

One of many major points for laptop imaginative and prescient (CV) builders is to keep away from overfitting. That’s a scenario when your CV mannequin works nice on the coaching information however is inefficient in predicting the take a look at information. The reason being that your mannequin is overfitting. To repair this drawback you want regularization, most frequently finished by Batch Normalization (BN).
The regularization strategies allow CV fashions to converge sooner and forestall over-fitting. Subsequently, the training course of turns into extra environment friendly. There are a number of methods for regularization and right here, we current the idea of batch normalization.
About us: Viso Suite is the pc imaginative and prescient resolution for enterprises. By masking your entire ML pipeline in an easy-to-use no-code interface, groups can simply combine laptop imaginative and prescient into their enterprise workflows. To learn the way your workforce can get began with laptop imaginative and prescient, guide a demo of Viso Suite.
What’s Batch Normalization?
Batch normalization is a technique that may improve the effectivity and reliability of deep neural community fashions. It is rather efficient in coaching convolutional neural networks (CNN), offering sooner neural community convergence. As a supervised studying methodology, BN normalizes the activation of the inner layers throughout coaching. The subsequent layer can analyze the info extra successfully by resetting the output distribution from the earlier layer.
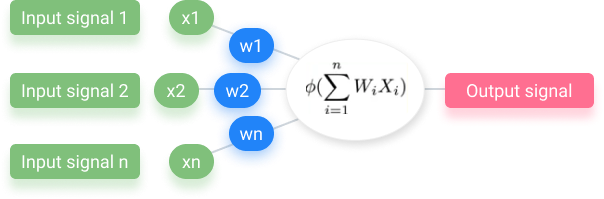
Inner covariate shift denotes the impact that parameters change within the earlier layers have on the inputs of the present layer. This makes the optimization course of extra advanced and slows down the mannequin convergence.
In batch normalization – the activation worth doesn’t matter, making every layer study individually. This strategy results in sooner studying charges. Additionally, the quantity of knowledge misplaced between processing phases could lower. That may present a major enhance within the precision of the community.
How Does Batch Normalization Work?
The batch normalization methodology enhances the effectivity of a deep neural community by discarding the batch imply and dividing it into the batch normal deviation. The gradient descent methodology scales the outputs by a parameter if the loss operate is massive. Subsequently – it updates the weights within the subsequent layer.
Batch normalization goals to enhance the coaching course of and enhance the mannequin’s generalization functionality. It reduces the necessity for exact initialization of the mannequin’s weights and allows increased studying charges. That may speed up the coaching course of.
Batch normalization multiplies its output by a regular deviation parameter (γ). Additionally, it provides a imply parameter (beta) when utilized to a layer. As a result of coaction between batch normalization and gradient descent, information could also be disarranged when adjusting these two weights for every output. Consequently, a discount of information loss and improved community stability might be achieved by establishing the opposite related weights.
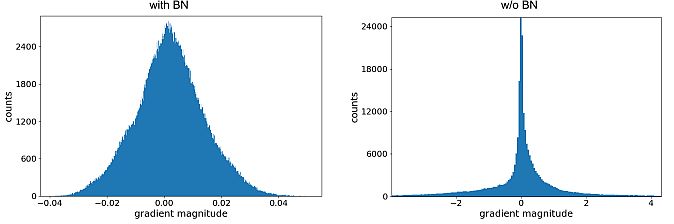
Generally, CV consultants apply batch normalization earlier than the layer’s activation. It’s typically used along with different regularization features. Additionally, deep studying strategies, together with picture classification, pure language processing, and machine translation make the most of batch normalization.
Batch Normalization in CNN Coaching
Inner Covariate Shift Discount
Google researchers Sergey Ioffe and Christian Szegedy defined the internal covariate shift as a change within the order of community activations as a result of change in community parameters throughout coaching. To enhance the coaching, they aimed to scale back the inner covariate shift. Their objective was to extend the coaching velocity by optimizing the distribution of layer inputs as coaching progressed.
Earlier researchers (Lyu, Simoncelli, 2008) utilized statistics over a single coaching instance, or, within the case of picture networks, over completely different function maps at a given location. They wished to protect the data within the community. Subsequently, they normalized the activations in a coaching pattern relative to the statistics of your entire coaching dataset.
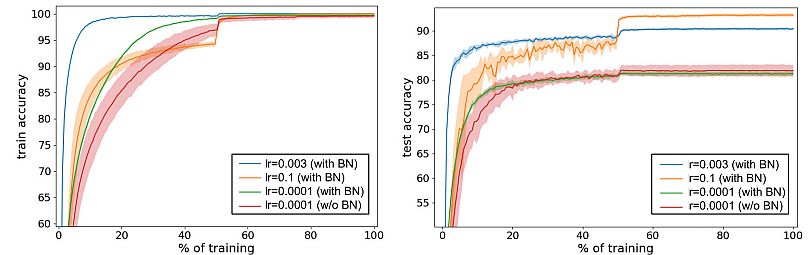
The gradient descent optimization doesn’t have in mind the truth that the normalization will occur. Ioffe and Szegedy wished to make sure that the community at all times produces activations for parameter values. As a result of gradient loss, they utilized the normalization and calculated its dependence on the mannequin parameters.
Coaching and Inference with Batch-Normalized CNNs
Coaching will be extra environment friendly by normalizing activations that rely on a mini-batch, however it isn’t essential throughout inference. (Mini-batch is a portion of the coaching dataset). The researchers wanted the output to rely solely on the enter. By making use of shifting averages, they tracked the accuracy of a mannequin, whereas it skilled.
Normalization will be finished by making use of a linear transformation to every activation, as means and variances are fastened throughout inference. To batch-normalize a CNN, researchers specified a subset of activations and inserted the BN rework for every (Algorithm under).
Authors thought-about a mini-batch B of dimension m. They carried out normalization to every activation independently, by specializing in a selected activation x(ok) and omitting ok for readability. They obtained m values for every activation within the mini-batch:
B = {x1…m}
They denoted normalized values as x1…m, and their linear transformations had been y1…m. Researchers have outlined the rework
BN γ,β : x1…m → y1…m
to be the Batch Normalizing rework. They carried out the BN Rework algorithm given under. Within the algorithm, σ is a continuing added to the mini-batch variance for numerical stability.

The BN rework has been added to a community to govern all activations. By y = BN γ,β(x), researchers indicated that the parameters γ and β needs to be discovered. Nonetheless, they famous that the BN rework doesn’t independently course of the activation in every coaching instance.
Consequently, BN γ,β(x) relies upon each on the coaching instance and the opposite samples within the mini-batch. They handed the scaled and shifted values y to different community layers. The normalized activations xb had been inside to the transformation, however their presence was essential. The distributions of values of all xb had the anticipated worth of 0 and the variance of 1.
All layers that beforehand obtained x because the enter – now obtain BN(x). Batch normalization permits for the coaching of a mannequin utilizing batch gradient descent, or stochastic gradient descent with a mini-batch dimension m > 1.
Batch-Normalized Convolutional Networks
Szegedy et al., (2014) utilized batch normalization to create a brand new Inception community, skilled on the ImageNet classification job. The community had numerous convolutional and pooling layers.
- They included a SoftMax layer to foretell the picture class, out of 1000 potentialities. Convolutional layers embody ReLU because the nonlinearity.
- The principle distinction between their CNN was that the 5 × 5 convolutional layers had been changed by two consecutive layers of three × 3 convolutions.
- Through the use of batch normalization researchers matched the accuracy of Inception in lower than half the variety of coaching steps.
- With slight modifications, they considerably elevated the coaching velocity of the community. BN-x5 wanted 14 occasions fewer steps than Inception to succeed in 72.2% accuracy.
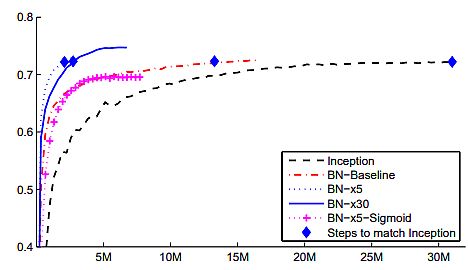
By growing the training charge additional (BN-x30) they precipitated the mannequin to coach slower at the beginning. Nonetheless, it was capable of attain the next last accuracy. It reached 74.8% after 6·106 steps, i.e. 5 occasions fewer steps than required by Inception.
Advantages of Batch Normalization
Batch normalization brings a number of advantages to the training course of:
- Greater studying charges. The coaching course of is quicker since batch normalization allows increased studying charges.
- Improved generalization. BN reduces overfitting and improves the mannequin’s generalization skill. Additionally, it normalizes the activations of a layer.
- Stabilized coaching course of. Batch normalization reduces the inner covariate shift occurring throughout coaching, bettering the steadiness of the coaching course of. Thus, it makes it simpler to optimize the mannequin.
- Mannequin Regularization. Batch normalization treats the coaching instance along with different examples within the mini-batch. Subsequently, the coaching community not produces deterministic values for a given coaching instance.
- Lowered want for cautious initialization. Batch normalization decreases the mannequin’s dependence on the preliminary weights, making it simpler to coach.
What’s Subsequent?
Batch normalization affords an answer to handle challenges with coaching deep neural networks for laptop programs. By normalizing the activations of every layer, batch normalization permits for smoother and extra steady optimization, leading to sooner convergence and improved generalization efficiency. As a result of it will probably mitigate points like inside covariate shifts it allows the event of extra strong and environment friendly neural community architectures.
For different related matters in laptop imaginative and prescient, try our different blogs: