

Carry this venture to life
Textual content-based picture era methods have prevailed lately. Particularly, diffusion fashions have proven super success in a several types of text-to-image works. Steady diffusion can generate photorealistic pictures by giving it textual content prompts. After the success of picture synthesis fashions, the quantity of focus grew on picture modifying analysis. This analysis focuses on modifying pictures (both actual pictures or pictures synthesized by any mannequin) by offering textual content prompts on what to edit within the picture. There have been many fashions that got here out as a part of picture modifying analysis however virtually all of them deal with coaching one other mannequin to edit the picture. Even when the diffusion fashions have the flexibility to synthesize pictures, these fashions prepare one other mannequin with a view to edit the photographs.
Latest analysis on Textual content-guided Picture Enhancing by Manipulating Diffusion Path focuses on modifying pictures primarily based on the textual content immediate with out coaching one other mannequin. It makes use of the inherent capabilities of the diffusion mannequin to synthesize pictures. The picture synthesis course of path will be altered primarily based on the edit textual content immediate and it’ll generate the edited picture. Since this course of solely depends on the standard of the underlying diffusion mannequin, it would not require any extra coaching.
Fundamentals of Diffusion Fashions
The target behind the diffusion mannequin is admittedly easy. The target is to be taught to synthesize photorealistic pictures. The diffusion mannequin consists of two processes: the ahead diffusion course of and the reverse diffusion course of. Each of those diffusion processes observe the standard Markov Chain precept.
As a part of the ahead diffusion course of, the noise is added to the picture in order that it’s instantly recognizable. To try this it first samples a random picture from the dataset, say $x_0$. Now, the diffusion course of iterates for complete $T$ timesteps. At every time step $t$ ($0 < t le T$), gaussian noise is added to the picture on the earlier timestep to generate a brand new picture. i.e. $q(x_t lvert x_{t-1})$. The next picture explains the ahead diffusion course of.
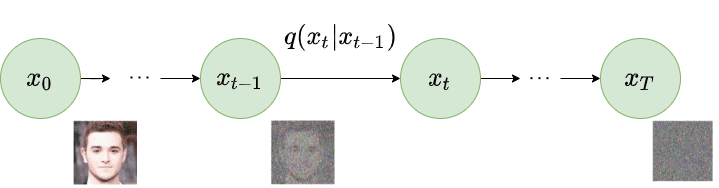
As a part of the reverse diffusion course of, the noisy picture generated as a part of the ahead diffusion course of is taken as enter. The diffusion course of once more iterates for complete $T$ timesteps. At every timestep $t$ ($0 < t le T$), the mannequin tries to take away the noise from the picture to supply a brand new picture. i.e. $p_{theta}(x_{t-1} lvert x_t)$. The next picture explains the reverse diffusion course of.
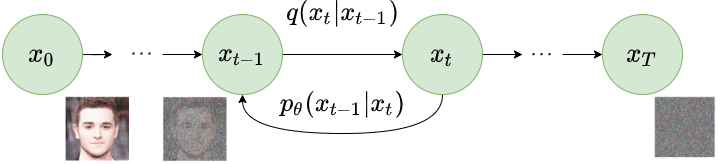
By recreating the actual picture from the noisy picture, the mannequin learns to synthesize the picture. The loss perform solely compares the noise added and noise eliminated at corresponding timesteps in every ahead and reverse diffusion course of. We’d advocate understanding the arithmetic of the diffusion fashions to know the remainder of the content material of this weblog. We extremely advocate studying this AISummer article to develop a mathematical understanding of diffusion fashions.
Moreover, CLIP (Contrastive-Picture-Language-Pretraining) can be utilized in order that the related textual content immediate can have an effect on the picture era course of. Thus, we will generate pictures primarily based on the given textual content prompts.
Manipulating Diffusion Path
Analysis accomplished as a part of the MDP paper argues that we don’t want any extra mannequin coaching to edit the photographs utilizing the diffusion method. As an alternative, we will use the pre-trained diffusion mannequin and we will change the diffusion path primarily based on the edit textual content immediate to generate the edited picture itself. By altering $q(x_t lvert x_{t-1})$ and $p_{theta}(x_{t-1} lvert x_t)$ for just a few timesteps primarily based on the edit textual content immediate, we will synthesize the edited picture. For this paper, the authors check with textual content prompts as circumstances. It implies that we will do the picture modifying job by combining the structure from the enter picture and altering related issues within the picture primarily based on supplied situation. To edit the picture primarily based on situation, conditional embedding generated from the textual content immediate is used.
The modifying course of will be carried out in two totally different circumstances primarily based on the supplied enter. The primary case is that we’re solely given an enter picture $x^A$ and the conditional embedding akin to edit job $c^B$. Our job is to generate an edited picture $x^B$ which has been generated by altering the diffusion path of $x^A$ primarily based on situation $c^B$.
The second case is that we’re given enter situation embedding $c^A$ and the conditional embedding akin to edit job $c^B$. Our job is to first generate enter picture $x^A$ primarily based on enter situation embedding $c^A$, then to generate an edited picture $x^B$ which has been generated by altering the diffusion path of $x^A$ primarily based on situation $c^B$.
If we glance intently, the primary case described above is the subset of the second case. To unify each of those right into a single framework, we would wish to foretell $c^A$ within the first case described above. If we will decide the conditional embedding $c^A$ from the enter picture $x^A$, each circumstances will be processed in the identical method for to seek out the ultimate edited picture. To seek out conditional embedding $c^A$ from enter picture $x^A$, authors have used the Null Textual content Inversion course of. This course of carries out each diffusion processes and finds the embedding $c^A$. You may consider it as predicting the sentence from which the picture $x^A$ will be generated. Please learn the paper on Null Textual content Inversion for extra details about it.
Now we have now unified each circumstances, we will now modify the diffusion path to get the edited picture. Allow us to say we chosen units of timesteps to change within the diffusion path to get the edited picture. However what ought to we modify? So, there are 4 components we will modify for specific timestep $t$ ($0 < t le T$): (1) We will modify the anticipated noise $epsilon_t$. (2) We will modify the conditional embedding $c_t$. (3) We will modify the latent picture tensor $x_t$ (4) We will modify the steering scale $beta$ which is the distinction between the anticipated noise from the edited diffusion path and the unique diffusion path. Based mostly on these 4 circumstances, the authors describe 4 totally different algorithms which will be applied to edit pictures. Allow us to check out them one after the other and perceive the arithmetic behind them.
MDP-$epsilon_t$
This case focuses on modifying solely the anticipated noise at timestep $t$ ($0 < t le T$) throughout the reverse diffusion course of. In the beginning of the reverse diffusion course of, we may have the noisy picture $x_T^A$, conditional embedding $c^A$ and conditional embedding $c^B$. We’ll iterate in reverse from timestep $T$ to $1$ to change the noise. At related timestep $t$ ($0 < t le T$), we’ll apply following modifications:
$$epsilon_t^B = epsilon_{theta}(x_t^*, c^B, t)$$
$$epsilon_t^* = (1-w_t) epsilon_t^B + w_t epsilon_t^*$$
$$x_{t-1}^* = DDIM(x_t^*, epsilon_t^*, t)$$
We first predict the noise utilizing the $epsilon_t^B$ akin to the picture within the present timestep and situation embedding $c^B$ utilizing the UNet block of the diffusion mannequin. Do not get confused by $x_t^*$ right here. Initially, we begin with $x_T^A$ at timestep $T$ however we check with the intermediate picture at timestep $t$ as $x_t^*$ as a result of it’s not solely conditioned by $c^A$ but in addition $c^B$. The identical can be relevant to $epsilon_t^*$.
After calculating $epsilon_t^B$, we will now calculate the $epsilon_t^*$ as a linear mixture of $epsilon_t^B$ (conditioned by $c^B$) and $epsilon_t^*$ (unique diffusion path). Right here, parameter $w_t$ will be set to fixed or will be scheduled for various timesteps. As soon as we calculate $epsilon_t^*$, we will apply DDIM (Denoising Diffusion Implicit Fashions) that generates a picture for the earlier timestep. This fashion, we will alter the diffusion path of a number of (or all) timesteps of the reverse diffusion course of to edit the picture.
MDP-$c$
This case focuses on modifying solely the situation ($c$) at timestep $t$ ($0 < t le T$) throughout the reverse diffusion course of. In the beginning of the reverse diffusion course of, we may have the noisy picture $x_T^A$, conditional embedding $c^A$ and conditional embedding $c^B$. At every step, we’ll modify the mixed situation embedding $c_t^*$. At related timestep $t$ ($0 < t le T$), we’ll apply following modifications:
$$c_t^* = (1-w_t)c^B + w_tc_t^*$$
$$epsilon_t^* = epsilon_{theta}(x_t^*, c_t^*, t)$$
$$x_{t-1}^* = DDIM(x_t^*, epsilon_t^*, t)$$
We first calculate the mixed embedding $c_t^*$ for timestep $t$ by taking a linear mixture of $c^B$ (situation embedding for edit textual content immediate) and $c_t^*$ (situation embedding for unique diffusion steps). Right here, parameter $w_t$ will be set to fixed or will be scheduled for various timesteps. Within the second step, we predict $epsilon_t^*$ utilizing this newly calculated situation embedding $c_t^*$. The final step generates a picture for the earlier timestep utilizing DDIM.
MDP-$x_t$
This case focuses on modifying solely the generated picture itself ($x_{t-1}$) at timestep $t$ ($0 < t le T$) throughout the reverse diffusion course of. In the beginning of the reverse diffusion course of, we may have the noisy picture $x_T^A$, conditional embedding $c^A$ and conditional embedding $c^B$. At every step, we’ll modify the generated picture $x_{t-1}^*$. At related timestep $t$ ($0 < t le T$), we’ll apply following modifications:
$$epsilon_t^B = epsilon_{theta}(x_t^*, c^B, t)$$
$$x_{t-1}^* = DDIM(x_t^*, epsilon_t^B, t)$$
$$x_{t-1}^* = (1-w_t) x_{t-1}^{*} + w_tx_{t-1}^A$$
We first predict the noise $epsilon_t^B$ akin to the situation embedding $c^B$. Then, we generate the picture $x_{t-1}^*$ utilizing DDIM. Eventually, we take a linear mixture of $x_{t-1}^{B*}$ (conditioned by $c^B$) and $x_{t-1}^A$ (unique diffusion path). Right here, parameter $w_t$ will be set to fixed or will be scheduled for various timesteps.
MDP-$beta$
This case focuses on modifying the steering scale by calculating the anticipated noise of each circumstances and taking a linear mixture of it. In the beginning of the reverse diffusion course of, we may have the noisy picture $x_T^A$, conditional embedding $c^A$ and conditional embedding $c^B$. At every step, we’ll modify the generated picture $epsilon_t^*$. At related timestep $t$ ($0 < t le T$), we’ll apply following modifications:
$$epsilon_t^A = epsilon_{theta}(x_t^*, c^A, t)$$
$$epsilon_t^B = epsilon_{theta}(x_t^*, c^B, t)$$
$$epsilon_t^* = (1-w_t) epsilon_t^B + w_t epsilon_t^A$$
$$x_{t-1}^* = DDIM(x_t^*, epsilon_t^*, t)$$
We first predict the noise $epsilon_t^A$ and $epsilon_t^B$ corresponding to 2 situation embeddings $c^A$ and $c^B$ respectively. We then take a linear mixture of these two to calculate $epsilon_t^*$. Right here, parameter $w_t$ will be set to fixed or will be scheduled for various timesteps. The final step generates a picture for the earlier timestep utilizing DDIM.
Mannequin Efficiency & Comparisons
All the 4 algorithms outlined above are capable of generate good-quality edited pictures that observe the edit textual content immediate. The outcomes obtained by these algorithms are in contrast with Immediate-to-Immediate picture modifying mannequin. Beneath outcomes are supplied within the analysis paper.

The outcomes of those algorithms are similar to different picture modifying fashions which make use of coaching. The authors have argued that MDP-$epsilon_t$ works finest amongst all 4 algorithms when it comes to native and world modifying capabilities.
Attempt it your self
Carry this venture to life
Allow us to now stroll by means of how one can do this mannequin. The authors have open-sourced the code for less than the MDP-$epsilon_t$ algorithm. However primarily based on the detailed descriptions, we have now applied all 4 algorithms and the Gradio demo on this GitHub Repository. The very best half about MDP mannequin is that it would not require any coaching. We simply must obtain the pre-trained Steady Diffusion mannequin. However don’t fret, we have now taken care of this within the code. You’ll not must manually fetch the checkpoints. For demo functions, allow us to get this code working in a Gradient Pocket book right here on Paperspace. To navigate to the codebase, click on on the “Run on Gradient” button above or on the prime of this weblog.
Setup
The file installations.sh comprises all the required code to put in required dependencies. This methodology would not require any coaching however the inference shall be very pricey and time-consuming on the CPU since diffusion fashions are too heavy. Thus, it’s good to have CUDA assist. Additionally, you could require totally different model of torch primarily based on the model of CUDA. In case you are working this on Paperspace, then the default model of CUDA is 11.6 which is appropriate with this code. In case you are working it some other place, please examine your CUDA model utilizing nvcc --version. If the model differs from ours, you could need to change variations of PyTorch libraries within the first line of installations.sh by taking a look at compatibility desk.
To put in all of the dependencies, run the beneath command:
bash installations.sh
MDP would not require any coaching. It makes use of the secure diffusion mannequin and modifications the reverse diffusion path primarily based on the edit textual content immediate. Thus, it allows synthesizing the edited picture. We now have applied all 4 algorithms talked about within the paper and ready two kinds of Gradio demos to check out the mannequin.
Actual-Picture Enhancing Demo
As a part of this demo, you may edit any picture primarily based on the textual content immediate. With this, you may enter any picture, an edit textual content immediate, choose the algorithm that you simply need to apply for modifying, and modify the required algorithm parameters. The Gradio app will run the required algorithm by taking supplied inputs with specified parameters and can generate the edited picture.
To run this the Gradio app, run the beneath command:
gradio app_real_image_editing.py
When you run the above command, the Gradio app will generate a hyperlink that you would be able to open to launch the app. The beneath video exhibits how one can work together with the app.
Actual-Picture Enhancing
Artificial-Picture Enhancing Demo
As a part of this demo, you may first generate a picture utilizing a textual content immediate after which you may edit that picture utilizing one other textual content immediate. With this, you may enter the preliminary textual content immediate to generate a picture, an edit textual content immediate, choose the algorithm that you simply need to apply for modifying and modify the required algorithm parameters. The Gradio app will run the required algorithm by taking supplied inputs with specified parameters and can generate the edited picture.
To run this Gradio app, run the beneath command:
gradio app_synthetic_image_editing.py
When you run the above command, the Gradio app will generate a hyperlink that you would be able to open to launch the app. The beneath video exhibits how one can work together with the app.
Artificial-Picture Enhancing
Conclusion
We will edit the picture by altering the trail of the reverse diffusion course of in a pre-trained Steady Diffusion mannequin. MDP makes use of this precept and allows modifying a picture with out coaching any extra mannequin. The outcomes are similar to different picture modifying fashions which use coaching procedures. On this weblog, we walked by means of the fundamentals of the diffusion mannequin, the target & structure of the MDP mannequin, in contrast the outcomes obtained from 4 totally different MDP algorithm variants and mentioned methods to arrange the surroundings & check out the mannequin utilizing the Gradio demos on Gradient Pocket book.
Remember to try our repo and contemplate contributing to it!