

Earlier than diving into Grounded Phase Something (Grounded-SAM), let’s take a quick refresher on the core applied sciences that underly it. Grounded Phase Something innovatively combines Grounding DINO’s zero-shot detection capabilities with Phase Something’s versatile picture segmentation. This integration permits detecting and segmenting objects inside pictures utilizing textual prompts.
About Us: We’re the creators of Viso Suite: the end-to-end machine studying infrastructure for enterprises. With Viso Suite, your complete ML pipeline is consolidated into an easy-to-use platform. To study extra, ebook a demo with the viso.ai workforce.
The Core Know-how Behind Grounded-SAM
Grounding DINO
Grounding DINO is a zero-shot detector, that means it will probably acknowledge and classify objects by no means seen throughout coaching. It leverages DINO (Distilled Data from Web pre-trained mOdels), to interpret free-form textual content and generate exact bounding bins and labels for objects inside pictures. Imaginative and prescient Transformers (ViTs) type the spine of this mannequin. These ViTs are skilled on huge, unlabeled picture datasets to study wealthy visible representations.
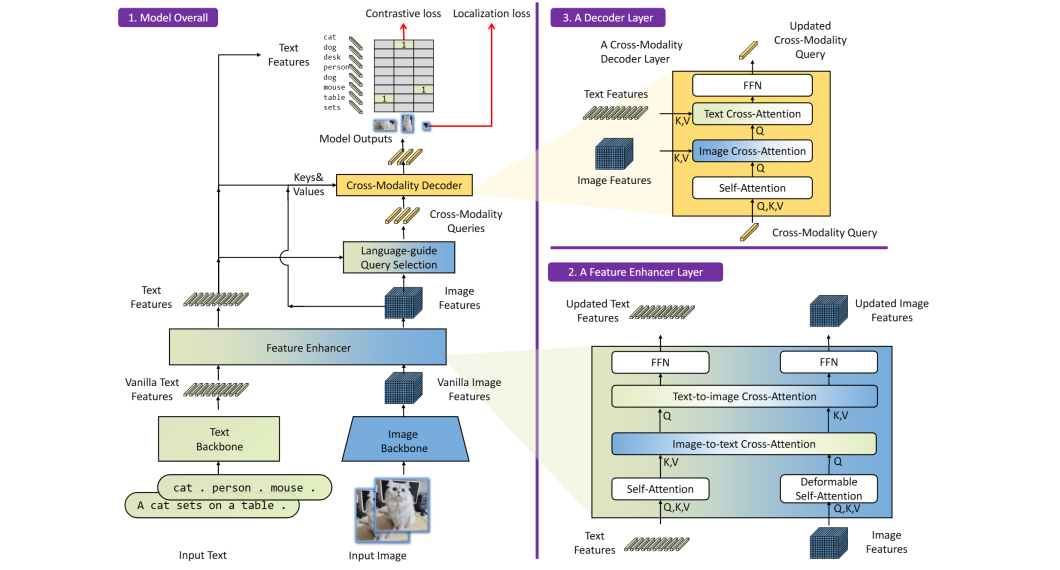
With out prior publicity to particular object lessons, Grounding DINO can perceive and localize pure language prompts. It acknowledges objects with excellent generalization utilizing an intuitive understanding of textual descriptions. It thereby successfully bridges the hole between language and visible notion.
Phase Something Mannequin (SAM)
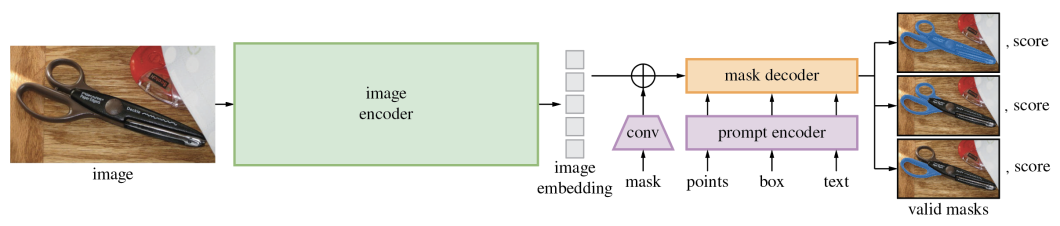
Phase Something (SAM) is a basis mannequin able to segmenting each discernible entity inside a picture. On high of textual description, it will probably additionally course of prompts as bounding bins or factors. Its segmentation mechanism accommodates many objects, no matter their classes.
It makes use of rules of few-shot studying and leverages ViTs to adapt to a flexible vary of segmentation duties. Few-shot machine studying fashions are designed to grasp or infer new duties and objects from a small quantity of coaching information.
SAM excels in producing detailed masks for objects by decoding varied prompts for fine-grained segmentation throughout arbitrary classes.
Collectively, Grounding DINO and Phase Something permits a extra pure, language-driven method to parsing visible content material. The synergy of those two applied sciences has the potential to supply two-fold advantages:
- Improve the accuracy of figuring out and delineating objects.
- Broaden the scope of laptop imaginative and prescient purposes to incorporate extra dynamic and contextually wealthy environments.
What’s Grounded-SAM?
Grounded-SAM goals to refine how fashions interpret and work together with visible content material. This framework combines the strengths of various fashions to “construct a really highly effective pipeline for fixing complicated issues.” They envision a modular framework whereby builders can substitute fashions with options as they see match. For instance, changing Grounding DINO with GLIP or Secure-Diffusion with ControlNet or GLIGEN with ChatGPT).
Powered by DistilBERT, Grounding DINO is a distilled model of the BERT mannequin optimized for pace and effectivity. The Grounded-SAM framework is liable for the primary half of the method. It interprets linguistic inputs into visible cues with a zero-shot detector that may establish objects from these descriptions. Grounding DINO does this by analyzing the textual content prompts to foretell picture labels and bounding bins.
That’s the place SAM is available in. It makes use of these text-derived cues to create detailed segmentation masks for the recognized objects.
It leverages a Transformer-based picture encoder to course of and translate visible enter right into a collection of characteristic embeddings. These embeddings are processed by a collection of convolutional layers. Mixed with inputs (factors, bounding bins, or textual descriptions) from a immediate encoder, it generates the varied segmentation masks.
The mannequin employs iterative refinement, with every layer refining the masks based mostly on visible options and immediate data. It makes use of methods resembling Masks R-CNN to fine-tune masks particulars.
How Does the Mannequin Study?
SAM learns via a mixture of supervised and few-shot studying approaches. It trains on a dataset curated from varied sources, together with frequent objects in context (COCO) and Visible Genome. These datasets include pre-segmented pictures accompanied by wealthy annotations. A meta-learning framework helps SAM section new objects with solely a handful of annotated examples via sample recognition.
By integrating the 2, Grounding DINO enhances the detection capabilities of SAM. That is particularly efficient when segmentation fashions battle because of the lack of labeled information for sure objects. Grounded-SAM can obtain this by:
- Utilizing Grounding DINO’s zero-shot detection capabilities to supply context and preliminary object localization.
- Utilizing SAM to refine the output into correct masks.
- Autodistill grounding methods assist the mannequin perceive and course of complicated visible information with out in depth supervision.

Grounded SAM achieves a 46.0 imply common precision (mAP) within the “Segmentation within the Wild” competitors’s zero-shot observe. This surpasses earlier fashions by substantial margins. Probably, this framework might contribute to AI fashions that perceive and work together with visuals extra humanly.
What’s extra, it streamlines the creation of coaching datasets via automated labeling.
Grounded-SAM Paper and Abstract of Benchmarking Outcomes
The open-source Grounded-SAM mannequin is accompanied by a paper describing its integration of Grounding DINO and SAM. Known as Grounded-SAM, it will probably detect and section pictures with out prior coaching on particular object lessons.
The paper evaluates Grounded-SAM’s efficiency on the difficult ‘Phase within the Wild’ (SIGw) dataset. And, for good measure, compares it to different common segmentation methods. The outcomes are promising, with Grounded-SAM variants outperforming present strategies throughout a number of classes. Grounded-SAM (B+H) scored the best mAP in lots of classes, showcasing its superior skill to generalize.
Right here’s a summarized benchmarking desk extracted from the paper:
| Methodology | meanSGinW | Elephants | Airplane-Components | Fruits | Hen | Telephones |
|---|---|---|---|---|---|---|
| X-Decoder-T | 22.6 | 65.6 | 10.5 | 66.5 | 12.0 | 29.9 |
| X-Decoder-L-IN22K | 26.6 | 63.9 | 12.3 | 79.1 | 3.5 | 43.4 |
| X-Decoder-B | 27.7 | 68.0 | 13.0 | 76.7 | 13.6 | 8.9 |
| X-Decoder-L | 32.2 | 66.0 | 13.1 | 79.2 | 8.6 | 15.6 |
| OpenSeeD-L | 36.7 | 72.9 | 13.0 | 76.4 | 82.9 | 7.6 |
| ODISE-L | 38.7 | 74.9 | 15.8 | 81.3 | 84.1 | 43.8 |
| SAN-CLIP-ViT-L | 41.4 | 67.4 | 13.2 | 77.4 | 69.2 | 10.4 |
| UNINEXT-H | 42.1 | 72.1 | 15.1 | 81.1 | 75.2 | 6.1 |
| Grounded-HQ-SAM(B+H) | 49.6 | 77.5 | 37.6 | 82.3 | 84.5 | 35.3 |
| Grounded-SAM(B+H) | 48.7 | 77.9 | 37.2 | 82.3 | 84.5 | 35.4 |
| Grounded-SAM(L+H) | 46.0 | 78.6 | 38.4 | 86.9 | 84.6 | 3.4 |
The outcomes spotlight Grounded-SAM’s superiority in zero-shot detection capabilities and segmentation accuracy. Grounded-SAM (B+H) does significantly effectively, with an general mAP of 48.7. Nonetheless, all Grounded-SAM-based fashions carried out effectively, with a mean rating of 48.1 in comparison with 33.5 for the remainder.
The one class wherein Grounded-SAM fashions lagged considerably behind others was cellphone segmentation. You possibly can evaluation the paper for a whole set of outcomes.
In conclusion, Grounded-SAM, seemingly signifies a major development within the area of AI-driven picture annotation.
Sensible Information on The best way to Use Grounded Phase Something and Combine with Numerous Platforms/Frameworks
The researchers behind Grounded-SAM encourage different builders to create attention-grabbing demos based mostly on the muse they offered. Or, to develop different new and attention-grabbing initiatives based mostly on Phase-Something. Consequently, it provides help for a spread of platforms and different laptop imaginative and prescient fashions, extending its versatility.
Here’s a fast, sensible information on how one can get began experimenting with Grounded-SAM:
Setting Up Grounded Phase Something Step-by-Step:
- Surroundings Preparation:
- Guarantee Python 3.8+ is put in.
- Arrange a digital surroundings (elective however really useful).
- Set up PyTorch 1.7+ with suitable CUDA help for GPU acceleration.
- Set up:
- Clone the GSA repository:
git clone [GSA-repo-url]. - Navigate to the cloned listing:
cd [GSA-repo-directory]. - Set up GSA:
pip set up -r necessities.txt.
- Clone the GSA repository:
- Configuration:
- Obtain the pre-trained fashions and place them within the specified listing.
- Modify the configuration recordsdata to match your native setup. Bear in mind to specify paths to fashions and information.
- Execution:
- Run the GSA script with applicable flags to your activity:
python run_gsa.py --input [input-path] --output [output-path]. - Make the most of offered Jupyter notebooks for interactive utilization and experimentation.
- Run the GSA script with applicable flags to your activity:
Integration with Different Platforms/Frameworks
Right here’s a listing of assorted platforms, frameworks, and parts you could combine with Grounded-SAM:
- OSX: Built-in as a one-stage movement seize technique that generates high-quality 3D human meshes from monocular pictures. Makes use of the UBody dataset for enhanced upper-body reconstruction accuracy.
- Secure-Diffusion: A high latent text-to-image diffusion mannequin to enhance the creation and refinement of visible content material.
- RAM: Employed for its picture tagging skills, able to precisely figuring out frequent classes throughout varied contexts.
- RAM++: The subsequent iteration of the RAM mannequin. It acknowledges an enormous array of classes with heightened precision and is a part of the venture’s object recognition module.
- BLIP: A language-vision mannequin that enhances the understanding of pictures.
- Visible ChatGPT: Serves as a bridge between ChatGPT and visible fashions for picture sending and receiving throughout conversations.
- Tag2Text: Gives each superior picture captioning and tagging, supporting the necessity for descriptive and correct picture annotations.
- VoxelNeXt: Absolutely sparse 3D object detector predicting objects straight from sparse voxel options.
We encourage trying out the GitHub repo for full steering on integrating with these and different applied sciences, such because the Gradio APP, Whisper, VISAM, and so on.
Use Circumstances, Functions, Challenges, and Future Instructions
GSA might make a distinction in varied sectors with its superior visible recognition capabilities. Surveillance, for instance, has the potential to enhance monitoring and menace detection. In healthcare, GSA’s precision in analyzing medical pictures aids in early analysis and therapy planning. Within the paper’s benchmarking checks, GSA-based fashions achieved the primary and second-highest scores for segmenting mind tumors.
GSA’s implementation throughout these fields not solely elevates product options but additionally spearheads innovation by tackling complicated visible recognition challenges. But, its deployment faces obstacles like excessive computational necessities, the necessity for huge, various datasets, and guaranteeing constant efficiency throughout completely different contexts.
Wanting forward, GSA’s trajectory contains refining its zero-shot studying capabilities to higher deal with unseen objects and situations. Additionally, broadening the mannequin’s skill to deal with low-resource settings and languages will make it extra accessible. Future integrations might embrace augmented and digital actuality platforms, opening new potentialities for interactive experiences.