

Carry this venture to life
Object detection stays one of the crucial fashionable and rapid use instances for AI expertise. Main the cost for the reason that launch of the primary model by Joseph Redman et al. with their seminal 2016 work, “You Solely Look As soon as: Unified, Actual-Time Object Detection”, has been the YOLO suite of fashions. These object detection fashions have paved the way in which for analysis into utilizing DL fashions to carry out realtime identification of the topic and placement of entities inside a picture.
Final yr we checked out and benchmarked two earlier iterations of this mannequin framework, YOLOv6 and YOLOv7, and confirmed methods to step-by-step fine-tune a customized model of YOLOv7 in a Gradient Pocket book.
On this article, we’ll revisit the fundamentals of those strategies, talk about what’s new within the newest launch YOLOv8 from Ultralytics, and stroll by the steps for fine-tuning a customized YOLOv8 mannequin utilizing RoboFlow and Paperspace Gradient utilizing the brand new Ultralytics API. On the finish of this tutorial, customers ought to have the ability to rapidly and simply match the YOLOv8 mannequin to any set of labeled photos in fast succession.
How does YOLO work?
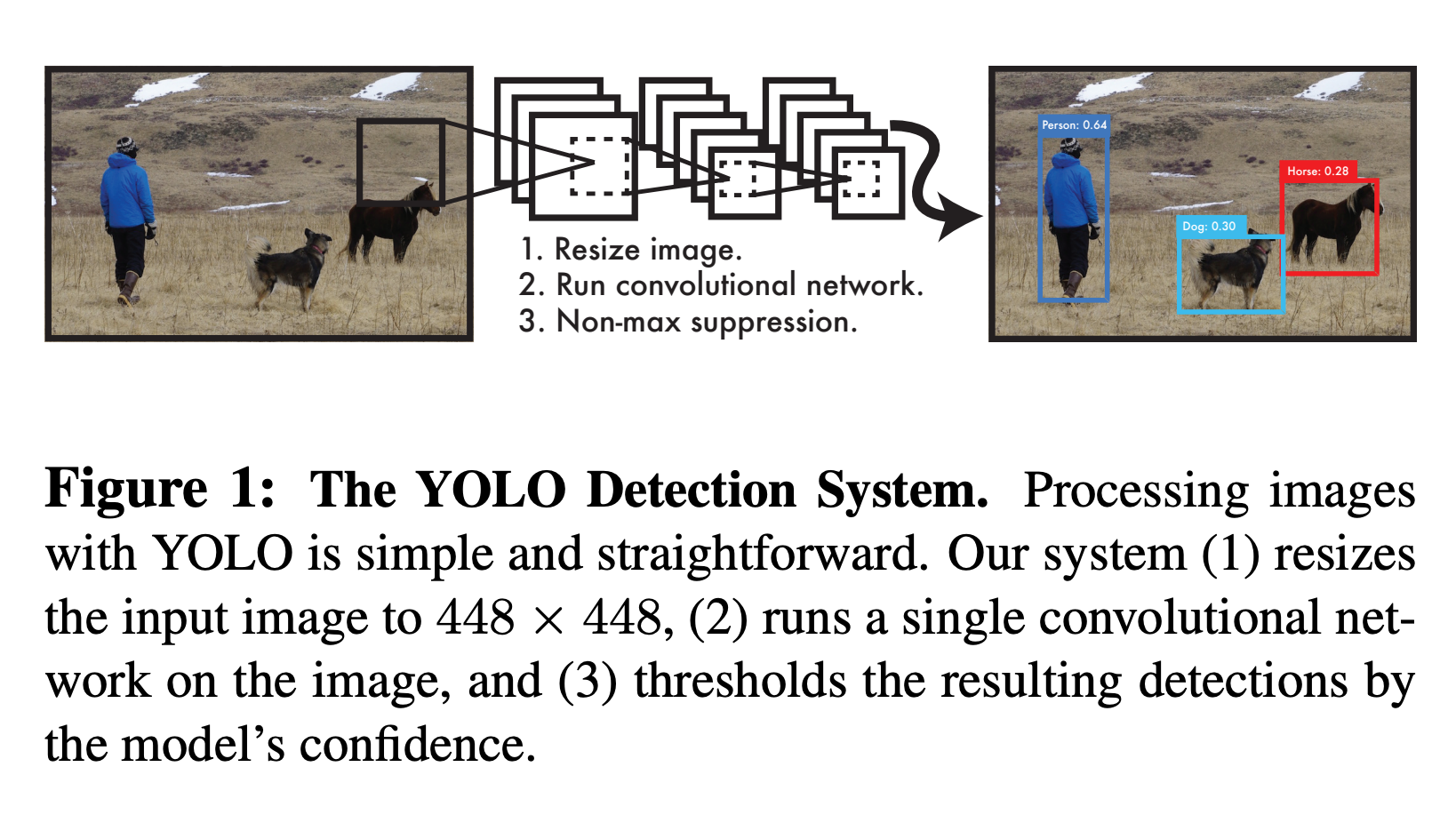
To start out, let’s talk about the fundamentals of how YOLO works. Here’s a brief quote breaking down the sum of the mannequin’s performance from the unique YOLO paper:
“A single convolutional community concurrently predicts a number of bounding containers and sophistication possibilities for these containers. YOLO trains on full photos and instantly optimizes detection efficiency. This unified mannequin has a number of advantages over conventional strategies of object detection.” (Supply)
As said above, the mannequin is able to predicting the situation and figuring out the topic of a number of entities in a picture, supplied it has been educated to acknowledged these options earlier than. It does this in a single stage by separating the picture into N grids, every of dimension s*s. These areas are concurrently parsed to detect and localize any objects contained inside. The mannequin then predicts bounding field coordinates, B, in every grid with a label and prediction rating for the thing contained inside.
Placing these all collectively, we get a expertise able to every of the duties of object classification, object detection, and picture segmentation. For the reason that primary expertise underlying YOLO stays the identical, we are able to infer that is additionally true for YOLOv8. For a extra full breakdown of how YOLO works, you should definitely take a look at our earlier articles on YOLOv5 and YOLOv7, our benchmarks with YOLOv6 and YOLOv7, and the unique YOLO paper right here.
What’s new in YOLOv8?
Since YOLOv8 was solely simply launched, the paper protecting the mannequin shouldn’t be but obtainable. The authors intend to launch it quickly, however for now, we are able to solely go off of the official launch submit, extrapolate for ourselves the adjustments from the commit historical past, and attempt to establish for ourselves the extent of the adjustments made between YOLOv5 and YOLOv8.
Structure
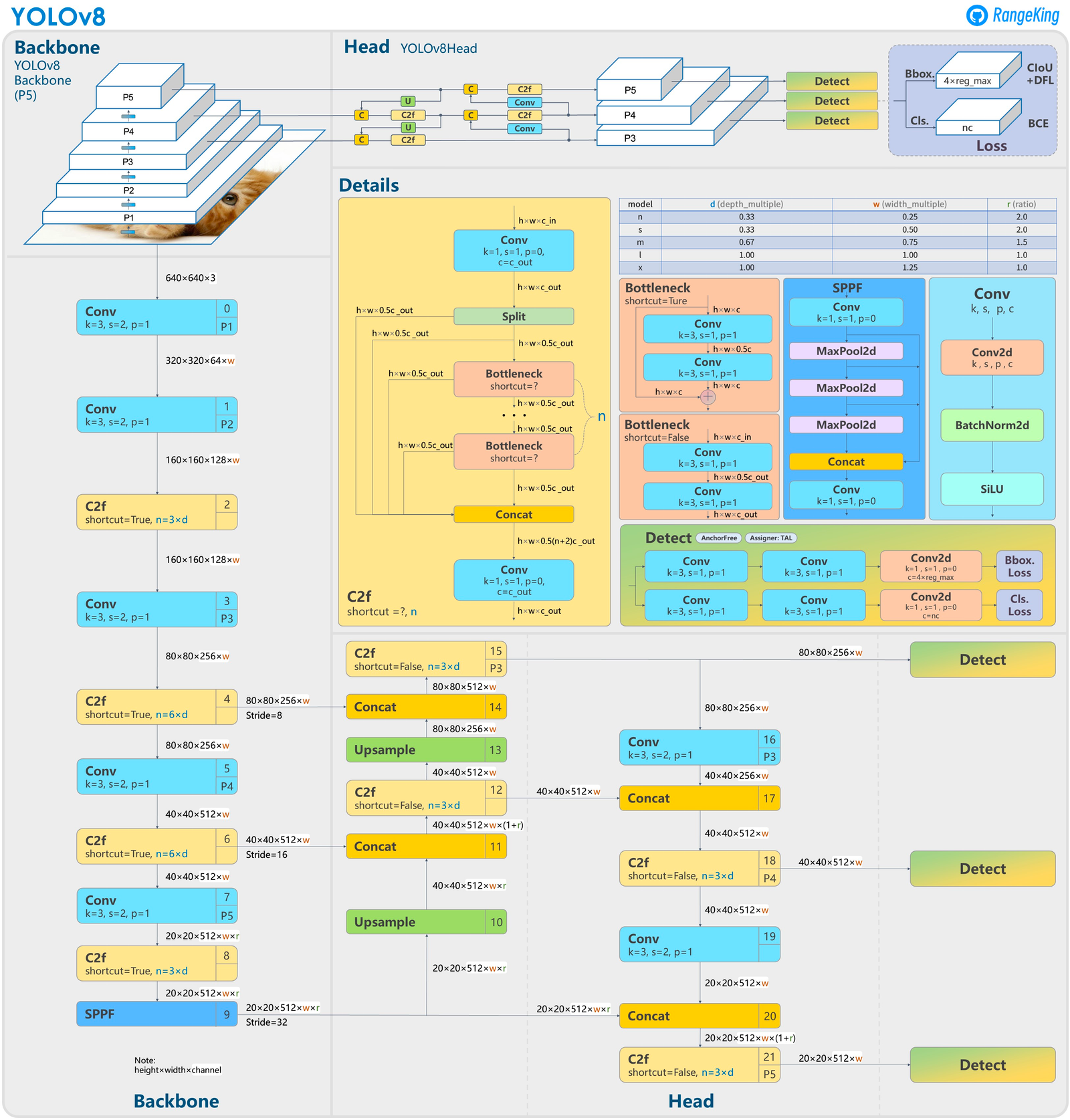
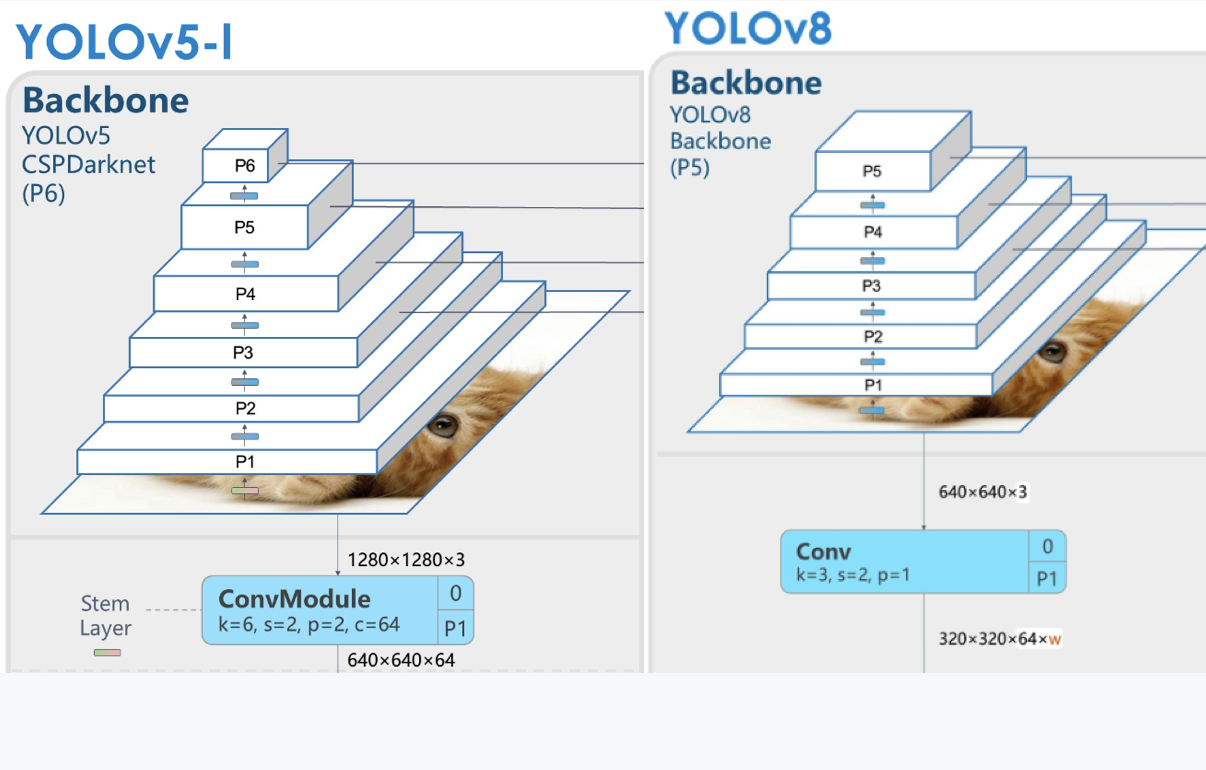
In keeping with the official launch, YOLOv8 includes a new spine community, anchor-free detection head, and loss operate. Github consumer RangeKing has shared this define of the YOLOv8 mannequin infrastructure displaying the up to date mannequin spine and head constructions. In keeping with a comparability of this diagram with a comparable examination of YOLOv5, RangeKing recognized the next adjustments of their submit:
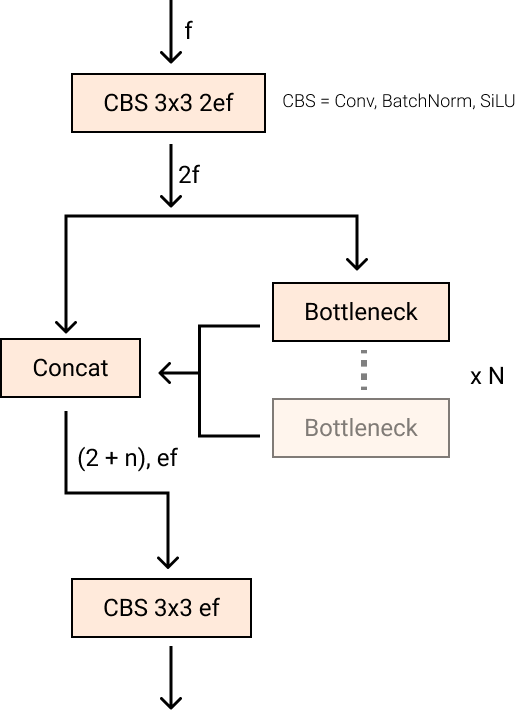
C2f module, credit score to RoboFlow (Supply)- They changed the
C3module with theC2fmodule. InC2f, all of the outputs from theBottleneck(the 2 3×3convswith residual connections) are concatenated, however inC3solely the output of the finalBottleneckwas used. (Supply)
- They changed the primary
6x6 Convwith a3x3 Convblock within theSpine - They deleted two of the
Convs (No.10 and No.14 within the YOLOv5 config)
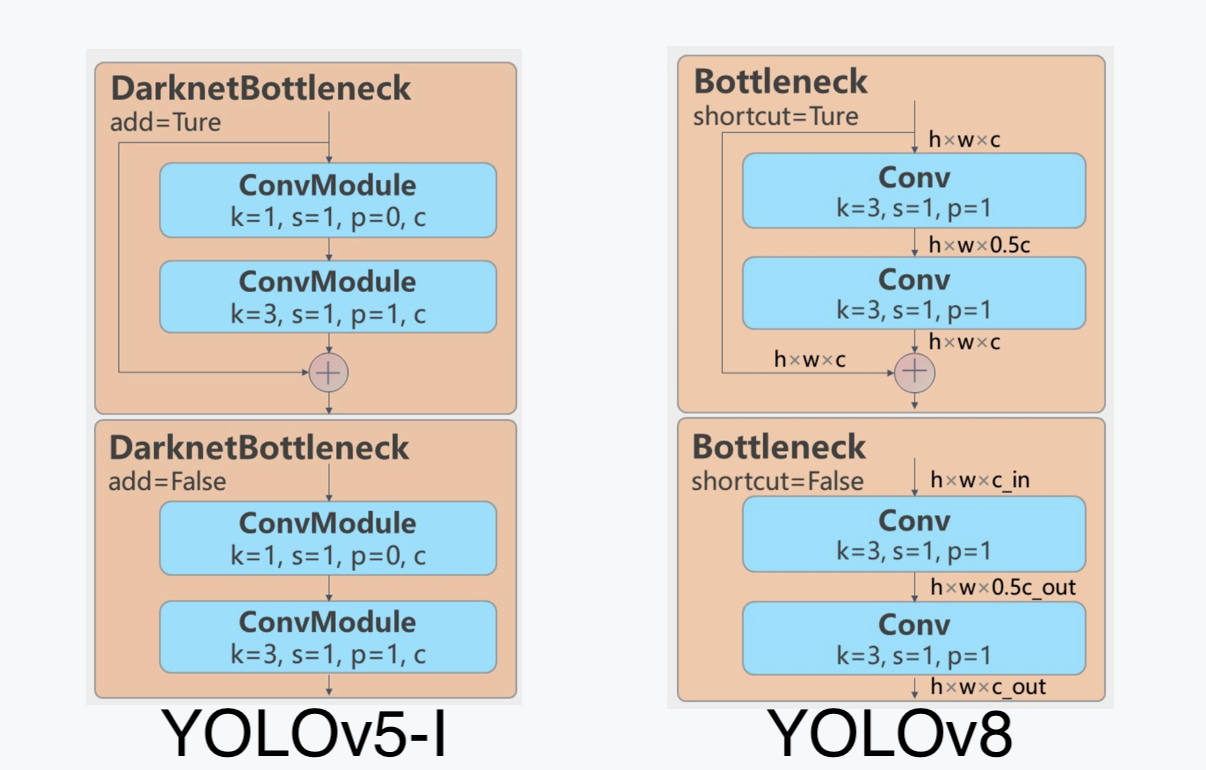
- They changed the primary
1x1 Convwith a3x3 Convwithin theBottleneck. - They switched to utilizing a decoupled head, and deleted the
objectnessdepartment
Verify again right here after the paper for YOLOv8 is launched, we’ll replace this part with further info. For a radical breakdown of the adjustments mentioned above, please take a look at the RoboFlow article protecting the discharge of YOLOv8
Accessibility
Along with the previous methology of cloning the Github repo, and establishing the surroundings manually, customers can now entry YOLOv8 for coaching and inference utilizing the brand new Ultralytics API. Take a look at the Coaching your mannequin part under for particulars on establishing the API.
Anchor free bounding containers
In keeping with Ultralytics companion RoboFlow’s weblog submit protecting YOLOv8, YOLOv8 now options the anchor free bounding containers. Within the unique iterations of YOLO, customers have been required to manually establish these anchor containers with a purpose to facilitate the thing detection course of. These predefined bounding containers of predetermined dimension and peak seize the size and side ratio of particular object courses within the information set. Calculating the offset from these boundaries to the expected object helps the mannequin higher establish the situation of the thing.
With YOLOv8, these anchor containers are routinely predicted on the heart of an object.
Stopping the Mosaic Augmentation earlier than the tip of coaching
At every epoch throughout coaching, YOLOv8 sees a barely completely different model of the photographs it has been supplied. These adjustments are referred to as augmentations. Considered one of these, Mosaic augmentation, is the method of mixing 4 photos, forcing the mannequin to be taught the identities of the objects in new areas, partially blocking one another by occlusion, with larger variation on the encircling pixels. It has been proven that utilizing this all through the complete coaching regime could be detrimental to the prediction accuracy, so YOLOv8 can cease this course of throughout the last epochs of coaching. This permits for the optimum coaching sample to be run with out extending to the complete run.
Effectivity and accuracy
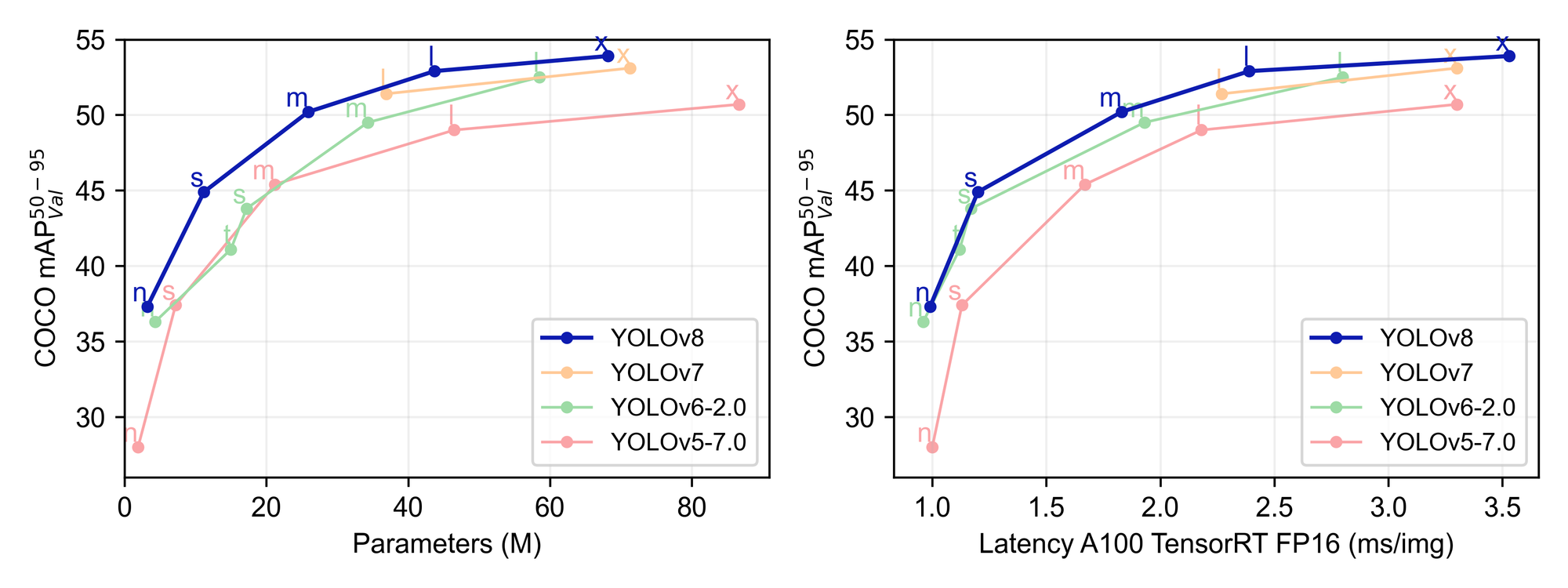
The principle cause we’re all listed here are the massive boosts to efficiency accuracy and effectivity throughout each inference and coaching. The authors at Ultralytics have supplied us with some helpful pattern information which we are able to use to match the brand new launch with different variations of YOLO. We will see from the plot above that YOLOv8 outperforms YOLOv7, YOLOv6-2.0, and YOLOv5-7.0 by way of imply Common Precision, dimension, and latency throughout coaching.
| Mannequin | dimension (pixels) |
mAPval 50-95 |
Velocity CPU ONNX (ms) |
Velocity A100 TensorRT (ms) |
params (M) |
FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
Of their respective Github pages, we are able to discover the statistical comparability tables for the completely different sized YOLOv8 fashions. As we are able to see from the desk above, the mAP will increase as the scale of the parameters, velocity, and FLOPs improve. The most important YOLOv5 mannequin, YOLOv5x, achieved a most mAP worth of fifty.7. The two.2 unit improve in mAP represents a big enchancment in capabilities. That is coserved throughout all mannequin sizes, with the newer YOLOv8 fashions constantly outperforming YOLOv5, as proven by the info under.
| Mannequin | dimension (pixels) |
mAPval 50-95 |
mAPval 50 |
Velocity CPU b1 (ms) |
Velocity V100 b1 (ms) |
Velocity V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
Total, we are able to see that YOLOv8 represents a big step up from YOLOv5 and different competing frameworks.
Fantastic-tuning YOLOv8
Carry this venture to life
The method for fine-tuning a YOLOv8 mannequin could be damaged down into three steps: creating and labeling the dataset, coaching the mannequin, and deploying it. On this tutorial, we’ll cowl the primary two steps intimately, and present methods to use our new mannequin on any incoming video file or stream.
Establishing your dataset
We’re going to be recreating the experiment we used for YOLOv7 for the aim of evaluating the 2 fashions, so we will probably be returning to the Basketball dataset on Roboflow. Take a look at the “Establishing your customized datasets part” of the earlier article for detailed instruction for establishing the dataset, labeling it, and pulling it from RoboFlow into our Pocket book.
Since we’re utilizing a beforehand made dataset, we simply want to tug the info in for now. Under is the command used to tug the info right into a Pocket book surroundings. Use this similar course of in your personal labeled dataset, however change the workspace and venture values with your personal to entry your dataset in the identical method.
Make sure you change the API key to your personal if you wish to use the script under to comply with the demo within the Pocket book.
!pip set up roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="")
venture = rf.workspace("james-skelton").venture("ballhandler-basketball")
dataset = venture.model(11).obtain("yolov8")
!mkdir datasets
!mv ballhandler-basketball-11/ datasets/Coaching your mannequin
With the brand new Python API, we are able to use the ultralytics library to facilitate the entire work inside a Gradient Pocket book surroundings. We’ll construct our YOLOv8n mannequin from scratch utilizing the supplied config and weights. We’ll then fine-tune it utilizing the dataset we simply loaded into the surroundings, utilizing the mannequin.practice() methodology.
from ultralytics import YOLO
# Load a mannequin
mannequin = YOLO("yolov8n.yaml") # construct a brand new mannequin from scratch
mannequin = YOLO("yolov8n.pt") # load a pretrained mannequin (really useful for coaching)
# Use the mannequin
outcomes = mannequin.practice(information="datasets/ballhandler-basketball-11/information.yaml", epochs=10) # practice the mannequinTesting the mannequin
outcomes = mannequin.val() # consider mannequin efficiency on the validation setWe will set our new mannequin to guage on the validation set utilizing the mannequin.val() methodology. This can output a pleasant desk displaying how our mannequin carried out into the output window. Seeing as we solely educated right here for ten epochs, this comparatively low mAP 50-95 is to be anticipated.

From there, it is easy to submit any picture. It can output the expected values for the bounding containers, overlay these containers to the picture, and add to the ‘runs/detect/predict’ folder.
from ultralytics import YOLO
from PIL import Picture
import cv2
# from PIL
im1 = Picture.open("belongings/samp.jpeg")
outcomes = mannequin.predict(supply=im1, save=True) # save plotted photos
print(outcomes)
show(Picture.open('runs/detect/predict/image0.jpg'))We’re left with the predictions for the bounding containers and their labels, printed like this:
[Ultralytics YOLO <class 'ultralytics.yolo.engine.results.Boxes'> masks
type: <class 'torch.Tensor'>
shape: torch.Size([6, 6])
dtype: torch.float32
+ tensor([[3.42000e+02, 2.00000e+01, 6.17000e+02, 8.38000e+02, 5.46525e-01, 1.00000e+00],
[1.18900e+03, 5.44000e+02, 1.32000e+03, 8.72000e+02, 5.41202e-01, 1.00000e+00],
[6.84000e+02, 2.70000e+01, 1.04400e+03, 8.55000e+02, 5.14879e-01, 0.00000e+00],
[3.59000e+02, 2.20000e+01, 6.16000e+02, 8.35000e+02, 4.31905e-01, 0.00000e+00],
[7.16000e+02, 2.90000e+01, 1.04400e+03, 8.58000e+02, 2.85891e-01, 1.00000e+00],
[3.88000e+02, 1.90000e+01, 6.06000e+02, 6.58000e+02, 2.53705e-01, 0.00000e+00]], gadget="cuda:0")]These are then utilized to the picture, like the instance under:
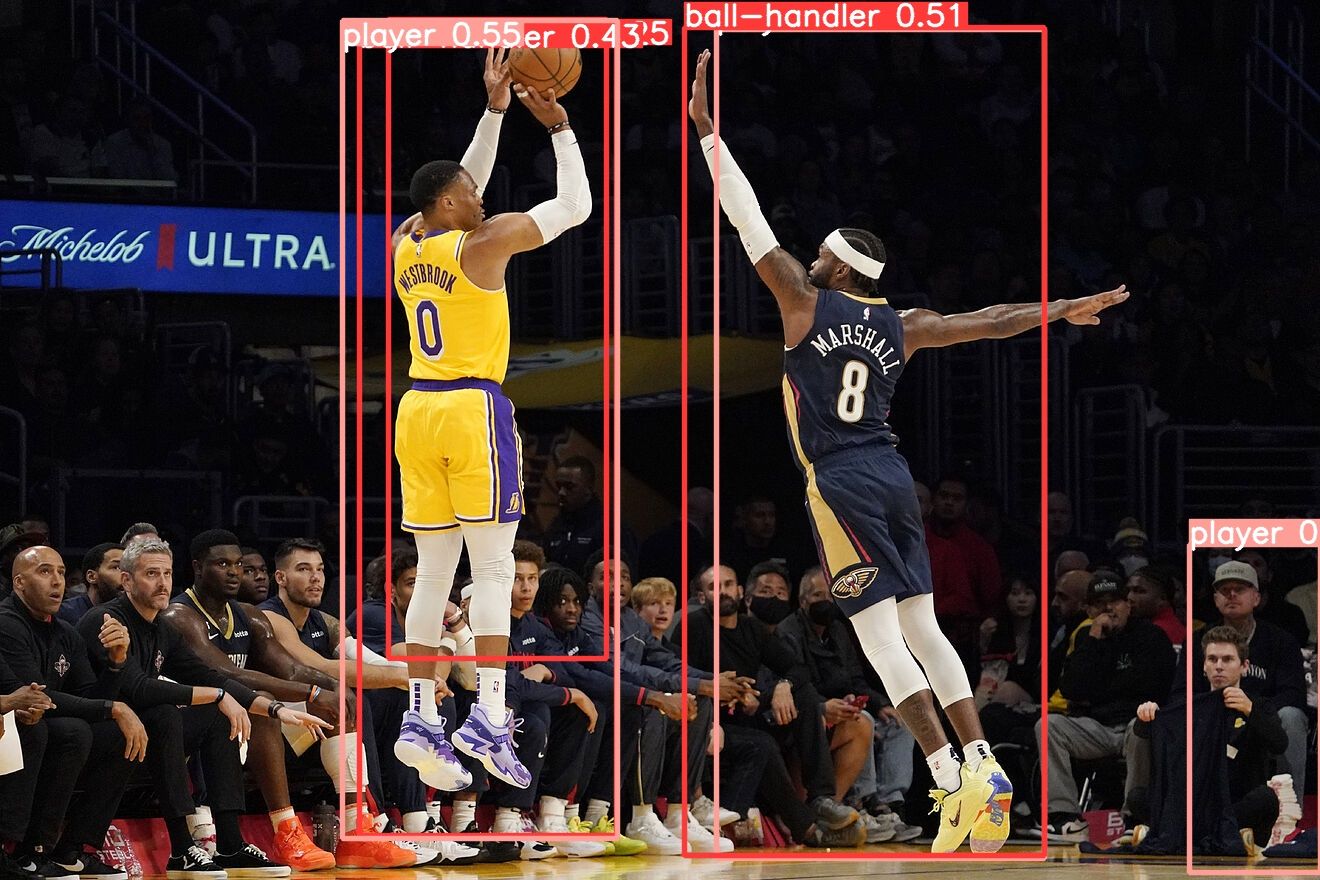
As we are able to see, our flippantly educated mannequin exhibits that it might acknowledge the gamers on the court docket from the gamers and spectators on the facet of the court docket, with one exception within the nook. Extra coaching is nearly positively required, however it’s simple to see that the mannequin in a short time gained an understanding of the duty.
If we’re happy with our mannequin coaching, we are able to then export the mannequin within the desired format. On this case, we’ll export an ONNX model.
success = mannequin.export(format="onnx") # export the mannequin to ONNX formatClosing ideas
On this tutorial, we examined what’s new in Ultralytics superior new mannequin, YOLOv8, took a peak beneath the hood on the adjustments to the structure in comparison with YOLOv5, after which examined the brand new mannequin’s Python API performance by testing our Ballhandler dataset on the brand new mannequin. We have been in a position to present that this represents a big step ahead for simplifying the method of fine-tuning a YOLO object detection mannequin, and demonstrated the capabilities of the mannequin for discerning the possession of the ball in an NBA recreation utilizing an in-game picture from the