

Convey this challenge to life
This text is about among the finest GANs as we speak, StyleGAN from the paper A Model-Primarily based Generator Structure for Generative Adversarial Networks, we are going to make a clear, easy, and readable implementation of it utilizing PyTorch, and attempt to replicate the unique paper as intently as attainable, so for those who learn the paper, the implementation must be just about similar.
If you happen to do not learn the StyleGAN1 paper or do not know the way it works and also you wish to perceive it, I extremely advocate you to take a look at this weblog submit the place I’m going via the small print of it.
The dataset that we’ll use on this weblog is that this dataset from Kaggle which comprises 16240 higher garments for ladies with 256*192 decision.
Load all dependencies we’d like
We first will import torch since we are going to use PyTorch, and from there we import nn. That may assist us create and prepare the networks, and likewise allow us to import optim, a package deal that implements numerous optimization algorithms (e.g. sgd, adam,..). From torchvision we import datasets and transforms to arrange the information and apply some transforms.
We’ll import practical as F from torch.nn to upsample the pictures utilizing interpolate, DataLoader from torch.utils.information to create mini-batch sizes, save_image from torchvision.utils to avoid wasting faux samples, and log2 type math as a result of we’d like the inverse illustration of the ability of two to implement the adaptive minibatch measurement relying on the output decision, NumPy for linear algebra, os for interplay with the working system, tqdm to point out progress bars, and eventually matplotlib.pyplot to point out the outcomes and evaluate them with the true ones.
import torch
from torch import nn, optim
from torchvision import datasets, transforms
import torch.nn.practical as F
from torch.utils.information import DataLoader
from torchvision.utils import save_image
from math import log2
import numpy as np
import os
from tqdm import tqdm
import matplotlib.pyplot as plt
Hyperparameters
- Initialize the DATASET by the trail of the true photos.
- Specify the beginning prepare at picture measurement 8×8.
- Initialize the gadget by Cuda whether it is obtainable and CPU in any other case, and studying charge by 0.001.
- The batch measurement might be totally different relying on the decision of the pictures that we wish to generate, so we initialize BATCH_SIZES by an inventory of numbers, you’ll be able to change them relying in your VRAM.
- Initialize image_size by 128 and CHANNELS_IMG by 3 as a result of we are going to generate 128 by 128 RGB photos.
- Within the unique paper, they initialize Z_DIM, W_DIM, and IN_CHANNELS by 512, however I initialize them by 256 as a substitute for much less VRAM utilization and speed-up coaching. We might even perhaps get higher outcomes if we doubled them.
- For StyleGAN we will use any of the GANs loss capabilities we wish, so I exploit WGAN-GP from the paper Improved Coaching of Wasserstein GANs. This loss comprises a parameter title λ and it is common to set λ = 10.
- Initialize PROGRESSIVE_EPOCHS by 30 for every picture measurement.
DATASET = "Ladies garments"
START_TRAIN_AT_IMG_SIZE = 8 #The authors begin from 8x8 photos as a substitute of 4x4
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
LEARNING_RATE = 1e-3
BATCH_SIZES = [256, 128, 64, 32, 16, 8]
CHANNELS_IMG = 3
Z_DIM = 256
W_DIM = 256
IN_CHANNELS = 256
LAMBDA_GP = 10
PROGRESSIVE_EPOCHS = [30] * len(BATCH_SIZES)Get information loader
Now let’s create a operate get_loader to:
- Apply some transformation to the pictures (resize the pictures to the decision that we wish, convert them to tensors, then apply some augmentation, and eventually normalize them to be all of the pixels starting from -1 to 1).
- Determine the present batch measurement utilizing the record BATCH_SIZES, and take as an index the integer variety of the inverse illustration of the ability of two of image_size/4. And that is truly how we implement the adaptive minibatch measurement relying on the output decision.
- Put together the dataset through the use of ImageFolder as a result of it is already structured in a pleasant method.
- Create mini-batch sizes utilizing DataLoader that take the dataset and batch measurement with shuffling the information.
- Lastly, return the loader and dataset.
def get_loader(image_size):
rework = transforms.Compose(
[
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.RandomHorizontalFlip(p=0.5),
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)],
[0.5 for _ in range(CHANNELS_IMG)],
),
]
)
batch_size = BATCH_SIZES[int(log2(image_size / 4))]
dataset = datasets.ImageFolder(root=DATASET, rework=rework)
loader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
)
return loader, dataset
Fashions implementation
Now let’s Implement the StyleGAN1 generator and discriminator(ProGAN and StyleGAN1 have the identical discriminator structure) with the important thing attributions from the paper. We’ll attempt to make the implementation compact but in addition maintain it readable and comprehensible. Particularly, the important thing factors:
- Noise Mapping Community
- Adaptive Occasion Normalization (AdaIN)
- Progressive rising
On this tutorial, we are going to simply generate photos with StyleGAN1, and never implement model mixing and stochastic variation, but it surely should not be laborious to take action.
Let’s outline a variable with the title elements that comprise the numbers that may multiply with IN_CHANNELS to have the variety of channels that we wish in every picture decision.
elements = [1, 1, 1, 1, 1 / 2, 1 / 4, 1 / 8, 1 / 16, 1 / 32]Noise Mapping Community
The noise mapping community takes Z and places it via eight absolutely related layers separated by some activation. And remember to equalize the training charge because the authors do in ProGAN (ProGAN and StyleGan authored by the identical researchers).
Let’s first construct a category with the title WSLinear (weighted scaled Linear) which might be inherited from nn.Module.
- Within the init half we ship in_features and out_channels. Create a linear layer, then we outline a scale that might be equal to the sq. root of two divided by in_features, we copy the bias of the present column layer right into a variable as a result of we do not need the bias of the linear layer to be scaled, then we take away it, Lastly, we initialize linear layer.
- Within the ahead half, we ship x and all that we’re going to do is multiplicate x with scale and add the bias after reshaping it.
class WSLinear(nn.Module):
def __init__(
self, in_features, out_features,
):
tremendous(WSLinear, self).__init__()
self.linear = nn.Linear(in_features, out_features)
self.scale = (2 / in_features)**0.5
self.bias = self.linear.bias
self.linear.bias = None
# initialize linear layer
nn.init.normal_(self.linear.weight)
nn.init.zeros_(self.bias)
def ahead(self, x):
return self.linear(x * self.scale) + self.biasNow let’s create the MappingNetwork class.
- Within the init half we ship z_dim and w_din, and we outline the community mapping that first normalizes z_dim, adopted by eight of WSLInear and ReLU as activation capabilities.
- Within the ahead half, we return the community mapping.
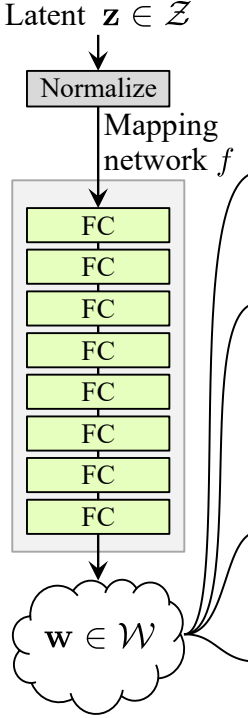
class MappingNetwork(nn.Module):
def __init__(self, z_dim, w_dim):
tremendous().__init__()
self.mapping = nn.Sequential(
PixelNorm(),
WSLinear(z_dim, w_dim),
nn.ReLU(),
WSLinear(w_dim, w_dim),
nn.ReLU(),
WSLinear(w_dim, w_dim),
nn.ReLU(),
WSLinear(w_dim, w_dim),
nn.ReLU(),
WSLinear(w_dim, w_dim),
nn.ReLU(),
WSLinear(w_dim, w_dim),
nn.ReLU(),
WSLinear(w_dim, w_dim),
nn.ReLU(),
WSLinear(w_dim, w_dim),
)
def ahead(self, x):
return self.mapping(x)Adaptive Occasion Normalization (AdaIN)
Now let’s create AdaIN class
- Within the init half we ship channels, w_dim, and we initialize instance_norm which would be the occasion normalization half, and we initialize style_scale and style_bias which would be the adaptive components with WSLinear that maps the Noise Mapping Community W into channels.
- Within the ahead go, we ship x, apply occasion normalization for it, and return style_sclate * x + style_bias.
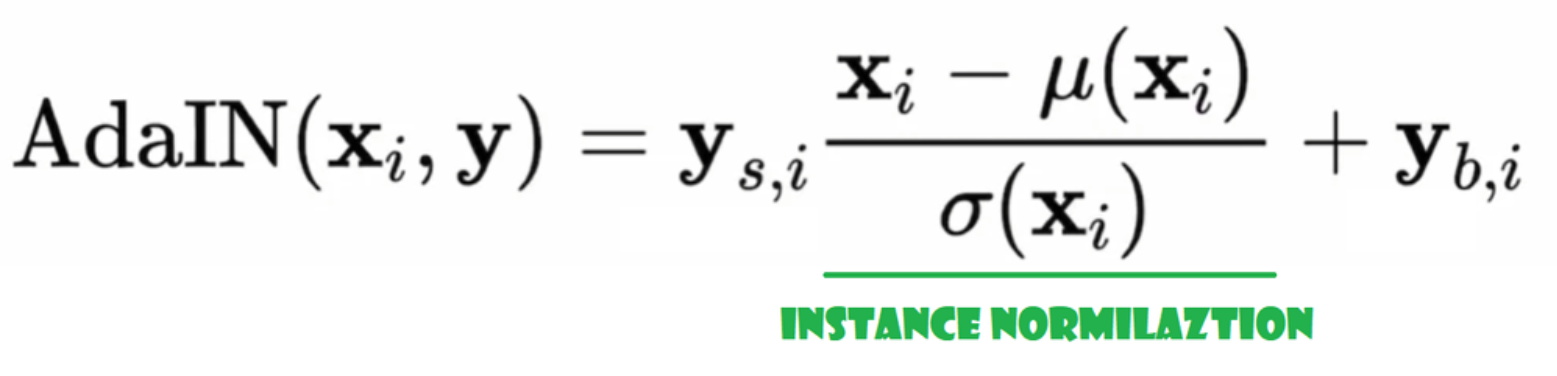
class AdaIN(nn.Module):
def __init__(self, channels, w_dim):
tremendous().__init__()
self.instance_norm = nn.InstanceNorm2d(channels)
self.style_scale = WSLinear(w_dim, channels)
self.style_bias = WSLinear(w_dim, channels)
def ahead(self, x, w):
x = self.instance_norm(x)
style_scale = self.style_scale(w).unsqueeze(2).unsqueeze(3)
style_bias = self.style_bias(w).unsqueeze(2).unsqueeze(3)
return style_scale * x + style_biasInject Noise
Now let’s create the category InjectNoise to inject the noise into the generator
- Within the init half we despatched channels and we initialize weight from a random regular distribution and we use nn.Parameter in order that these weights could be optimized
- Within the ahead half, we ship a picture x and we return it with random noise added
class InjectNoise(nn.Module):
def __init__(self, channels):
tremendous().__init__()
self.weight = nn.Parameter(torch.zeros(1, channels, 1, 1))
def ahead(self, x):
noise = torch.randn((x.form[0], 1, x.form[2], x.form[3]), gadget=x.gadget)
return x + self.weight * noiseuseful lessons
The authors construct StyleGAN upon the official implementation of ProGAN by Karras et al, they use the identical discriminator structure, adaptive minibatch measurement, hyperparameters, and many others. So there are a number of lessons that keep the identical from ProGAN implementation.
On this part, we are going to create the lessons that don’t change from the ProGAN structure that I’ve already defined on this submit weblog.
Within the code snippet under you could find the category WSConv2d (weighted scaled convolutional layer) to Equalized Studying Fee for the conv layers.
class WSConv2d(nn.Module):
def __init__(
self, in_channels, out_channels, kernel_size=3, stride=1, padding=1
):
tremendous(WSConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.scale = (2 / (in_channels * (kernel_size ** 2))) ** 0.5
self.bias = self.conv.bias
self.conv.bias = None
# initialize conv layer
nn.init.normal_(self.conv.weight)
nn.init.zeros_(self.bias)
def ahead(self, x):
return self.conv(x * self.scale) + self.bias.view(1, self.bias.form[0], 1, 1)Within the code snippet under you could find the category PixelNorm to normalize Z earlier than the Noise Mapping Community.
class PixelNorm(nn.Module):
def __init__(self):
tremendous(PixelNorm, self).__init__()
self.epsilon = 1e-8
def ahead(self, x):
return x / torch.sqrt(torch.imply(x ** 2, dim=1, keepdim=True) + self.epsilon) Within the code snippet under you could find the category ConvBock that may assist us create the discriminator.
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels):
tremendous(ConvBlock, self).__init__()
self.conv1 = WSConv2d(in_channels, out_channels)
self.conv2 = WSConv2d(out_channels, out_channels)
self.leaky = nn.LeakyReLU(0.2)
def ahead(self, x):
x = self.leaky(self.conv1(x))
x = self.leaky(self.conv2(x))
return xWithin the code snippet under you could find the category Discriminatowich is similar as in ProGAN.
class Discriminator(nn.Module):
def __init__(self, in_channels, img_channels=3):
tremendous(Discriminator, self).__init__()
self.prog_blocks, self.rgb_layers = nn.ModuleList([]), nn.ModuleList([])
self.leaky = nn.LeakyReLU(0.2)
# right here we work again methods from elements as a result of the discriminator
# must be mirrored from the generator. So the primary prog_block and
# rgb layer we append will work for enter measurement 1024x1024, then 512->256-> and many others
for i in vary(len(elements) - 1, 0, -1):
conv_in = int(in_channels * elements[i])
conv_out = int(in_channels * elements[i - 1])
self.prog_blocks.append(ConvBlock(conv_in, conv_out))
self.rgb_layers.append(
WSConv2d(img_channels, conv_in, kernel_size=1, stride=1, padding=0)
)
# maybe complicated title "initial_rgb" that is simply the RGB layer for 4x4 enter measurement
# did this to "mirror" the generator initial_rgb
self.initial_rgb = WSConv2d(
img_channels, in_channels, kernel_size=1, stride=1, padding=0
)
self.rgb_layers.append(self.initial_rgb)
self.avg_pool = nn.AvgPool2d(
kernel_size=2, stride=2
) # down sampling utilizing avg pool
# that is the block for 4x4 enter measurement
self.final_block = nn.Sequential(
# +1 to in_channels as a result of we concatenate from MiniBatch std
WSConv2d(in_channels + 1, in_channels, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
WSConv2d(in_channels, in_channels, kernel_size=4, padding=0, stride=1),
nn.LeakyReLU(0.2),
WSConv2d(
in_channels, 1, kernel_size=1, padding=0, stride=1
), # we use this as a substitute of linear layer
)
def fade_in(self, alpha, downscaled, out):
"""Used to fade in downscaled utilizing avg pooling and output from CNN"""
# alpha must be scalar inside [0, 1], and upscale.form == generated.form
return alpha * out + (1 - alpha) * downscaled
def minibatch_std(self, x):
batch_statistics = (
torch.std(x, dim=0).imply().repeat(x.form[0], 1, x.form[2], x.form[3])
)
# we take the std for every instance (throughout all channels, and pixels) then we repeat it
# for a single channel and concatenate it with the picture. On this method the discriminator
# will get details about the variation within the batch/picture
return torch.cat([x, batch_statistics], dim=1)
def ahead(self, x, alpha, steps):
# the place we should always begin within the record of prog_blocks, perhaps a bit complicated however
# the final is for the 4x4. So instance as an instance steps=1, then we should always begin
# on the second to final as a result of input_size might be 8x8. If steps==0 we simply
# use the ultimate block
cur_step = len(self.prog_blocks) - steps
# convert from rgb as preliminary step, this may rely upon
# the picture measurement (every could have it is on rgb layer)
out = self.leaky(self.rgb_layers[cur_step](x))
if steps == 0: # i.e, picture is 4x4
out = self.minibatch_std(out)
return self.final_block(out).view(out.form[0], -1)
# as a result of prog_blocks would possibly change the channels, for down scale we use rgb_layer
# from earlier/smaller measurement which in our case correlates to +1 within the indexing
downscaled = self.leaky(self.rgb_layers[cur_step + 1](self.avg_pool(x)))
out = self.avg_pool(self.prog_blocks[cur_step](out))
# the fade_in is completed first between the downscaled and the enter
# that is reverse from the generator
out = self.fade_in(alpha, downscaled, out)
for step in vary(cur_step + 1, len(self.prog_blocks)):
out = self.prog_blocks[step](out)
out = self.avg_pool(out)
out = self.minibatch_std(out)
return self.final_block(out).view(out.form[0], -1)Generator
Within the generator structure, we now have some patterns that repeat so let’s first create a category for it to make our code as clear as attainable, let’s title the category GenBlock which might be inherited from nn.Module.
- Within the init half we ship in_channels, out_channels, and w_dim, then we initialize conv1 by WSConv2d which maps in_channels to out_channels, conv2 by WSConv2d which maps out_channels to out_channels, leaky by Leaky ReLU with a slope of 0.2 as they use within the paper, inject_noise1, inject_noise2 by the InjectNoise, adain1, and adain2 by AdaIN
- Within the ahead half, we ship x, and we go it to conv1 then to inject_noise1 with leaky, then we normalize it with adain1, and once more we go that into conv2 then to inject_noise2 with leaky and we normalize it with adain2. And at last, we return x.
class GenBlock(nn.Module):
def __init__(self, in_channels, out_channels, w_dim):
tremendous(GenBlock, self).__init__()
self.conv1 = WSConv2d(in_channels, out_channels)
self.conv2 = WSConv2d(out_channels, out_channels)
self.leaky = nn.LeakyReLU(0.2, inplace=True)
self.inject_noise1 = InjectNoise(out_channels)
self.inject_noise2 = InjectNoise(out_channels)
self.adain1 = AdaIN(out_channels, w_dim)
self.adain2 = AdaIN(out_channels, w_dim)
def ahead(self, x, w):
x = self.adain1(self.leaky(self.inject_noise1(self.conv1(x))), w)
x = self.adain2(self.leaky(self.inject_noise2(self.conv2(x))), w)
return xNow we now have all that we have to create the generator.
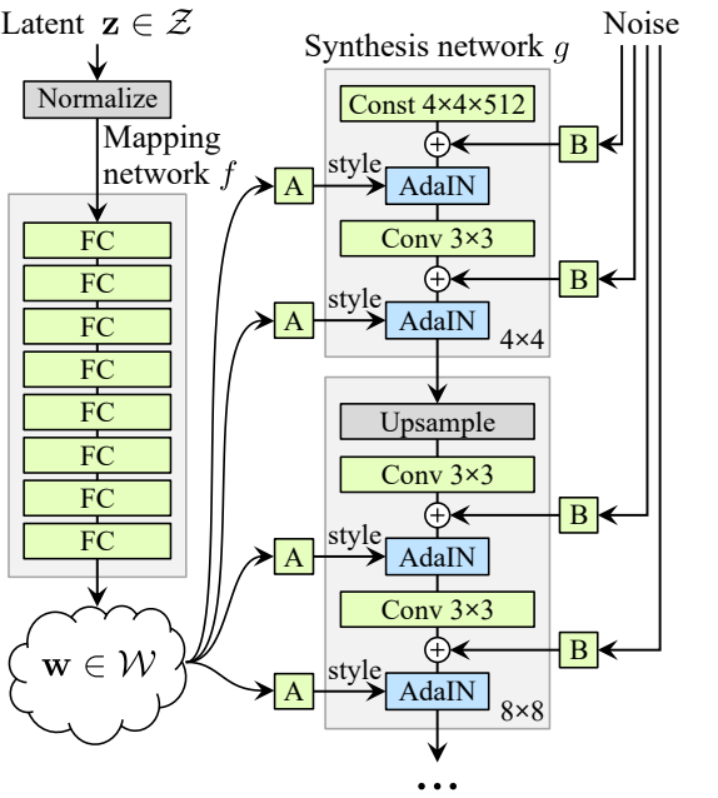
- within the init half let’s initialize ‘starting_constant’ by fixed 4 x 4 (x 512 channel for the unique paper, and 256 in our case) tensor which is put via an iteration of the generator, map by ‘MappingNetwork’, initial_adain1, initial_adain2 by AdaIN, initial_noise1, initial_noise2 by InjectNoise, initial_conv by a conv layer that map in_channels to itself, leaky by Leaky ReLU with a slope of 0.2, initial_rgb by WSConv2d that maps in_channels to img_channels wi=hich is 3 for RGB, prog_blocks by ModuleList() that may comprise all of the progressive blocks (we point out convolution enter/output channels by multiplicate in_channels which is 512 in paper and 256 in our case with elements), and rgb_blocks by ModuleList() that may comprise all of the RGB blocks.
- To fade in new layers (an origin part of ProGAN), we add the fade_in half, which we ship alpha, scaled, and generated, and we return [tanh(alpha∗generated+(1−alpha)∗upscale)], The rationale why we use tanh is that would be the output(the generated picture) and we wish the pixels to be vary between 1 and -1.
- Within the ahead half, we ship the noise (Z_dim), the alpha worth which goes to fade in slowly throughout coaching (alpha is between 0 and 1), and steps which is the quantity of the present decision that we’re working with, we go x into the map to get the intermediate noise vector W, we go starting_constant to initial_noise1, apply for it and for W initial_adain1, then we passe it into initial_conv, and once more we add initial_noise2 for it with leaky as activation operate, and apply for it and W initial_adain2. Then we test if steps = 0 whether it is, then all we wish to do is run it via the preliminary RGB and we now have carried out, in any other case, we loop over the variety of steps, and in every loop we upscaling(upscaled) and we run via the progressive block that corresponds to that decision(out). In the long run, we return fade_in that takes alpha, final_out, and final_upscaled after mapping it to RGB.
class Generator(nn.Module):
def __init__(self, z_dim, w_dim, in_channels, img_channels=3):
tremendous(Generator, self).__init__()
self.starting_constant = nn.Parameter(torch.ones((1, in_channels, 4, 4)))
self.map = MappingNetwork(z_dim, w_dim)
self.initial_adain1 = AdaIN(in_channels, w_dim)
self.initial_adain2 = AdaIN(in_channels, w_dim)
self.initial_noise1 = InjectNoise(in_channels)
self.initial_noise2 = InjectNoise(in_channels)
self.initial_conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
self.leaky = nn.LeakyReLU(0.2, inplace=True)
self.initial_rgb = WSConv2d(
in_channels, img_channels, kernel_size=1, stride=1, padding=0
)
self.prog_blocks, self.rgb_layers = (
nn.ModuleList([]),
nn.ModuleList([self.initial_rgb]),
)
for i in vary(len(elements) - 1): # -1 to forestall index error due to elements[i+1]
conv_in_c = int(in_channels * elements[i])
conv_out_c = int(in_channels * elements[i + 1])
self.prog_blocks.append(GenBlock(conv_in_c, conv_out_c, w_dim))
self.rgb_layers.append(
WSConv2d(conv_out_c, img_channels, kernel_size=1, stride=1, padding=0)
)
def fade_in(self, alpha, upscaled, generated):
# alpha must be scalar inside [0, 1], and upscale.form == generated.form
return torch.tanh(alpha * generated + (1 - alpha) * upscaled)
def ahead(self, noise, alpha, steps):
w = self.map(noise)
x = self.initial_adain1(self.initial_noise1(self.starting_constant), w)
x = self.initial_conv(x)
out = self.initial_adain2(self.leaky(self.initial_noise2(x)), w)
if steps == 0:
return self.initial_rgb(x)
for step in vary(steps):
upscaled = F.interpolate(out, scale_factor=2, mode="bilinear")
out = self.prog_blocks[step](upscaled, w)
# The variety of channels in upscale will keep the identical, whereas
# out which has moved via prog_blocks would possibly change. To make sure
# we will convert each to rgb we use totally different rgb_layers
# (steps-1) and steps for upscaled, out respectively
final_upscaled = self.rgb_layers[steps - 1](upscaled)
final_out = self.rgb_layers[steps](out)
return self.fade_in(alpha, final_upscaled, final_out)
Utils
Within the code snippet under you could find the generate_examples operate that takes the generator gen, the variety of steps to establish the present decision, and a quantity n=100. The purpose of this operate is to generate n faux photos and save them consequently.
def generate_examples(gen, steps, n=100):
gen.eval()
alpha = 1.0
for i in vary(n):
with torch.no_grad():
noise = torch.randn(1, Z_DIM).to(DEVICE)
img = gen(noise, alpha, steps)
if not os.path.exists(f'saved_examples/step{steps}'):
os.makedirs(f'saved_examples/step{steps}')
save_image(img*0.5+0.5, f"saved_examples/step{steps}/img_{i}.png")
gen.prepare()Within the code snippet under you could find the gradient_penalty operate for WGAN-GP loss.
def gradient_penalty(critic, actual, faux, alpha, train_step, gadget="cpu"):
BATCH_SIZE, C, H, W = actual.form
beta = torch.rand((BATCH_SIZE, 1, 1, 1)).repeat(1, C, H, W).to(gadget)
interpolated_images = actual * beta + faux.detach() * (1 - beta)
interpolated_images.requires_grad_(True)
# Calculate critic scores
mixed_scores = critic(interpolated_images, alpha, train_step)
# Take the gradient of the scores with respect to the pictures
gradient = torch.autograd.grad(
inputs=interpolated_images,
outputs=mixed_scores,
grad_outputs=torch.ones_like(mixed_scores),
create_graph=True,
retain_graph=True,
)[0]
gradient = gradient.view(gradient.form[0], -1)
gradient_norm = gradient.norm(2, dim=1)
gradient_penalty = torch.imply((gradient_norm - 1) ** 2)
return gradient_penaltyCoaching
On this part, we are going to prepare our StyleGAN
Convey this challenge to life
Prepare operate
For the prepare operate, we ship critic (which is the discriminator), gen(generator), loader, dataset, step, alpha, and optimizer for the generator and for the critic.
We begin by looping over all of the mini-batch sizes that we create with the DataLoader, and we take simply the pictures as a result of we do not want a label.
Then we arrange the coaching for the discriminatorCritic once we wish to maximize E(critic(actual)) – E(critic(faux)). This equation means how a lot the critic can distinguish between actual and faux photos.
After that, we arrange the coaching for the generator once we wish to maximize E(critic(faux)).
Lastly, we replace the loop and the alpha worth for fade_in and be sure that it’s between 0 and 1, and we return it.
def train_fn(
critic,
gen,
loader,
dataset,
step,
alpha,
opt_critic,
opt_gen,
):
loop = tqdm(loader, go away=True)
for batch_idx, (actual, _) in enumerate(loop):
actual = actual.to(DEVICE)
cur_batch_size = actual.form[0]
noise = torch.randn(cur_batch_size, Z_DIM).to(DEVICE)
faux = gen(noise, alpha, step)
critic_real = critic(actual, alpha, step)
critic_fake = critic(faux.detach(), alpha, step)
gp = gradient_penalty(critic, actual, faux, alpha, step, gadget=DEVICE)
loss_critic = (
-(torch.imply(critic_real) - torch.imply(critic_fake))
+ LAMBDA_GP * gp
+ (0.001 * torch.imply(critic_real ** 2))
)
critic.zero_grad()
loss_critic.backward()
opt_critic.step()
gen_fake = critic(faux, alpha, step)
loss_gen = -torch.imply(gen_fake)
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
# Replace alpha and guarantee lower than 1
alpha += cur_batch_size / (
(PROGRESSIVE_EPOCHS[step] * 0.5) * len(dataset)
)
alpha = min(alpha, 1)
loop.set_postfix(
gp=gp.merchandise(),
loss_critic=loss_critic.merchandise(),
)
return alpha
Coaching
Now since we now have all the things let’s put them collectively to coach our StyleGAN.
We begin by initializing the generator, the discriminator/critic, and optimizers, then convert the generator and the critic into prepare mode, then loop over PROGRESSIVE_EPOCHS, and in every loop, we name the prepare operate variety of epoch occasions, then we generate some faux photos and save them, consequently, utilizing generate_examples operate, and eventually, we progress to the following picture decision.
gen = Generator(
Z_DIM, W_DIM, IN_CHANNELS, img_channels=CHANNELS_IMG
).to(DEVICE)
critic = Discriminator(IN_CHANNELS, img_channels=CHANNELS_IMG).to(DEVICE)
# initialize optimizers
opt_gen = optim.Adam([{"params": [param for name, param in gen.named_parameters() if "map" not in name]},
{"params": gen.map.parameters(), "lr": 1e-5}], lr=LEARNING_RATE, betas=(0.0, 0.99))
opt_critic = optim.Adam(
critic.parameters(), lr=LEARNING_RATE, betas=(0.0, 0.99)
)
gen.prepare()
critic.prepare()
# begin at step that corresponds to img measurement that we set in config
step = int(log2(START_TRAIN_AT_IMG_SIZE / 4))
for num_epochs in PROGRESSIVE_EPOCHS[step:]:
alpha = 1e-5 # begin with very low alpha
loader, dataset = get_loader(4 * 2 ** step)
print(f"Present picture measurement: {4 * 2 ** step}")
for epoch in vary(num_epochs):
print(f"Epoch [{epoch+1}/{num_epochs}]")
alpha = train_fn(
critic,
gen,
loader,
dataset,
step,
alpha,
opt_critic,
opt_gen
)
generate_examples(gen, step)
step += 1 # progress to the following img measurement
End result
Hopefully, it is possible for you to to observe the entire steps and get a very good understanding of the way to implement StyleGAN in the precise method. Now let’s take a look at the outcomes that we acquire after coaching this mannequin on this dataset with 128*x 128 decision.

Conclusion
On this article, we make a clear, easy, and readable implementation from scratch of StyleGAN1 utilizing PyTorch. we replicate the unique paper as intently as attainable, so for those who learn the paper the implementation must be just about similar.
Within the upcoming articles, we are going to clarify in depth and implement from scratch StyleGAN2 which is an enchancment over StyleGAN1.