

The idea of picture segmentation has fashioned the idea of assorted trendy Laptop Imaginative and prescient (CV) purposes. Segmentation fashions assist computer systems perceive the varied parts and objects in a visible reference body, equivalent to a picture or a video. Varied sorts of segmentation methods exist, equivalent to panoptic or semantic segmentation. Every of those fashions has totally different working ideas and purposes.
On account of the rising purposes and the introduction of latest use instances at times, the picture segmentation area has stretched skinny. With a plethora of fashions to select from, it turns into a problem for builders engaged on sensible implementations.
OMG-Seg (2024) introduces a single segmentation mannequin able to dealing with varied duties. This text will talk about:
- Varieties Of Picture Segmentation Duties
- Widespread Fashions for Picture Segmentation
- Structure of OMG-Seg
- Outcomes and Benchmarks evaluating OMG-Seg to in style fashions
About us: Viso.ai gives a sturdy end-to-end no-code laptop imaginative and prescient answer – Viso Suite. Our software program allows ML groups to coach deep studying and machine studying fashions and deploy them in laptop imaginative and prescient purposes – utterly end-to-end. Get a demo.
Understanding Segmentation
Earlier than we dive into the intricacies of OMG-Seg, we’ll temporary recap on the subject of picture segmentation. For extra particulars, try our Picture Segmentation Utilizing Deep Studying article.
Picture segmentation fashions divide (or phase) an enter picture into varied objects inside that body. It does so by recognizing the varied entities current and producing a pixel masks to map the boundary and placement of every.
Picture segmentation works equally to object detection however with a distinct strategy to creating annotations. Whereas object detection attracts an oblong boundary to point whether or not the detected object is current, segmentation labels pixels belonging to totally different classes, forming an correct masks.

The granularity of picture segmentation makes it helpful for varied sensible purposes equivalent to autonomous automobiles, medical picture processing, and segmenting satellite tv for pc photographs.
Nevertheless, the picture segmentation area consists of assorted classes. Every of those classes processes the picture in a different way and produces several types of class labels. Let’s look into these classes intimately.
Kinds of Segmentation Fashions
There are numerous segmentation fashions that carry out duties together with picture segmentation, prompt-based segmentation, and video segmentation.
Picture Segmentation
Picture segmentation methods embody panoptic, semantic, and occasion segmentation.
Semantic Segmentation: Classifies every pixel in a picture right into a class. Semantic segmentations duties create a masks for each entity current in your entire picture. Nevertheless, its main shortcoming is that it doesn’t differentiate between the varied occurrences of the identical object. For instance, the cubes within the instance beneath are all highlighted purple, and there’s no info within the annotations to distinguish between their occurrences.

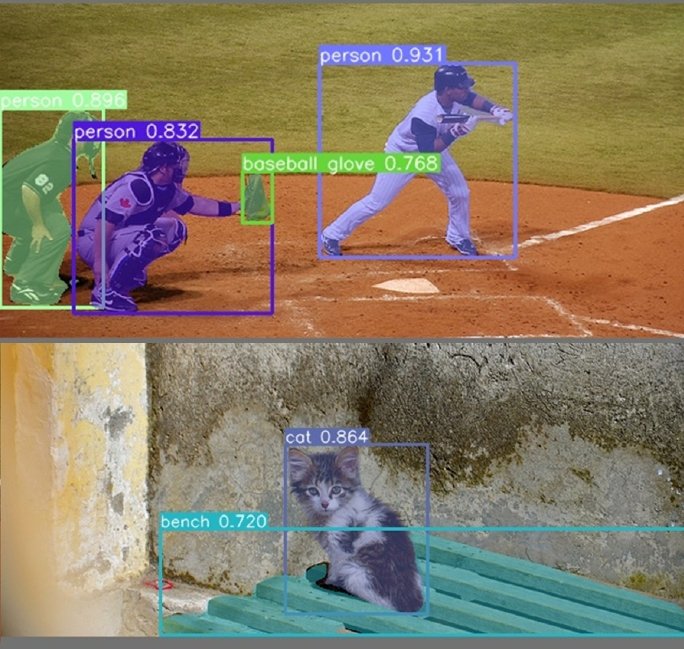
Occasion Segmentation: Addresses the semantic segmentation drawback. On high of making pixel-level masks, it additionally generates labels to establish the cases of an object. It does so by combining object detection and semantic segmentation. The previous identifies the varied objects of curiosity, whereas the latter constructs pixel-perfect labels.
Occasion segmentation is nice for understanding countable visible parts equivalent to cups or cubes however leaves out parts within the backdrop. These embody the sky, the horizon, or a long-running street. These objects don’t precisely have varied cases (or we are saying they can’t be counted), however are an integral a part of the visible canvas.
Panoptic Segmentation: Combines semantic and occasion segmentation to supply particulars about each entity in a picture. It processes the picture to creates instance-level labels for every object in focus and masks for background objects equivalent to buildings, the sky, or bushes.

Immediate-Based mostly Segmentation
Furthermore, trendy picture segmentation fashions are developed to deal with real-life eventualities encompassing a number of seen and unseen objects. One such improvement is prompt-based segmentation.
Immediate-based Segmentation combines the facility of pure language processing (NLP) and laptop imaginative and prescient to create a picture segmentation mannequin. This mannequin makes use of textual content and visible prompts to know, detect, and classify objects inside a picture.
Luddecke and Ecker display the capabilities of utilizing such prompts to categorise beforehand unseen objects. The mannequin can perceive the item in query utilizing the prompts offered. The textual content and visible prompts can be utilized in conjunction or independently to show the mannequin what must be segmented.
Video Segmentation
Most sensible use instances of picture segmentation make use of it to real-time video feeds moderately than single photographs. It treats a video as a bunch of photographs, applies segmentation to every, and teams collectively every masked body to type a segmented video. Video segmentation is helpful for self-driving automobiles and visitors surveillance purposes.
Fashionable video segmentation algorithms enhance their outcomes by using body pixels and causal info. These algorithms mix info from the current body and context from earlier frames to foretell a segmentation masks. Different methods for video segmentation embody interactive segmentation.
This method makes use of consumer enter in an preliminary body to localize the item. It then continues to generate segmentation masks in subsequent frames utilizing the preliminary info.
Widespread Picture Segmentation Fashions
Masks-RCNN
The Masks Area-based Convolutional Neural Community (RCNN) was probably the most in style segmentation algorithms throughout Laptop Imaginative and prescient’s early days. It improved upon its predecessor, Sooner RCNN, by outputting pixel-level masks moderately than bounding containers for detecting objects.
Its structure consists of a CNN spine (characteristic extractor) constructed from different in style networks like VGG or Resnet. Additional, it makes use of a region-proposal community to slender the search window for object areas. Lastly, it incorporates separate branches for object classification, detection, and masks formation for segmentation.
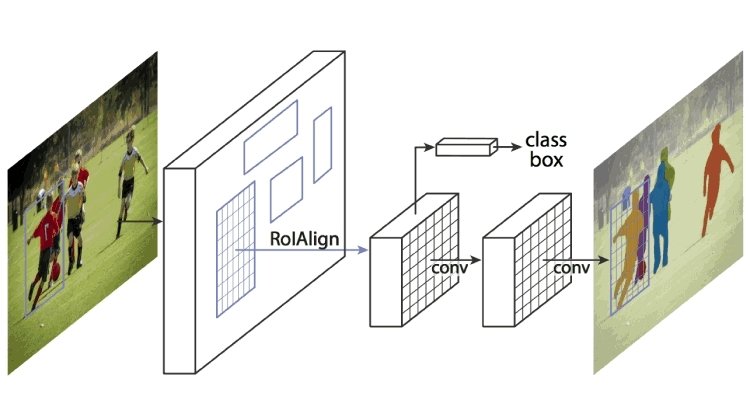
The mannequin achieved state-of-the-art outcomes on in style datasets equivalent to COCO and Pascal VOC.
UNET
The U-Web structure is in style for semantic segmentation of Biomedical picture information. Its structure consists of a descending layer and an ascending layer. The descending layer is answerable for characteristic extraction and object detection through convolution and pooling layer.
The opposite reconstructs the options through deconvolution whereas producing masks for the detected object. The layers even have skip connections that join their subsequent elements to go info.
The ultimate output is a characteristic map consisting of segmentations of objects of curiosity.
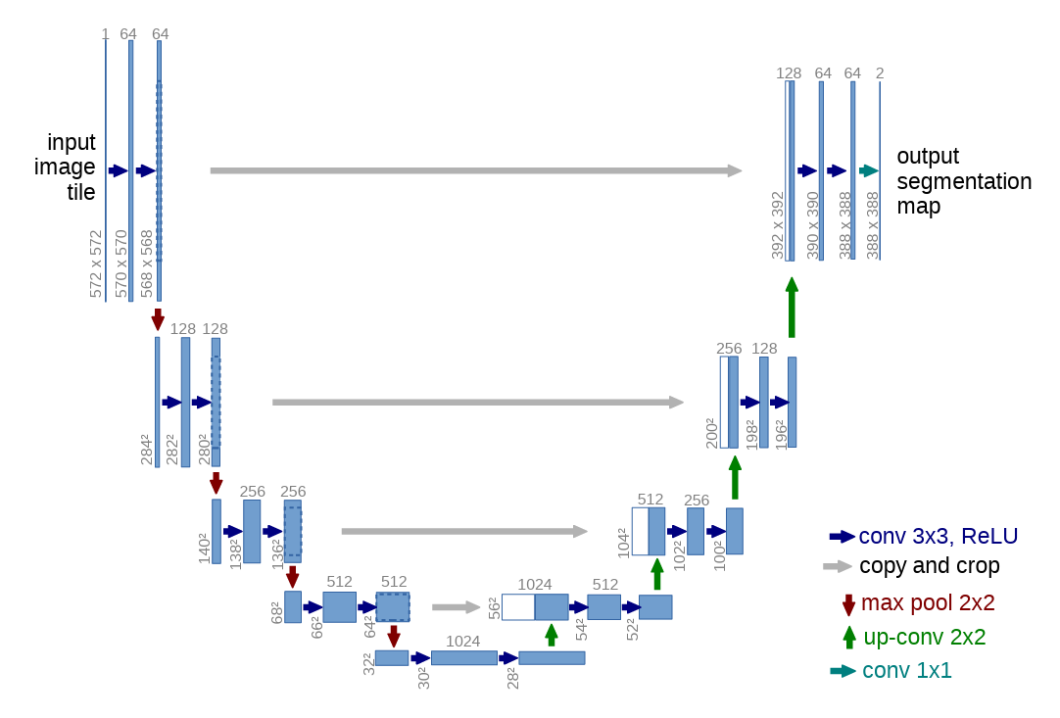
Through the years, the structure has advanced to supply UNet ++ and Consideration UNet.
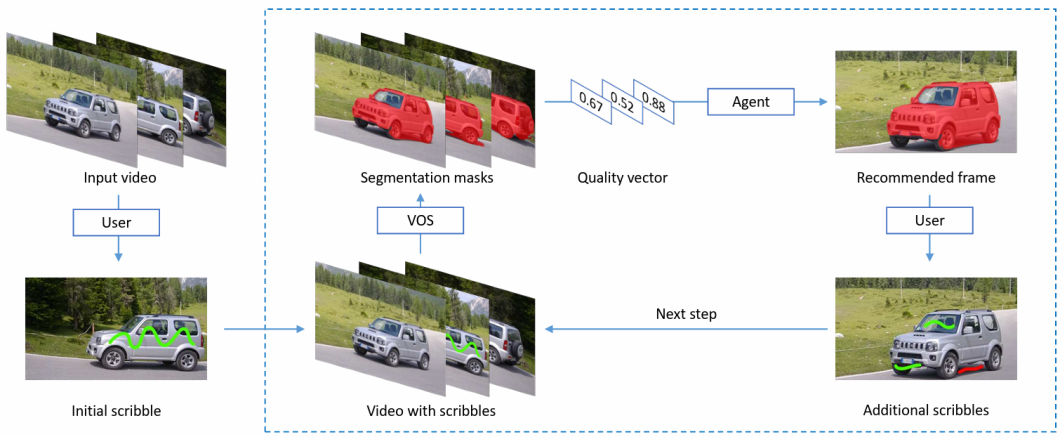
Phase Something Mannequin (SAM)
Phase Something Mannequin (SAM) is the proper instance of what trendy laptop imaginative and prescient appears to be like like. That is an open-source picture segmentation mannequin developed by Meta and is skilled on 11 Million photographs and over a billion masks.
SAM gives an interactive interface the place customers can merely click on on the objects they wish to phase or omit of the segmentation. Furthermore, it permits zero-shot generalization to phase photographs with a single enter and a immediate. The immediate may be descriptive textual content, a tough bounding field, a masks, or just some coordinates on the item to be segmented.
-

Phase Something Mannequin demo instance
SAM’s structure consists of a picture encoder, a immediate encoder, and a masks decoder. The mannequin is pre-trained on the SA-1B dataset, permitting it to generalize on new lessons with out re-training.
OMG-Seg: Unified Picture Segmentation
To this point, all of the methodologies and architectures we’ve mentioned have been task-specific, i.e., plain picture segmentation, video segmentation, immediate segmentation, and so on. Every of those fashions has state-of-the-art outcomes on their respective duties, however it’s difficult to deploy a number of fashions due to {hardware} prices and restricted sources.

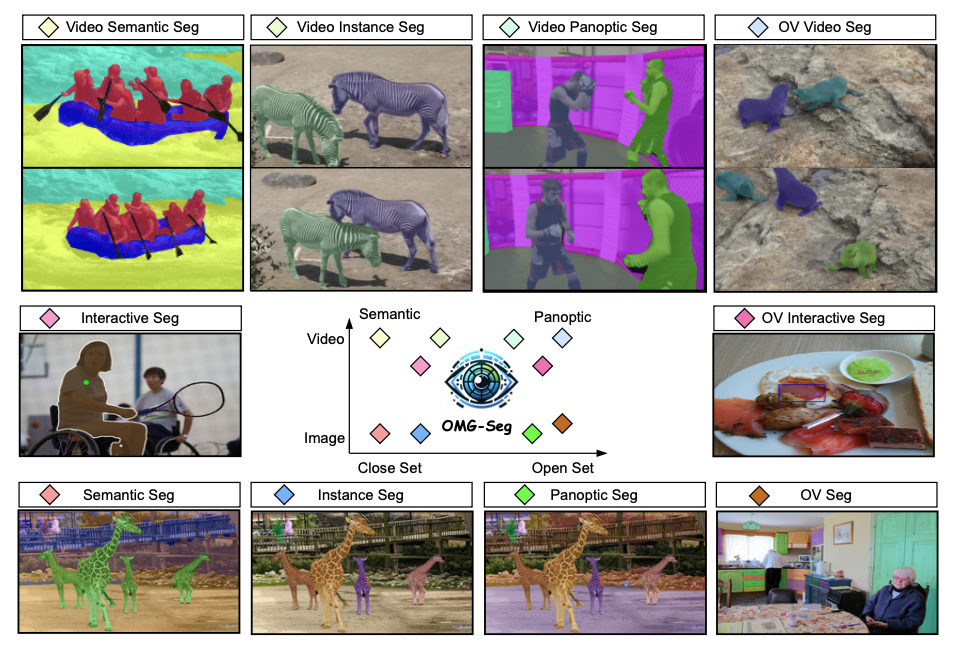
To unravel this, Li et al. (2024) have launched OMG-seg, an all-in-one segmentation mannequin that may carry out varied segmentation duties. The mannequin is a transformer-based encoder-decoder structure that helps over ten distinct duties, together with semantic, occasion, and panoptic segmentation and their video counterparts. It might additionally deal with prompt-driven duties, interactive segmentation, and open-vocabulary settings for simple generalization.
The segmentation lessons included within the framework are as follows:
- Semantic
- Occasion
- Panoptic
- Interactive
- Video Semantic
- Video Occasion
- Video Panoptic
- Open-Vocabulary
- Open-Vocabulary Interactive
- Open-Vocabulary Video
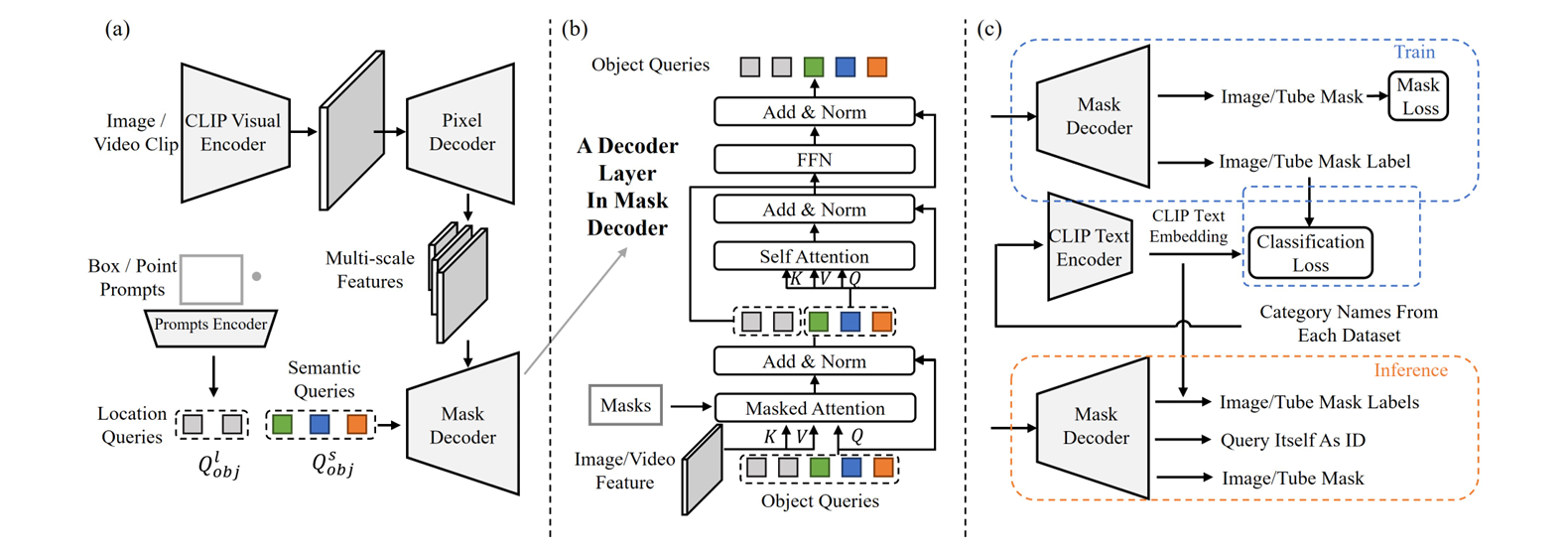
OMG-Seg Structure
OMG-Seg follows an analogous structure to Mask2Former, together with a spine, a pixel decoder, and a masks decoder. Nevertheless, it contains sure alterations to help the totally different duties. This general structure consists of:
- VLM Encoder as a Spine: OMG-Seg replaces the unique spine with the frozen CLIP mannequin as a characteristic extractor. This Imaginative and prescient-Language Mannequin (VLM) extracts multi-scale frozen options and allows open-vocabulary recognition.
- Pixel Decoder as Function Adapter: The decoder consists of multi-layer deformable consideration layers. It transforms the frozen options into fused options.
- Mixed Object Queries: Every object question generates masks outputs for various duties. For photographs, the item question focuses on object localization and recognition, whereas for movies, it additionally considers temporal options. For interactive segmentation, OMG-Seg makes use of the immediate encoder to encode the varied visible prompts into the identical form as object queries.
- Shared Multi-task Decoder: The ultimate masks decoder takes within the fused options from the pixel decoder and the mixed object queries to supply the segmentation masks. The layer makes use of a multi-head self-attention for picture segmentation and combines pyramid options for video segmentation.
Coaching and Benchmarks
The mannequin is skilled for all segmentation duties concurrently. It makes use of a joint image-video dataset and a single entity label and masks for the several types of segmentations current. Additional, it replaces the classifier with the CLIP textual content embeddings to keep away from cross-dataset taxonomy conflicts.
OMG-Seg explores co-training on varied datasets, together with COCO panoptic, COCO-SAM, and Youtube-VIS-2019. Every helps develop totally different duties, equivalent to panoptic segmentation and open vocabulary settings.
The coaching was performed in a distributed coaching setting utilizing 32 A100 GPUs. Every mini-batch included one picture per GPU, and large-scale jitter was launched for augmentation.
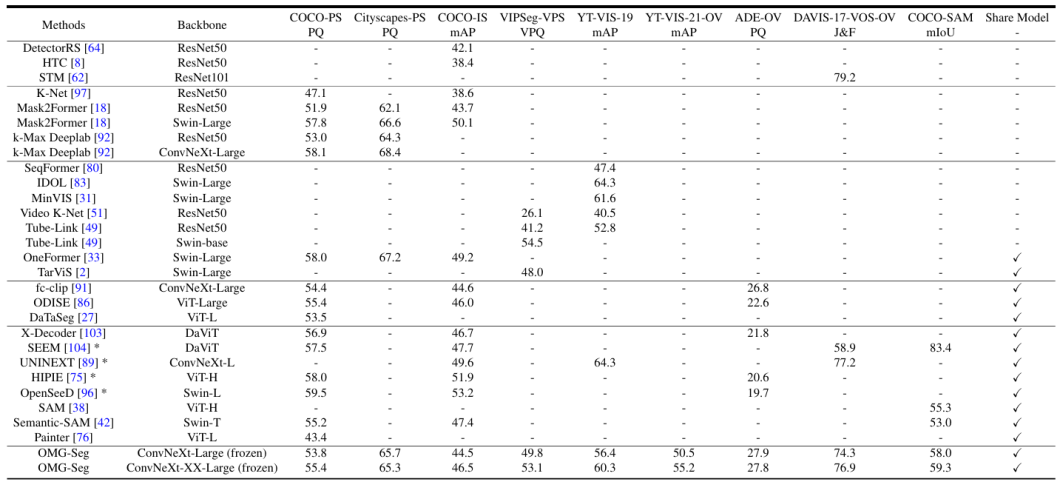
The above desk has two attention-grabbing takeaways.
- It showcases the big selection of datasets (therefore duties) OMG-Seg can work with.
- Its efficiency in opposition to every activity is kind of corresponding to, if not higher than, the competitor fashions.
OMG-Seg: Key Takeaways
The picture segmentation area covers varied duties, together with occasion, semantic, panoptic, video, and prompt-based segmentation. Every of those duties is carried out by totally different fashions on totally different datasets.

OMG-Seg introduces a unified mannequin for a number of segmentation duties. Right here’s what we discovered about it:
- Having totally different fashions introduces sensible limitations throughout software integration.
- OMG-Seg performs over ten segmentation duties from a single mannequin.
- The duties embody Occasion, Semantic, Panoptic Segmentation, and their video counterparts. It additionally works on open-vocabulary settings and interactive segmentation.
- Most of its structure follows that of the Mask2Former mannequin.
- The mannequin shows comparable efficiency in opposition to in style fashions equivalent to SAM and Mask2Former on datasets like COCO and CityScapes.
Fashionable machine studying has come a great distance. Listed here are a couple of subjects the place you possibly can be taught extra about Laptop Imaginative and prescient:
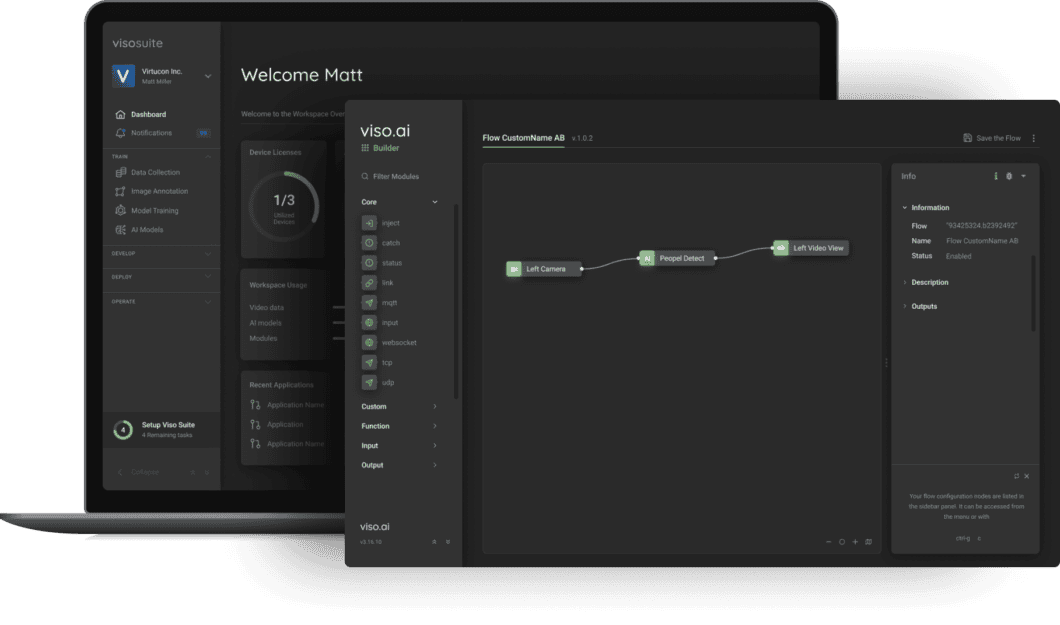
Develop Segmentation Purposes with Viso
Picture segmentation is utilized in industries together with automotive, healthcare, and manufacturing. Implementing a segmentation mannequin requires dealing with large-scale datasets, growing advanced fashions, and deploying sturdy inference pipelines.
Viso.ai gives a no-code end-to-end platform for creating and deploying laptop imaginative and prescient purposes. We provide an unlimited library of vision-related fashions with purposes throughout varied industries. We additionally provide information administration and annotation options for customized coaching.
Ebook a demo to be taught extra concerning the Viso Suite.