

Pandas is a free and open-source Python information evaluation library particularly designed for information manipulation and evaluation. It excels at working with structured information, typically encountered in spreadsheets or databases. Pandas simplifies information cleansing by offering instruments for duties like sorting, filtering, and information transformation. It might probably successfully deal with lacking values, remove duplicates, and restructure your information to organize it for evaluation.
Past core information manipulation, pandas combine seamlessly with information visualization libraries like Matplotlib and Seaborn. This integration empowers you to create plots and charts for visible exploration and a deeper understanding of the info.
Developed in 2008 by Wes McKinney for monetary information evaluation, pandas has grown considerably to turn into a flexible information science toolkit.
The creators of the Pandas library designed it as a high-level software or constructing block to facilitate sensible, real-world evaluation in Python. The distinctive efficiency, user-friendliness, and seamless integration with different scientific Python libraries have made pandas a well-liked and succesful software for Information Science duties.
About us: Viso Suite is the enterprise machine studying infrastructure that palms full management of the complete software lifecycle to ML groups. With top-of-the-line safety measures, ease of use, scalability, and accuracy, Viso Suite gives enterprises with 695% ROI in 3 years. To study extra, guide a demo with our workforce.
The core of Pandas Library
Pandas affords two major information constructions: Sequence (one-dimensional) and DataFrame (two-dimensional).
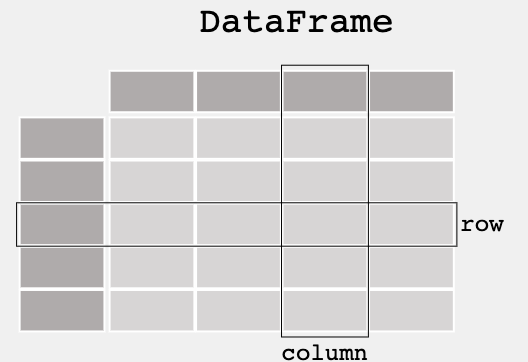
- DataFrame: A DataFrame is a two-dimensional, size-mutable information construction with labeled axes (rows and columns). They’re simply readable and printable as a two-dimensional desk.
- Sequence: A Sequence in pandas is a one-dimensional labeled array able to holding information of varied information varieties like integers, strings, floating-point numbers, Python objects, and so forth. Every aspect within the Sequence has a corresponding label, offering a approach to entry and reference information.
Furthermore, Pandas permits for importing and exporting tabular information in varied codecs, similar to CSV recordsdata, JSON, Exel recordsdata (.xlsx), and SQL databases.

Creating Information Frames and Sequence in Pandas
First, you’ll want to arrange your atmosphere. You should use Jupyter Pocket book or arrange a customized atmosphere.
- Begin by putting in the Pandas library utilizing: pip set up pandas
- Import pandas: import pandas as pd
- Create DataFrame
- Create Sequence
#creating dataframe
information = {'Identify': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 28]}
df = pd.DataFrame(information)
print(df)
#Creating Sequence fruits = ['apple', 'banana', 'orange'] sequence = pd.Sequence(fruits) print(sequence)
Core Functionalities in Pandas
Pandas affords a variety of functionalities to cater to the phases of the info processing pipeline for Machine Studying and Information Science duties, furthermore it’s the most used within the assortment of Python libraries for information evaluation duties. A number of the core functionalities embrace:
- Information Choice and Indexing: It permits deciding on and indexing information, both by label (loc), integer location (iloc), or a mix of each.
- Information Cleansing: Figuring out and dealing with lacking information, duplicate entries, and information inconsistencies.
- Information Transformation: Duties similar to pivoting, reshaping, sorting, aggregating, and merging datasets.
- Information Filtering: Filtering strategies to pick out subsets of knowledge primarily based on conditional standards.
- Statistical Evaluation: Pandas gives features to carry out descriptive statistics, correlation evaluation, and aggregation operations.
- Time Sequence Evaluation: With specialised time sequence functionalities, Pandas is well-equipped to deal with date and time information, and carry out date arithmetic, resampling, and frequency conversion.
- Visualization: Creating plots and graphs of the info.
Information Choice and Indexing
Pandas gives a number of instruments for choosing information from DataFrames utilizing a number of strategies.
Deciding on rows and columns in Pandas could be accomplished in a number of methods, relying on the particular necessities of your process. Right here’s a information to a few of the commonest strategies utilizing loc, iloc, and different methods:
Utilizing loc for Label-Based mostly Choice
- Single column: df.loc[:, ‘column_name’]
- A number of columns: df.loc[:, [‘column_name1’, ‘column_name2’]]
- Single row: df.loc[‘row_label’]
- A number of rows: df.loc[[‘row_label1’, ‘row_label2’]]
Utilizing iloc for Place-Based mostly Choice
- Single column: df.iloc[:, 2] (selects the third column)
- A number of columns: df.iloc[:, [1, 3]] (selects the second and fourth columns)
- Single row: df.iloc[4] (selects the fifth row)
- A number of rows: df.iloc[[1, 3]] (selects the second and fourth rows)
Boolean Indexing
- Rows primarily based on situation: df[df[‘column_name’] > worth] (selects rows the place the situation is True)
- Utilizing loc with a situation: df.loc[df[‘column_name’] == ‘worth’, [‘column1’, ‘column2’]]
import pandas as pd
import numpy as np
# Making a pattern DataFrame
information = {
'Identify': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 34, 29, 32],
'Metropolis': ['New York', 'Paris', 'Berlin', 'London'],
'Wage': [68000, 72000, 71000, 69000]
}
df = pd.DataFrame(information)
# Utilizing loc for label-based choice
multiple_columns_loc = df.loc[:, ['Name', 'Age']]
# Utilizing iloc for position-based choice
multiple_columns_iloc = df.iloc[:, [0, 1]]
# Rows primarily based on situation
rows_based_on_condition = df[df['Age'] > 30]
# Utilizing loc with a situation
loc_with_condition = df.loc[df['City'] == 'Paris', ['Name', 'Salary']]
#output
Utilizing loc for Label-Based mostly Choice
Identify Age
0 John 28
1 Anna 34
2 Peter 29
3 Linda 32
Rows Based mostly on Situation (Age > 30)
Identify Age Metropolis Wage
1 Anna 34 Paris 72000
3 Linda 32 London 69000
Utilizing loc with a Situation (Metropolis == 'Paris')
Identify Wage
1 Anna 72000
Information Cleansing and Dealing with Lacking Values
Significance of Information Cleansing
Actual-world information typically accommodates inconsistencies, errors, and lacking values. Information cleansing is essential to make sure the standard and reliability of your evaluation. Right here’s why it’s essential:
- Improved Information High quality
- Enhanced Evaluation
- Mannequin Effectivity in ML

Lacking values are information factors which can be absent or not recorded. They’ll come up resulting from varied causes like sensor malfunctions, consumer skipping fields, or information entry errors. Listed here are some widespread strategies for dealing with lacking values in pandas:
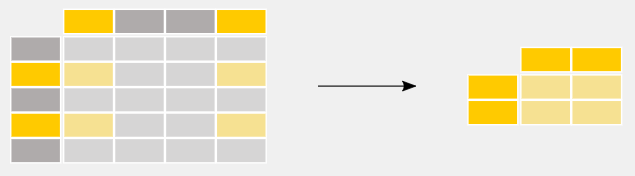
Figuring out Lacking Values
- Examine for lacking values: Use df.isnull() or df.isna() to examine for lacking values, which returns a boolean DataFrame indicating the presence of lacking values.
- Rely lacking values: df.isnull().sum() to depend the variety of lacking values in every column.
Dealing with Lacking Values
- Take away lacking values:
- df.dropna() drops rows with any lacking values.
- df.dropna(axis=1) drops columns with any lacking values.
- Fill lacking values:
- df.fillna(worth) fills lacking values with a specified worth.
- df[‘column’].fillna(df[‘column’].imply()) fills lacking values in a particular column with the imply of that column.
Information Transformation
- Eradicating duplicates: df.drop_duplicates() removes duplicate rows.
- Renaming columns: df.rename(columns={‘old_name’: ‘new_name’}) to rename columns.
- Altering information varieties: df.astype({‘column’: ‘dtype’}) modifications the info sort of a column.
- Apply features: df.apply(lambda x: func(x)) applies a perform throughout an axis of the DataFrame.
# Pattern information with lacking values
information = {'Identify': ['John', 'Anna', 'Peter', None],
'Age': [28, np.nan, 29, 32],
'Metropolis': ['New York', 'Paris', None, 'London']}
df = pd.DataFrame(information)
# Examine for lacking values
missing_values_check = df.isnull()
# Rely lacking values
missing_values_count = df.isnull().sum()
# Take away rows with any lacking values
cleaned_df_dropna = df.dropna()
# Fill lacking values with a particular worth
filled_df = df.fillna({'Age': df['Age'].imply(), 'Metropolis': 'Unknown'})
# Eradicating duplicates (assuming df has duplicates for demonstration)
deduped_df = df.drop_duplicates()
# Renaming columns
renamed_df = df.rename(columns={'Identify': 'FirstName'})
# Altering information sort of Age to integer (after filling lacking values for demonstration)
df['Age'] = df['Age'].fillna(0).astype(int)
missing_values_check, missing_values_count, cleaned_df_dropna, filled_df, deduped_df, renamed_df, df
#ouputs Examine for lacking values Identify Age Metropolis 0 False False False 1 False True False 2 False False True 3 True False False Counting Lacking Values Identify 1 Age 1 Metropolis 1 dtype: int64 Eradicating the lacking values Identify Age Metropolis 0 John 28.0 New York
DataFiltering and Statistical Evaluation
Statistical evaluation in Pandas entails summarizing the info utilizing descriptive statistics, exploring relationships between variables, and performing inferential statistics. Widespread operations embrace:
- Descriptive Statistics: Features like describe(), imply(), and sum() present summaries of the central tendency, dispersion, and form of the dataset’s distribution.
- Correlation: Calculating the correlation between variables utilizing corr(), to grasp the energy and course of their relationship.
- Aggregation: Utilizing groupby() and agg() features to summarize information primarily based on classes or teams.
Information filtering in Pandas could be carried out utilizing boolean indexing by which it selects entries that meets a particular standards ( for e.g. gross sales > 20)
# Pattern information creation
sales_data = {
'Product': ['Table', 'Chair', 'Desk', 'Bed', 'Chair', 'Desk', 'Table'],
'Class': ['Furniture', 'Furniture', 'Office', 'Furniture', 'Furniture', 'Office', 'Furniture'],
'Gross sales': [250, 150, 200, 400, 180, 220, 300]
}
sales_df = pd.DataFrame(sales_data)
inventory_data = {
'Product': ['Table', 'Chair', 'Desk', 'Bed'],
'Inventory': [20, 50, 15, 10],
'Warehouse_Location': ['A', 'B', 'C', 'A']
}
inventory_df = pd.DataFrame(inventory_data)
# Merging gross sales and stock information on the Product column
merged_df = pd.merge(sales_df, inventory_df, on='Product')
# Filtering information
filtered_sales = merged_df[merged_df['Sales'] > 200]
# Statistical Evaluation
# Fundamental descriptive statistics for the Gross sales column
sales_descriptive_stats = merged_df['Sales'].describe()
#ouputs Filtered Gross sales Information (Gross sales > 200): Product Class Gross sales Inventory Warehouse_Location 0 Desk Furnishings 250 20 A 3 Mattress Furnishings 400 10 A 5 Desk Workplace 220 15 C 6 Desk Furnishings 300 20 A Descriptive Statistics for Gross sales: depend 7.000000 imply 242.857143 std 84.599899 min 150.000000 25% 190.000000 50% 220.000000 75% 275.000000 max 400.000000 Identify: Gross sales, dtype: float64
Information Visualization
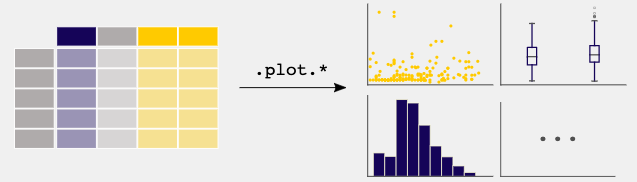
Pandas is primarily targeted on information manipulation and evaluation, nevertheless, it affords fundamental plotting functionalities to get you began with information visualization.
Information visualization in Pandas is constructed on prime of the matplotlib library, making it straightforward to create fundamental plots from DataFrames and Sequence with no need to import matplotlib explicitly. This performance is accessible by the .plot() technique and gives a fast and simple approach to visualize your information for evaluation.
Pandas AI

PandasAI is a third-party library constructed on prime of the favored Pandas library for Python, that simplifies information evaluation for Information Scientists and inexperienced coders. It leverages generative AI methods and machine studying algorithms to boost information evaluation capabilities for the pandas framework, serving to with machine studying modeling. It permits customers to work together with their information by pure language queries as a substitute of writing complicated pandas code. Here is the GitHub repo.
Moreover, it may be used to generate summaries, visualize the info, deal with lacking values, and have engineering, all of it utilizing simply prompts.
To put in it, you simply have to make use of pip set up pandasai.
Right here is an instance code for its utilization.
import os
import pandas as pd
from pandasai import Agent
# Pattern DataFrame
sales_by_country = pd.DataFrame({
"nation": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"gross sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000]
})
# By default, until you select a distinct LLM, it should use BambooLLM.
# You will get your free API key signing up at https://pandabi.ai (you may as well configure it in your .env file)
os.environ["PANDASAI_API_KEY"] = "YOUR_API_KEY"
agent = Agent(sales_by_country)
agent.chat('That are the highest 5 international locations by gross sales?')
output: China, United States, Japan, Germany, Australia
agent.chat(
"What's the whole gross sales for the highest 3 international locations by gross sales?"
)
output: The entire gross sales for the highest 3 international locations by gross sales is 16500.
Use Instances of Pandas AI
Pandas library is extensively used not simply by information scientists, but in addition in a number of different fields similar to:
- Scientific Computing: Pandas could be mixed with different libraries (NumPy) to carry out linear algebra operations. You possibly can carry out Fundamental Vector and Matrix Operations, resolve linear equations, and different mathematical duties. Furthermore, scikit-learn library is extensively utilized in mixture with Pandas.
- Statistical Evaluation: Pandas gives built-in features for varied statistical operations. You possibly can calculate descriptive statistics like imply, median, normal deviation, and percentiles for complete datasets or subsets.
- Machine Studying: Pandas facilitates characteristic engineering, a vital step in machine studying. It permits information cleansing, transformation, and choice to create informative options that energy correct machine-learning fashions.
- Time Sequence: Industries like retail and manufacturing use time sequence evaluation to establish seasonal patterns, predict future demand fluctuations, and optimize stock administration. Pandas library is well-suited for working with time sequence information. Options like date-time indexing, resampling, and frequency conversion, all help with managing time sequence information.
- Monetary Evaluation: Pandas is used to investigate huge monetary datasets, and monitor market traits. Its information manipulation capabilities streamline complicated monetary modeling and danger evaluation.