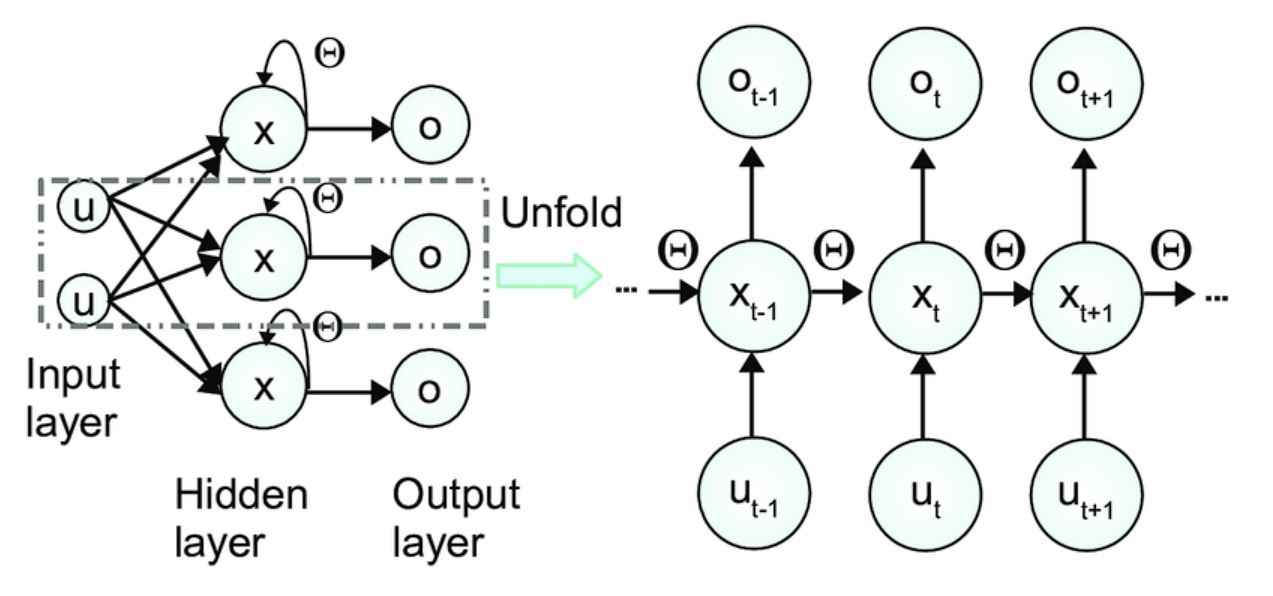
As soon as that is carried out, the losses are calculated for every time step, after which the mannequin computes the gradients of the loss for hidden states, weight, and biases, backpropagating the error by the unrolled community.
This beautiful a lot explains the working of RNNs.
RNNs face severe limitations comparable to exploding and vanishing gradients issues, and restricted reminiscence. Combining all these limitations made coaching RNNs troublesome. Consequently, LSTMs had been developed, that inherited the inspiration of RNNs and mixed with a couple of adjustments.
Sequence Mannequin 2: Lengthy Brief-Time period Reminiscence Networks (LSTM)
LSTM networks are a particular sort of RNN-based sequence mannequin that addresses the problems of vanishing and exploding gradients and are utilized in purposes comparable to sentiment evaluation. As we mentioned above, LSTM makes use of the inspiration of RNNs and therefore is much like it, however with the introduction of a gating mechanism that permits it to carry reminiscence over an extended interval.
An LSTM community consists of the next elements.
Cell State
The cell state in an LSTM community is a vector that features because the reminiscence of the community by carrying data throughout completely different time steps. It runs down the complete sequence chain with just some linear transformations, dealt with by the overlook gate, enter gate, and output gate.
Hidden State
The hidden state is the short-term reminiscence as compared cell state that shops reminiscence for an extended interval. The hidden state serves as a message service, carrying data from the earlier time step to the following, identical to in RNNs. It’s up to date based mostly on the earlier hidden state, the present enter, and the present cell state.
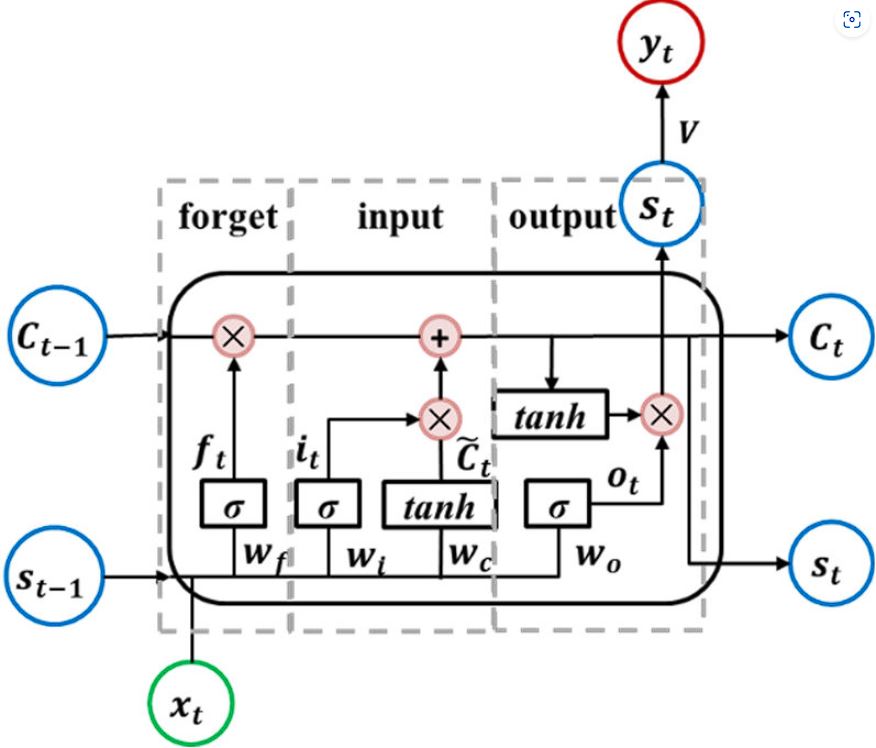
LSTMs use three completely different gates to manage data saved within the cell state.
Overlook Gate Operation
The overlook gate decides which data from the earlier cell state must be carried ahead and which have to be forgotten. It provides an output worth between 0 and 1 for every factor within the cell state. A worth of 0 implies that the data is totally forgotten, whereas a price of 1 implies that the data is totally retained.
That is determined by element-wise multiplication of overlook gate output with the earlier cell state.
Enter Gate Operation
The enter gate controls which new data is added to the cell state. It consists of two components: the enter gate and the cell candidate. The enter gate layer makes use of a sigmoid perform to output values between 0 and 1, deciding the significance of recent data.
The values output by the gates are usually not discrete; they lie on a steady spectrum between 0 and 1. That is because of the sigmoid activation perform, which squashes any quantity into the vary between 0 and 1.
Output Gate Operation
The output gate decides what the following hidden state must be, by deciding how a lot of the cell state is uncovered to the hidden state.
Allow us to now have a look at how all these elements work collectively to make predictions.
- At every time step t, the community receives an enter x_t
- For every enter, LSTM calculates the values of the completely different gates. Notice that, these are learnable weights, as with time the mannequin will get higher at deciding the worth of all three gates.
- The mannequin computes the Overlook Gate.
- The mannequin then computes the Enter Gate.
- It updates the Cell State by combining the earlier cell state with the brand new data, which is determined by the worth of the gates.
- Then it computes the Output Gate, which decides how a lot data of the cell state must be uncovered to the hidden state.
- The hidden state is handed to a totally related layer to provide the ultimate output
Sequence Mannequin 3: Gated Recurrent Unit (GRU)
LSTM and Gated Recurrent Unit are each varieties of Recurrent Networks. Nonetheless, GRUs differ from LSTM within the variety of gates they use. GRU is less complicated compared to LSTM and makes use of solely two gates as a substitute of utilizing three gates present in LSTM.
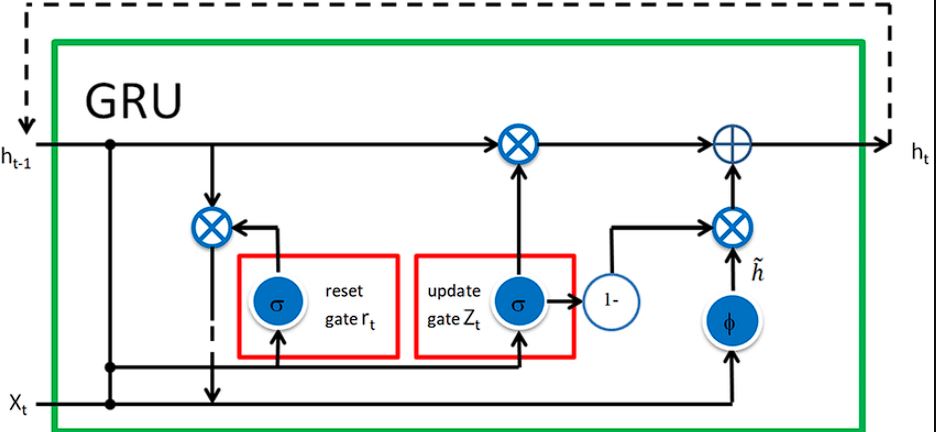
Furthermore, GRU is less complicated than LSTM by way of reminiscence additionally, as they solely make the most of the hidden state for reminiscence. Listed below are the gates utilized in GRU:
- The replace gate in GRU controls how a lot of previous data must be carried ahead.
- The reset gate controls how a lot data within the reminiscence it must overlook.
- The hidden state shops data from the earlier time step.
Sequence Mannequin 4: Transformer Fashions
The transformer mannequin has been fairly a breakthrough on the planet of deep studying and has introduced the eyes of the world to itself. Numerous LLMs comparable to ChatGPT and Gemini from Google use the transformer structure of their fashions.
Transformer structure differs from the earlier fashions we have now mentioned in its means to offer various significance to completely different components of the sequence of phrases it has been offered. This is named the self-attention mechanism and is confirmed to be helpful for long-range dependencies in texts.
Self-Consideration Mannequin
As we mentioned above, self-attention is a mechanism that permits the mannequin to offer various significance and extract necessary options within the enter information.
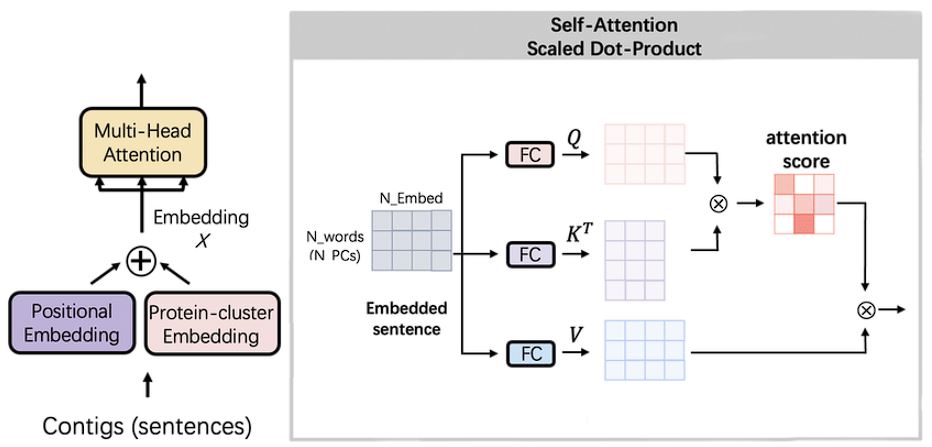
It really works by first computing the eye rating for every phrase within the sequence and derives their relative significance. This course of permits the mannequin to concentrate on related components and provides it the power to know pure language, in contrast to some other mannequin.
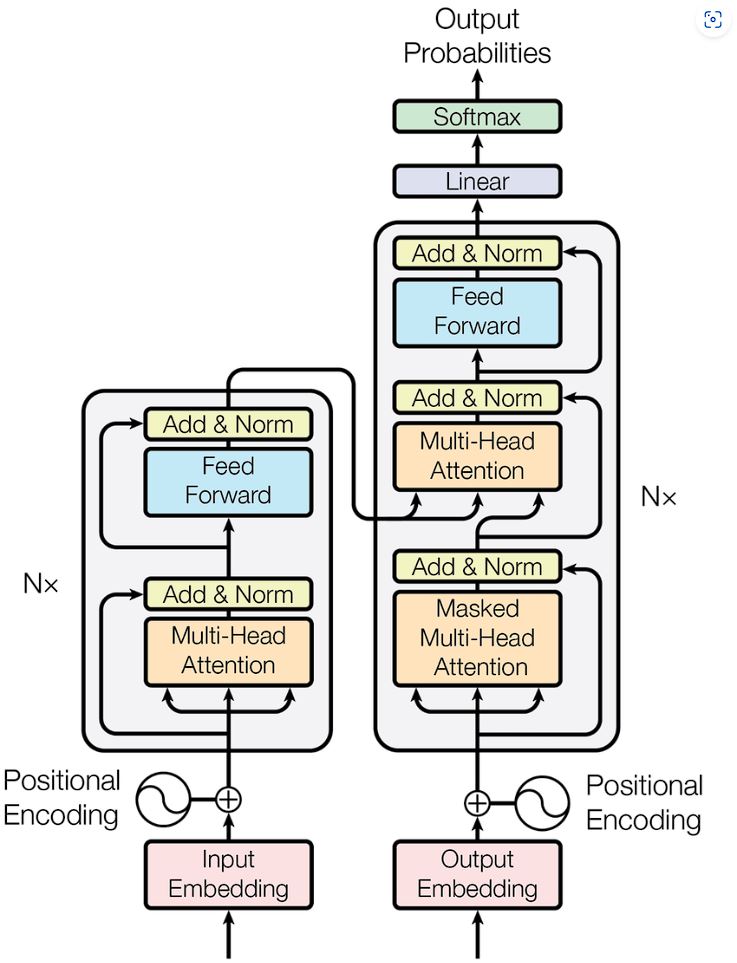
Structure of Transformer mannequin
The important thing function of the Transformer mannequin is its self-attention mechanisms that permit it to course of information in parallel fairly than sequentially as in Recurrent Neural Networks (RNNs) or Lengthy Brief-Time period Reminiscence Networks (LSTMs).
The Transformer structure consists of an encoder and a decoder.
Encoder
The Encoder consists of the identical a number of layers. Every layer has two sub-layers:
- Multi-head self-attention mechanism.
- Absolutely related feed-forward community.
The output of every sub-layer passes by a residual connection and a layer normalization earlier than it’s fed into the following sub-layer.
“Multi-head” right here implies that the mannequin has a number of units (or “heads”) of discovered linear transformations that it applies to the enter. That is necessary as a result of it enhances the modeling capabilities of the community.
For instance, the sentence: “The cat, which already ate, was full.” By having multi-head consideration, the community will:
- Head 1 will concentrate on the connection between “cat” and “ate”, serving to the mannequin perceive who did the consuming.
- Head 2 will concentrate on the connection between “ate” and “full”, serving to the mannequin perceive why the cat is full.
On account of this, we will course of the enter and extract the context higher parallelly.
Decoder
The Decoder has an identical construction to the Encoder however with one distinction. Masked multi-head consideration is used right here. Its main elements are:
- Masked Self-Consideration Layer: Much like the Self-Consideration layer within the Encoder however entails masking.
- Self Consideration Layer
- Feed-Ahead Neural Community.
The “masked” a part of the time period refers to a method used throughout coaching the place future tokens are hidden from the mannequin.
The explanation for that is that in coaching, the entire sequence (sentence) is fed into the mannequin without delay, however this poses an issue, the mannequin now is aware of what the following phrase is and there’s no studying concerned in its prediction. Masking out removes the following phrase from the coaching sequence offered, which permits the mannequin to offer its prediction.
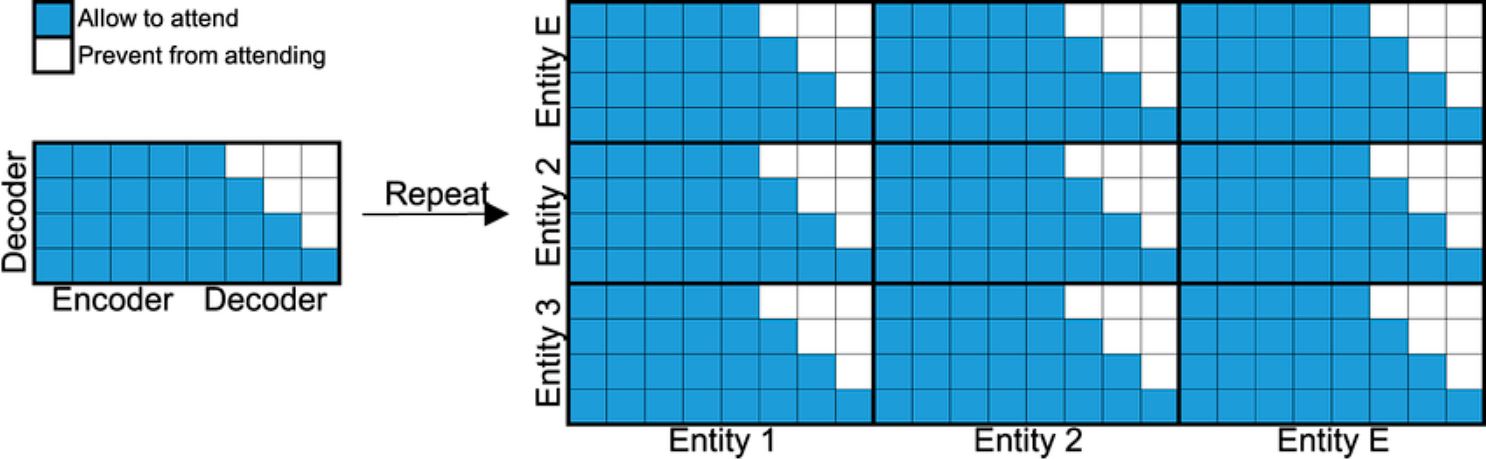
For instance, let’s take into account a machine translation job, the place we need to translate the English sentence “I’m a pupil” to French: “Je suis un étudiant”.
[START] Je suis un étudiant [END]
Right here’s how the masked layer helps with prediction:
- When predicting the primary phrase “Je”, we masks out (ignore) all the opposite phrases. So, the mannequin doesn’t know the following phrases (it simply sees [START]).
- When predicting the following phrase “suis”, we masks out the phrases to its proper. This implies the mannequin can’t see “un étudiant [END]” for making its prediction. It solely sees [START] Je.
Abstract
On this weblog, we appeared into the completely different Convolution Neural Community architectures which can be used for sequence modeling. We began with RNNs, which function a foundational mannequin for LSTM and GRU. RNNs differ from customary feed-forward networks due to the reminiscence options because of their recurrent nature, which means the community shops the output from one layer and is used as enter to a different layer. Nonetheless, coaching RNNs turned out to be troublesome. Consequently, we noticed the introduction of LSTM and GRU which use gating mechanisms to retailer data for an prolonged time.
Lastly, we appeared on the Transformer machine studying mannequin, an structure that’s utilized in notable LLMs comparable to ChatGPT and Gemini. Transformers differed from different sequence fashions due to their self-attention mechanism that allowed the mannequin to offer various significance to a part of the sequence, leading to human-like comprehension of texts.
Learn our blogs to know extra in regards to the ideas we mentioned right here: