

The which means of modality is outlined as “a selected mode during which one thing exists or is skilled or expressed.” In synthetic intelligence, we use this time period to speak concerning the kind(s) of enter and output knowledge an AI system can interpret. In human phrases, modality’s which means refers back to the senses of contact, style, scent, sight, and listening to. Nonetheless, AI methods can combine with quite a lot of sensors and output mechanisms to work together by an extra array of information sorts.

Understanding Modality
Every kind presents distinctive insights that improve the AI’s potential to know and work together with its environments.
Kinds of Modalities:
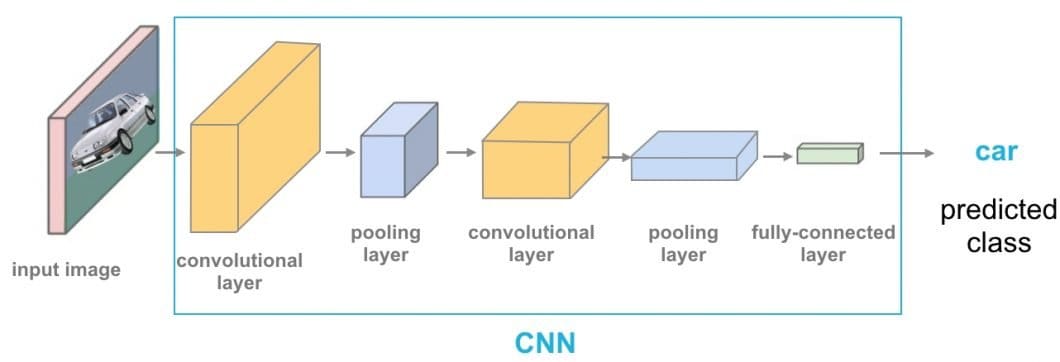
- Visible: Fashions reminiscent of Convolutional Neural Networks (CNNs) allow the processing of visible knowledge for duties like picture recognition and video evaluation. For example, Google’s DeepMind leverages pc imaginative and prescient applied sciences for correct predictions of protein buildings.
- Sound: This refers back to the potential to course of auditory knowledge. Sometimes, AI methods use fashions like Recurrent Neural Networks (RNNs) to interpret sound waves. The commonest functions in the present day are for voice recognition and ambient sound detection. For instance, voice assistants (e.g., Siri, Alexa) use auditory modalities to course of consumer instructions.
- Textual: These modalities need to do with understanding and producing human texts. These methods typically leverage giant language fashions (LLM) and pure language processing (NLP) in addition to Transformer-based architectures. Chatbots, translation instruments, and generative AIs, like ChatGPT, depend on these phrase modalities.
- Tactile: This pertains to touch-based sensory modalities for haptic applied sciences. A poignant instance in the present day is robots that may carry out delicate duties, reminiscent of dealing with fragile objects.
Initially, AI methods had been targeted closely on singular modalities. Early fashions, like perceptrons laid the groundwork for visible modality within the Nineteen Fifties, for instance. NLP was one other main breakthrough for quite a lot of modalities in AI methods. Whereas its apparent utility is in human-readable textual content, it additionally led to pc imaginative and prescient fashions, reminiscent of LeNet, for handwriting recognition. NLPs nonetheless underpin the interactions between people and most generative AI instruments.
The introduction of RNNs and CNNs within the late twentieth century was a watershed second for auditory and visible modalities. One other leap ahead occurred with the disclosing of Transformer architectures, like GPT and BERT, in 2017. These notably enhanced the power to know and generate language.
At present, the main target is shifting towards multi-modal AI methods that may work together with the world in multifaceted methods.
Multi-Modal Programs in AI
Multi-modal AI is the pure evolution of methods that may interpret and work together with the world. These methods mix multimodal knowledge, reminiscent of textual content, photos, sound, and video, to type extra subtle fashions of the atmosphere. In flip, this enables for extra nuanced interpretations of, and responses to, the surface world.
Whereas incorporating particular person modalities might assist AIs excel specifically duties, a multi-model method drastically expands the horizon of capabilities.
Breakthrough Fashions and Applied sciences
Meta AI is likely one of the entities on the forefront of multi-modal AI analysis. It’s within the technique of growing fashions that may perceive and generate content material throughout completely different modalities. One of many staff’s breakthroughs is the Omnivore mannequin, which acknowledges photos, movies, and 3D knowledge utilizing the identical parameters.
The staff additionally developed its FLAVA undertaking to supply a foundational mannequin for multimodal duties. It may possibly carry out over 35 duties, from picture and textual content recognition to joint text-image duties. For instance, in a single immediate, FLAVA can describe a picture, clarify its which means, and reply particular questions. It additionally has spectacular zero-shot capabilities to categorise and retrieve textual content and picture content material.
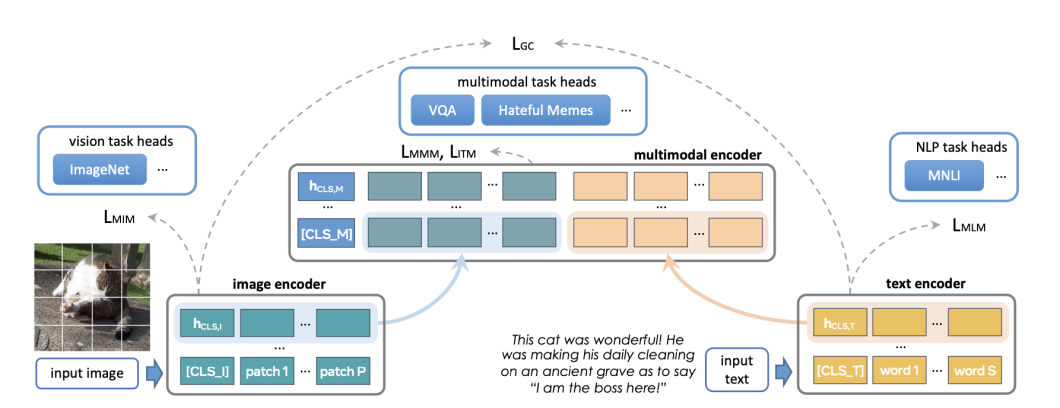
Data2vec, one other Meta initiative, proves that “very same mannequin structure and self-supervised coaching process can be utilized to develop state-of-the-art fashions for recognition of photos, speech, and textual content.” In easy phrases, it helps the truth that implementing a number of modalities doesn’t necessitate excessive developmental overhead.
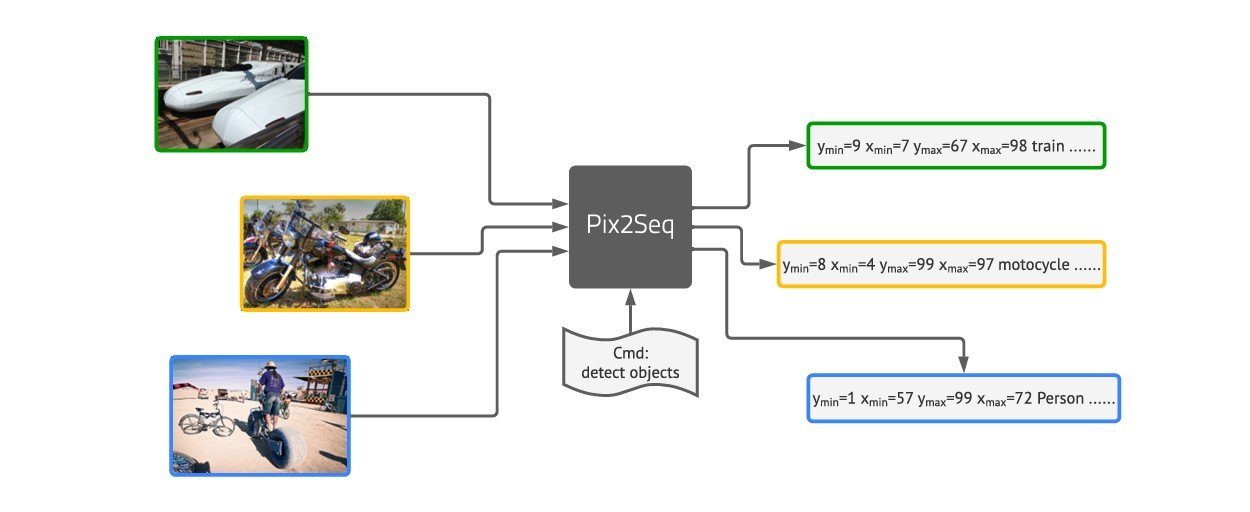
Google has additionally contributed considerably to the sector with fashions like Pix2Seq. This mannequin takes a singular method by fixing seemingly unimodal duties utilizing a multi-modal structure. For instance, it treats object detection as a language modeling activity by tokenizing visible inputs. MaxViT, a imaginative and prescient transformer, ensures that native and non-local info is mixed effectively.
On the know-how entrance, NVIDIA has been instrumental in pushing multi-modal AI innovation. The NVIDIA L40S GPU is a common knowledge heart GPU designed to speed up AI workloads. This contains numerous modalities, together with Giant Language Mannequin (LLM) inference, coaching, graphics, and video functions. It could nonetheless show pivotal in growing the subsequent technology of AI for audio, speech, 2D, video, and 3D.
Powered by NVIDIA L40S GPUs, the ThinkSystem SR675 V3 represents {hardware} able to subtle multi-modal AI. For instance, the creation of digital twins and immersive metaverse simulations.
Actual-Life Purposes
The functions of multi-modal AI methods are huge, and we’re solely originally. For instance, autonomous automobiles require a mixture of visible, auditory, and textual modalities to reply to human instructions and navigate. In healthcare, multi-modal diagnostics incorporate imaging, experiences, and affected person knowledge to supply extra exact diagnoses. Multi-modal AI assistants can perceive and reply to completely different inputs like voice instructions and visible cues.
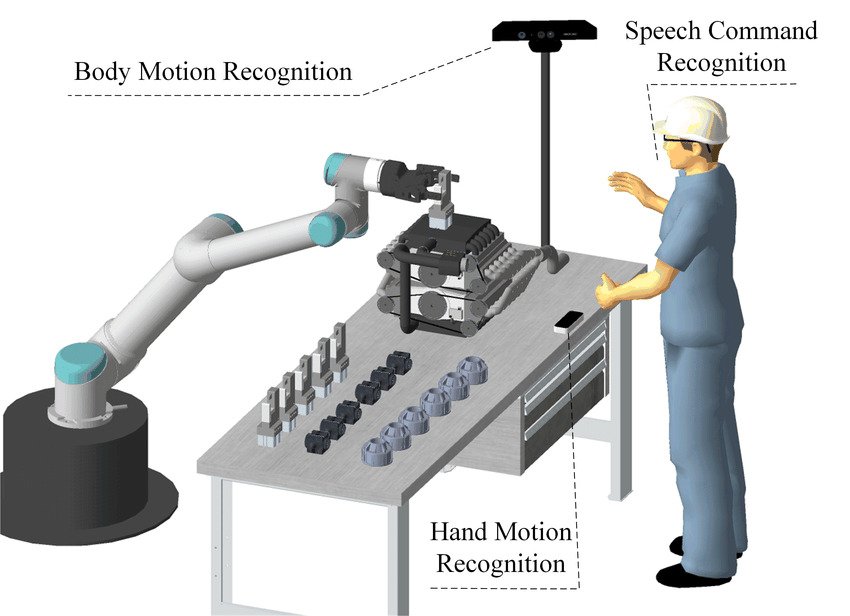
And, on the very forefront, we’re seeing superior new robotics methods utilizing muti-modal capabilities. In a latest demo, Determine 01 demonstrated the power to mix human language inputs with a visible interpretation. This allowed it to carry out typical human duties in a kitchen, primarily based on verbal directions. We’re seeing comparable developments with different rivals, reminiscent of Tesla’s Optimus.
Technological Frameworks and Fashions Supporting Multi-Modal AI
The success of multi-modal methods necessitates the combination of varied advanced neural community architectures. Most use circumstances for multi-modal AIs require an in-depth understanding of each the content material and context of the info it’s fed. To complicate issues additional, they have to have the ability to effectively course of modalities from a number of sources concurrently.
This raises the query of learn how to greatest combine disparate knowledge sorts whereas balancing the necessity to improve relevance and reduce noise. Even coaching AI methods on a number of modalities on the identical time can result in points like co-learning. The affect of this may vary from easy interference to catastrophic forgetting.
Nonetheless, due to the sector’s fast evolution, superior frameworks and fashions that tackle these shortcomings emerge on a regular basis. Some are designed particularly to assist harmoniously synthesize the data from completely different knowledge sorts. PyTorch’s TorchMultimodal library is one instance such instance. It offers researchers and builders with the constructing blocks and end-to-end examples for state-of-the-art multi-modal fashions.
Notable fashions embrace BERT, which presents a deep understanding of textual content material, and CNNs for picture recognition. Torch multimodal permits the mix of those highly effective unimodal fashions right into a multi-modal system.
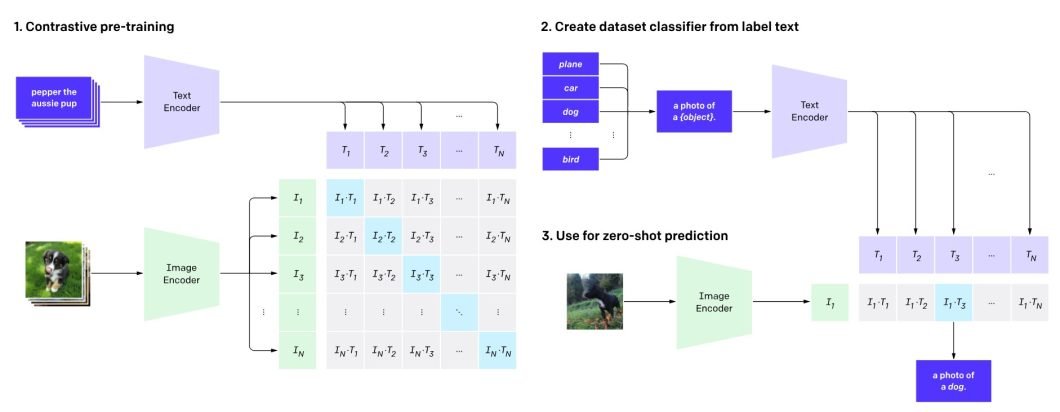
This has additionally led to revolutionary breakthroughs. For instance, the event of CLIP has modified the way in which pc imaginative and prescient methods be taught textual and AI representations. OR, Multimodal GPT, which extends OpenAI’s GPT structure to deal with multi-modal technology.
Challenges to Growing Multi-Modal AI Programs
There are a number of challenges in terms of integrating completely different knowledge sorts right into a single AI mannequin:
- Illustration: That is the problem of encoding completely different knowledge sorts in a means that makes it attainable to course of them uniformly. Joint representations mix knowledge into a standard “house”, whereas coordinated representations hold them separated however structurally linked. It’s troublesome to combine completely different modalities resulting from variances in noise, lacking knowledge, construction, and codecs.
- Translation: Some functions might require wholly changing knowledge from one kind to a different. The precise course of can differ primarily based on the modality of each knowledge sorts and the applying. Typically, the translated knowledge nonetheless requires extra analysis by both a human or utilizing metrics like BLUE and ROUGE.
- Alignment: In lots of use circumstances, modalities additionally have to be synchronized. For instance, audio and visible inputs might have to be aligned in accordance with particular timestamps or visible/auditory queues. Extra disparate knowledge sorts might not naturally align resulting from inherent structural variations.
- Fusion: When you’ve solved illustration, you continue to must merge the modalities to carry out advanced duties, like making selections or predictions. That is typically difficult resulting from their completely different charges of generalization and ranging noise ranges.
- Co-learning: As touched on earlier, poor co-learning can negatively affect the coaching of each modalities. Nonetheless, when accomplished proper, it might probably enhance the power to switch information between them for mutual profit. It’s largely difficult for a similar causes as illustration and fusion.
Discovering options to those challenges is a steady space of growth. A few of the model-agnostic approaches, like these developed by Meta, supply probably the most promising path ahead.
Moreover, deep studying fashions showcase the power to mechanically be taught representations from giant multi-modal knowledge units. This has the potential to additional enhance accuracy and effectivity, particularly the place the info is very various. The addition of neural networks additionally helps resolve challenges associated to the complexity and dimensionality of multi-modal knowledge.
Influence of Modality on AI and Pc Imaginative and prescient
Developments in multi-modal predict a future the place AI and pc imaginative and prescient seamlessly combine into our every day lives. As they mature, they may turn into more and more essential parts of superior AR and VR, robotics, and IoT.

In robotics, AR exhibits promise in providing strategies to simplify programming and enhance management. Particularly, Augmented Actuality Visualization Programs enhance advanced decision-making by combining real-world physicality with AR’s immersive capabilities. Combining imaginative and prescient, eye monitoring, haptics, and sound makes interplay extra immersive.
For instance, ABB Robotics makes use of it in its AR methods to overlay modeled options into real-life environments. Amongst different issues, it permits customers to create superior simulations in its RobotStudio software program earlier than deploying options. PTC Actuality Lab’s Kinetic AR undertaking is researching utilizing multi-modal fashions for robotic movement planning and programming.
In IoT, Multimodal Interplay Programs (MIS) merge real-world contexts with immersive AR content material. This opens up new avenues for consumer interplay. Developments in networking and computational energy enable for real-time, pure, and user-friendly interfaces.