

MobileNet was developed by a workforce of researchers at Google in 2017, who aimed to design an environment friendly Convolution Neural Community (CNN) for cell and embedded units. The mannequin they created was not solely considerably smaller in measurement and environment friendly however was additionally at par with high fashions when it comes to efficiency.
Right now, MobileNet is utilized in varied real-world purposes to carry out object detection and picture classification in facial recognition, augmented actuality, and extra.
On this weblog, we’ll look into how MobileNet was in a position to deliver down the full variety of parameters by virtually 10 occasions, and likewise look briefly at its succor fashions.
Growth of MobileNet
The motivation behind growing MobileNet arises from the rising utilization of smartphones. However, CNNs require vital computational assets and energy, whereas smartphones have restricted assets resembling processing energy, and energy supply.
Bringing real-time picture processing into these units would end in a brand new set of capabilities and functionalities. MobileNet, with the introduction of Depth-wise and Level-wise convolutions, lowered the limitation of those {hardware} assets.
Depthwise Separable Convolutions
Commonplace Convolutions
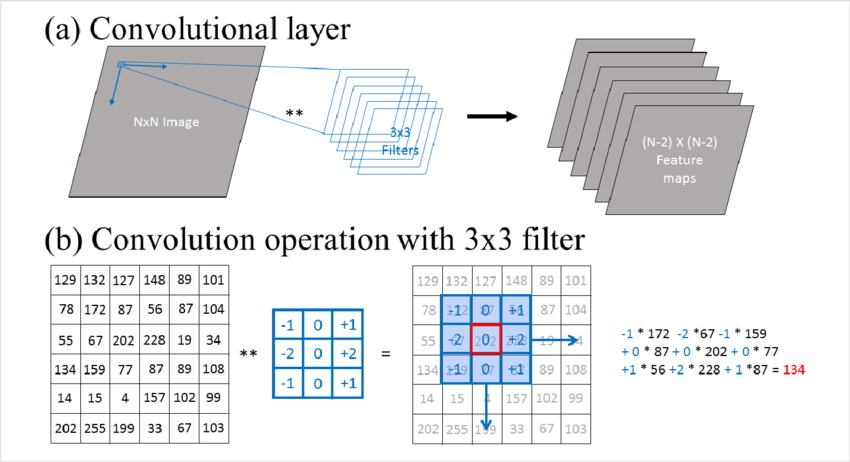
Convolution layers are the core of deep studying fashions. They extract options from a picture. Listed here are the steps concerned in a regular convolution operation:
- Defining the Filter (Kernel): A filter (additionally referred to as a kernel) is a randomly initialized small matrix, that’s used to detect options resembling edges, textures, or patterns in photos. The values of the matrix are up to date through the coaching course of by means of backpropagation.
- Sliding the Filter Throughout the Enter: The filter is slid throughout the width and top of the picture, at every step element-wise multiplication and summation operation is carried out.
- Aspect-wise Multiplication and Summation: At every place, the results of the multiplication is then summed as much as get a single quantity. This ends in the formation of a characteristic map or an activation map. The output values (i.e., the sum) point out the presence and power of the characteristic detected by the filter.
Nonetheless, this convolution operation has its limitations:
- Increased Computational Price: Because of the dense matrix multiplications (the place every filter is convolved with all of the enter channels), it’s computationally costly. For instance, in case you have an enter with 64 channels and apply 32 filters, every filter processes all 64 channels.
- Elevated Parameter Depend: The variety of parameters additionally grows considerably with a rise within the variety of enter and output channels. It is because every filter has to be taught from all of the enter channels.
This progress in parameter counts and better computational value will increase the reminiscence utilization and computation necessities to carry out all these multiplications. It is a limiting issue for deployment in smartphones and IoT units.
Depthwise convolution and Pointwise Convolution
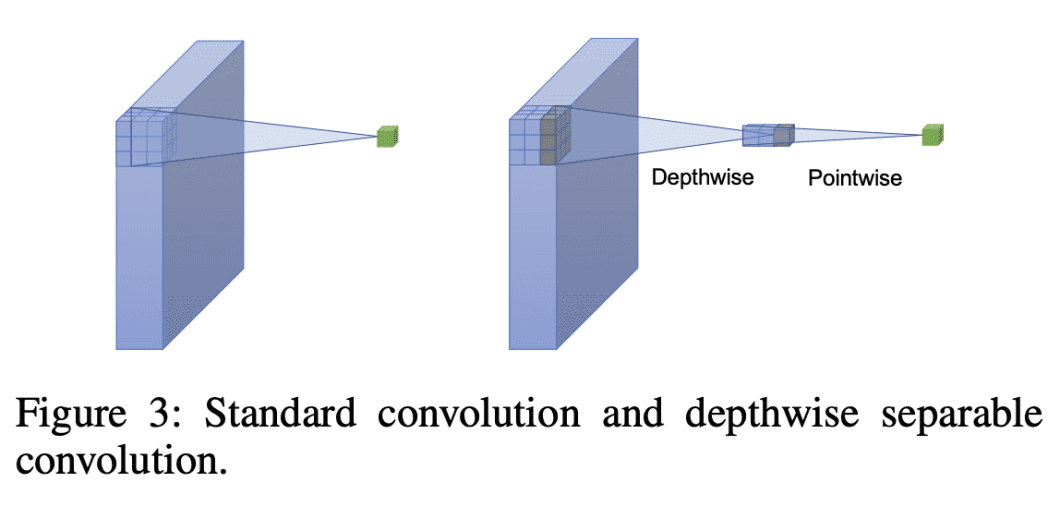
Depthwise Separable Convolution splits the usual convolution into two separate steps:
- Depthwise convolution: Applies a single filter to every enter channel.
- Pointwise convolution (1×1 convolution): Combines the outputs from the depthwise convolution to create new options.
Steps in Depthwise Convolution
- Separation of Channels: Commonplace convolution applies filters to every channel of the enter picture. Whereas depthwise convolution solely applies a single filter per enter channel.
- Filter Utility: As every filter is utilized independently, the output is the results of convolving (multiplication and summation) a single enter channel with a devoted filter.
- Output Channels: The output of the depthwise convolution has the identical variety of channels because the enter.
- Decreased Complexity: In comparison with normal convolution, the full variety of multiplicative operations is lowered.
- For normal convolution the full variety of multiplicative operations = 𝐾×𝐾×𝐶×𝐷×top×width
- For depthwise convolution, the variety of operations = 𝐾×𝐾×𝐶× top×width
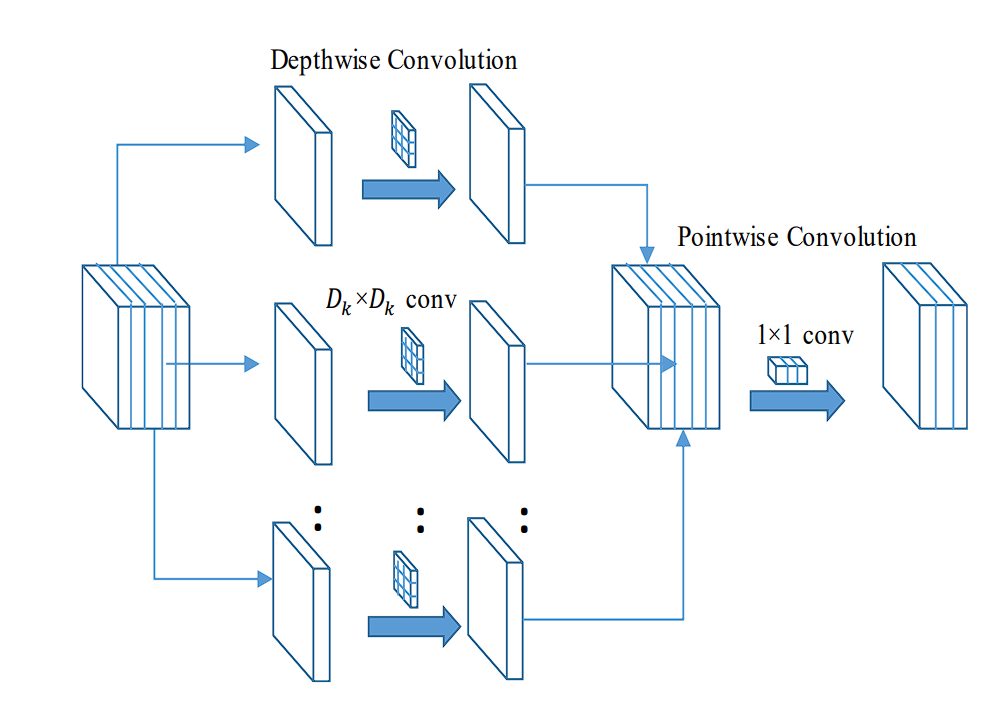
Pointwise Convolution
To mix options or increase channels, the output of depthwise convolution is utilized with pointwise convolution. It is a 1×1 filter, which is utilized to every pixel. This combines or expands the channels.
- Combining Channel Options: Depthwise convolution processes every enter channel individually, subsequently interplay between channels doesn’t occur. Pointwise convolution combines these independently processed channel options to create a brand new characteristic map. This enables the mannequin to be taught from the whole depth of characteristic maps.
- Will increase Mannequin Capability: The interactions between the channels enhance the representational capability of the community. The mannequin can be taught advanced patterns that rely upon the relationships between totally different characteristic channels.
- Adjusting the Variety of Channels: Pointwise convolution allows growing or lowering the variety of channels within the output characteristic map.
MobileNet Structure
The MobileNet structure is constructed primarily utilizing depthwise separable convolutions, with some exceptions like the primary layer which makes use of a full convolution. This enables for environment friendly characteristic extraction.
Different layers like batch normalization and ReLU are included for activation. The mannequin achieves down-sampling of the output characteristic from earlier layers with stride convolutions. On the finish of the community, we now have a mean pooling layer, then a totally related layer. The ultimate layer is a SoftMax layer for classification. In whole, MobileNet has 28 layers.
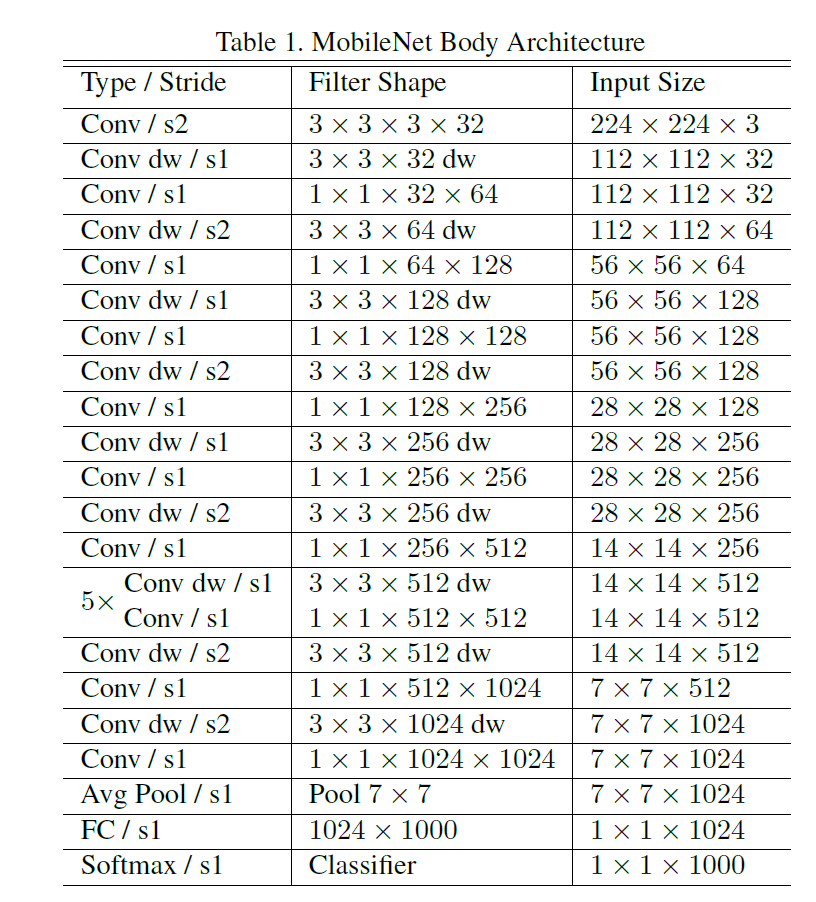
Furthermore, the mannequin closely depends on the optimized 1×1 convolutions (MobileNet spends 95% of its computation time in 1×1 convolutions which additionally has 75% of the parameters). The convolution makes use of optimized normal matrix multiply (GEMM) features for effectivity.
The mannequin is educated utilizing RMSprop and asynchronous gradient descent. Nonetheless, compared to coaching bigger fashions, MobileNet coaching makes use of much less regularization (resembling weight decay), and information augmentation as smaller fashions are much less liable to overfitting.
The mannequin is kind of small in measurement in comparison with varied different fashions, nevertheless, MobileNet additional makes use of two extra parameters to cut back mannequin measurement and computation when it’s mandatory. These parameters are:
MobileNet Variants
MobileNet V2
Launched by Google researchers in 2018, MobileNetV2 builds upon the concepts of the unique MobileNet, enhancing its structure to offer even higher effectivity and accuracy.
Key Enhancements
- Inverted Residuals: MobileNet v2 Launched inverted residual blocks with bottlenecking. These blocks use linear bottlenecks between layers to cut back the variety of channels processed, which additional improves the effectivity. It additionally added quick connections between these bottlenecks to enhance data movement. Furthermore, the final layer, which is often a non-linear activation operate (ReLU) is changed by linear activation. As the info has a low spatial dimension within the bottleneck, linear activation performs higher.
MobileNet V3
MobileNetV3 was launched in 2019 with the next key options:
- {Hardware}-Conscious NAS (Community Structure Search) for Layer-wise Optimization: This method makes use of an automatic search course of to seek out the most effective configuration design for cell {hardware}. This works by exploring totally different community architectures evaluating their efficiency on cell CPUs after which choosing essentially the most environment friendly and correct configuration.
- Squeeze-and-Excitation (SE) Modules: These modules analyze the characteristic maps produced by the convolutional layers and spotlight a very powerful options.
- Arduous Swish: That is an activation operate designed for cell processors. It presents a very good steadiness between accuracy and computational effectivity and is much less advanced in comparison with ReLU.
Different Light-weight Fashions
- SqueezeNet: SqueezeNet is an analogous mannequin identified for its small measurement, achieved through the use of 1×1 convolutions. SqueezeNet first compresses the info format after which expands it, by doing so, it removes the redundant options.
- ShuffleNet: ShuffleNet is one other mannequin designed for cell units. It makes use of pointwise group convolutions (by splitting characteristic channels into teams and making use of convolutions independently inside every group) and channel shuffle operations (this shuffles the order of channels after the group convolutions) to cut back computational prices.
Benchmarks and Efficiency
MobileNet has a major benefit in comparison with fashions with normal convolutions, because it achieves comparable excessive accuracy scores on the ImageNet dataset, however with considerably fewer parameters.
- It achieves accuracy near VGG16 whereas being considerably smaller and fewer computationally costly.
- It outperforms GoogLeNet when it comes to accuracy with a smaller measurement and decrease computational value.

MobileNet in opposition to Standard Fashions –source - MobileNet, when additional decreased in measurement utilizing width and determination multiplier hyperparameter, outperformed AlexNet and SqueezeNet with its considerably environment friendly and smaller measurement.

MobileNet Efficiency –source
Furthermore, it outperformed varied fashions that have been considerably bigger, on duties resembling:
- Effective-grained recognition (Stanford Canine dataset)
- Massive-scale geolocation (PlaNet)
- Face attribute classification (with data distillation)
- Object detection (COCO dataset)
- Face embedding (distilled MobileNet from FaceNet)
Functions of MobileNet
Covid Detection
Through the international pandemic on account of Coronavirus, researchers developed a mannequin utilizing MobileNet to precisely classify chest X-ray photos into three classes: regular, COVID-19, and viral pneumonia, with an accuracy of 99%.
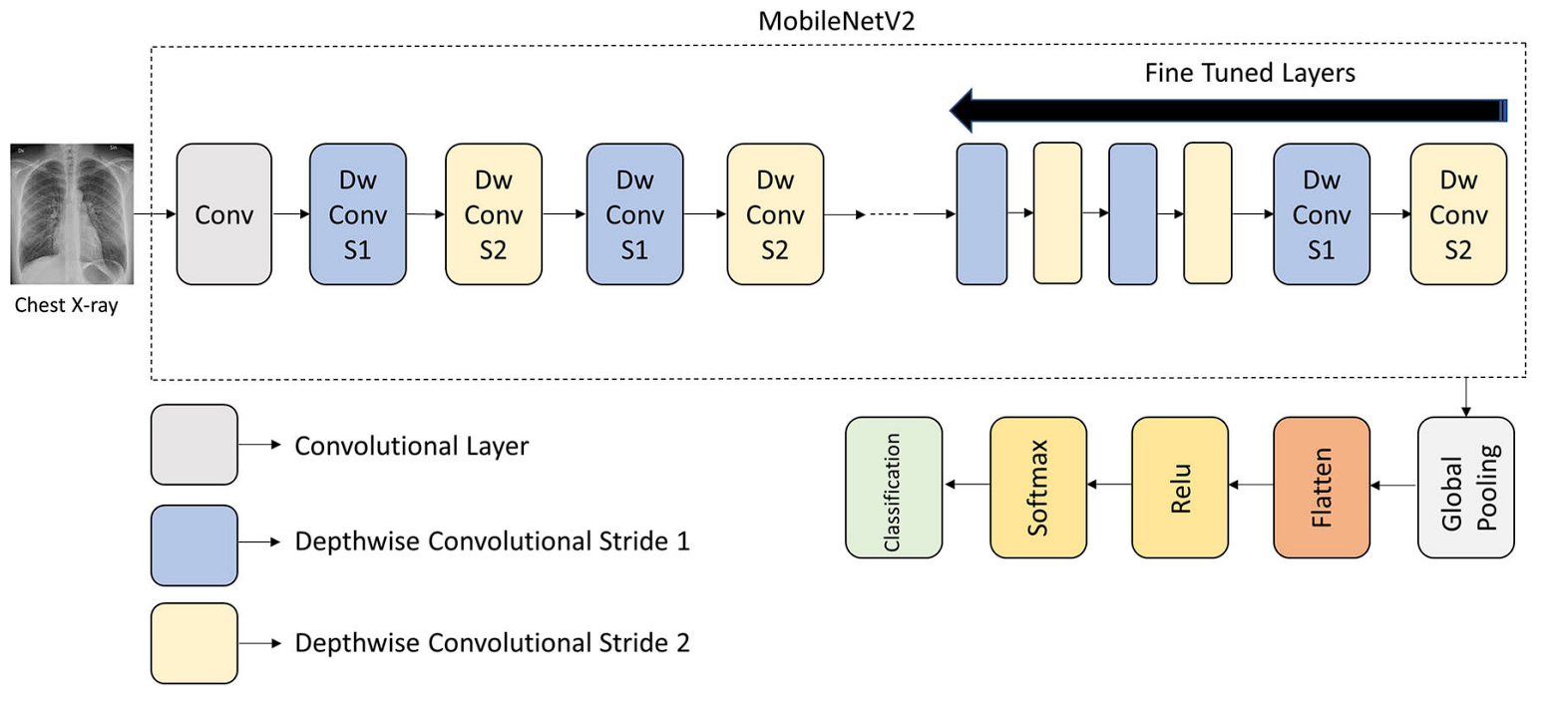
Fish Detection
Freshwater fish farming is a worthwhile enterprise that gives a supply of revenue for over 60 million individuals, and precisely figuring out fish species is essential for the enterprise. Researchers used MobileNet V1 to coach a mannequin to categorise freshwater fish from photos. MobileNet was chosen as a result of it could possibly be run on the smartphone units of the farmers. The ensuing mannequin achieved an accuracy price of 90% in distinguishing between various kinds of fish.
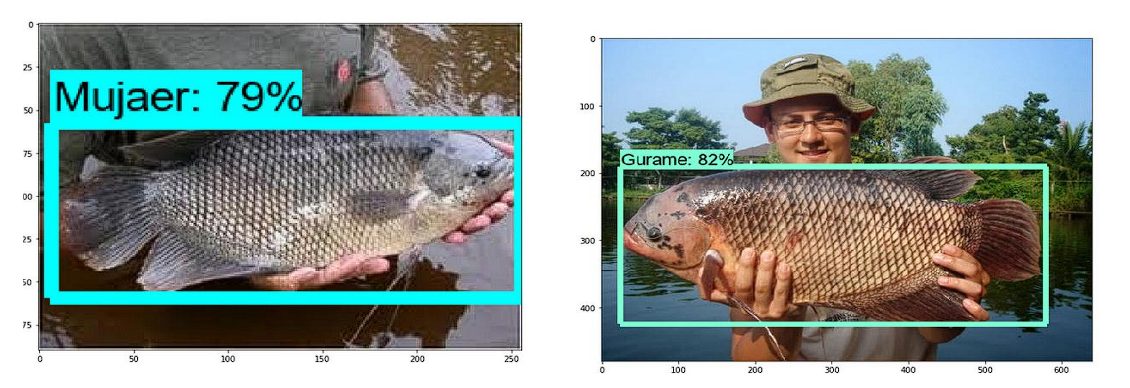
Pores and skin Most cancers
Cell purposes for detecting pores and skin most cancers have gotten widespread. All of them ship the info to a server, and that server returns the end result. Nonetheless, this will’t be utilized in areas with poor Web connectivity. In consequence, researchers educated the MobileNet v2 mannequin to detect and classify two kinds of pores and skin most cancers (Actinic Keratosis and Melanoma) in photos utilizing an Android system. The mannequin achieved 90% accuracy, taking round 20 seconds.
Leaf Illness
For a worthwhile tomato crop yield, early and correct detection of tomato leaf illnesses is essential. Different CNN-based networks are giant and require devoted gear. Researchers developed a cell software that makes use of a MobileNet mannequin to acknowledge 10 widespread tomato leaf illnesses utilizing a smartphone, attaining an accuracy of 90%.

Welding Defects
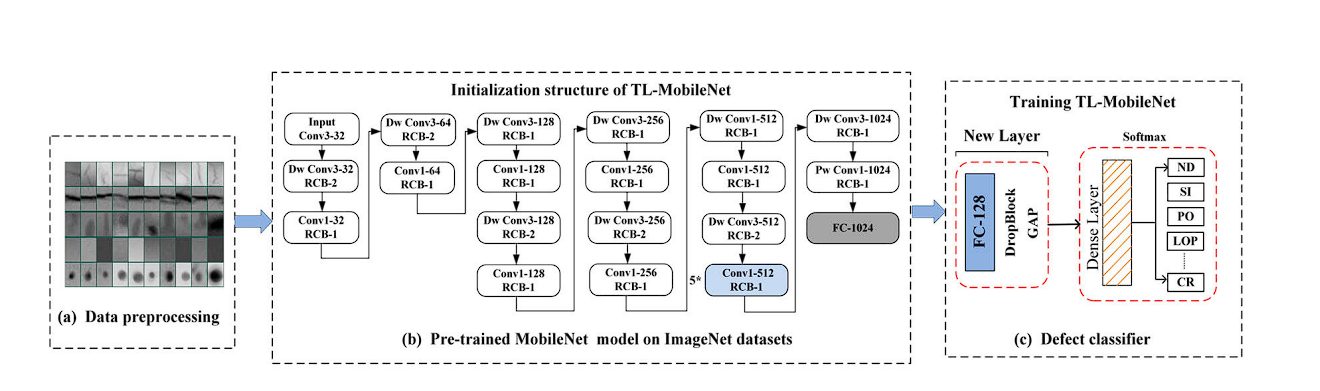
Welding defects can have an effect on the standard and security of welded buildings and can lead to accidents that may be life-threatening. X-ray imaging is used for inspecting welds for defects. Deep Studying fashions will be educated to detect defects, nevertheless, they require a big dataset. Researchers utilized switch studying, which makes use of a pre-trained MobileNet mannequin as a characteristic extractor, after which fine-tuned on welding defect X-ray photos. The Switch Studying-MobileNet mannequin achieves a excessive classification accuracy of 97%, the efficiency is in comparison with different strategies resembling Xception, VGG-16, VGG-19, and ResNet-50, however with fewer assets.
Masks on face
Resulting from COVID-19, carrying masks in public was made obligatory in 2020, to stop the unfold of the virus. Researchers educated the MobileNet mannequin on roughly 9,000 photos. The ensuing mannequin achieved an accuracy of 87.96% for detecting if a masks is worn and 93.5% for detecting if it’s worn accurately.
Conclusion
On this article, we checked out MobileNet, a extremely environment friendly Neural Community mannequin for cell and embedded units launched by Google. It achieves its outstanding effectivity utilizing depthwise separable convolution. Furthermore, the mannequin’s measurement will be additional lowered through the use of width and determination multiplier hyperparameters. With these developments, MobileNet has made real-time picture processing capabilities on cell units natively potential.
In consequence, a number of cell purposes have been developed that may use the MobileNet mannequin for picture classification and object detection.