

Basis fashions are latest developments in synthetic intelligence (AI). Fashions like GPT 4, BERT, DALL-E 3, CLIP, Sora, and so on., are on the forefront of the AI revolution. Whereas these fashions could appear numerous of their capabilities – from producing human-like textual content to producing beautiful visible artwork – they share a typical thread: They’re all pioneering examples of basis fashions.
These fashions are skilled on huge quantities of unlabeled or self-supervised information to accumulate a broad data base and language understanding capabilities. They extract significant options and patterns from the coaching information and fine-tune them for particular duties.
On this article, we’ll focus on the transformative impression of basis fashions in trendy AI developments. All through, you’ll acquire the next insights:
- Definition and Scope of Basis Fashions
- How Do Basis Fashions Endure Coaching And Effective-Tuning Processes?
- Use Circumstances for Basis Fashions
- Functions in Pre-trained Language Fashions like GPT, BERT, Claude, and so on.
- Functions in Pc Imaginative and prescient Fashions like ResNET, VGG, Picture Captioning, and so on.
- Functions in Multimodal Studying Fashions like CLIP
- Rising Tendencies and Future Development in Basis Mannequin Analysis
About Us: Viso Suite is the end-to-end pc imaginative and prescient infrastructure. With Viso Suite, enterprise groups can simply combine the total machine studying pipeline into their workflows in a matter of days. Thus, eliminating the necessity for time-consuming, complicated level options. Be taught extra about Viso Suite by reserving a demo with us.
What are Basis Fashions?
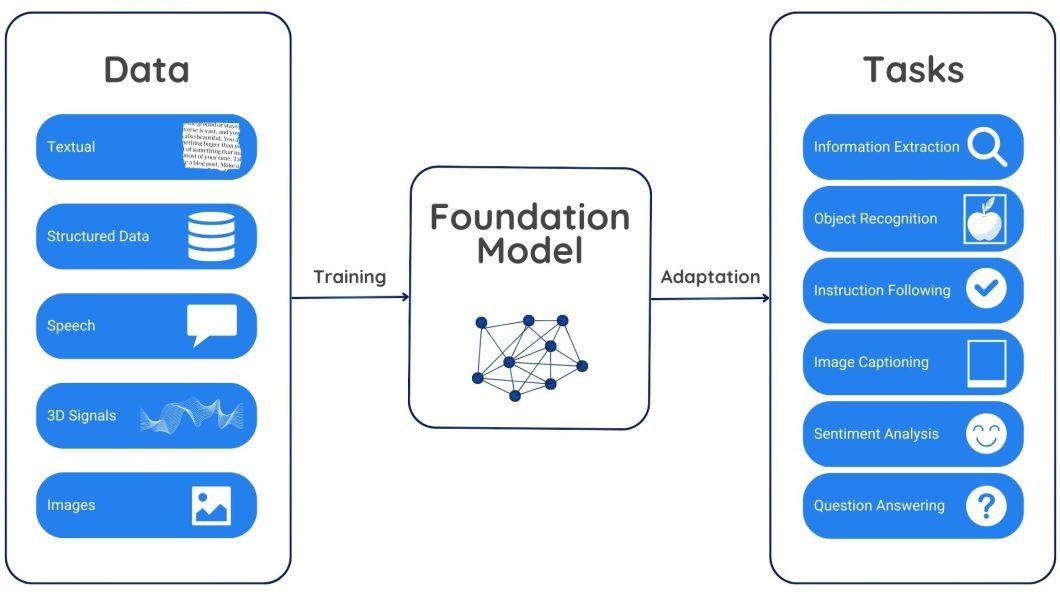
Basis fashions are large-scale neural community architectures that endure pre-training on huge quantities of unlabeled information by means of self-supervised studying. Self-supervised studying permits them to study and extract related options and representations from the uncooked information with out counting on labeled examples. The primary aim of basis fashions is to function a place to begin or foundational constructing block for a lot of AI duties, like pure language processing, query answering, textual content era, summarization, and even code era.
With billions and even trillions of parameters, basis fashions can successfully seize patterns and connections inside the coaching information. Whereas early fashions corresponding to GPT 3 have been text-focused ones. They take textual enter and generate textual output. Current fashions like CLIP, Secure Diffusion, and Gato are multimodal and might deal with information varieties like photos, audio recordsdata, and movies.
How Do Basis Fashions Work?
Basis fashions work on self-supervised studying, which permits them to study significant representations from the enter information with out counting on express labels or annotations. They’re pre-trained on large datasets. Throughout this stage, the mannequin predicts lacking elements, fixes corrupted information, or finds connections between completely different information varieties. This teaches the mannequin inherent patterns and relationships inside the information.
Pre-training equips the mannequin with a powerful understanding of the underlying information construction and that means. This realized data turns into a basis for particular duties being carried out by the mannequin. By fine-tuning smaller, particular datasets, the mannequin may be tailored for numerous duties.
For instance, a basis mannequin skilled on textual information would possibly perceive phrase relationships, sentence formations, and numerous writing kinds. This foundational understanding allows the mannequin to hold out duties like producing textual content, translating content material, and answering questions after fine-tuning.
Equally, if we prepare a basis mannequin on numerous picture datasets, the mannequin can study to acknowledge objects, their elements, and the underlying relationships between them. This skilled data can allow the inspiration mannequin to carry out numerous pc imaginative and prescient duties after fine-tuning. For instance, we will fine-tune a mannequin to detect particular objects in photos (like automobiles, site visitors indicators, and medical anomalies in X-ray reviews), classify photos (like landscapes, and indoor or out of doors scenes), and even generate new photos based mostly on textual descriptions.
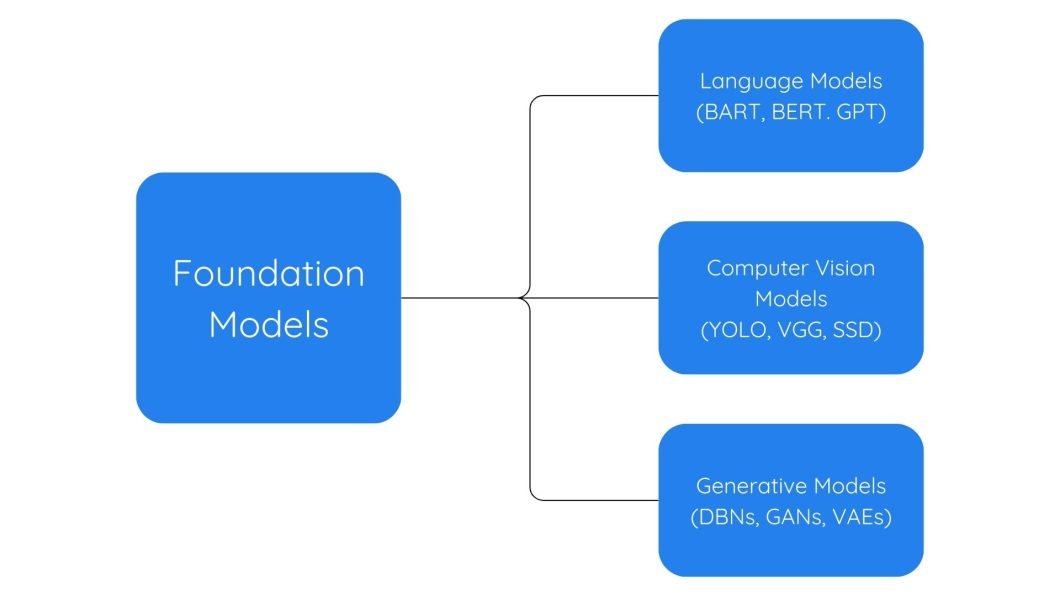
Use Circumstances of Basis Fashions
Basis fashions excel in pure language processing, pc imaginative and prescient, and numerous different synthetic intelligence duties. Every applies basis fashions in numerous methods to deal with complicated duties.
Let’s focus on a few of them intimately:
Pure Language Processing
Pure Language Processing (NLP) lets computer systems perceive and course of human language. It encompasses speech recognition, text-to-speech conversion, language translation, sentiment evaluation in textual content, content material summarization, and prompt-based question-answering duties.
Conventional NLP strategies closely depend on fashions which might be skilled on labeled datasets. These fashions typically struggled to adapt to new areas or duties and have been restricted by the provision of high-quality labeled information.
In the meantime, the emergence of huge language fashions LLMS (or basis fashions) has remodeled this area by enabling the creation of extra strong and adaptable language fashions. These highly effective fashions can deal with many NLP duties with just a bit fine-tuning on smaller datasets. Examples embrace GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), Claude, and so on.
Pc Imaginative and prescient
Pc imaginative and prescient is a specialised space of synthetic intelligence that focuses on processing and understanding visible information. It builds algorithms to establish objects, analyze scenes, and monitor movement.
Basis fashions are pushing the boundaries of pc imaginative and prescient. One vital progress facilitated by these fashions is the emergence of multimodal imaginative and prescient language fashions like CLIP, DALL-E, Sora, and so on. These fashions mix pc imaginative and prescient and language processing to know photos and textual content collectively. They’ll describe photos (captioning), reply questions on them (visible query answering), and even generate new photos or movies.
Likewise, pc imaginative and prescient fashions corresponding to ResNet (Residual Community) and VGG (Visible Geometry Group) have gained widespread adoption for operations like picture classification, object detection, and semantic segmentation. These fashions are pre-trained on in depth datasets of labeled photos and may be fine-tuned for particular pc imaginative and prescient assignments.
Generative AI
What are the inspiration fashions in Generative AI? Not like pc imaginative and prescient duties that concentrate on deciphering visible information, generative AI fashions are designed to provide solely new content material. This encompasses creating textual content that resembles human writing, crafting high-quality photos, audio/video era, coding, and producing different structured information codecs.
The arrival of basis fashions has revolutionized the coaching and improvement of generative AI methods. These large-scale fashions are pre-trained on huge quantities of knowledge. They study to seize intrinsic patterns, relationships, and representations inside information that may be utilized to many downstream duties, together with producing new content material.
Functions of Basis Fashions in Pre-trained Language Fashions
GPT (Generative Pre-trained Transformer)
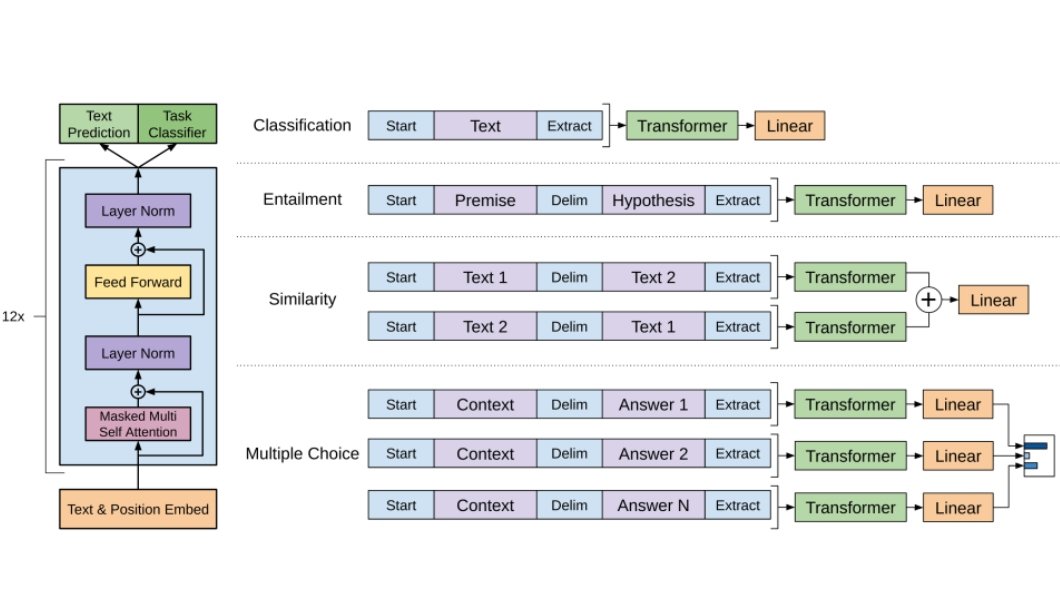
GPT is a big language mannequin from open supply OpenAI. It’s a transformer-based neural community structure that’s pre-trained on a large quantity of textual content information utilizing an unsupervised studying method referred to as self-attention.
Right here’s a common overview of how GPT works:
Pre-training: GPT undergoes pre-training utilizing an intensive assortment of textual content information sourced from the web, like books, analysis journals, articles, and net content material.
It makes use of a way referred to as “generative pre-training” to foretell the following phrase in a sequence. This includes masking phrases within the enter textual content with particular tokens and coaching the mannequin to foretell these masked phrases inside their contextual framework.
Structure: GPT makes use of transformer structure with self-attention mechanisms. The structure consists of a number of encoder and decoder layers every composed of self-attention and feed-forward neural networks.
Within the encoding course of, the transformer encoder takes the enter sequence (textual content) and produces a contextualized illustration for every token (phrase or subword) within the sequence. Subsequently, within the decoding section, the output sequence is generated “token by token” by contemplating elements of each the enter sequence and beforehand generated tokens.
Inference (Era): GPT receives a immediate (a textual content sequence) as enter. The mannequin leverages its realized data and language comprehension to foretell the following token (phrase or subword) that’s more than likely to return after the prompted enter. The generated token is then fed again into the mannequin, and the method continues iteratively till sure standards are met (e.g., it reaches a sure size).
Effective-tuning: After pre-training, GPT fashions can fine-tuned to particular duties, corresponding to textual content era, summarization, or query answering. Effective-tuning adjusts the mannequin’s parameters for these duties whereas retaining its pre-trained data.
Newer variations like GPT-3 and GPT-4, skilled on even bigger datasets. They’re showcasing outstanding talents in producing coherent and contextually related textual content for numerous purposes.
BERT (Bidirectional Encoder Representations from Transformers)
BERT, a machine studying mannequin created by Google is used for duties associated to pure language processing. That is how BERT undergoes coaching and fine-tuning course of;
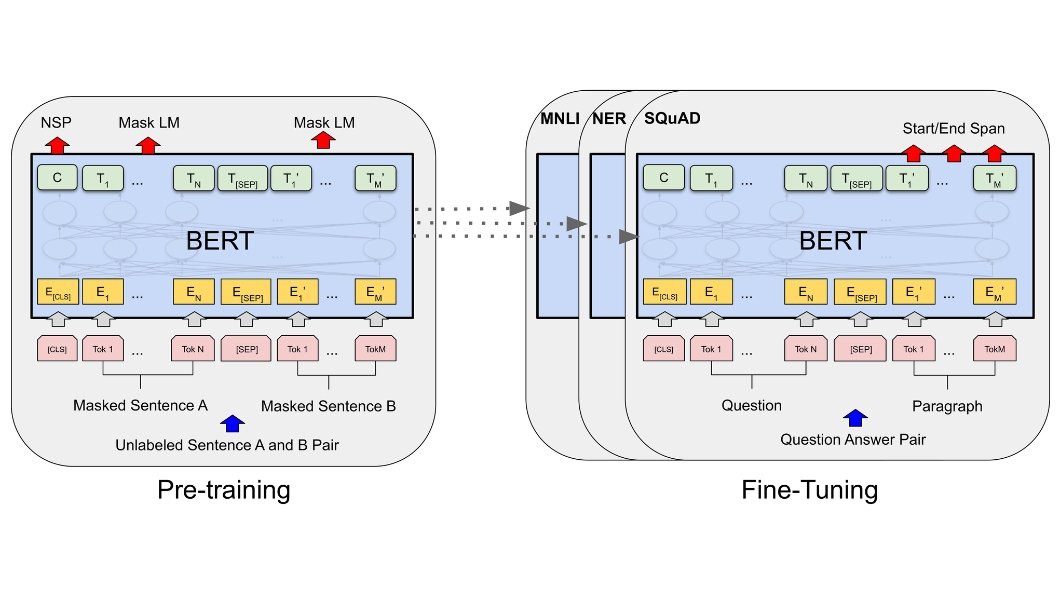
Coaching Part:
BERT undergoes coaching on an quantity of unlabelled textual content information by performing two primary duties; masked language modeling and subsequent sentence prediction.
- Masked Language Modelling: Throughout masked language modeling sure tokens within the enter sequence are randomly changed with a [MASK] token and the mannequin learns to foretell the unique values of those masked tokens based mostly on the encircling context.
- Subsequent Sentence Prediction: In sentence prediction, the mannequin is taught to find out if two given sentences comply with one another in sequence or not.
Not like GPT fashions, BERT is bidirectional. It considers each previous and succeeding contexts concurrently throughout coaching.
Effective Tuning:
After pre-training, BERT adapts to particular duties (classification, query answering, and so on.) with labeled information. We add task-specific layers on high of the pre-trained mannequin and fine-tune your entire mannequin for the goal activity.
Numerous variations of BERT such, as RoBERTa, DistilBERT, and ALBERT have been created to reinforce the BERT fashions’ efficiency, effectivity, and applicability to completely different eventualities.
Functions of Basis Fashions in Pc Imaginative and prescient Duties
ResNet
Residual Community (ResNet) will not be straight utilized as a basis mannequin. Slightly it serves as a Convolutional Neural Community (CNN) structure recognized for its excellence in duties associated to pc imaginative and prescient, corresponding to picture recognition.
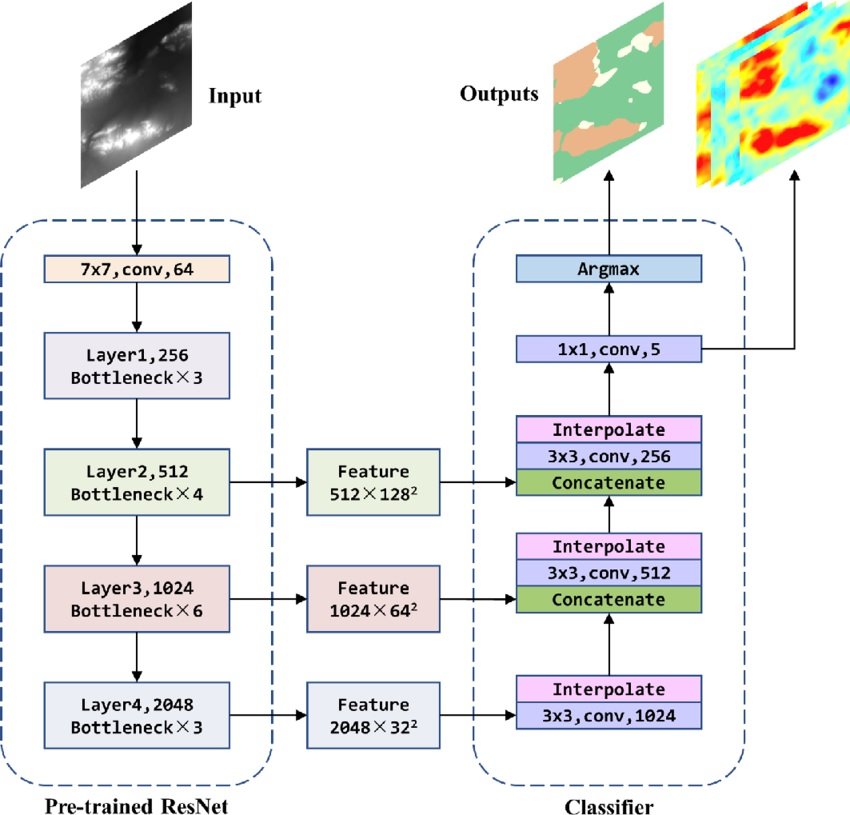
Nonetheless, ResNets performs an important position in establishing basis fashions for pc imaginative and prescient. Right here’s how;
- Pre-training for Function Extraction: ResNet fashions which might be pre-trained on picture datasets corresponding to ImageNet can function a strong basis for numerous pc imaginative and prescient assignments. These pre-trained fashions could purchase strong picture representations and have extraction capabilities.
- Present Base for Coaching CV Basis Fashions: The pre-trained weights of a ResNet can act as an preliminary level for coaching a foundational mannequin. This foundational mannequin can then be fine-tuned for functions like object detection, picture segmentation, or picture captioning. By harnessing the skilled options from ResNet, the foundational mannequin can effectively study these new duties.
VGG
Very Geometry Group (VGG) will not be itself a basis mannequin. Slightly it’s a pre-trained convolutional neural community (CNN) structure used to extract low- and mid-level visible options from photos in the course of the self-supervised pretraining section.
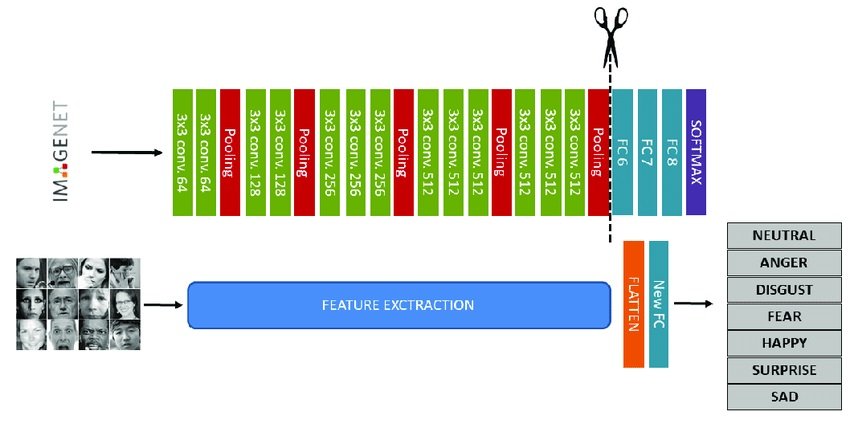
VGG helps construct basis fashions in two methods:
- The early layers of VGG are efficient at recognizing and extracting basic picture options like edges and shapes. These options are then handed on to different layers to study extra complicated representations by means of transformers or contrastive studying modules. As soon as pre-trained, these extracted options feed into a bigger basis mannequin targeted on a particular activity, like an object detection basis mannequin or picture segmentation.
- The VGG spine gives a powerful place to begin for constructing a basis mannequin. When fine-tuning, the load of the VGG spine can both stay fastened or be adjusted together with the remainder of the mannequin for downstream duties. This protects time and compute assets in comparison with coaching a wholly new mannequin from scratch.
Picture Captioning
Picture captioning is a pc imaginative and prescient activity that goals to generate pure language descriptions for given photos. We’ve seen vital developments on this space as a result of basis fashions. Such basis fashions study to align visible and textual representations by means of self-supervised goals like masked language modeling and contrastive studying.
Throughout pre-training, the mannequin takes a picture as enter and generates a related caption by extracting its visible options.

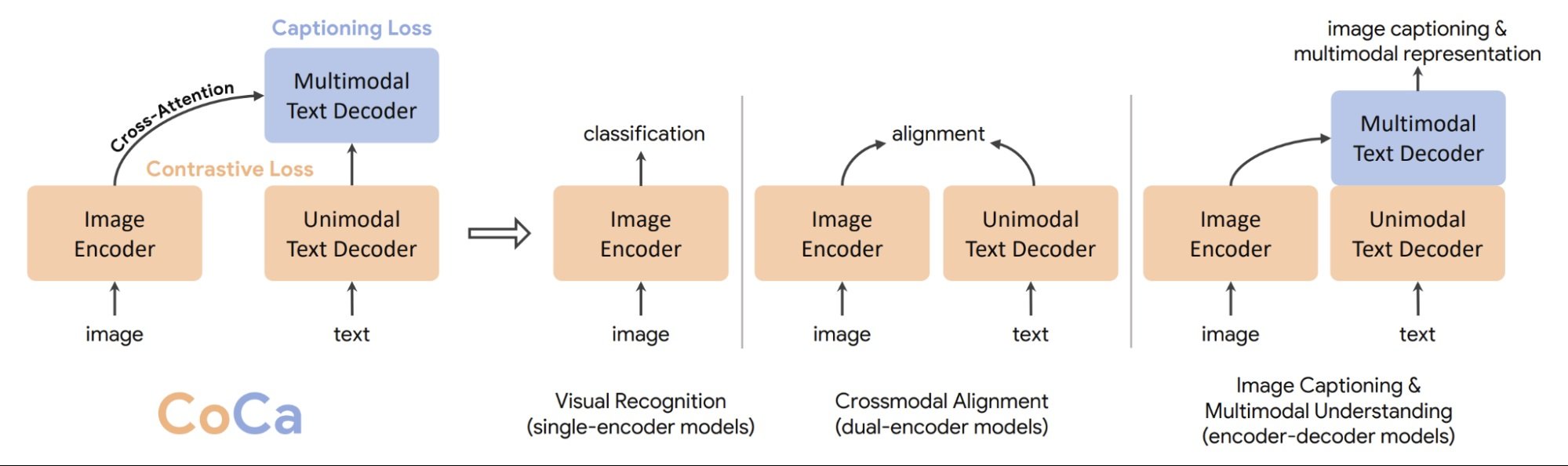
One latest instance is the CoCa (Contrastive Captioners) mannequin, a sophisticated basis mannequin, particularly designed for image-text duties. Coca learns from the similarities and variations between captions describing the identical picture. This permits CoCa to carry out numerous duties like producing captions for brand new photos and answering questions in regards to the content material of a picture.
Visible Query Answering (VQA)
Visible Query Answering (VQA) includes AI methods answering pure language questions on picture content material. Foundational fashions have superior on this area by means of self-supervised pre-training on massive picture textual content datasets. These fashions align visible and textual representations with masked area modeling and contrastive studying duties. Throughout the answering course of, the mannequin analyzes each the picture and query, specializing in related visible elements and using its understanding of various modes of data.
Notable examples embrace ViLT, METER, and VinVL. Via numerous information pre-training these foundational fashions set up a powerful visible linguistic basis for correct query answering throughout numerous domains with minimal fine-tuning required.
Functions of Basis Fashions in Multimodal Studying
CLIP (Contrastive Language-Picture Pre Coaching)
CLIP excels at bridging the hole between textual content and pictures. It’s a basis mannequin for multimodal duties like picture captioning and retrieval. CLIP is customized for numerous duties that contain each modalities, corresponding to producing new photos, answering questions on visuals, and retrieving data based mostly on picture textual content pairs.
Right here’s how CLIP works:
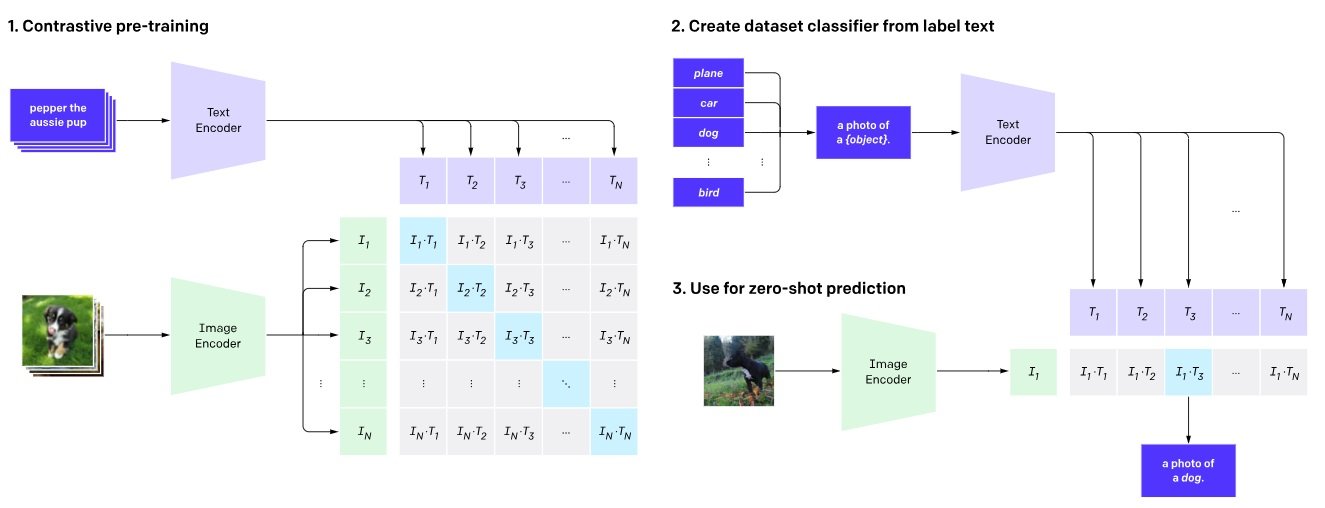
Twin-Encoder Structure: CLIP makes use of two distinct encoders: one for processing textual content and the opposite for processing photos. The textual content encoder converts textual descriptions into numerical representations (embeddings). In the meantime, the picture encoder transforms photos into one other set of vector embeddings.
Contrastive Studying: CLIP brings related image-text pairs nearer and pushes dissimilar ones aside, as soon as the vector embeddings are mapped.
- It boosts the similarity rating between appropriately paired picture embeddings and their corresponding textual descriptions.
- Scale back the similarity rating between a picture and any incorrect textual description.
Verify our complete article on CLIP for a extra detailed understanding of its pre-training and fine-tuning processes.
Rising Tendencies And Future Developments In Basis Mannequin Analysis
Basis mannequin analysis is pushing boundaries in synthetic intelligence in two key areas:
Researchers are repeatedly engaged on creating bigger fashions to seize intricate information relationships. Furthermore, there’s a rising emphasis on understanding how these fashions arrive at choices to reinforce belief and dependability of their outcomes.
This twin focus guarantees much more highly effective AI instruments sooner or later.
What’s Subsequent?
Basis fashions function the cornerstone of the following era of intelligence methods. They provide scalable, adaptable, and versatile frameworks for constructing superior AI purposes. By harnessing the ability of deep studying and large-scale information, these fashions are poised to reshape how we work together with know-how.
Listed here are some really useful reads to achieve extra insights in regards to the matter: