

Introduction
On this ever-evolving discipline of laptop imaginative and prescient, the emergence of Imaginative and prescient Transformers (ViTs) has been a groundbreaking idea. These fashions, launched by Dosovitskiy et al. within the paper “An Picture is Price 16×16 Phrases: Transformers for Picture Recognition (2020),” have confirmed a famous enchancment and alternative to conventional convolutional neural community (CNN) approaches. ViTs affords a novel Transformer structure that leverages the eye mechanism for picture evaluation.
Because the demand for superior laptop imaginative and prescient methods continues to surge throughout numerous industries, the deployment of Imaginative and prescient Transformers has develop into a focus for researchers and practitioners. Nevertheless, harnessing the complete potential of those fashions requires a deep understanding of their structure. Additionally, it’s equally essential to develop an optimization technique for an environment friendly deployment of those fashions.
This text goals to supply an outline on Imaginative and prescient Transformers, a complete exploration of their structure, key parts, and the underlying ideas that units them aside. On the finish of the article, we are going to talk about a couple of of the optimization methods to make the mannequin extra compact for deployment with a code demo.
Overview of Transformer Fashions
ViTs are a particular kind of neural community that finds its main utility in picture classification and object detection. The accuracy of ViTs have surpassed conventional CNNs, and a key issue contributing to that is their basis on the Transformer structure. Now what is that this structure?
In 2017, the Transformer neural community structure was launched within the paper “Consideration is all you want” by Vaswani et al. This community makes use of an encoder and a decoder construction similar to a Recurrent Neural Community (RNN). On this mannequin, there aren’t any notion of timestamps for the enter; all phrases are handed concurrently, and their phrase embeddings are decided concurrently.
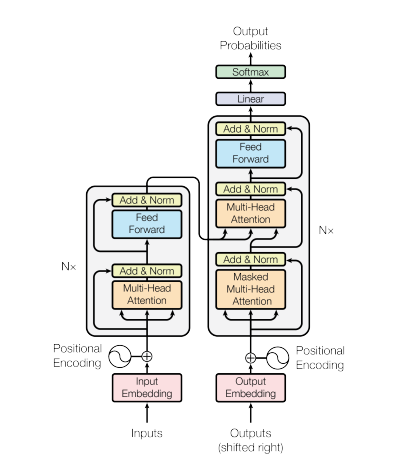
One of these neural community structure depends on a mechanism referred to as self-attention.
Here is a high-level clarification of the important thing parts of the Transformer structure:
- Enter-Embeddings: Enter-Embedding is step one to move the enter to the transformers. Enter embedding refers back to the means of changing enter tokens or phrases into fixed-size vectors that may be fed into the mannequin. This embedding step is essential as a result of it transforms the discrete token representations into steady vector representations in a manner that captures semantic relationships between phrases. This embedding step maps a phrase to a vector, however the identical phrase with totally different sentences could have totally different meanings. That is had been positional encoders is available in.
- Positional Encodings: Since Transformers don’t inherently perceive the order of the weather in a sequence, positional encodings are added to the enter embeddings to present the mannequin details about the positions of components within the sequence. In less complicated phrases, the positional embeddings offers a vector which is context based mostly on place of the phrase in a sentence. The unique paper makes use of a sin and cosine operate to generate this vector. This data is handed to the encoder block.
- Encoder-Decoder Construction: The Transformer is primarily used for sequence-to-sequence duties, like machine translation. It consists of an encoder and a decoder. The encoder processes the enter sequence, and the decoder generates the output sequence.
- Multi-Head Self-Consideration: Self-attention permits the mannequin to weigh totally different elements of the enter sequence in a different way when making predictions. The important thing innovation within the Transformer is the usage of a number of consideration heads, permitting the mannequin to deal with totally different points of the enter concurrently. Every consideration head is skilled to take care of totally different patterns.
- Scaled Dot-Product Consideration: The eye mechanism computes a set of consideration scores by taking the dot product of the enter sequence with learnable weight vectors. These scores are scaled and handed by way of a softmax operate to acquire consideration weights. The weighted sum of the enter sequence utilizing these consideration weights is the output of the eye mechanism.
- Feedforward Neural Networks: After consideration layers, every encoder and decoder block usually features a feedforward neural community with an activation operate equivalent to ReLu. This community is utilized independently to every place within the sequence.
- Layer Normalization and Residual Connections: Layer normalization and residual connections are used to stabilize coaching. Every sub-layer (consideration or feedforward) within the encoder and decoder has layer normalization, and the output of every sub-layer is handed by way of a residual connection.
- Encoder and Decoder Stacks: The encoder and decoder are composed of a number of an identical layers stacked on prime of one another. The variety of layers is a hyperparameter.
- Masked Self-Consideration in Decoders: Throughout coaching, within the decoder, the self-attention mechanism is modified to forestall attending to future tokens. That is achieved utilizing a masking approach to make sure that every place can solely attend to positions earlier than it.
- Closing Linear and Softmax Layer: The output of the decoder stack is reworked into the ultimate predicted chances (e.g., utilizing a linear layer adopted by a softmax activation) for producing the output sequence.
Understanding Imaginative and prescient Transformer Structure
CNNs had been thought-about to be the very best options for picture classification duties. ViTs constantly beat CNNs on such duties, if the dataset for pre-training is sufficiently massive. ViTs have marked a big achievement by efficiently coaching a Transformer encoder on ImageNet, showcasing spectacular outcomes compared to well-known convolutional architectures.
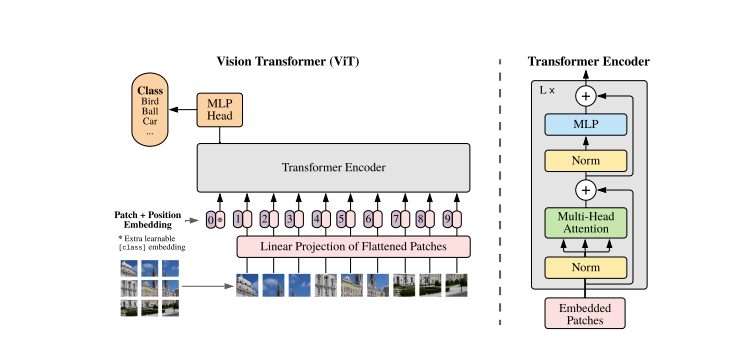
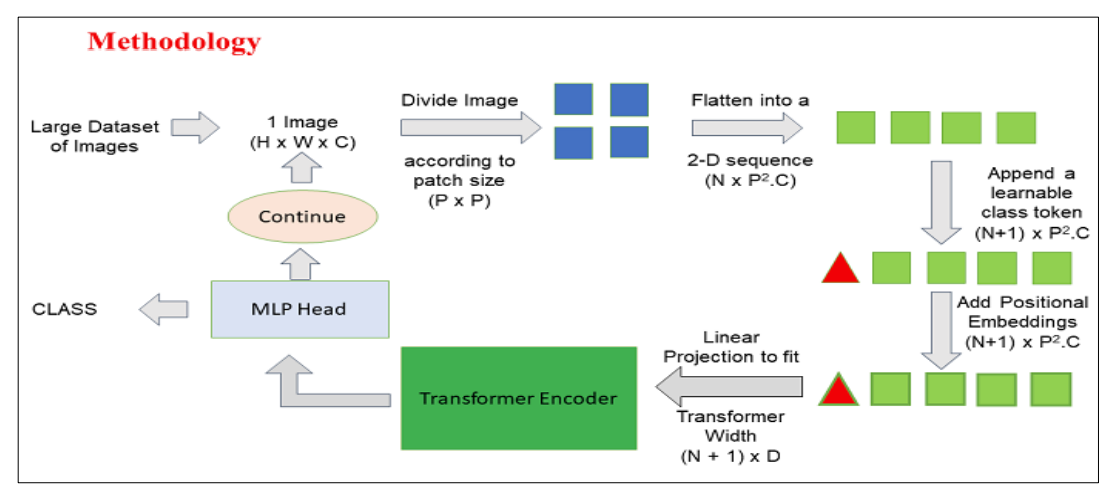
Transformers fashions usually work with photos and phrases which can be handed in sequence to the encoder-decoder. Here’s a simplified overview of ViTs:
- Patch Extraction: The photographs, as sequences of patches are fed to the Transformer encoder. A patch refers to a small rectangular part inside a picture, usually measuring 16×16 pixels in measurement.

- After dividing the picture into non-overlapping patches (usually 16×16 grid), every patch is reworked right into a vector that represents its options. These options are normally extracted by way of the utilization of a convolutional neural community (CNN), which is skilled to establish vital traits important for picture classification.
- Linear Embedding: These extracted patches are linearly embedded into flat vectors. These vectors are then handled because the enter sequence for the Transformer a.ka.a Linear Projection of Flattened Patches.
- Transformer Encoder: The embedded patch vectors are handed by way of a stack of Transformer encoder layers. Every encoder layer consists of self-attention mechanisms and feedforward neural networks.
- Self-Consideration Mechanism: The self-attention mechanism permits the mannequin to seize relationships between totally different patches within the picture, enabling it to be taught long-range dependencies and relationships. The eye mechanism within the Transformer permits the mannequin to seize each native and international contextual data, making it efficient for a variety of imaginative and prescient duties.
- Positional Encoding: Because the Transformer doesn’t inherently perceive the spatial relationships between patches, positional encodings are added to the enter embeddings to supply details about the patch positions within the authentic picture.
- A number of Encoder Layers: The ViTs usually makes use of a number of Transformer encoder layers to seize hierarchical and summary options from the enter picture.
- International Common Pooling: The output of the Transformer encoder is usually subjected to international common pooling, which aggregates the data from totally different patches right into a fixed-size illustration.
- Classification Head: The pooled illustration is then fed right into a classification head, usually consisting of a number of totally linked layers, to supply the ultimate output for the particular laptop imaginative and prescient process (e.g., picture classification).
We extremely suggest testing the unique analysis paper for a deeper understanding of ViTs structure.
The best way to use
Deliver this undertaking to life
Right here is python demo on methods to use this mannequin to categorise a picture:
#set up the transformers libraries utilizing pip
!pip set up -q transformersImport the mandatory courses from the Transformer library. ViTFeatureExtractor is used for extracting options from photos, and ViTForImageClassification is a pre-trained ViT mannequin for picture classification.
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Picture as img
from IPython.show import Picture, show
#specify the trail to picture
FILE_NAME = '/notebooks/football-1419954_640.jpg'
show(Picture(FILE_NAME, width = 700, top = 400))

The best way to use a pre-trained Imaginative and prescient Transformer (ViT) mannequin to foretell the category of an enter picture.
image_array = img.open('/notebooks/football-1419954_640.jpg')
#loading the ViT Function Extractor and Mannequin
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
mannequin = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#Extracting Options and Making Predictions:
inputs = feature_extractor(photos = image_array,
return_tensors="pt")
outputs = mannequin(**inputs)
logits = outputs.logits
# mannequin predicts one of many 1000 ImageNet courses
predicted_class_idx = logits.argmax(-1).merchandise()
print(predicted_class_idx)
#805
print("Predicted class:", mannequin.config.id2label[predicted_class_idx])
#Predicted class: soccer ball
Right here is code breakdown:
ViTFeatureExtractor.from_pretrained: That is answerable for changing the enter picture right into a format appropriate for the ViT mannequin.ViTForImageClassification.from_pretrained: Masses a pre-trained ViT mannequin for picture classification.feature_extractor: Processes the enter picture utilizing the ViT function extractor, changing it right into a format appropriate for the ViT mannequin.mannequin: Pre-trained mannequin processes the enter and produces output logits, representing the mannequin’s predictions for various courses.- The following steps is adopted by discovering the index of the category with the very best logit rating. Making a variable that shops the index of the expected class.
mannequin.config.id2label[predicted_class_idx]: Maps the expected class index to its corresponding label.
Initially, the ViT mannequin was pre-trained utilizing the well-known ImageNet-21k, a dataset consisting of 14 million photos and 21k courses, and was fine-tuned on ImageNet dataset which incorporates 1 million photos and 1k courses.
Optimization Methods
ViTs report an excellent efficiency in duties equivalent to picture classification, object detection, and semantic segmentation. Moreover, the Transformer structure itself has demonstrated efficiency enhancements over CNN. Nevertheless these architectures require large quantities of knowledge to coach and excessive computational sources. As a consequence of this the fashions deployment turns into heavy.
Mannequin compression has develop into a brand new level of analysis, providing a promising resolution to deal with the challenges of resource-intensive fashions. Varied strategies have emerged within the literature to compress fashions, together with weight quantization, weight multiplexing, pruning, and Data Distillation (KD). Data distillation (KD) has confirmed to be a simple but extremely environment friendly methodology for compressing fashions. It allows a much less intricate mannequin to realize process efficiency practically on par with the unique mannequin.
Data distillation is a mannequin compression approach in machine studying the place a fancy mannequin, sometimes called the “instructor” mannequin, transfers its information to a less complicated mannequin, referred to as the “scholar” mannequin. The purpose is to distill the important data or information realized by the instructor mannequin into the scholar mannequin, permitting the scholar mannequin to realize related efficiency on a given process. This course of usually entails coaching the scholar mannequin to imitate the output chances or representations of the instructor mannequin, serving to to cut back the computational sources required whereas sustaining passable efficiency.
A number of distilled mannequin approaches have confirmed to be efficient for ViT compression equivalent to Goal conscious Transformer, Fantastic-Grain Manifold Distillation Technique, Cross Inductive Bias Distillation (Coadvice), Tiny-ViT, Consideration Probe-based Distillation Technique, Knowledge-Environment friendly Picture Transformers Distillation by way of Consideration (DeiT), Unified Visible Transformer Compression (UVC), Pricey-KD Distillation Technique, Cross Structure Distillation Technique, and lots of extra.
What’s DeiT
A novel approach within the visual field transformers was developed by Touvron et al. named Coaching Knowledge-Environment friendly Picture Transformers Distillation by way of Consideration a.ok.a. DeiT. DEiT, or Knowledge-efficient Picture Transformer, is a kind of imaginative and prescient transformer that addresses the problem of coaching large-scale transformer fashions on restricted labeled knowledge. Imaginative and prescient transformers have gained consideration for his or her success in laptop imaginative and prescient duties, however coaching them typically requires in depth labeled datasets and computing sources.
DeiT is a convolution-free transformer which is completely skilled on the ImageNet dataset. The coaching course of took lower than three days on a single laptop. The benchmark mannequin was a imaginative and prescient transformer, consisting of 86 million parameters.
DeiT is launched because the teacher-student technique and depends on KD guaranteeing the scholar learns from the instructor mannequin by way of consideration. The primary thought is to pre-train a big instructor mannequin on a big dataset (e.g., ImageNet) the place considerable labeled examples can be found. The information realized by this instructor mannequin is then transferred to a smaller scholar mannequin, which is skilled on the goal dataset with restricted labeled samples.
| Vit | DeiT |
|---|---|
| Coaching required large dataset which isn’t obtainable publicly as properly | Educated solely utilizing ImageNet 10 instances smaller dataset |
| Educated utilizing in depth compute energy, additionally the coaching time was longer | Educated utilizing a single laptop in lower than 3 days, with a single 8 GPU or 4GPU machine |
| Required 300 M samples dataset | 30 M samples dataset |
Aside from KD, DeiT requires a information of Regularization and Knowledge Augmentation. In less complicated phrases regularization prevents the mannequin from overfitting to the coaching knowledge, it helps the mannequin to be taught the precise data from the information. Augmentation refers back to the strategy of artificially rising the scale of a dataset by making use of numerous transformations to the prevailing knowledge. This helps in getting totally different variations of the identical knowledge. These are the among the many few main strategies utilized in DeiT, nevertheless the foremost contributor was KD.
Within the authentic analysis paper, DeiT proposes a modified strategy of KD also called Exhausting Distillation. Right here the instructor community is the state-of-the-art CNN pretrained on ImageNet. The Pupil community is the modified model of transformer. The primary modification is the output of the CNN is additional handed as an enter to the transformer.
- Exhausting Choice of the instructor community is the true label, the purpose related to this hard-label distillation is:
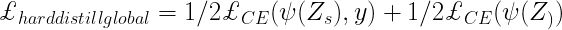
- New distillation tokens are launched together with the category tokens and patch tokens. These tokens interacts with the opposite two by way of self-attention layers.
- In all subsequent distillation experiments, the default instructor is a RegNetY-16GF with 84 million parameters. The experiments make use of the identical dataset and knowledge augmentation as DeiT.
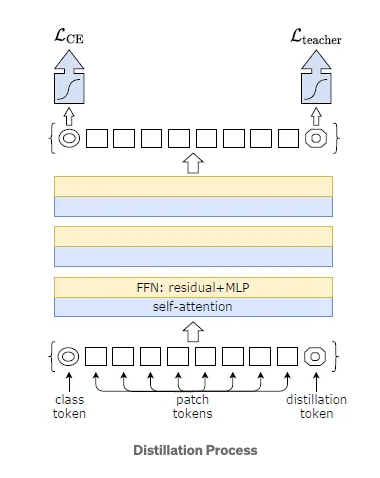
- DeiT Structure variations:
- DeiT-Ti: Tiny mannequin with 5M parameters
- DeiT-S: Small mannequin with 22M parameters
- DeiT-B: Massive mannequin with 86M parameters
- DeiT-b 384: Fantastic tuned mannequin for bigger decision of 384×384
- DeiT: Makes use of distillation course of
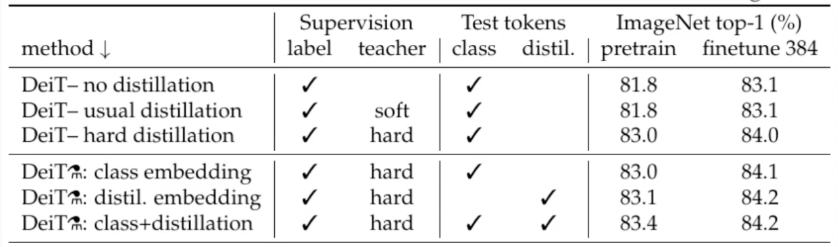
Within the picture under, we will assess the efficacy of laborious distillation, because the accuracy reaches practically 83%, a degree unattainable by way of delicate distillation. Moreover, the distillation tokens brings barely higher outcomes.
- Coaching DeiT-B for 300 epochs usually requires 37 hours on 2 nodes or 53 hours on a single 8-GPU node.
A Code Demo and In-Depth Understanding for Environment friendly Deployment
Deliver this undertaking to life
DeiT demonstrates the profitable utility of Transformers in laptop imaginative and prescient duties, even with restricted knowledge availability and sources.
Classifying Photographs with DeiT
Please seek advice from the detailed directions within the README.md of the DeiT repository for steering on picture classification utilizing DeiT. Alternatively, for a fast check, start by putting in the mandatory packages:
!pip set up torch torchvision timm pandas requests
Subsequent, run the under script
from PIL import Picture
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.knowledge.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# must be 1.8.0
mannequin = torch.hub.load('facebookresearch/deit:important', 'deit_base_patch16_224', pretrained=True)
mannequin.eval()
remodel = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
img = Picture.open(requests.get("https://photos.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).uncooked)
img = remodel(img)[None,]
out = mannequin(img)
clsidx = torch.argmax(out)
print(clsidx.merchandise())Now, this could output 285, which, in accordance with the checklist of courses from the ImageNet index (labels file), maps to ‘Egyptian cat.’
This code primarily demonstrates methods to use a pre-trained DeiT mannequin for picture classification and prints the output that’s the index of the expected class. Allow us to perceive the code briefly by breaking it down additional.
- Putting in Libraries: The primary mandatory step is putting in the required libraries. We extremely suggest the customers to analysis on the libraries for a greater understanding.
- Loading Pre-trained Mannequin:
mannequin = torch.hub.load('facebookresearch/deit:important', 'deit_base_patch16_224', pretrained=True): Masses a pre-trained DeiT mannequin named ‘deit_base_patch16_224’ from the DeiT repository. - Setting Mannequin to Analysis Mode:
mannequin.eval(): Units the mannequin to analysis mode, which is essential when utilizing a pre-trained mannequin for inference. - Picture Transformation: Defines a collection of transformation to be utilized to the picture. Comparable to resizing, heart cropping, changing the picture to PyTorch tensor, normalize the picture utilizing the imply and commonplace deviation values generally used for ImageNet knowledge.
- Downloading and remodeling the picture: The following step entails downloading the picture from a URL and remodeling it. Including the parameter
[None,]provides an additional dimension to simulate a batch of measurement 1. - Mannequin Inference and prediction:
out = mannequin(img)will permit the preprocessed picture by way of the DeiT mannequin for inference.clsidx = torch.argmax(out)will discover the index of the category with the very best chance. Subsequent, print the index of the expected class.
Quantizing the mannequin
To cut back the mannequin measurement, quantization is utilized. This course of reduces the scale by not hampering the mannequin accuracy.
#Specifies the quantization backend as "qnnpack." QNNPACK (Quantized Neural Community PACKage) is a library for low-precision quantized neural community inference developed by Fb
backend = "qnnpack"
mannequin.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
quantized_model = torch.quantization.quantize_dynamic(mannequin, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")In abstract, this code snippet quantizes the mannequin, and saves the mannequin to a file named “fbdeit_scripted_quantized.pt.” A very powerful a part of the code is defined under:
torch.quantization.quantize_dynamic(mannequin, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8): It quantizes the weights of the mannequin throughout the inference course of, and qconfig_spec specifies that quantization must be utilized solely to linear (totally linked) layers. The quantized knowledge kind used is torch.qint8 (8-bit integer quantization).
Optimizing the mannequin
To optimize the mannequin extra run the under code snippet:
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.merchandise())On this code snippet takes a scripted and quantized mannequin, optimizes it particularly for cell deployment utilizing the optimize_for_mobile operate, and saves the ensuing optimized mannequin to a file. The optimization goals to make the mannequin extra environment friendly when it comes to each reminiscence utilization and inference pace, which is essential for operating fashions on resource-constrained cell gadgets.
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model): The optimize_for_mobile operate performs numerous optimizations for cell deployment, equivalent to lowering the mannequin’s reminiscence footprint and bettering inference pace. The result’s an optimized model of the scripted and quantized mannequin.
The Lite model
Let’s create the lite model of the mannequin.
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")This course of is essential for deploying fashions on cell or edge gadgets that assist PyTorch Lite, guaranteeing compatibility and effectivity within the runtime surroundings of such gadgets.
Evaluating Inference Pace
To check the totally different mannequin variations when it comes to inference pace execute the offered code.
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = mannequin(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("authentic mannequin: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized mannequin: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized mannequin: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite mannequin: {:.2f}ms".format(prof4.self_cpu_time_total/1000))We strongly advise clicking the offered hyperlink on this article to entry the entire code throughout the Paperspace pocket book.
Concluding Ideas
On this article we’ve got included all the pieces to get began with imaginative and prescient transformer and discover this mannequin utilizing the Paperspace console. We now have explored one of many essential purposes for the mannequin: picture recognition. We now have additionally included Transformer structure for the sake of comparability and simpler interpretation of ViT.
The Imaginative and prescient Transformer paper, launched a promising and easy mannequin as a alternative for CNNs. This mannequin attained state-of-the-art benchmarks on widespread picture classification datasets, together with Oxford-IIIT Pets, Oxford Flowers, and Google Mind’s JFT-300M, following pre-training on ILSVRC’s ImageNet and its superset ImageNet-21M.
In conclusion, Imaginative and prescient Transformers (ViTs) and the DeiT symbolize vital developments within the discipline of laptop imaginative and prescient. ViTs, with their attention-based structure, demonstrated the effectiveness of transformer fashions in picture understanding, difficult conventional convolutional approaches.
DeiT, specifically, additional addressed the challenges confronted by ViT by introducing information distillation. By leveraging a teacher-student coaching paradigm, DeiT showcased the potential to realize aggressive efficiency with considerably much less labeled knowledge, making it a worthwhile resolution in eventualities the place massive datasets aren’t available.
As analysis on this space continues to evolve, these improvements pave the best way for extra environment friendly and highly effective fashions, promising thrilling prospects for the way forward for laptop imaginative and prescient purposes.