

Introduction
The period has arrived the place your telephone or laptop can perceive the objects of a picture, due to applied sciences like YOLO and SAM.
Meta’s Section Something Mannequin (SAM) can immediately determine objects in photos and separate them while not having to be educated on particular photos. It is like a digital magician, in a position to perceive every object in a picture with only a wave of its digital wand. After the profitable launch of llama 3.1, Meta introduced SAM 2 on July twenty ninth, a unified mannequin for real-time object segmentation in photos and movies, which has achieved state-of-the-art efficiency.
SAM 2 affords quite a few real-world functions. As an example, its outputs could be built-in with generative video fashions to create progressive video results and unlock new inventive potentialities. Moreover, SAM 2 can improve visible information annotation instruments, dashing up the event of extra superior laptop imaginative and prescient programs.
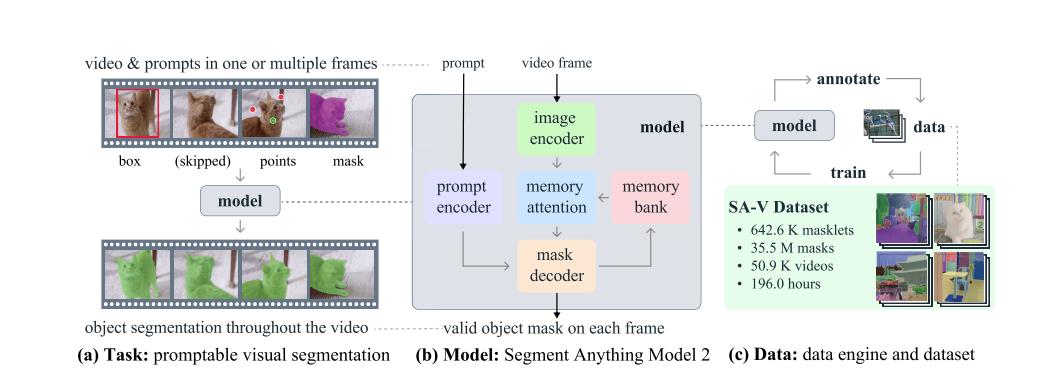
What’s Picture Segmentation in SAM?
Section Something (SAM) introduces a picture segmentation job the place a segmentation masks is generated from an enter immediate, reminiscent of a bounding field or level indicating the item of curiosity. Skilled on the SA-1B dataset, SAM helps zero-shot segmentation with versatile prompting, making it appropriate for numerous functions. Current developments have improved SAM’s high quality and effectivity. HQ-SAM enhances output high quality utilizing a Excessive-High quality output token and coaching on fine-grained masks. Efforts to extend effectivity for broader real-world use embody EfficientSAM, MobileSAM, and FastSAM. SAM’s success has led to its utility in fields like medical imaging, distant sensing, movement segmentation, and camouflaged object detection.
Dataset Used
Many datasets have been developed to help the video object segmentation (VOS) job. Early datasets characteristic high-quality annotations however are too small for coaching deep studying fashions. YouTube-VOS, the primary large-scale VOS dataset, covers 94 object classes throughout 4,000 movies. As algorithms improved and benchmark efficiency plateaued, researchers elevated the VOS job issue by specializing in occlusions, lengthy movies, excessive transformations, and each object and scene variety. Present video segmentation datasets lack the breadth wanted to ” section something in movies,” as their annotations usually cowl whole objects inside particular courses like individuals, automobiles, and animals. In distinction, the lately launched SA-V dataset focuses not solely on complete objects but in addition extensively on object elements, containing over an order of magnitude extra masks. The SA-V dataset collected contains of fifty.9K movies with 642.6K masklets.

Mannequin Structure
The mannequin extends SAM to work with each movies and pictures. SAM 2 can use level, field, and masks prompts on particular person frames to outline the spatial extent of the item to be segmented all through the video. When processing photos, the mannequin operates equally to SAM. A light-weight, promptable masks decoder takes a body’s embedding and any prompts to generate a segmentation masks. Prompts could be added iteratively to refine the masks.
Not like SAM, the body embedding utilized by the SAM 2 decoder is not taken straight from the picture encoder. As a substitute, it is conditioned on reminiscences of previous predictions and prompts from earlier frames, together with these from “future” frames relative to the present one. The reminiscence encoder creates these reminiscences based mostly on the present prediction and shops them in a reminiscence financial institution for future use. The reminiscence consideration operation makes use of the per-frame embedding from the picture encoder and situations it on the reminiscence financial institution to supply an embedding that’s handed to the masks decoder.
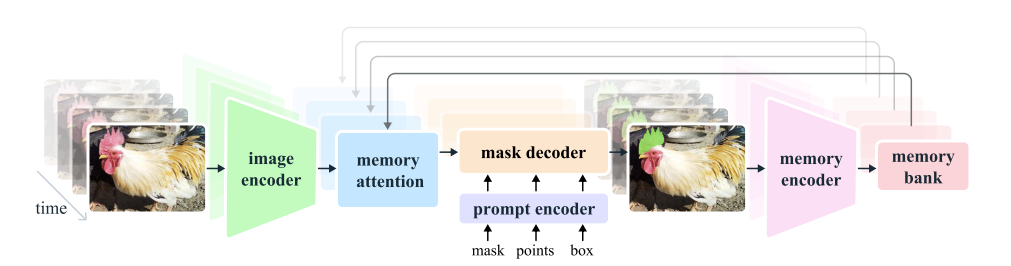
Right here’s a simplified clarification of the completely different parts and processes current within the picture:
Picture Encoder
- Function: The picture encoder processes every video body to create characteristic embeddings, that are basically condensed representations of the visible data in every body.
- How It Works: It runs solely as soon as for all the video, making it environment friendly. MAE and Hiera extracts options at completely different ranges of element to assist with correct segmentation.
Reminiscence Consideration
- Function: Reminiscence consideration helps the mannequin use data from earlier frames and any new prompts to enhance the present body’s segmentation.
- How It Works: It makes use of a sequence of transformer blocks to course of the present body’s options, evaluate them with reminiscences of previous frames, and replace the segmentation based mostly on each. This helps deal with advanced eventualities the place objects may transfer or change over time.
Immediate Encoder and Masks Decoder
- Immediate Encoder: Just like SAM’s, it takes enter prompts (like clicks or bins) to outline what a part of the body to section. It makes use of these prompts to refine the segmentation.
- Masks Decoder: It really works with the immediate encoder to generate correct masks. If a immediate is unclear, it predicts a number of attainable masks and selects one of the best one based mostly on overlap with the item.
Reminiscence Encoder and Reminiscence Financial institution
- Reminiscence Encoder: This element creates reminiscences of previous frames by summarizing and mixing data from earlier masks and the present body. This helps the mannequin keep in mind and use data from earlier within the video.
- Reminiscence Financial institution: It shops reminiscences of previous frames and prompts. This features a queue of latest frames and prompts and high-level object data. It helps the mannequin preserve observe of object modifications and actions over time.
Coaching
- Function: The mannequin is educated to deal with interactive prompting and segmentation duties utilizing each photos and movies.
- How It Works: Throughout coaching, the mannequin learns to foretell segmentation masks by interacting with sequences of frames. It receives prompts like ground-truth masks, clicks, or bounding bins to information its predictions. This helps the mannequin turn into good at responding to numerous kinds of enter and bettering its segmentation accuracy.
Total, the mannequin is designed to effectively deal with lengthy movies, keep in mind data from previous frames, and precisely section objects based mostly on interactive prompts.
SAM 2 Efficiency


SAM 2 considerably outperforms earlier strategies in interactive video segmentation, attaining superior outcomes throughout 17 zero-shot video datasets and requiring about 3 times fewer human interactions. It surpasses SAM in its zero-shot benchmark suite by being six occasions quicker and excels in established video object segmentation benchmarks like DAVIS, MOSE, LVOS, and YouTube-VOS. With real-time inference at roughly 44 frames per second, SAM 2 is 8.4 occasions quicker than guide per-frame annotation with SAM.
The way to set up SAM 2?
Deliver this undertaking to life
To begin the set up, open up a Paperspace Pocket book and begin the GPU machine of your selection.
# Clone the repo
!git clone https://github.com/facebookresearch/segment-anything-2.git
# Transfer to the folder
cd segment-anything-2
# Set up the mandatory necessities
!pip set up -e .To make use of the SAM 2 predictor and run the instance notebooks, jupyter and matplotlib are required and could be put in by:
pip set up -e ".[demo]"Obtain the checkpoints
cd checkpoints
./download_ckpts.shThe way to use SAM 2?
Picture prediction
SAM 2 can be utilized for static photos to section objects. SAM 2 affords picture prediction APIs just like SAM for these use instances. The SAM2ImagePredictor class supplies a user-friendly interface for picture prompting.
import torch
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)Video prediction
SAM 2 helps video predictor as properly on a number of objects and likewise makes use of an inference state to maintain observe of the interactions in every video.
import torch
from sam2.build_sam import build_sam2_video_predictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = build_sam2_video_predictor(model_cfg, checkpoint)
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# add new prompts and immediately get the output on the identical body
frame_idx, object_ids, masks = predictor.add_new_points(state, <your prompts>):
# propagate the prompts to get masklets all through the video
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
...Within the video we have now used SAM 2 to section the espresso mug
Abstract
- SAM 2 Overview: SAM 2 builds on SAM by extending its capabilities from photos to movies. It makes use of prompts like clicks, bounding bins, or masks to outline object boundaries in every body. A light-weight masks decoder processes these prompts and generates segmentation masks for every body.
- Video Processing: In movies, SAM 2 applies the preliminary masks prediction throughout all frames to create a masklet. It permits for iterative refinement by including prompts to subsequent frames.
- Reminiscence Mechanism: For video segmentation, SAM 2 makes use of a reminiscence encoder, reminiscence financial institution, and reminiscence consideration module. The reminiscence encoder shops body data and consumer interactions, enabling correct predictions throughout frames. The reminiscence financial institution holds information from earlier and prompted frames, which the reminiscence consideration module makes use of to refine predictions.
- Streaming Structure: SAM 2 processes frames one after the other in a streaming style, making it environment friendly for lengthy movies and real-time functions like robotics. It makes use of the reminiscence consideration module to include previous body information into present predictions.
- Dealing with Ambiguity: SAM 2 addresses ambiguity by producing a number of masks when prompts are unclear. If prompts don’t resolve the anomaly, the mannequin selects the masks with the very best confidence for additional use all through the video.
SAM 2 Limitations
- Efficiency and Enchancment: Whereas SAM 2 performs properly in segmenting objects in photos and brief movies, its efficiency could be enhanced, particularly in difficult eventualities.
- Challenges in Monitoring: SAM 2 might wrestle with drastic modifications in digital camera viewpoints, lengthy occlusions, crowded scenes, or prolonged movies. To deal with this, the mannequin is designed to be interactive, permitting customers to manually appropriate monitoring with clicks on any body to get better the goal object.
- Object Confusion: When the goal object is laid out in just one body, SAM 2 may confuse it with comparable objects. Further refinement prompts in future frames can resolve these points, guaranteeing the right masklet is maintained all through the video.
- A number of Object Segmentation: Though SAM 2 can section a number of objects concurrently, its effectivity decreases considerably as a result of every object is processed individually utilizing solely shared per-frame embeddings. Incorporating shared object-level context might enhance effectivity.
- Quick-Shifting Objects: For advanced, fast-moving objects, SAM 2 may miss advantageous particulars, resulting in unstable predictions throughout frames, as proven with the bicycle owner instance. Whereas including prompts can partially take away this, predictions should still lack temporal smoothness because the mannequin isn’t penalized for oscillation between frames.
- Information Annotation and Automation: Regardless of advances in automated masklet era utilizing SAM 2, human annotators are nonetheless wanted for verifying high quality and figuring out frames that want correction. Future enhancements might additional automate the info annotation course of to spice up effectivity.