

Sora is a text-to-video synthetic intelligence mannequin developed by OpenAI that may create lifelike and imaginative scenes from textual content directions. OpenAI considers Sora as a path in direction of making a simulator for the bodily and digital world.
This weblog publish will discover Sora, diving into the way it works and its potential purposes. We’ll additionally study its capabilities for video technology and the dangers related to its use.
About us: Viso Suite is the end-to-end enterprise-grade laptop imaginative and prescient answer. By gaining management over the whole machine studying pipeline with Viso Suite, ML groups have been capable of scale back software time-to-value from 3 months to three days. Study extra by reserving a demo with the Viso staff.
What Can You Do With Sora?
Aside from text-to-video technology, Sora may also do a number of different duties. Right here is the checklist of issues you are able to do utilizing Sora.
- Textual content-to-Video: Utilizing Sora you possibly can create movies by merely giving it directions.
- Generate video in any format: From 1920 x 1080 to 1080 x 1920 and every thing in between.
- Picture Animation: Sora can animate a picture, you simply have to offer a picture to it, and it’ll create a video of it
- Extending Movies: Sora can lengthen movies, both ahead or backward in time.
- Video Modifying: Sora can remodel and alter the kinds and environments of enter movies in response to the textual content prompts supplied.
- Picture Technology: Sora is able to producing photographs.
- Simulate digital worlds and video games: Minecraft and different video video games.
Distinctive Capabilities of Sora
OpenAI of their revealed paper has admitted that Sora and different video fashions when educated at scale confirmed attention-grabbing capabilities, a few of these are:
- Real looking 3D Worlds: Sora creates movies with easy digicam motion, sustaining constant depth and object positions regardless of modifications in perspective.
- Lengthy Movies with Reminiscence: Not like some video turbines, Sora can maintain monitor of objects and characters all through a video, even when they disappear for some time. It could additionally present the identical character a number of instances with a constant look.
- Easy Interactions: Sora can simulate fundamental interactions like portray leaving marks or a personality consuming one thing that modifications their look.
- Simulating Video games: Sora may even be used to manage characters in easy video video games like Minecraft, producing the sport world and the character’s actions concurrently.
How Does OpenAI’s Sora Work?
Sora makes use of diffusion transformer structure to generate movies. Because the title suggests, Sora is a diffusion mannequin mixed with a transformer (extra on this beneath).
Furthermore, on the core, Sora does one thing completely different, it makes use of visible patches as tokens, impressed by LLMs like ChatGPT (GPT makes use of phrases as tokens).
What are Visible Patches?
Video knowledge is made from frames, subsequently, Sora treats them as a group of frames. Then every body is decomposed into a bunch of pixels. Here’s what Sora does in a different way, it treats the pixels not simply as extraordinary pixels, however as a 3D construction, capturing temporal (time) data of pixels.

Sora Structure
To grasp the function of visible patches, we have to have a look at the structure of Sora, which is as follows:
- Compression: Sora takes uncooked video as enter, after which compresses it right into a latent illustration that shops data relating to spatial (the situation of pixels) and temporal (the relation of pixels with time).
- House Time Patches: The compressed latent illustration is then transformed into house time patches after which used as tokens for the transformer, much like LLMs.
- Diffusion: The house time patches are full of noise after which undergo a diffusion course of the place they’re denoised.

Diffusion by Sora – source - Decoding: As soon as the diffusion course of is accomplished on the latent illustration, they’re transformed again to video format.
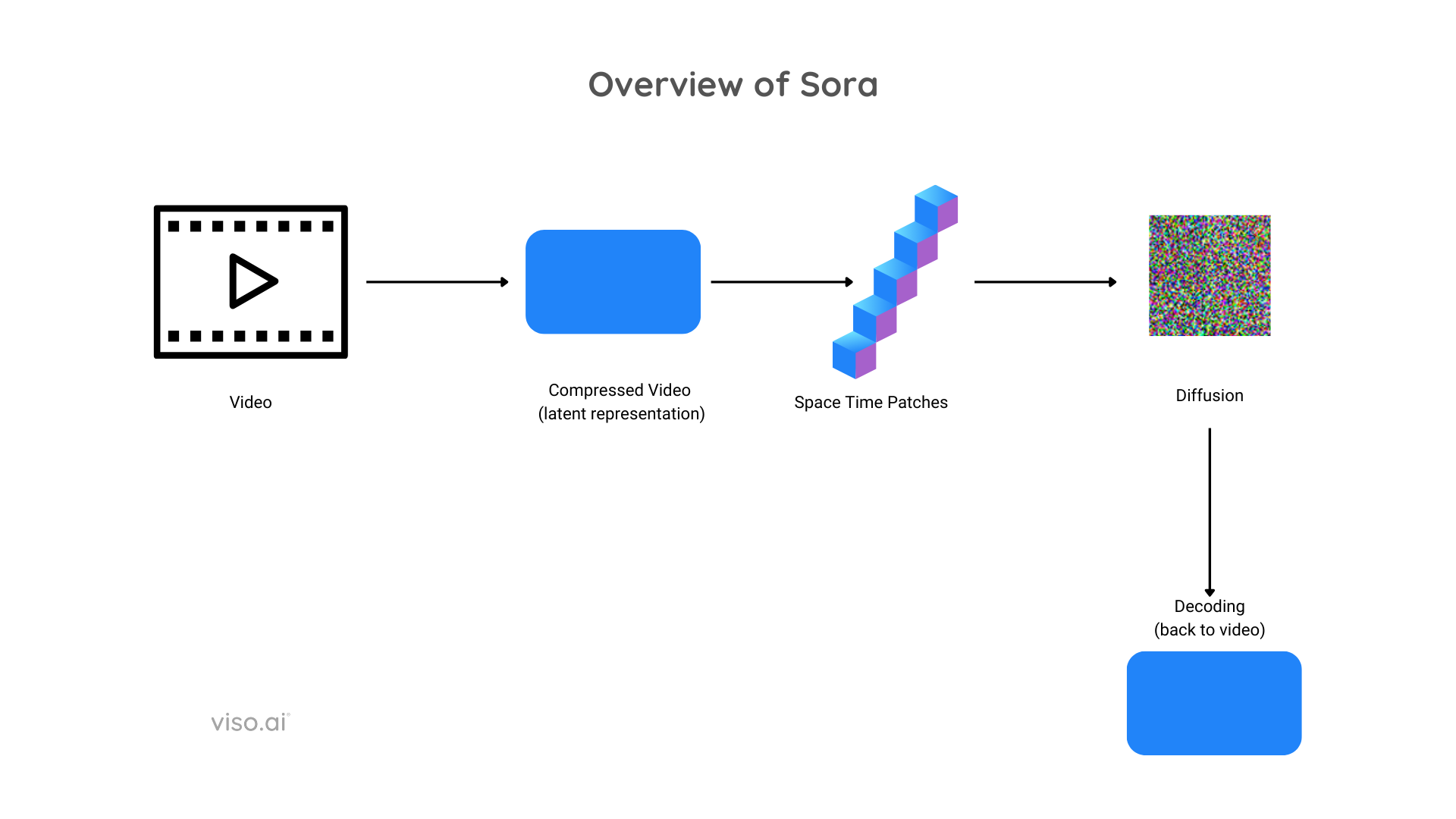
Sora Structure
Why Compress Movies?
Sora compresses the video right into a latent illustration for:
- Effectivity: Working with movies in compressed type is cheaper (fewer sources are utilized) and sooner.
- Effectiveness: Latent illustration house helps the mannequin take note of what issues. As a substitute of each pixel of the picture, the mannequin processes equal illustration however is considerably smaller in measurement.
What’s a Transformer?
Transformer is a deep studying mannequin that makes use of a mechanism referred to as “self-attention” to course of sequential enter knowledge. It could course of the whole enter knowledge directly, capturing context and relevance.
What’s Consideration Mechanism?
In transformers the “consideration mechanism” permits the mannequin to give attention to completely different elements of the enter knowledge at completely different instances and to contemplate the context of every piece of information relative to the remainder of the weather within the sequence.
To grasp higher, we will have a look at the distinction between CNNs and Transformers. CNNs course of an space by giving equal significance to every aspect, whereas in transformers, the eye mechanism permits it to course of components with various significance, leading to it specializing in what’s essential and what’s not.
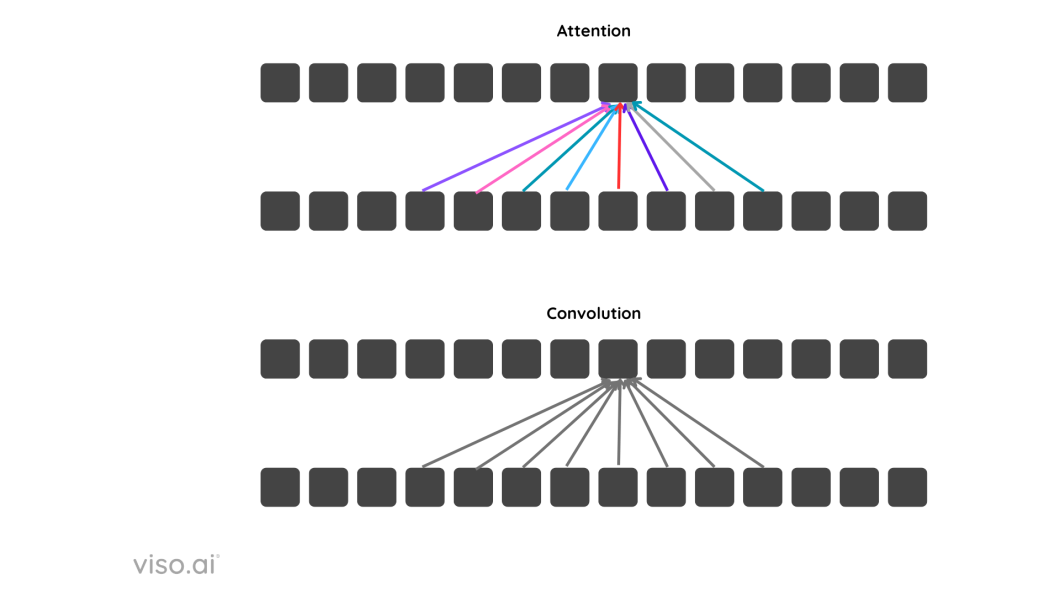
Within the diagram above, the coloured arrows in consideration denote completely different weights assigned.
To grasp this higher, allow us to have a look at how ChatGPT makes use of the eye mechanism.
For instance, think about these two sentences, “The bat flew out of the cave at nightfall to hunt bugs” and “He swung the bat exhausting, hoping to hit a house run”. The phrase “bat” right here has a distinct that means based mostly on the context for the remainder of the phrases within the sentence. ChatGPT tries to determine this context out.
Equally, Sora makes use of space-time patches as tokens for the eye mechanism for:
- Body-Stage Understanding: Perceive what’s happening on the body degree.
- Body-Sequence: To grasp the relationships between the completely different frames.
That is what allows Sora to generate movies with complicated and summary eventualities.
How Does Sora Generate Video From Textual content?
To generate movies from textual content, throughout coaching, Sora is given two issues:
- Video
- Textual content description of the video
To coach at a big scale (web degree), OpenAI used a separate mannequin to generate textual content captions for the coaching movies (much like DALL-E 3). Furthermore, additionally they used GPT to generate an in depth caption from person prompts, in order that the mannequin can generate video precisely. Furthermore, Sora makes use of one other essential method, referred to as diffusion.
What’s Diffusion?
Diffusion is the method of including noise to a picture till it turns into unrecognizable, after which making the mannequin reverse that picture by denoising. The thought may appear complicated, however it powers Open AI Sora and DALL-E 3.

The method is as follows:
- Ahead Diffusion (Including Noise): The mannequin has a transparent picture, and regularly provides noise to it over many steps. This creates a sequence of noisy variations of the unique knowledge.
- Reverse Diffusion (Eradicating Noise): The mannequin is then educated to learn to take away the noise and get well the unique knowledge (by studying a perform that maps the noised model again to the unique picture). It does this one step at a time, going from the very noisy model again to the clear picture.
By studying to take away noise successfully, the mannequin captures the underlying patterns and constructions of the actual knowledge. This enables it to generate completely new knowledge samples which are much like what it has seen earlier than.
Use Circumstances of OpenAI Sora
Sora with its lifelike video-generating skills, can be utilized for the next;
Media Manufacturing: Sora can be utilized to create brief movies, animations, or video content material for people and social media.
Promoting and Advertising: Corporations can generate customized video advertisements or promotional content material for particular merchandise with out the necessity for intensive video manufacturing sources.
Schooling and Coaching: Explainer movies and simulations that may be generated for youngsters, college students, and workers for interactive studying.
Gaming and Digital Actuality: Sora can generate dynamic backgrounds, cutscenes, or interactive components for video games and VR experiences. Lowering manufacturing prices extensively and permitting creators to give attention to the gameplay to make the video games extra enjoyable.
Artwork and Inventive Exploration: Artists and creators can discover new dimensions of digital artwork by producing distinctive movies that specific their concepts and convey their message.
Simulations for Drug Discovery: Sora can simulate drug interactions with molecules based mostly on scientific descriptions. This is able to enable researchers to just about check potential medicine earlier than conducting real-world experiments.
Challenges
Though Sora generates movies with excessive accuracy and realism, it nonetheless struggles with good realism in movies and produces inaccurate movies. A few of the points it faces are:
- Actual-world physics: Struggles with simulating complicated scene physics and cause-effect relationships, resembling a bitten cookie not displaying a chew mark.
- Spatial inaccuracy: Confuses spatial particulars (e.g., mixing up left and proper) and exact occasion descriptions over time, like particular digicam actions.

Concerns Relating to Sora
Sora can generate near actual movies and thus presents quite a lot of dangers. Right here are some things to recollect for potential misuse dangers:
Dangers of Sora AI
- Social Unrest:
- Fabrication of movies inciting violence, discrimination, or social unrest.
- Ambiguity: Issue to tell apart what’s video actual and what’s not.
- Dangerous Content material Technology: Movies containing express, nsfw, or different unsavory content material.
- Misinformation and Disinformation:
- Spreading false data by means of lifelike movies.
- Creation of deepfakes for manipulating actual folks and conditions.
- For instance might be utilized in elections to unfold propaganda.
- Biases and Stereotypes: Perpetuation of cultural biases or stereotypes current in coaching knowledge.
OpenAI has mentioned on its web site, that will probably be taking the next steps to make sure the secure utilization of Sora:
- Testing by Consultants: Crimson teamers (consultants in misinformation, hateful content material, bias, and so forth.) will check Sora to determine potential dangers.
- Deceptive Content material Detection: Instruments are being constructed to detect movies generated by Sora and flag deceptive content material.
- Metadata for Transparency: C2PA metadata (figuring out AI-generated content material) shall be included in future deployments.
- Leveraging Current Security Strategies: Current security measures from DALL-E 3 shall be utilized to Sora, together with:
- Textual content immediate filtering to stop dangerous content material technology.
- Picture classification to make sure adherence to utilization insurance policies earlier than the person views the generated content material.
- Collaboration & Schooling: OpenAI will have interaction policymakers, educators, and artists to:
- Perceive considerations about Sora’s potential misuse.
- Establish optimistic use circumstances for the expertise.
- Study from real-world use to constantly enhance security.
Way forward for OpenAI Sora
OpenAI plans to make use of Sora as a basis for fashions sooner or later that perceive and simulate the actual world.
In the meantime, they’re assured that additional scaling of Sora will yield enhancements. Furthermore, Sooner or later, we’d see a extra lifelike Sora and related fashions that may perceive the bodily dynamics of the world higher, and generate extra lifelike movies.
To proceed studying in regards to the world of AI, try our different blogs: