

The sphere of picture era strikes shortly. Although the diffusion fashions utilized by widespread instruments like Midjourney and Secure Diffusion might appear to be the very best we’ve received, the following factor is at all times coming — and OpenAI might need hit on it with “consistency fashions,” which might already do easy duties an order of magnitude quicker than the likes of DALL-E.
The paper was put online as a preprint last month, and was not accompanied by the understated fanfare OpenAI reserves for its main releases. That’s no shock: that is undoubtedly only a analysis paper, and it’s very technical. However the outcomes of this early and experimental approach are fascinating sufficient to notice.
Consistency fashions aren’t significantly simple to elucidate, however make extra sense in distinction to diffusion fashions.
In diffusion, a mannequin learns tips on how to progressively subtract noise from a beginning picture made totally of noise, shifting it nearer step-by-step to the goal immediate. This strategy has enabled at this time’s most spectacular AI imagery, however essentially it depends on performing anyplace from ten to 1000’s of steps to get good outcomes. Meaning it’s costly to function and likewise sluggish sufficient that real-time functions are impractical.
The purpose with consistency fashions was to make one thing that received first rate leads to a single computation step, or at most two. To do that, the mannequin is skilled, like a diffusion mannequin, to watch the picture destruction course of, however learns to take a picture at any stage of obscuration (i.e. with slightly info lacking or so much) and generate an entire supply picture in only one step.
However I hasten so as to add that that is solely essentially the most hand-wavy description of what’s occurring. It’s this sort of paper:
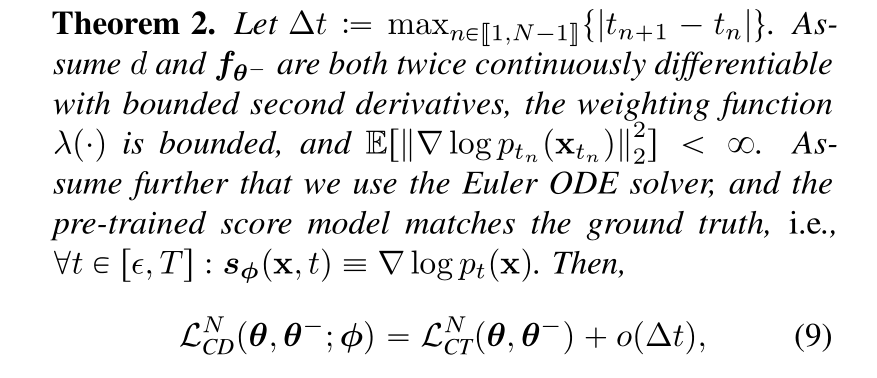
A consultant excerpt from the consistency paper.
The ensuing imagery shouldn’t be mind-blowing — most of the photos can hardly even be referred to as good. However what issues is that they had been generated in a single step slightly than 100 or a thousand. Moreover, the consistency mannequin generalizes to various duties like colorizing, upscaling, sketch interpretation, infilling, and so forth, additionally with a single step (although regularly improved by a second).

Whether or not the picture is generally noise or largely knowledge, consistency fashions go straight to a closing end result.
This issues, first, as a result of the sample in machine studying analysis is usually that somebody establishes a way, another person finds a strategy to make it work higher, then others tune it over time whereas including computation to supply drastically higher outcomes than you began with. That’s roughly how we ended up with each fashionable diffusion fashions and ChatGPT. It is a self-limiting course of as a result of virtually you’ll be able to solely dedicate a lot computation to a given activity.
What occurs subsequent, although, is a brand new, extra environment friendly approach is recognized that may do what the earlier mannequin did, manner worse at first but additionally far more effectively. Consistency fashions display this, although it’s nonetheless early sufficient that they’ll’t be straight in comparison with diffusion ones.
But it surely issues at one other stage as a result of it signifies how OpenAI, simply essentially the most influential AI analysis outfit on the planet proper now, is actively trying previous diffusion on the next-generation use instances.
Sure, if you wish to do 1500 iterations over a minute or two utilizing a cluster of GPUs, you may get gorgeous outcomes from diffusion fashions. However what if you wish to run a picture generator on somebody’s cellphone with out draining their battery, or present ultra-quick leads to, say, a reside chat interface? Diffusion is just the fallacious device for the job, and OpenAI’s researchers are actively looking for the proper one — together with Ilya Sutskever, a well-known identify within the subject, to not downplay the contributions of the opposite authors, Yang Music, Prafulla Dhariwal, and Mark Chen.
Whether or not consistency fashions are the following large step for OpenAI or simply one other arrow in its quiver — the long run is sort of definitely each multimodal and multi-model — will rely upon how the analysis performs out. I’ve requested for extra particulars and can replace this put up if I hear again from the researchers.