

Llama 2 is right here – the newest pre-trained massive language mannequin (LLM) by Meta AI, succeeding Llama model 1. The mannequin marks the following wave of generative fashions characterizing security and moral utilization whereas leveraging the advantages of the broader synthetic intelligence (AI) group by open-sourcing its mannequin for analysis and business software.
On this article, we’ll focus on:
- What Llama 2 is and the way it differs from its predecessor
- Mannequin structure and growth particulars
- Llama 2 use instances and examples
- Advantages and challenges in comparison with options
- Lllama fine-tuning ideas for downstream duties
About us: Viso.ai gives a strong enterprise platform Viso Suite to construct and scale pc imaginative and prescient end-to-end with no-code instruments. Our software program helps trade leaders effectively implement real-world deep studying AI functions with minimal overhead for all downstream duties. Get a demo.
What’s Llama 2?
Llama 2 is an open-source massive language mannequin (LLM) by Meta AI launched in July 2023 with a pre-trained and fine-tuned model known as Llama 2 Chat. The static mannequin was educated between January 2023 and July 2023 on an offline dataset.
The mannequin has three variants, every with 7 billion, 13 billion, and 70 billion parameters, respectively. The brand new Llama mannequin provides varied enhancements over its predecessor, Llama 1. These embrace:
- The power to course of 4096 tokens versus 2048 in Llama 1.
- Pre-training information consists of two trillion tokens in comparison with 1 trillion within the earlier model.
Moreover, Llama 1’s largest variant was capped at 65 Billion parameters, which has elevated to 70 Billion in Llama 2. These structural enhancements enhance the mannequin’s robustness, permit it to recollect longer sequences, and supply a extra acceptable response to person queries.
How Giant Language Fashions (LLMS) work
Giant Language Fashions (LLMs) are the powerhouses behind a lot of right this moment’s generative AI functions, from chatbots to content material creation instruments. Typically, LLMs are educated on huge quantities of textual content information to foretell the following phrase in a sentence. Here’s what it’s a must to find out about LLMs:
LLMs require coaching on huge datasets. Due to this fact, they’re fed billions of phrases from books, articles, web sites, social media (X, Fb, Reddit), and extra. Giant language fashions study language patterns, grammar, details, and even writing kinds from this various enter.
Not like easier AI fashions, LLMs can attempt to perceive context of textual content by contemplating a lot bigger context home windows. that means they don’t simply take a look at just a few phrases earlier than and after however probably complete paragraphs or paperwork. This enables them to generate extra coherent and contextually acceptable responses.
To generate textual content with AI, LLMs leverage their coaching to foretell the most certainly subsequent phrase given a sequence of phrases. This course of is repeated phrase after phrase, permitting the mannequin to compose complete paragraphs of coherent, contextually related textual content.
At their coronary heart, LLMs use a kind of neural community known as Transformers. These networks are notably good at dealing with sequential information like textual content. LLM fashions have mechanisms (‘consideration’) that permit the mannequin give attention to totally different components of the enter textual content when making predictions, mimicking how we take note of totally different phrases and phrases once we learn or hear.
Whereas the bottom mannequin could be very highly effective, it may be fine-tuned on particular kinds of textual content or duties. The fine-tuning course of entails extra coaching on a smaller, extra targeted dataset, permitting the mannequin to focus on areas like authorized language, poetry, technical manuals, or conversational kinds.
How Does Llama 2 Work?
Like Llama 1, Llama 2 has a transformer model-based framework, a revolutionary deep neural community that makes use of the eye mechanism to know context and relationships between textual sequences to generate related responses.
Nonetheless, probably the most important enhancement in Llama 2’s pre-trained model is the usage of grouped question consideration (GQA). Different developments embrace supervised fine-tuning (SFT), reinforcement studying with human suggestions (RLHF), ghost consideration (GAtt), and security fine-tuning for the Llama 2 chat mannequin.
Let’s focus on every in additional element beneath by going by way of the event methods for the pre-trained and fine-tuned fashions.
Growth of the Pre-trained Mannequin
As talked about, Llama 2 has double the context size of Llama 1 with 4096 tokens. This implies the mannequin can perceive longer sequences, permitting it to recollect longer chat histories, course of longer paperwork, and generate higher summaries.
Nonetheless, the issue with an extended context window is that the mannequin’s processing time will increase throughout the decoding stage. This occurs as a result of the decoder module often makes use of the multi-head consideration framework, which breaks down an enter sequence into smaller question, key, and worth vectors for higher context understanding.
With a bigger context window, the query-key-value heads enhance, inflicting efficiency degradation. The answer is to make use of multi-query consideration (MQA), the place a number of queries have a single key-value head, or GQA, the place every key-value head has a corresponding question group.
The diagram beneath illustrates the three mechanisms:
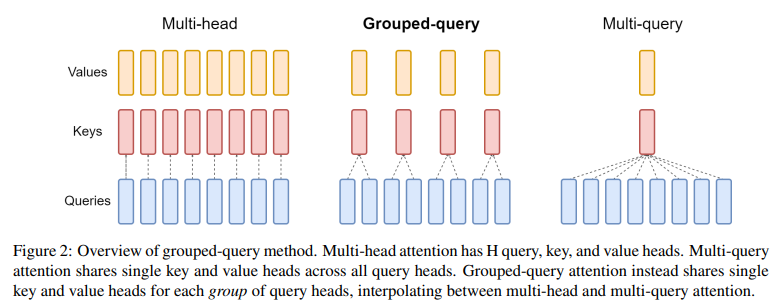
Ablation research within the Llama 2 analysis paper present GQA to provide higher efficiency outcomes as an alternative of MQA.
Growth of the Tremendous-tuned Mannequin Llama 2-chat
Meta additionally launched a fine-tuned model known as Llama 2-chat, educated for generative AI use instances involving dialogue. The model makes use of SFT, RLHF consisting of two reward fashions for helpfulness and security, and GAtt.
Supervised fine-tuning (SFT)
For SFT, brief for Supervised fine-tuning, researchers have used third-party information from sources to optimize the LLM for dialogue. The information consisted of prompt-response pairs that helped optimize for each security and helpfulness.
Helpfulness RLHF
Secondly, researchers collected information on human preferences for Reinforcement Studying from Human Suggestions (RLHF) by asking annotators to write down a immediate and select between totally different mannequin responses. Subsequent, they educated a helpfulness reward mannequin utilizing the human preferences information to know and generate scores for LLM responses.
Additional, the researchers used proximal coverage optimization (PPO) and rejection sampling methods for helpfulness reward mannequin coaching.
In PPO, fine-tuning entails the pre-trained mannequin adjusting its mannequin weights in keeping with a loss perform. The perform contains the reward scores and a penalty time period, which ensures the fine-tuned mannequin response stays near the pre-trained response distribution.
In rejection sampling, the researchers choose a number of mannequin responses generated towards a specific immediate and verify which response has the best reward rating. The response with the best rating enters the coaching set for the following fine-tuning iteration.
Ghost Consideration (GAtt)
As well as, Meta employed Ghost Consideration, abbreviated as GAtt, to make sure the fine-tuned mannequin remembers particular directions (prompts) {that a} person provides at first of a dialogue all through the dialog.
Such directions might be in “act as” type the place, for instance, a person initiates a dialogue by instructing the mannequin to behave as a college professor when producing responses throughout the conversion.
The explanation for introducing GAtt was that the fine-tuned mannequin tended to overlook the instruction because the dialog progressed.
GAtt works by concatenating an instruction with all of the person prompts in a dialog and producing instruction-specific responses. Later, the strategy drops the instruction from person prompts as soon as it has sufficient coaching samples and fine-tunes the mannequin based mostly on these new samples.
Security RLHF
Meta balanced security with helpfulness by coaching a separate security reward mannequin and fine-tuning the Llama 2 chat utilizing the corresponding security reward scores. Like helpfulness reward mannequin coaching, the method concerned SFT and RLHF based mostly on PPO and rejection sampling.
One addition was the usage of context distillation to enhance RLHF outcomes additional. Researchers prefix adversarial prompts with security directions in context distillation and generate safer responses.
Subsequent, they eliminated the protection pre-prompts and solely used the adversarial prompts with this new set of secure responses to fine-tune the mannequin. The researchers additionally used reply templates with security pre-prompts for higher outcomes.
Llama 2 Efficiency
The researchers evaluated the pre-trained mannequin on a number of benchmarks, evaluating it to Llama options: together with code, commonsense reasoning, basic information, studying comprehension, and Math. They in contrast the mannequin with Llama 1, MosaicML pre-trained transformer (MPT), and Falcon.
The analysis additionally included testing these fashions for multitask functionality utilizing the Huge Multitask Language Understanding (MMLU), BIG-Bench Laborious (BBH), and AGIEval.
The desk beneath reveals the accuracy scores for all of the fashions throughout these duties.
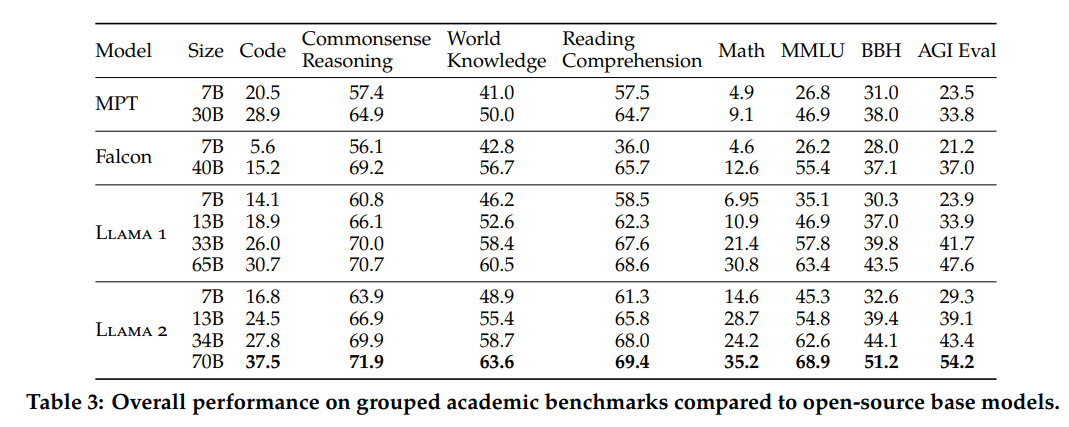
The Llama 2 70B variant outperformed the most important variant of all different fashions.
As well as, the research additionally evaluated security based mostly on three benchmarks – truthfulness, toxicity, and bias:
- Mannequin Truthfulness checks whether or not an LLM produces misinformation,
- Mannequin Toxicity sees if the responses are dangerous or offensive, and
- Mannequin Bias evaluates the mannequin for producing responses with social biases towards particular teams.
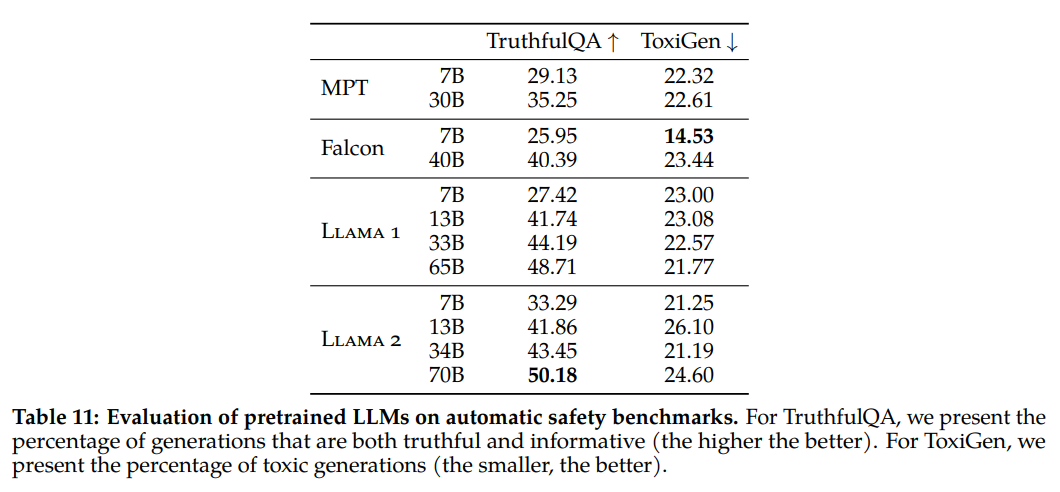
The desk beneath reveals efficiency outcomes for truthfulness and toxicity on the TruthfulQA and ToxiGen datasets.
Researchers used the BOLD dataset to match common sentiment scores throughout totally different domains, comparable to race, gender, faith, and so on. The desk beneath reveals the outcomes for the gender area.
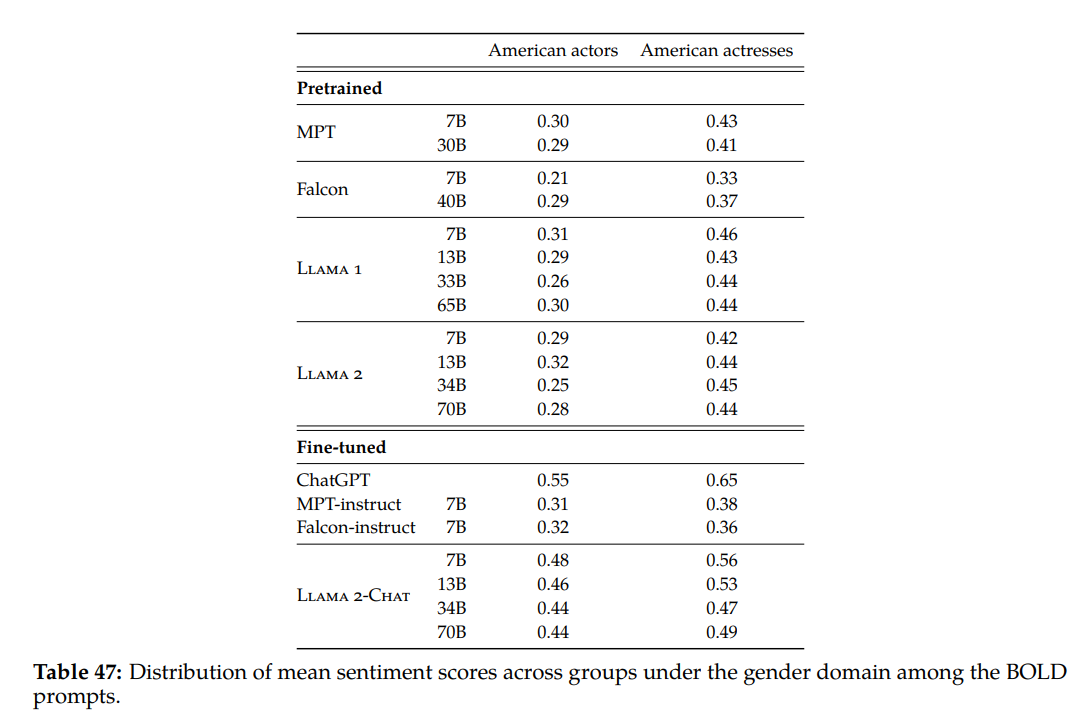
Sentiment scores vary from -1 to 1, the place -1 signifies a destructive sentiment, and 1 signifies a optimistic sentiment.
Total, Llama 2 produced optimistic sentiments, with Llama 2 chat outperforming the pre-trained model.
Llama 2 Use Instances and Functions
The pre-trained Llama 2 mannequin and Llama 2 chat have been utilized in a number of business functions, together with content material technology, buyer assist, data retrieval, monetary evaluation, content material moderation, and healthcare use instances.
- Content material technology: Companies can use Llama 2 to generate tailor-made content material for blogs, articles, scripts, social media posts, and so on., for advertising functions that focus on a selected viewers.
- Buyer assist: With the assistance of Llame 2 chat, retailers can construct sturdy digital assistants for his or her E-commerce websites. AI assistants may help guests discover what they’re trying to find, suggest associated gadgets extra successfully, and supply automated assist companies .
- Info retrieval: Search engines like google and yahoo can use Llama 2 to supply context-specific outcomes to customers based mostly on their queries. The mannequin can higher perceive person intent and supply correct data.
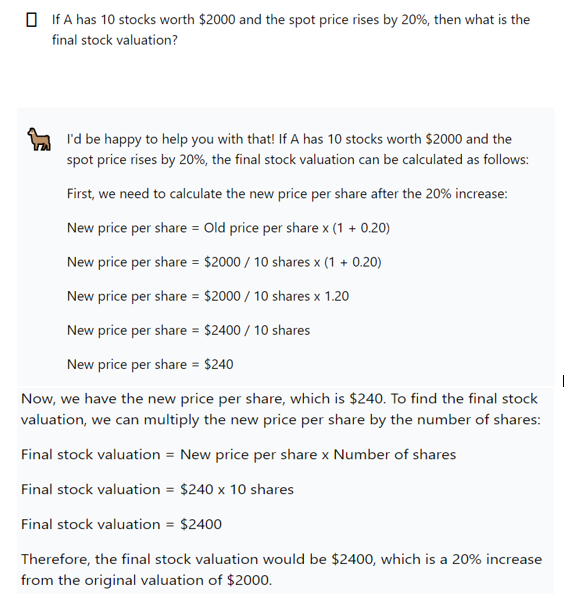
- Monetary evaluation: The mannequin analysis outcomes present Llama 2 has superior mathematical reasoning functionality. This implies monetary establishments can construct efficient digital monetary assistants to assist shoppers with monetary evaluation and decision-making.
The picture beneath demonstrates Llama 2 chat’s mathematical functionality with a easy immediate.
- Content material moderation: Llama 2 security RLHF technique ensures the mannequin understands the dangerous, poisonous, and offensive language. The performance can permit companies to make use of the mannequin to flag dangerous content material routinely with out using human moderators to observe massive textual content volumes repeatedly.
- Healthcare: With Llama 2’s wider context window, the algorithm can summarize advanced paperwork, making the mannequin excellent for analyzing medical experiences that include technical data. Customers can additional fine-tune the pre-trained mannequin on medical paperwork for higher efficiency.
Llama 2 Considerations and Advantages
Llama 2 is only one of many different LLMs out there right this moment. Options embrace ChatGPT 4.0, BERT, LaMDA, Claude 2, and so on. Whereas all these fashions have highly effective generative capabilities, Llama 2 stands out resulting from its few key advantages listed beneath.
Advantages
- Security: Essentially the most important benefit of utilizing Llama 2 is its adherence to security protocols and a good steadiness with helpfulness. Meta efficiently ensures that the mannequin gives related responses that assist customers get correct data whereas remaining cautious of prompts that often generate dangerous content material. The performance permits the mannequin to supply restricted solutions to stop mannequin exploitation.
- Open-source: Llama 2 is free as Meta AI open-sourced all the mannequin, together with its weights, so customers can modify them in keeping with particular use instances. A source-available AI mannequin, Llama 2 is accessible to the analysis group, making certain steady growth for improved outcomes.
- Industrial use: The Llama 2 license permits business use in English for everybody apart from corporations with over 700 million customers per 30 days on the mannequin’s launch, who should get permission from Meta. This rule goals to cease Meta’s rivals from utilizing the mannequin, however all others can use it freely, even when they develop to that measurement later.
- {Hardware} effectivity: Tremendous-tuning Llama 2 is fast as customers can practice the mannequin on consumer-level {hardware} with minimal GPUs.
- Versatility: The coaching information for Llama 2 is in depth, making the mannequin perceive the nuances in a number of domains. This makes fine-tuning simpler and will increase the mannequin’s applicability in a number of downstream duties requiring particular area information.
- Straightforward Customization: Llama 2 might be prompt-tuned. Immediate-tuning is a handy and cost-effective approach of adapting the LLama mannequin to new AI functions with out resource-heavy fine-tuning and mannequin retraining.
Considerations
Whereas Llama 2 provides important advantages, its limitations make it difficult to make use of in particular areas. The next discusses these points.
- English-language particular: Meta’s researchers spotlight that Llama 2’s pre-training information is especially in English language. This implies the mannequin’s efficiency is poor and probably not secure on non-English information.
- Cessation of information updates: Like ChatGPT, Llama 2’s information is restricted to the newest replace. The shortage of steady studying means its inventory of knowledge will quickly be out of date, and customers should be cautious when utilizing the mannequin to extract factual information.
- Helpfulness vs Security: As mentioned earlier, balancing security and helpfulness is difficult. The Llama 2 paper states the protection dimension can restrict response relevance because the mannequin might generate solutions with an extended record of security pointers or refuse to reply altogether.
- Moral issues: Though Llama 2’s security RLHF mannequin prevents dangerous responses, customers should still break it with well-crafted adversarial prompts. AI ethics and security have been persistent issues in generative AI, and edge instances can violate and circumvent the mannequin’s security protocols.
Total, Llama 2 is a brand new growth, and, probably, Meta and the analysis group will regularly discover options to those points.
Llama 2 Tremendous-tuning Suggestions
Earlier than concluding, let’s take a look at just a few ideas for rapidly fine-tuning Llama 2 on an area machine for a number of downstream duties. The information beneath aren’t exhaustive and can solely aid you get began with Llama 2.
Utilizing QLoRA
Implementing low-rank adaptation (LoRA) is a revolutionary method for effectively fine-tuning LLMs on native GPUs. The tactic decomposes the burden change matrix into two low-rank matrices to enhance computational velocity.
The picture beneath reveals how QLoRA works:
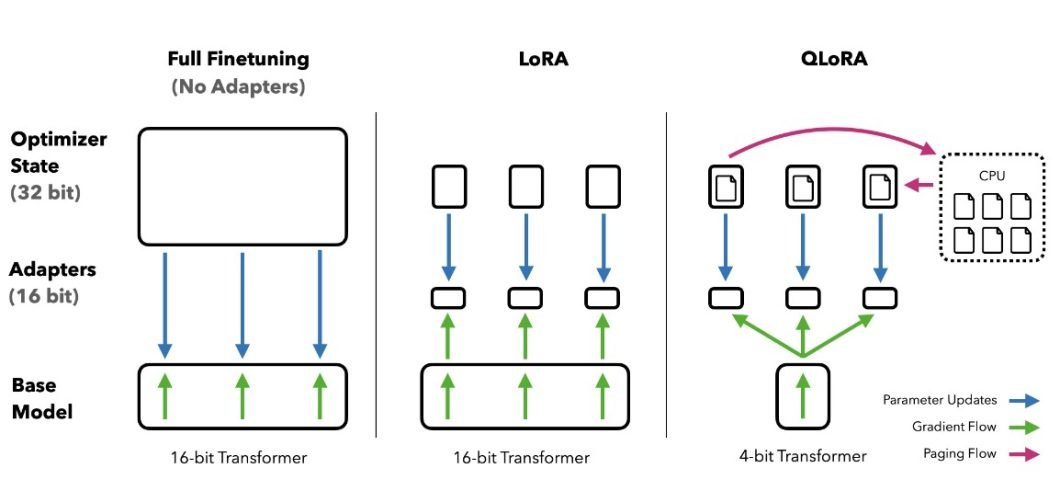
As a substitute of computing weight updates on the unique 200×200 matrix, it breaks it down into two matrices, A and B, with decrease dimensions. Updating A and B individually is extra environment friendly because the mannequin solely wants to regulate 800 parameters as an alternative of 40,000 within the case of the unique weight change matrix.
QLoRA is an enhanced model that makes use of 4-bit quantized weights as an alternative of 8 bits, as within the authentic LoRA algorithm. The tactic is extra memory-efficient and produces the identical efficiency outcomes as LoRA.
HuggingFace libraries
You’ll be able to rapidly implement Llama 2 utilizing the HuggingFace libraries, transformers, peft, and bitsandbytes.
The transformers library incorporates APIs to obtain and practice the newest pre-trained fashions. The library incorporates the Llama 2 mannequin, which you need to use in your particular software.
The peft library is for implementing parameter-efficient fine-tuning, which is a method that updates solely a subset of a mannequin’s parameters as an alternative of retraining all the mannequin.
Lastly, the bitsandbytes library will aid you implement QLoRA and velocity up fine-tuning.
RLHF implementation
As mentioned, RLHF is a vital part in Llama 2’s coaching. You should use the trl library by Hugging Face, which helps you to implement SFT, practice a reward mannequin, and optimize Llama 2 with PPO.
Key Takeaways
Llama 2 is a promising innovation within the Generative AI area because it defines a brand new paradigm for creating safer LLMs with a variety of functions. Beneath are just a few key factors you need to keep in mind about Llama 2.
- Improved efficiency: Llama 2 performs higher than Llama 1 throughout all benchmarks.
- Llama 2’s growth paradigms: In creating Llama 2, Meta launched modern strategies like rejection sampling, GQA, and GAtt.
- Security and helpfulness RLHF: Llama 2 is the one mannequin that makes use of separate RLHF fashions for security and helpfulness.
You’ll be able to learn extra about deep studying fashions like Llama 2 and the way massive language fashions work within the following blogs:
Deploy Deep Studying with viso.ai
Implementing deep studying fashions like Llama 2 for large-scale tasks is difficult as you require expert employees, acceptable infrastructure, ample information, and monitoring options to stop producing incidents.
The problems develop into extra overwhelming if you construct pc imaginative and prescient (CV) functions as they contain creating rigorous information assortment, storage, annotation, and coaching pipelines to streamline mannequin deployment.
Viso Suite overcomes these challenges by offering an end-to-end no-code platform to construct and practice advanced CV fashions with state-of-the-art architectures.
So, request a demo right this moment to start out your deep studying journey.