

Introduction
The authors of this paper introduce Imagen, a text-to-image diffusion mannequin with a rare degree of photorealism and a deep degree of language comprehension.
With the target of extra completely evaluating text-to-image fashions, the authors present DrawBench, a complete and complicated benchmark for text-to-image fashions.
Imagen depends closely on diffusion fashions for high-quality picture technology and on large transformer language fashions for textual content comprehension. The principle discovering of this paper is that generic massive language fashions (e.g. T5), pretrained on text-only corpora, are surprisingly efficient at encoding textual content for picture synthesis; in Imagen, growing the dimensions of the language mannequin, boosts pattern constancy and image-text alignment rather more than growing the dimensions of the picture diffusion mannequin.
Associated works and Imagen
- Diffusion fashions have skilled widespread success in picture technology, prevailing over GANs in constancy and variety whereas avoiding coaching instability and mode collapse issues. Auto-regressive fashions, GANs, VQ-VAE, Transformer-based approaches, and diffusion fashions have made vital advances in text-to-image conversion, together with the concurrent DALL-E 2, which makes use of a diffusion prior on CLIP textual content latents and cascaded diffusion fashions to generate excessive decision 1024X1024 photos.
- Imagen, in accordance with the authors, is extra simpler because it doesn’t want studying a latent prior and will get increased ends in each MS-COCO FID and human evaluation on DrawBench.
Strategy
When in comparison with multi-modal embeddings like CLIP, the authors present that utilizing a big pre-trained language mannequin as a textual content encoder for Imagen has some advantages:
- Massive frozen language fashions educated solely on textual content information are surprisingly very efficient textual content encoders for text-to-image technology, and that scaling the dimensions of frozen textual content encoder improves pattern high quality considerably greater than scaling the dimensions of picture diffusion mannequin.
- The presence of dynamic thresholding, a novel diffusion sampling strategy that makes use of excessive steerage weights to generate extra lifelike and detailed photos than have been beforehand attainable.
- The authors emphasize some essential diffusion architectural design choices and supply Environment friendly U-Web, a novel structure different that’s easier, faster to converge, and makes use of much less reminiscence.
Evaluation of Imagen, coaching and outcomes
- It is fairly environment friendly to scale the dimensions of textual content encoders. Scaling up the textual content encoder persistently improves image-text alignment and picture high quality, as noticed by the authors. Imagen educated with the biggest textual content encoder, T5-XXL (4.6B parameters), yields one of the best outcomes (Fig. 4a)
- Bigger U-Nets are much less of a priority than scaling textual content encoder sizes. The authors found that growing the dimensions of the textual content encoder had a far bigger impact than growing the dimensions of the U-Web did on the pattern high quality (Fig. 4b).
- Using a dynamic threshold is crucial. Beneath the presence of considerable classifier-free steerage weights, dynamic thresholding generates samples with a lot improved photorealism and alignment with textual content in comparison with static or no thresholding (Fig. 4c).
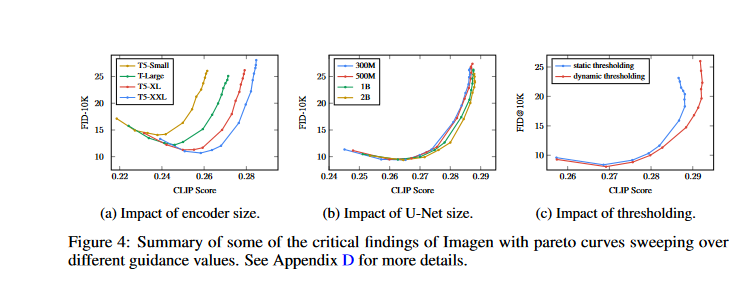
- The researchers practice a 2B parameter mannequin for the 64 × 64 text-to-image synthesis, and 600M and 400M parameter fashions for 64 × 64 → 256 × 256 and 256 × 256 → 1024 × 1024 for super- decision respectively. They use a batch dimension of 2048 and a pair of.5M coaching steps for all fashions. We use
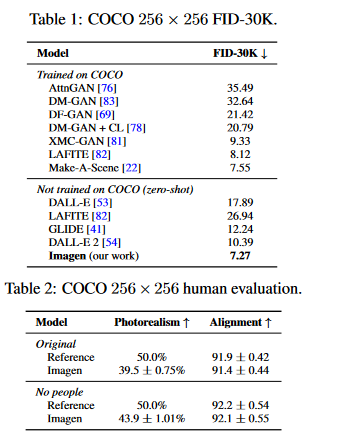
256 TPU-v4 chips for our base 64 × 64 mannequin, and 128 TPU-v4 chips for each super-resolution fashions - Imagen is evaluated on the COCO validation set utilizing the FID rating. The findings are proven in Desk 1. Imagen achieves state-of-the-art zero-shot FID on COCO at 7.27, prevailing over DALL-E 2 concurrent work and even fashions educated on COCO.
- Desk 2 summarizes the human evaluation of picture high quality and alignment on the COCO validation set. The authors present findings for the unique COCO validation set in addition to a filtered model that excludes any reference information together with individuals. Imagen has a 39.2% desire ranking for photorealism, suggesting excellent picture technology. Imagen’s desire charge will increase to 43.6% on the scene with no individuals, suggesting Imagen’s restricted capability to generate lifelike individuals.
- Imagen’s rating for caption similarity is on par with the unique reference photos, indicating Imagen’s capability to generate photos that correspond properly with COCO captions.
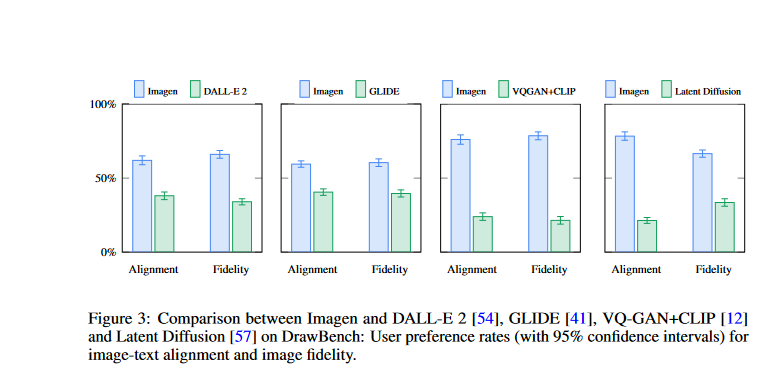
- On the COCO validation set, fashions educated with both the T5-XXL or CLIP textual content encoders present related CLIP and FID scores. On DrawBench, nonetheless, human raters favor T5-XXL over CLIP in all 11 classes.
- The authors use DrawBench to check Imagen to different present approaches together with VQ-GAN+CLIP, Latent Diffusion Fashions, GLIDE, and DALL-E 2, they usually present that Imagen is most well-liked by human raters over the opposite fashions by way of pattern high quality and image-text alignment.
- Each pattern constancy and image-text alignment are a lot improved by conditioning throughout the sequence of textual content embeddings with cross consideration.
Evaluating Textual content-to-Picture Fashions
we introduce DrawBench, a complete and difficult set of prompts that help the analysis and comparability of text-to-image fashions. DrawBench comprises 11 classes of prompts, testing totally different capabilities of fashions comparable to the flexibility to faithfully render totally different colours, numbers of objects, spatial relations, textual content within the scene, and strange interactions between objects.
- Picture constancy (FID) and image-text alignment (CLIP rating) are two of a very powerful automated efficiency indicators.
- The authors current zero-shot FID-30K, which follows within the footsteps of comparable analysis by reporting a technique through which 30K randomly chosen samples from the validation set are used to construct mannequin samples, that are then in comparison with reference photos taken from the whole validation set.
- As a result of significance of steerage weight in regulating picture high quality and textual content alignment, many of the ablation findings within the paper are proven as trade-off (or pareto) curves between CLIP and FID scores for varied values of steerage weight.
- To check picture high quality, they ask the rater, “Which picture is extra photorealistic (appears extra actual)?” and supply them with choices starting from the model-generated picture to the reference picture. The variety of instances raters choose mannequin generations over reference photos is reported.
- To check alignment, human raters are offered a picture and a immediate with the query: “Does the caption precisely describe the above picture?”. They’ve three choices for a response: “sure,” “considerably,” and “no.” The scores for these choices are 100, 50, and 0 accordingly. These scores are obtained independently for mannequin samples and reference photos, and each are reported.
- In each eventualities, the authors used 200 randomly chosen image-caption pairs from the COCO validation set. Topics obtained 50 photos in batches. In addition they used interleaved “management” trials and solely included information from raters who answered at the least 80% of the management questions appropriately. This resulted in 73 and 51 scores per picture for picture high quality and image-text alignment, respectively.
Conclusion
Imagen demonstrates how efficient frozen big pre-trained language fashions may be when used as textual content encoders for text-to-image technology utilizing diffusion fashions.
Of their subsequent work, the authors plan to analyze a framework for accountable externalization. This framework will stability the advantages of unbiased overview with the risks of unrestricted open entry.
The information used to coach Imagen got here from a wide range of pre-existing datasets that contained pairs of photos and English alt textual content. A few of this information was filtered to take away noise and something deemed inappropriate, comparable to pornographic photos and offensive language. Nevertheless, a latest examination of one of many information sources, LAION-400M, revealed a variety of offensive materials, together with pornographic photos, racial epithets, and dangerous social stereotypes.
The significance of thorough dataset audits and detailed dataset documentation to information judgments in regards to the applicable and protected use of the mannequin is underscored by this discovery, which contributes to the conclusion that Imagen isn’t prepared for public use at the moment. Imagen, like different large-scale language fashions, is biased and restricted by its use of textual content encoders educated on uncurated web-scale information.
Reference
Photorealistic Textual content-to-Picture Diffusion Fashions with Deep Language Understanding
We current Imagen, a text-to-image diffusion mannequin with an unprecedented
diploma of photorealism and a deep degree of language understanding. Imagen
builds on the ability of enormous transformer language fashions in understanding textual content
and hinges on the power of diffusion fashions in high-fidelity picture
gene…