

The RetinaNet mannequin is a one-stage object detection mannequin incorporating options comparable to Focal Loss, a Characteristic Pyramid Community (FPN), and varied architectural enhancements. These enhancements present a novel stability between velocity and accuracy, making RetinaNet a novel mannequin.
Object detection, a core process in pc imaginative and prescient, includes pinpointing and classifying objects inside photographs or movies. This underpins purposes like self-driving automobiles, safety surveillance, and augmented actuality.
About us: Viso Suite is the end-to-end pc imaginative and prescient infrastructure permitting ML groups to remove the necessity for level options. Viso Suite covers all phases within the software lifecycle from sourcing information to mannequin coaching to deployment and past. To learn the way Viso Suite helps enterprises simply combine pc imaginative and prescient into their workflows, e book a demo.
Two most important approaches dominate object detection: One-Stage (like YOLO and SSD) and Two-Stage detectors (like R-CNN). Two-stage fashions suggest doubtless object areas first, then classify and refine their bounding containers. One-stage fashions bypass this step, predicting classes and bounding containers instantly from the picture in a single go.
Two-stage fashions (e.g., R-CNN) excel in accuracy and dealing with advanced scenes. Nevertheless, their processing time makes them much less appropriate for real-time duties. However, one-stage fashions are quick however have limitations:
- Accuracy vs. Velocity: Excessive-accuracy fashions are computationally costly, resulting in slower processing. YOLO prioritizes velocity, sacrificing some accuracy, significantly for small objects, in comparison with R-CNN variants.
- Class Imbalance: One-stage fashions deal with detection as a regression downside. When “background” vastly outnumbers precise objects, the mannequin will get biased in the direction of the background (destructive) class.
- Anchors: YOLO and SSD depend on predefined anchor containers with particular sizes and ratios. This will restrict their skill to adapt to various object sizes and shapes.
What’s RetinaNet?
RetinaNet is an object detection mannequin that tries to beat the restrictions of object detection fashions talked about above, particularly addressing the diminished accuracy in single-stage detectors. Regardless of RetinaNet being a Single-Stage detector it supplies a novel stability between velocity and accuracy.
It was launched by Tsung-Yi Lin and the crew of their 2017 paper titled “Focal Loss for Dense Object Detection.” Benchmark outcomes on the MS COCO dataset present that the mannequin achieves an excellent stability between precision (mAP) and velocity (FPS), making it appropriate for real-time purposes.
RetinaNet incorporates the next options:
- Focal Loss for Object Detection: RetinaNet introduces Focal Loss to deal with the category imbalance downside throughout coaching. That is achieved by modifying the usual cross-entropy loss perform to down-weight the loss assigned to well-classified examples. It provides much less significance to simply categorised objects and focuses extra on laborious, misclassified examples. This enables for elevated accuracy with out sacrificing velocity.
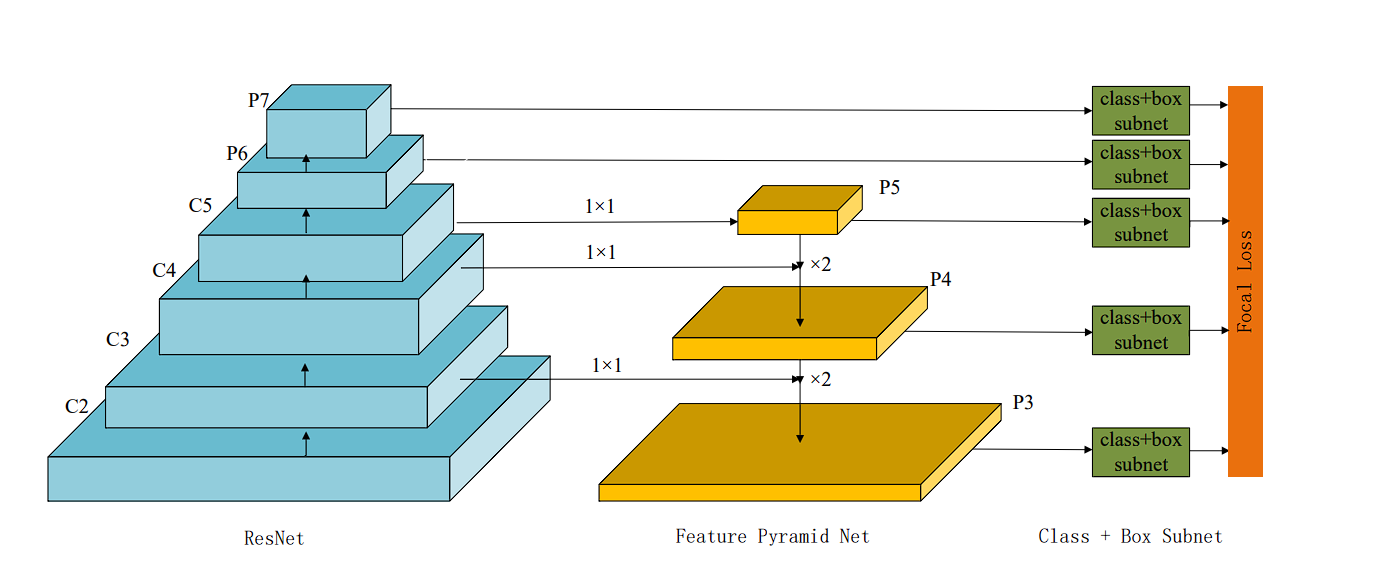
- Characteristic Pyramid Community (FPN): RetinaNet incorporates an FPN as its spine structure. This enhances its skill to detect objects at completely different scales successfully.
- ResNet: FPN is constructed on high of a typical convolutional neural community (CNN) like ResNet.
- SubNetworks: These are specialised smaller networks that department off the principle function extraction spine. They’re of two sorts:
- Classification Subnet
- Field Regression Subnet
RetinaNet surpasses a number of object detectors, together with one-stage and two-stage fashions, it types an envelope of all of the listed detectors.
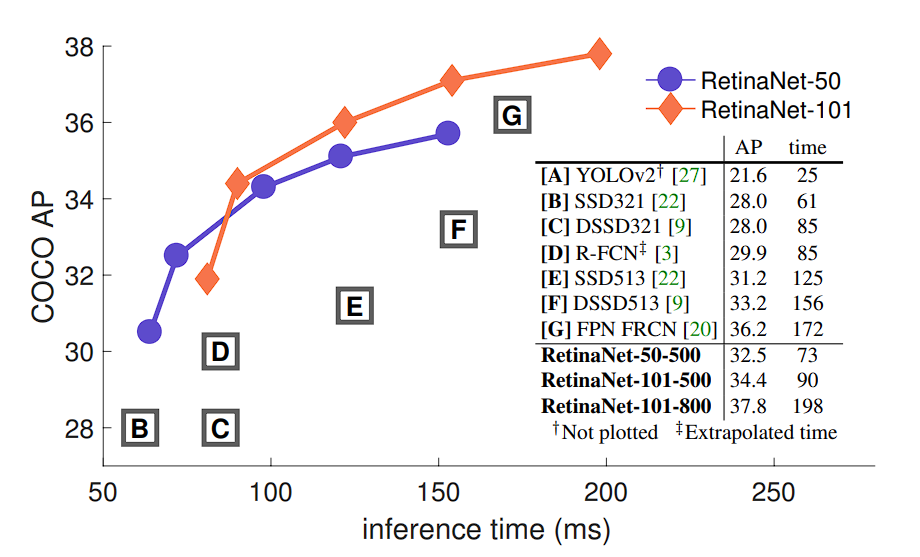
Earlier than we dive deeper into the structure of RetinaNet, let’s have a look at a few of the fashions earlier than it, and the restrictions and enhancements they revamped the earlier fashions.
Overview of Object Detection Fashions
- R-CNN (Areas with CNN options) 2014:
- Limitations: R-CNN was one of many first fashions that used CNNs for object detection however was gradual because of the must course of a number of areas individually. It additionally required a separate algorithm for proposing areas, which added to the complexity and processing time.
- Quick R-CNN (2015):
- Enhancements: Launched ROI pooling to hurry up processing by sharing computations throughout proposed areas.
Limitations: Though sooner than R-CNN, it nonetheless relied on selective seek for area proposals, which was a bottleneck.
- Enhancements: Launched ROI pooling to hurry up processing by sharing computations throughout proposed areas.
- Quicker R-CNN (2015):
- Enhancements: Built-in a Area Proposal Community (RPN) that shares full-image convolutional options with the detection community, bettering each velocity and accuracy.
- Limitations: Whereas it was extra environment friendly, the complexity of the mannequin and the necessity for appreciable computational assets restricted its deployment in resource-constrained environments.
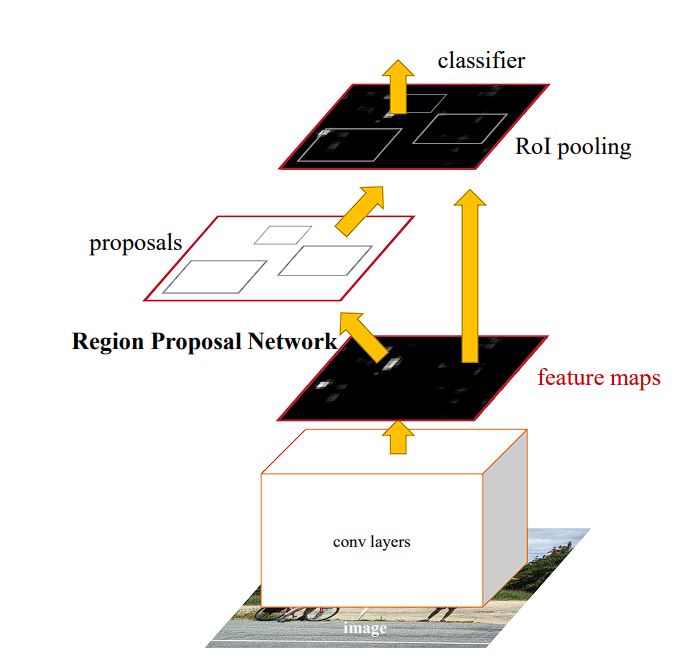
Quicker R-CNN –source
- YOLO (You Solely Look As soon as) (2016):
- SSD (Single Shot MultiBox Detector) (2016):
- Enhancements: Tried to stability velocity and accuracy higher than YOLO through the use of a number of function maps at completely different resolutions to seize objects at varied scales.
- Limitations: The accuracy was nonetheless not on par with the extra advanced fashions like Quicker R-CNN, particularly for smaller objects.
RetinaNet Structure
What’s ResNet?
ResNet (Residual Community), is a kind of CNN structure that solves the vanishing gradient downside, throughout coaching very deep neural networks.
As networks develop deeper, the community tends to endure from a vanishing gradient. That is when the gradients utilized in coaching grow to be so small that studying successfully stops attributable to activation capabilities squashing the gradients.
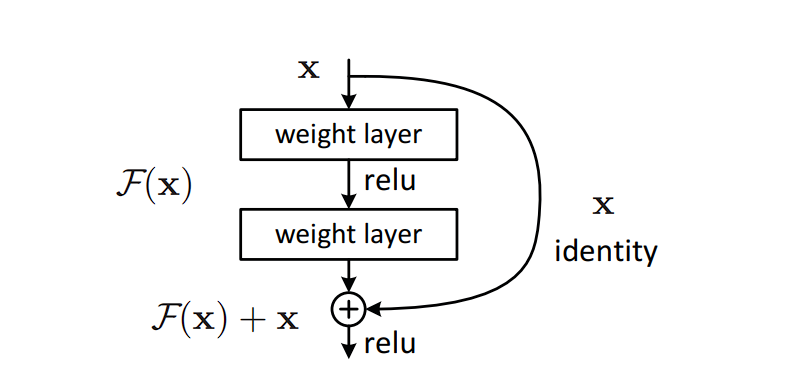
ResNet solves this downside by propagating the gradient all through the community. The output from an earlier layer is added to the output of a later layer, serving to to protect the gradient that may be misplaced in deeper networks. This enables for the coaching of networks with a depth of over 100 layers.
Characteristic Pyramid Community (FPN)
Detecting objects at completely different scales is difficult for object detection and picture segmentation. Listed here are a few of the key challenges concerned:
- Scale Variance: Objects of curiosity can fluctuate considerably in dimension, from very small to very massive, relative to the picture dimension. Conventional CNNs may excel at recognizing medium-sized objects however typically battle with very massive or very small objects attributable to fastened receptive discipline sizes.
- Lack of Element in Deep Layers: As we go deeper right into a CNN, the spatial decision of the function maps decreases attributable to pooling layers and strides in convolutions. This leads to a lack of fine-grained particulars that are essential for detecting small objects.
- Semantic Richness vs. Spatial Decision: Usually, deeper layers in a CNN seize high-level semantic info however at a decrease spatial decision. Conversely, earlier layers protect spatial particulars however comprise much less semantic info. Balancing these points is essential for efficient detection throughout completely different scales.
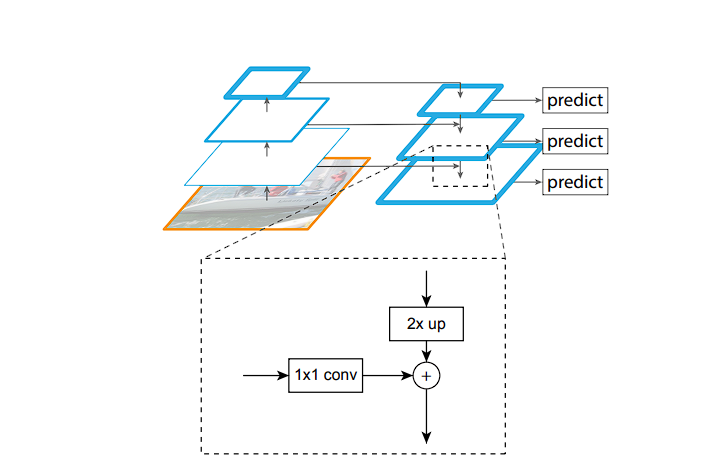
The FPN permits RetinaNet to detect objects at completely different scales successfully. Right here is the way it works.
FPN enhances the usual convolutional networks by making a top-down structure with lateral connections.
Because the enter picture progresses by way of the community, the spatial decision decreases (attributable to max pooling and convolutions), whereas the function illustration turns into richer and semantically stronger. The preliminary layers have detailed picture options, the final layers have condensed representations.
- High-Down Path: After reaching the deepest layer (smallest spatial decision however highest abstraction), the FPN constructs a top-down pathway, progressively rising spatial decision by up-sampling function maps from deeper (larger) layers within the community.
- Lateral Connections: RetinaNet leverages lateral connections to strengthen every upsampled map. These connections add options from the corresponding stage of the spine community. To make sure compatibility, 1×1 convolutions are used to scale back the channel dimensions of the spine’s function maps earlier than they’re integrated into the upsampled maps
Loss Features: Focal Loss
Object Detectors clear up classification and regression issues concurrently (class labels of the objects and their bounding field coordinates). The general loss perform is a weighted sum of the person losses of every. By minimizing this mixed loss, an object detector learns to precisely establish each the presence and the exact location of objects in photographs.
For the classification a part of object detection cross-entropy loss is used. It measures the efficiency of a classification mannequin whose output is a chance worth between 0 and 1.
RetinaNet makes use of a modified model of cross-entropy loss. It’s referred to as Focal loss. Focal Loss addresses the problem of sophistication imbalance in dense object detection duties.
How does Focal Loss work?
Normal cross-entropy loss suffers in object detection as a result of a lot of straightforward destructive examples dominate the loss perform. This overwhelms the mannequin’s skill to be taught from much less frequent objects, resulting in poor efficiency in detecting them.
Focal Loss modifies the usual cross-entropy loss by including a focusing parameter that reduces the relative loss for well-classified examples (placing extra deal with laborious, misclassified examples), and a weighting issue to handle class imbalance. The formulation for Focal Loss is:
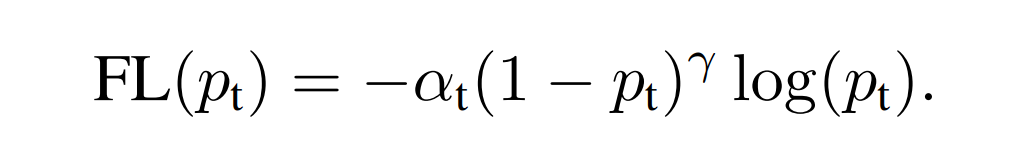
Right here,
- pt is the mannequin’s estimated chance for every class being the true class.
- αt is a balancing issue for the category (sometimes set to 0.25 inside RetinaNet)
- γ is a focusing parameter to regulate the speed at which straightforward examples are down-weighted. It’s sometimes set to 2 in RetinaNet.
- (1−pt)γ reduces the loss contribution from straightforward examples and extends the vary wherein an instance receives low loss.
Focal Loss helps enhance the efficiency of object detection fashions, significantly in circumstances the place there’s a vital imbalance between foreground and background courses, by focusing coaching on laborious negatives and giving extra weight to uncommon courses.
This makes fashions educated with Focal Loss simpler in detecting objects throughout a variety of sizes and sophistication frequencies.
Subnetworks: Classification and Bounding Field Regression
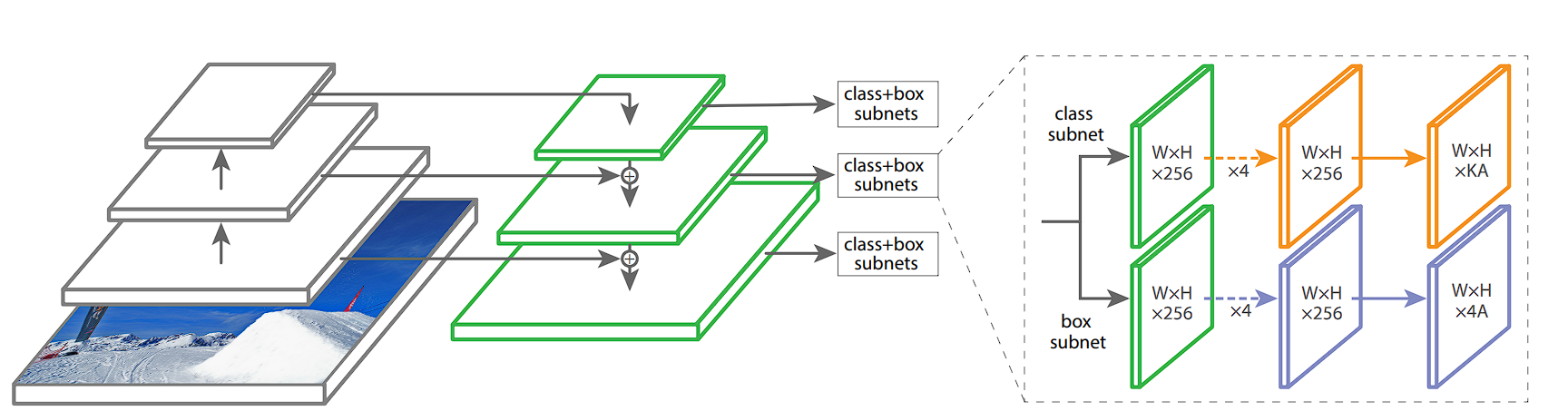
RetinaNet makes use of an FPN and two task-specific subnetworks linked to every stage of the pyramid. The FPN takes a single-scale enter and produces pyramid function maps at completely different scales. Every stage of the pyramid detects objects of various sizes.
Two Subnetworks
The 2 distinct subnetworks are hooked up to each stage of the function pyramid. Every stage of the function pyramid feeds into each subnetworks, permitting the mannequin to make predictions at a number of scales and side ratios. The subnetworks include classification and bounding field regression networks:
- Classification Subnetwork: The classification subnetwork, a small absolutely convolutional community, attaches to every stage of the function pyramid. It consists of a number of convolutional layers adopted by a sigmoid activation layer. This subnetwork predicts the chance of object presence at every spatial location for every anchor and every object class.
- Bounding Field Regression Subnetwork: This subnetwork predicts the offset changes for the anchors to higher match the precise object-bounding containers. It consists of a number of convolutional layers however ends with a linear output layer. This subnetwork predicts 4 values for every anchor, representing the changes wanted to rework the anchor right into a bounding field that higher encloses a detected object.
Functions of RetinaNet
The Way forward for RetinaNet
In conclusion, RetinaNet has established itself as an excellent single-stage object detection mannequin, providing excessive accuracy and effectivity. Its key innovation, the Focal Loss mixed with FPN, and Two Subnetworks addresses the problems of sophistication imbalances. These developments have led to RetinaNet reaching state-of-the-art accuracy on varied benchmarks.
Nevertheless, there are just a few areas wherein it may well make developments sooner or later:
- Quicker Inference Speeds: Whereas RetinaNet already provides a stability between accuracy and velocity, lots of real-time purposes comparable to autonomous driving and robotics require sooner inference time. Analysis can discover environment friendly community architectures particularly designed for resource-constrained environments like cellular gadgets.
- Multi-task Studying: RetinaNet will be prolonged for duties past object detection. By incorporating extra branches within the community, it could possibly be used for duties like object segmentation, and pose estimation, all using the efficiency of the mannequin.
- Improved Spine Architectures: RetinaNet depends on ResNet as its spine structure. Nevertheless, newer and extra environment friendly spine architectures will be explored by researchers that would obtain higher efficiency.