

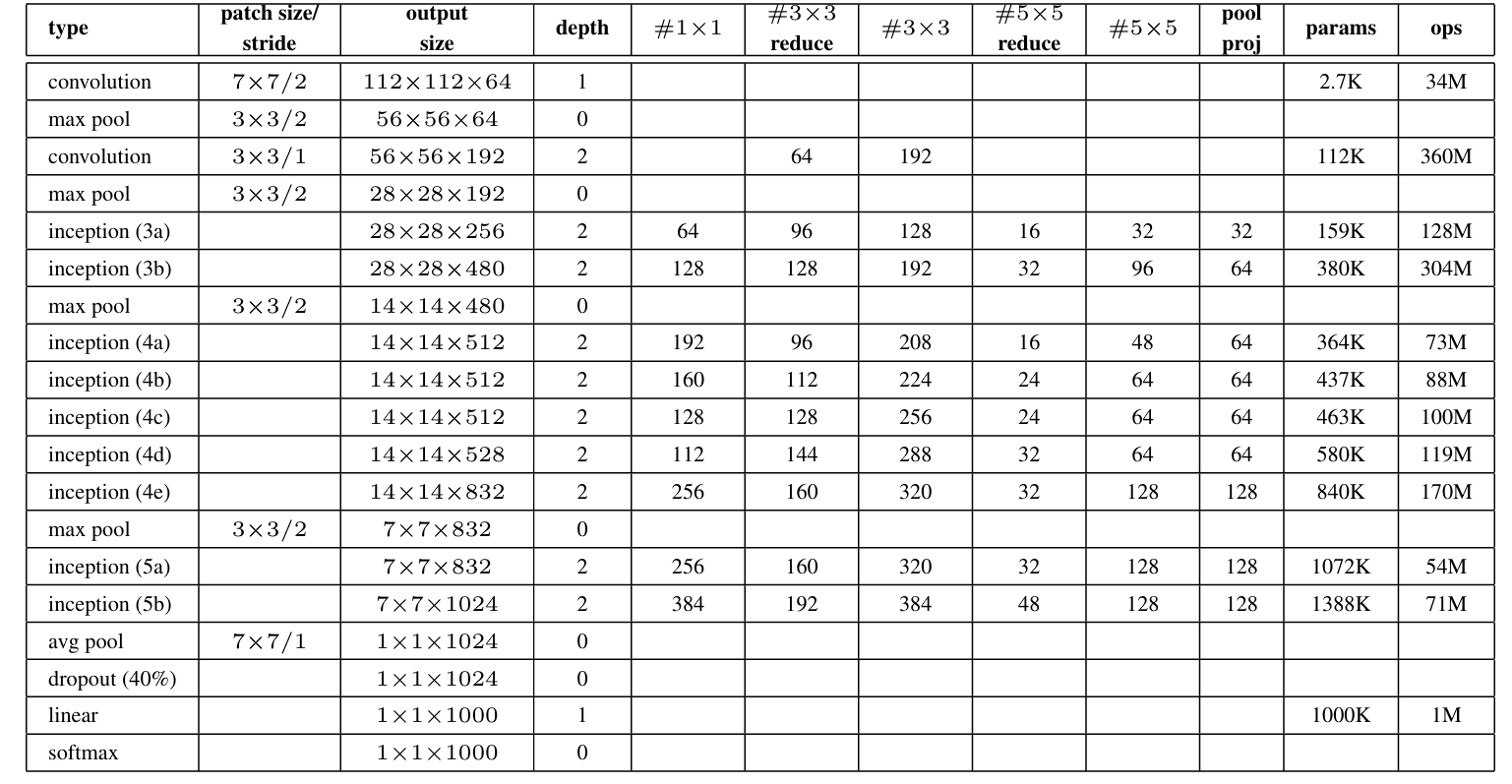
GoogLeNet, launched in 2014, set a brand new benchmark in object classification and detection by means of its revolutionary strategy (attaining a top-5 error charge of 6.7%, practically half the error charge of the earlier yr’s winner ZFNet with 11.7%) in ImageNet Giant Scale Visible Recognition Problem (ILSVRC).
GoogLeNet’s deep studying mannequin was deeper than all of the earlier fashions launched, with 22 layers in whole. Growing the depth of the Machine Studying mannequin is intuitive, as deeper fashions are likely to have extra studying capability and in consequence, this will increase the efficiency of a mannequin. Nonetheless, that is solely attainable if we are able to resolve the vanishing gradient downside.
When designing a deep studying mannequin, one must resolve what convolution filter dimension to make use of (whether or not it needs to be 3×3, 5×5, or 1×3) because it impacts the mannequin’s studying and efficiency, and when to max pool the layers. Nonetheless, the inception module, the important thing innovation launched by a crew of Google researchers solved this downside creatively. As an alternative of deciding what filter dimension to make use of and when max pooling operation should be carried out, they mixed a number of convolution filters.
Stacking a number of convolution filters collectively as an alternative of only one will increase the parameter rely many instances. Nonetheless, GoogLeNet demonstrated through the use of the inception module that depth and width in a neural community might be elevated with out exploding computations. We are going to examine the inception module in depth.
Historic Context
The idea of Convolutional Neural Networks (CNNs) isn’t new. It dates again to the Nineteen Eighties with the introduction of the Noncognition by Kunihiko Fukushima. Nonetheless, CNNs gained reputation within the Nineties after Yann LeCun and his colleagues launched LeNet-5 (one of many earliest CNNs), designed for handwritten digit recognition. LeNet-5 laid the groundwork for contemporary CNNs through the use of a sequence of convolutional layers adopted by subsampling layers, now generally known as pooling layers.
Nonetheless, CNNs by no means noticed any widespread adoption for a very long time after LeNet-5, as a result of an absence of computational assets and the unavailability of enormous datasets, which made the realized fashions impotent.
The turning level got here in 2012 with the introduction of AlexNet by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton. AlexNet was designed for the ImageNet problem and considerably outperformed different machine studying approaches. This introduced deep studying to the forefront of AI analysis. AlexNet featured a number of improvements, corresponding to ReLU, dropout for regularization, and overlapping pooling.
After AlexNet, researchers began growing complicated and deeper networks. GoogLeNet had 22 layers and VGGNet had 16 layers in comparison with AlexNet which had solely 8 layers in whole.
Nonetheless, within the VGGNet paper, the restrictions of merely stacking extra layers have been highlighted, because it was computationally costly and led to overfitting. It wasn’t attainable to maintain growing the layers with none innovation to cater to those issues.
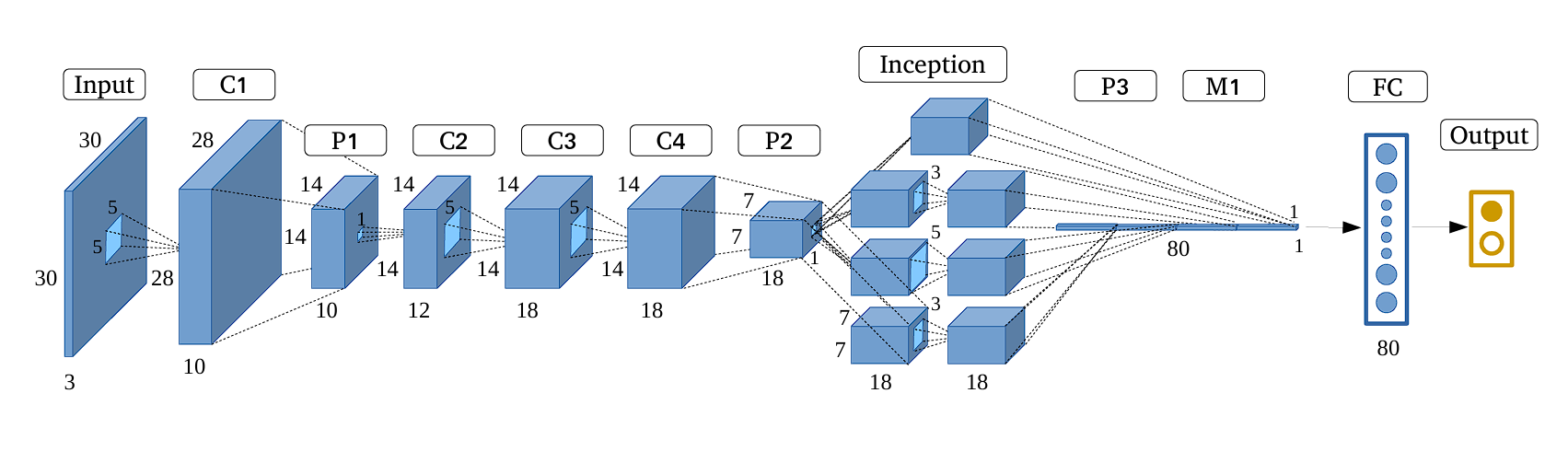
Structure of GoogLeNet
GoogLeNet mannequin is especially recognized for its use of Inception modules, which function its constructing blocks through the use of parallel convolutions with numerous filter sizes (1×1, 3×3, and 5×5) inside a single layer. The outputs from these filters are then concatenated. This fusion of outputs from numerous filters creates a richer illustration.
Furthermore, the structure is comparatively deep with 22 layers, nevertheless, the mannequin maintains computational effectivity regardless of the rise within the variety of layers.
Listed below are the important thing options of GoogLeNet:
- Inception Module
- The 1×1 Convolution
- International Common Pooling
- Auxiliary Classifiers for Coaching
The Inception Module
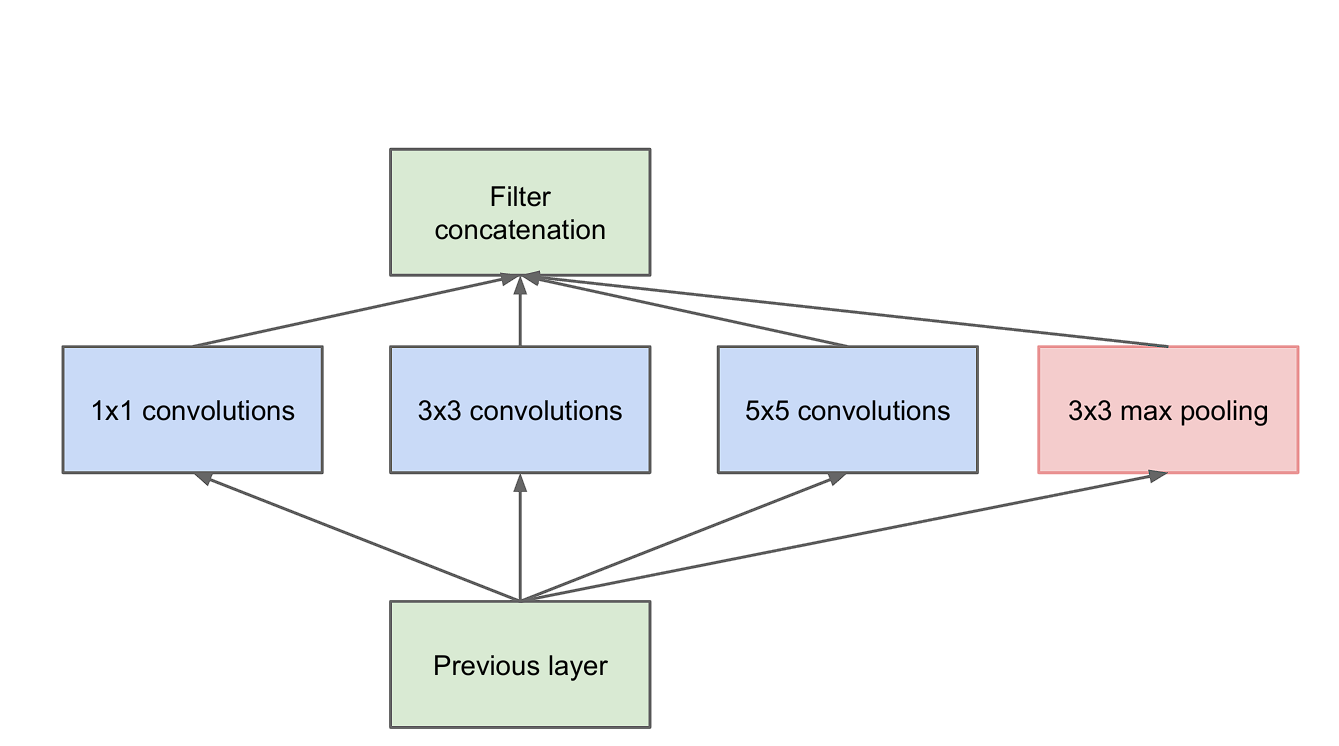
The Inception Module is the constructing block of GoogLeNet, as your entire mannequin is made by stacking Inception Modules. Listed below are the important thing options of it:
- Multi-Degree Characteristic Extraction: The principle thought of the inception module is that it consists of a number of pooling and convolution operations with totally different sizes (3×3, 5×5) in parallel, as an alternative of utilizing only one filter of a single dimension.
- Dimension Discount: Nonetheless, as we mentioned earlier, stacking a number of layers of convolution leads to elevated computations. To beat this, the researchers incorporate 1×1 convolution earlier than feeding the information into 3×3 or 5×5 convolutions. That is additionally referred to as dimensionality discount.
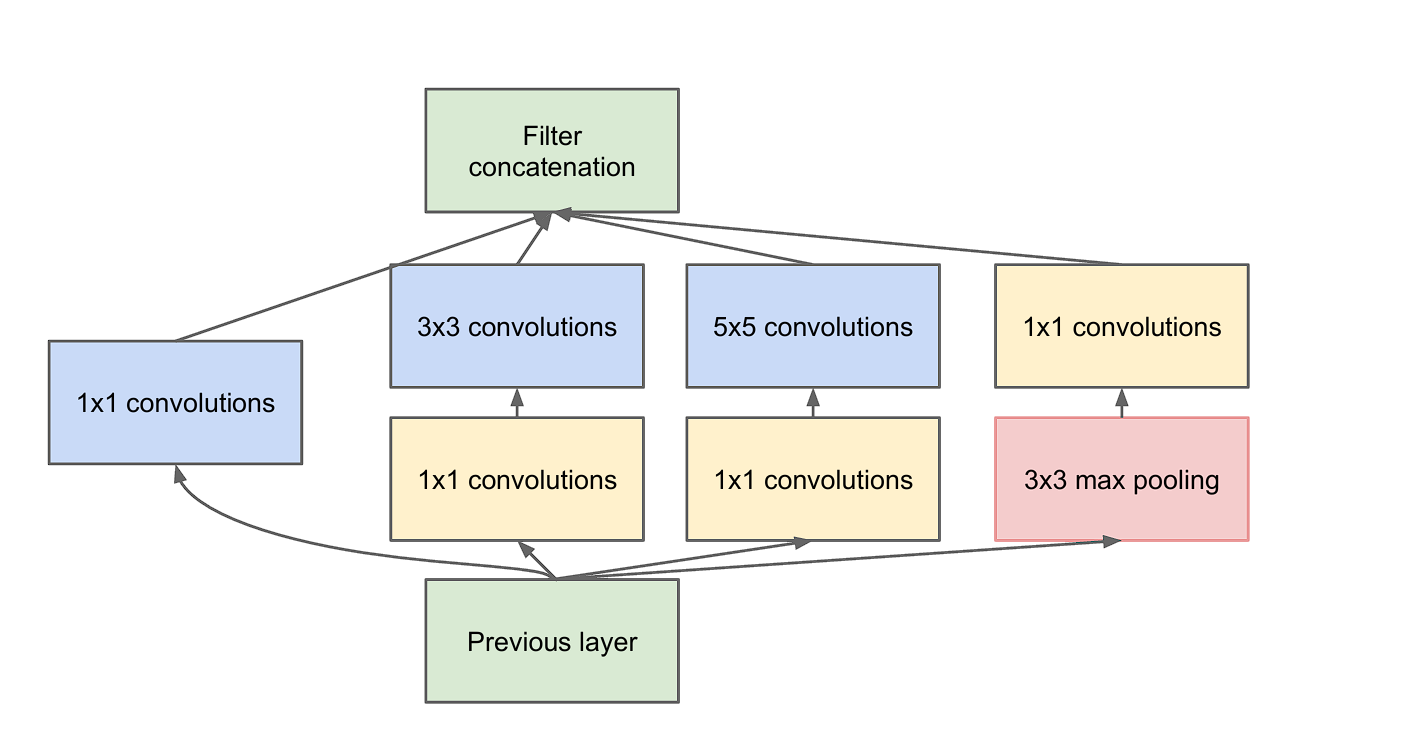
To place it into perspective, let’s have a look at the distinction.
- Enter Characteristic Map Dimension: 28×28
- Enter Channels (D): 192
- Variety of Filters in 3×3 Convolution (F): 96
With out Discount:
- Complete Parameters=3×3×192×96=165,888
With Discount:
- 1×1 Parameters=1×1×192×64=12,288
- 3×3 Parameters=3×3×64×96=55,296
- Complete Parameters with Discount=12,288+55,296=67,584
Advantages
- Parameter Effectivity: Through the use of 1×1 convolutions, the module reduces dimensionality earlier than making use of the costlier 3×3 and 5×5 convolutions and pooling operations.
- Elevated Illustration: By incorporating filters of various sizes and extra layers, the community captures a variety of options within the enter knowledge. This leads to higher illustration.
- Enhancing Characteristic Mixture: The 1×1 convolution can also be referred to as community within the community. Which means that every layer is a micro-neural community that learns to summary the information earlier than the principle convolution filters are utilized.
International Common Pooling
International Common Pooling is a method utilized in Convolutional Neural Networks (CNNs) within the place of totally linked layers on the finish a part of the community. This methodology is used to scale back the overall variety of parameters and to attenuate overfitting.
For instance, think about you’ve a function map with dimensions 10,10, 32 (Width, Top, Channels).
International Common Pooling performs a median operation throughout the Width and Top for every filter channel individually. This reduces the function map to a vector that is the same as the dimensions of the variety of channels.
The output vector captures essentially the most distinguished options by summarizing the activation of every channel throughout your entire function map. Right here our output vector is of the size 32, which is the same as the variety of channels.
Advantages of International Common Pooling
- Diminished Dimensionality: GAP considerably reduces the variety of parameters within the community, making it environment friendly and sooner throughout coaching and inference. Because of the absence of trainable parameters, the mannequin is much less liable to overfitting.
- Robustness to Spatial Variations: Your entire function map is summarized, in consequence, GAP is much less delicate to small spatial shifts within the object’s location throughout the picture.
- Computationally Environment friendly: It’s a easy operation in comparison with a set of totally linked layers.
In GoogLeNet structure, changing totally linked layers with world common pooling improved the top-1 accuracy by about 0.6%. In GoogLeNet, world common pooling could be discovered on the finish of the community, the place it summarizes the options realized by the CNN after which feeds it immediately into the SoftMax classifier.
Auxiliary Classifiers for Coaching
These are intermediate classifiers discovered on the aspect of the community. One essential factor to notice is that these are solely used throughout coaching and within the inference, these are omitted.
Auxiliary classifiers assist overcome the challenges of coaching very Deep Neural Networks, and vanishing gradients (when the gradients flip into extraordinarily small values).
Within the GoogLeNet structure, there are two auxiliary classifiers within the community. They’re positioned strategically, the place the depth of the function extracted is ample to make a significant influence, however earlier than the ultimate prediction from the output classifier.
The construction of every auxiliary classifier is talked about beneath:
- A median pooling layer with a 5×5 window and stride 3.
- A 1×1 convolution for dimension discount with 128 filters.
- Two totally linked layers, the primary layer with 1024 models, adopted by a dropout layer and the ultimate layer equivalent to the variety of courses within the job.
- A SoftMax layer to output the prediction possibilities.
Throughout coaching, the loss calculated from every auxiliary classifier is weighted and added to the overall lack of the community. Within the unique paper, it’s set to 0.3.
These auxiliary classifiers assist the gradient to movement and never diminish too rapidly, because it propagates again by means of the deeper layers. That is what makes coaching a Deep Neural Community like GoogLeNet attainable.
Furthermore, the auxiliary classifiers additionally assist with mannequin regularization. Since every classifier contributes to the ultimate output, in consequence, the community is inspired to distribute its studying throughout totally different elements of the community. This distribution prevents the community from relying too closely on particular options or layers, which reduces the probabilities of overfitting.
Efficiency of GoogLeNet
GoogLeNet achieved a top-5 error charge of 6.67%, bettering the rating in comparison with earlier fashions.
Here’s a comparability with different fashions launched beforehand:
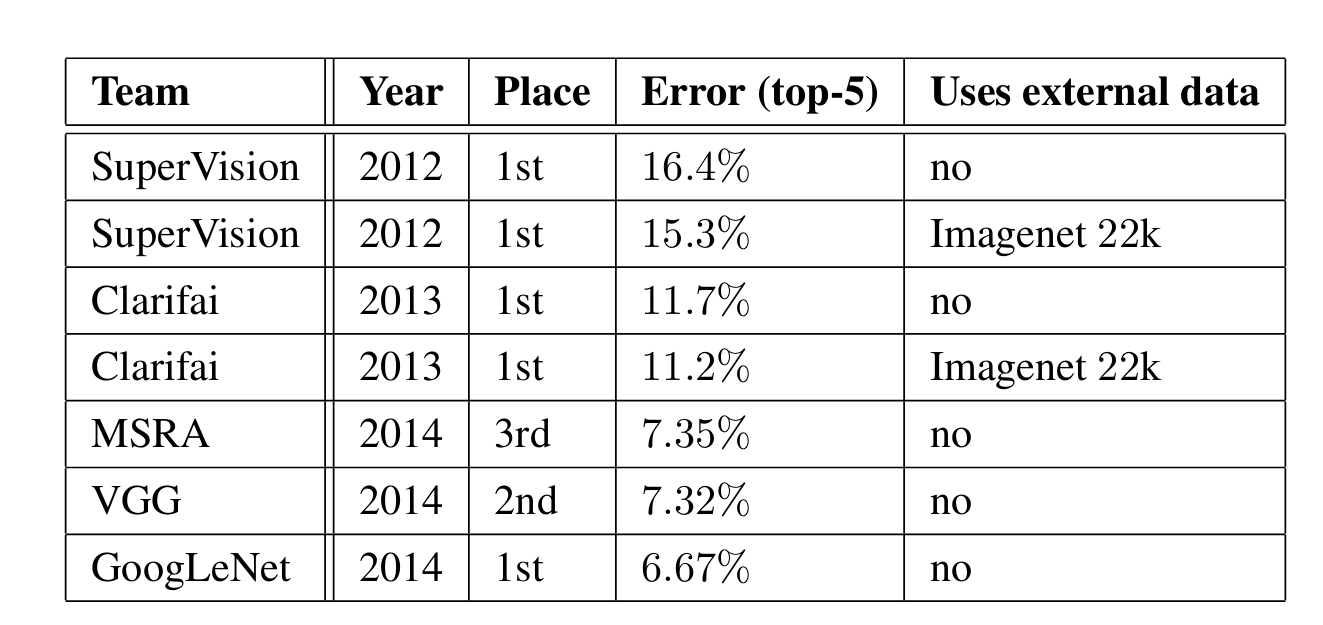
Comparability with Different Architectures
- AlexNet (2012): High-5 Error Charge of 15.3%. The Structure Consists of 8 layers (5 convolutional and three totally linked layers), which used ReLU activations, dropout, and knowledge augmentation to attain state-of-the-art efficiency in 2012.
AlexNet Structure –source - VGG (2014): High-5 Error Charge of seven.3%. The Structure is appreciated for its simplicity, utilizing solely 3×3 convolutional layers stacked on prime of one another in growing depth. Furthermore, VGG was additionally the runner-up in the identical competitors that GoogLeNet received. Though VGG used small convolution filters, its parameter rely, and computation have been intensive in comparison with GoogLeNet.
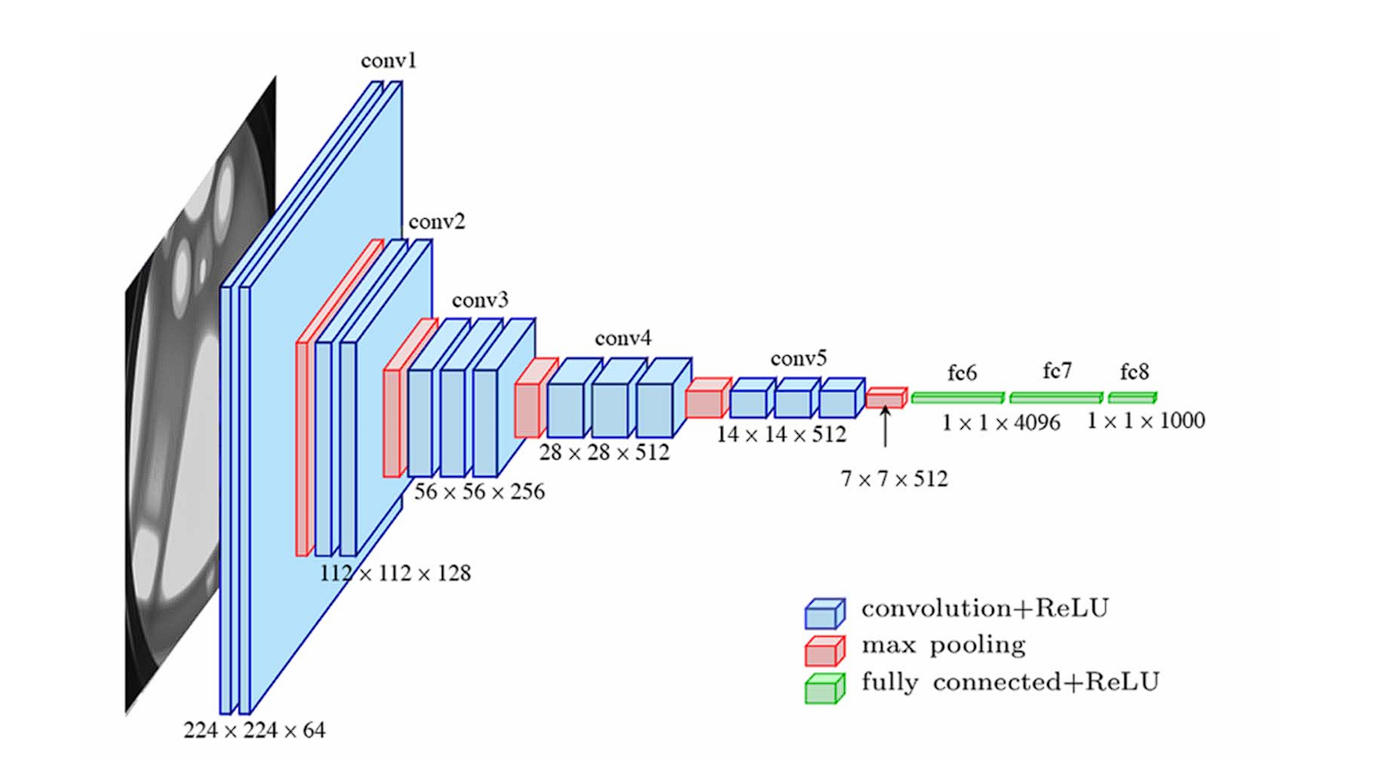
VGG-16 community structure –source
GoogLeNet Variants and Successors
Following the success of the unique GoogLeNet (Inception v1), a number of variants and successors have been developed to boost its structure. These embrace Inception v2, v3, v4, and the Inception-ResNet hybrids. Every of those fashions launched key enhancements and optimizations, addressing numerous challenges, and pushing the boundaries of what was attainable with the CNN architectures.
- Inception v2 (2015): The second model of Inception was modified with enhancements corresponding to batch normalization and shortcut connections. It additionally refined the inception modules by changing bigger convolutions with smaller, extra environment friendly ones. These adjustments improved accuracy and diminished coaching time.
- Inception v3 (2015): The v3 mannequin additional refined Inception v2 through the use of atrous convolution (dilated convolutions that increase the community’s receptive discipline with out sacrificing decision and considerably growing community parameters).
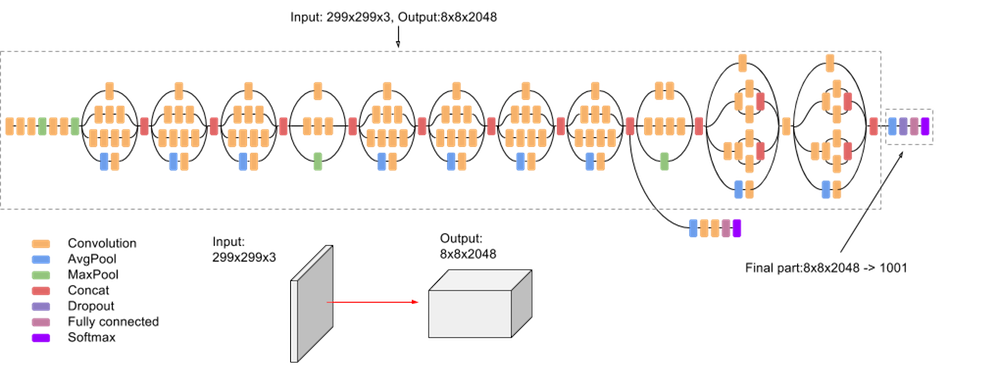
Inceptin v3 –source - Inception v4, Inception-ResNet v2 (2016): This model of Inception launched residual connections (impressed by ResNet) into the Inception lineage, which led to additional efficiency enhancements.
- Xception (2017): Xception changed Inception modules with depth-wise separable convolutions.
- MobileNet (2017): This structure is for cell and embedded units. The community makes use of depth-wise separable convolutions and linear bottleneck layers.
- EfficientNet (2019): It is a household of fashions that scales each mannequin dimension and accuracy strategically through the use of Neural Structure Search (NAS).
Conclusion
GoogLeNet or what we are able to name, Inception v1 contributed considerably to the event of CNNs with the introduction of the inception module, its use of numerous convolution filters in a single layer that expanded the community, and using 1×1 convolutions for dimensionality discount.
On account of the improvements, it received the ImageNet problem with a record-low error charge. Nonetheless, it reveals researchers how they’ll develop a deeper mannequin with out growing computational calls for considerably. In consequence, its successors, like Inception v2, v3, and so forth., constructed on the core concepts to attain even higher efficiency and suppleness