

Object detection is a crucial process in laptop imaginative and prescient that identifies and locates the place an object is in a picture, by drawing bounding bins across the detected objects. The significance of object detection can’t be mentioned sufficient. It permits for functions in quite a lot of fields, for e.g., it powers autonomous driving, drones, illness detection, and automatic safety surveillance.
On this weblog, we’ll look deeply into FCOS, an revolutionary and widespread object detection mannequin utilized to varied fields. However earlier than diving into the improvements introduced by FCOS, it is very important perceive the varieties of object detection fashions accessible.
Sorts of Object Detection Fashions
Object detection fashions will be divided into two classes, one-stage and two-stage detectors.
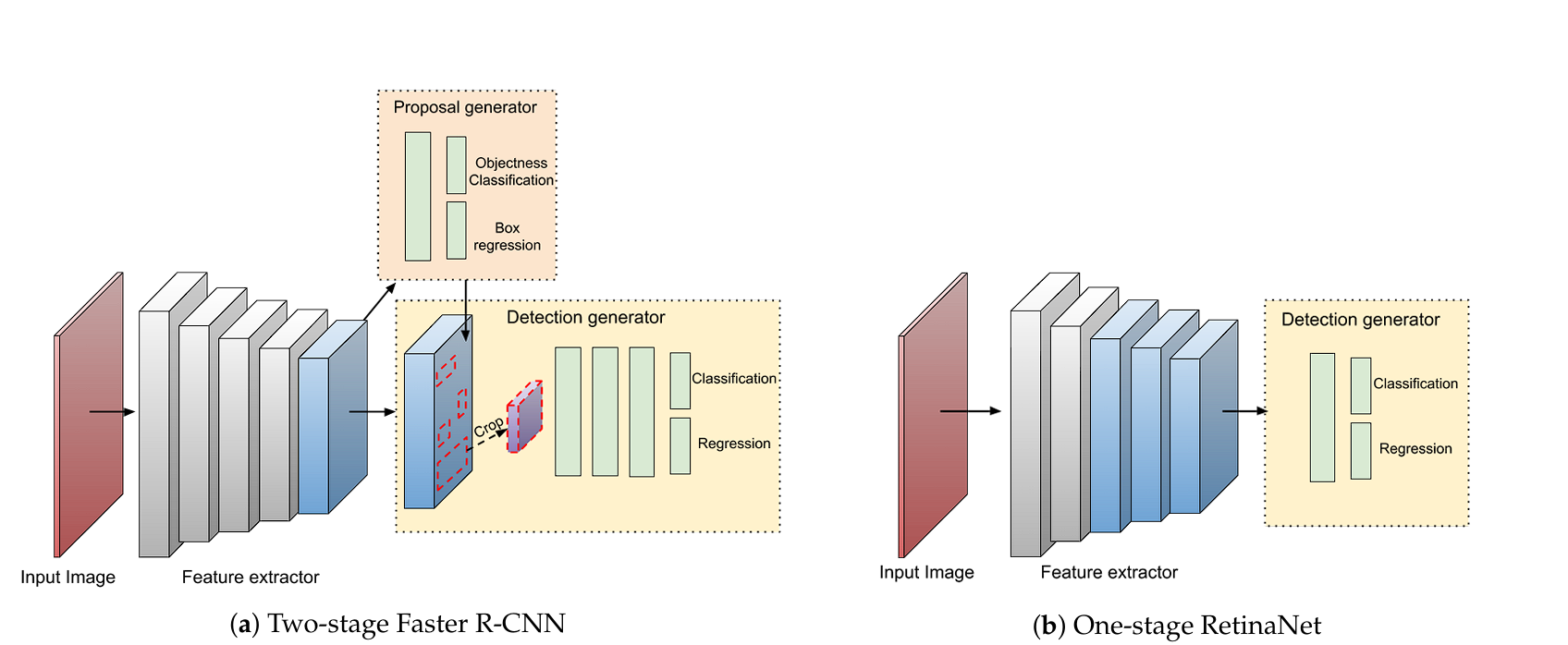
Two-Stage Detectors
Two-stage detectors, resembling R-CNN, Quick R-CNN, and Quicker R-CNN, divide the duty of object detection right into a two-step course of:
- Area Proposal: Within the first stage, the mannequin generates a set of area proposals which are more likely to include objects. That is executed utilizing strategies like selective search (R-CNN) or a Area Proposal Community (RPN) (Quicker R-CNN).
- Classification and Refinement: Within the second stage, the proposals are labeled into object classes and refined to enhance the accuracy of the bounding bins.
The multi-stage pipeline is slower, extra advanced, and will be difficult to implement and optimize compared to single-stage detectors. Nonetheless, these two-stage detectors are often extra strong and obtain increased accuracy.
One-Stage Detectors
One-stage detectors, resembling FCOS, YOLO (You Solely Look As soon as), and SSD (Single Shot Multi-Field Detector) eradicate the necessity for regional proposals. The mannequin in a single move straight predicts class chances and bounding field coordinates from the enter picture.
This leads to one-stage detectors being less complicated and simpler to implement in comparison with two-stage strategies, additionally the one-stage detectors are considerably sooner, permitting for real-time functions.
Regardless of their velocity, they’re often much less correct and make the most of pre-made anchors for detection. Nonetheless, FCOS has lowered the accuracy hole in contrast with two-stage detectors and fully avoids using anchors.
What’s FCOS?
FCOS (Totally Convolutional One-Stage Object Detection) is an object detection mannequin that drops using predefined anchor field strategies. As a substitute, it straight predicts the places and sizes of objects in a picture utilizing a totally convolutional community.
This anchor-free method on this state-of-the-art object detection mannequin has resulted within the discount of computational complexity and elevated efficiency hole. Furthermore, FCOS outperforms its anchor-based counterparts.
What are anchors?
In single-stage object detection fashions, anchors are pre-defined bounding bins used throughout the coaching and detection (inference) course of to foretell the places and sizes of objects in a picture.
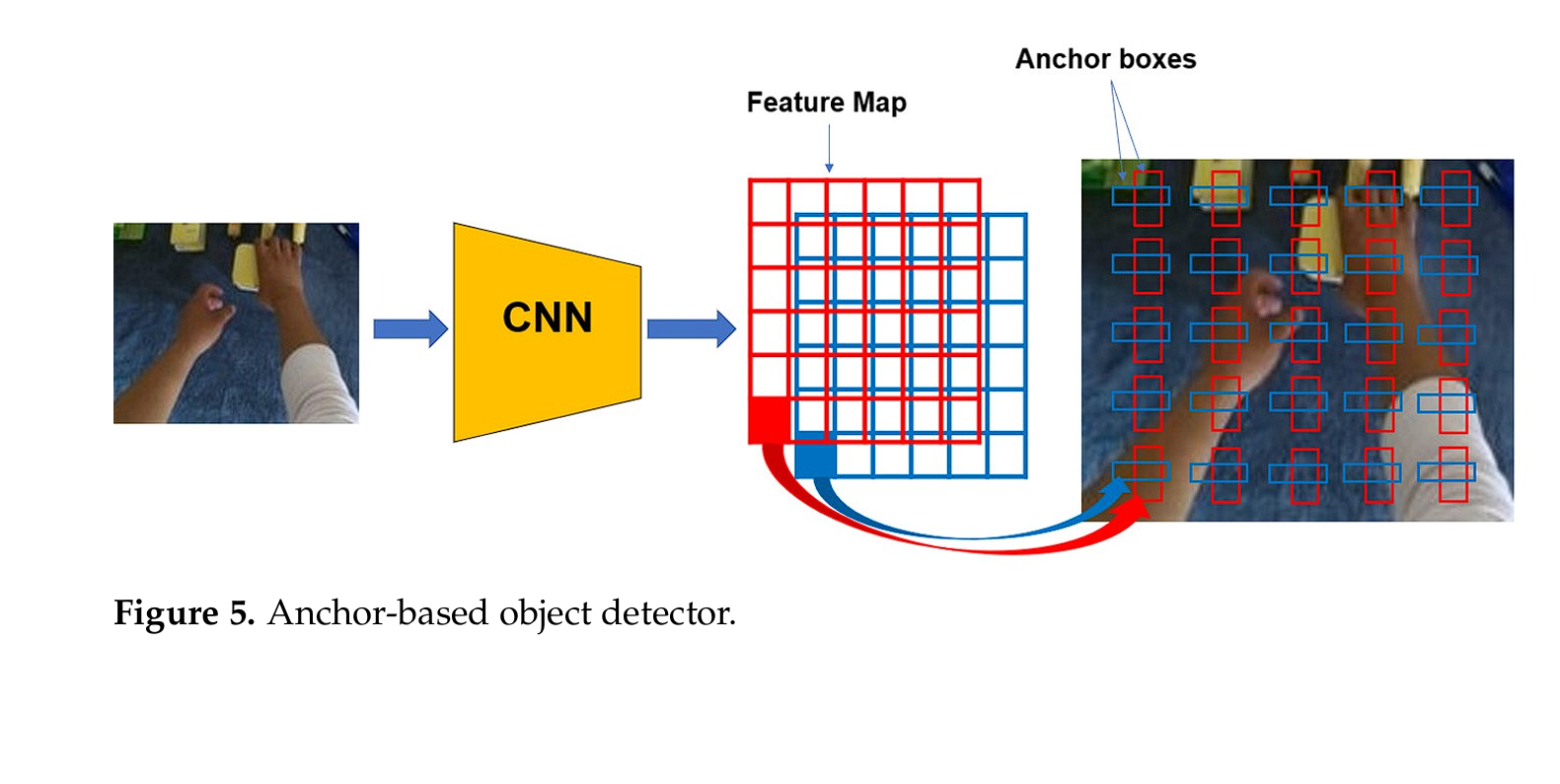
Widespread fashions resembling YOLO and SSD use anchor bins for direct prediction, which results in limitations in dealing with various object shapes and sizes, and in addition reduces the mannequin’s robustness and effectivity.
Limitations of Anchors
- Complexity: Anchor-based detectors rely on quite a few anchor bins of various sizes and facet ratios at varied places within the picture. This will increase the complexity of the detection pipeline, because it requires the designing of anchors for varied objects.
- Computation associated to Anchors: Anchor-based detectors make the most of numerous anchor bins at totally different places, scales, and facet ratios throughout each coaching and inference. That is computationally intensive and time-consuming
- Challenges in Anchor Design: Designing applicable anchor bins is troublesome and results in the mannequin being succesful for the particular dataset solely. Poorly designed anchors may end up in lowered efficiency.
- Imbalance Points: The massive variety of adverse pattern anchors (anchors that don’t overlap considerably with any floor fact object) in comparison with constructive anchors can result in an imbalance throughout coaching. This may make the coaching course of much less secure and more durable to converge.
How Anchor-Free Detection Works
An anchor-free object detection mannequin resembling FCOS takes benefit of all factors in a floor fact bounding field to foretell the bounding bins. In essence, it really works by treating object detection as a per-pixel prediction process. For every pixel on the characteristic map, FCOS predicts:
- Object Presence: A confidence rating indicating whether or not an object is current at that location.
- Offsets: The distances from the purpose to the item’s bounding field edges (prime, backside, left, proper).
- Class Scores: The category chances for the item current at that location.
By straight predicting these values, FCOS fully avoids the sophisticated means of designing anchor bins, simplifying the detection course of and enhancing computational effectivity.
FCOS Structure
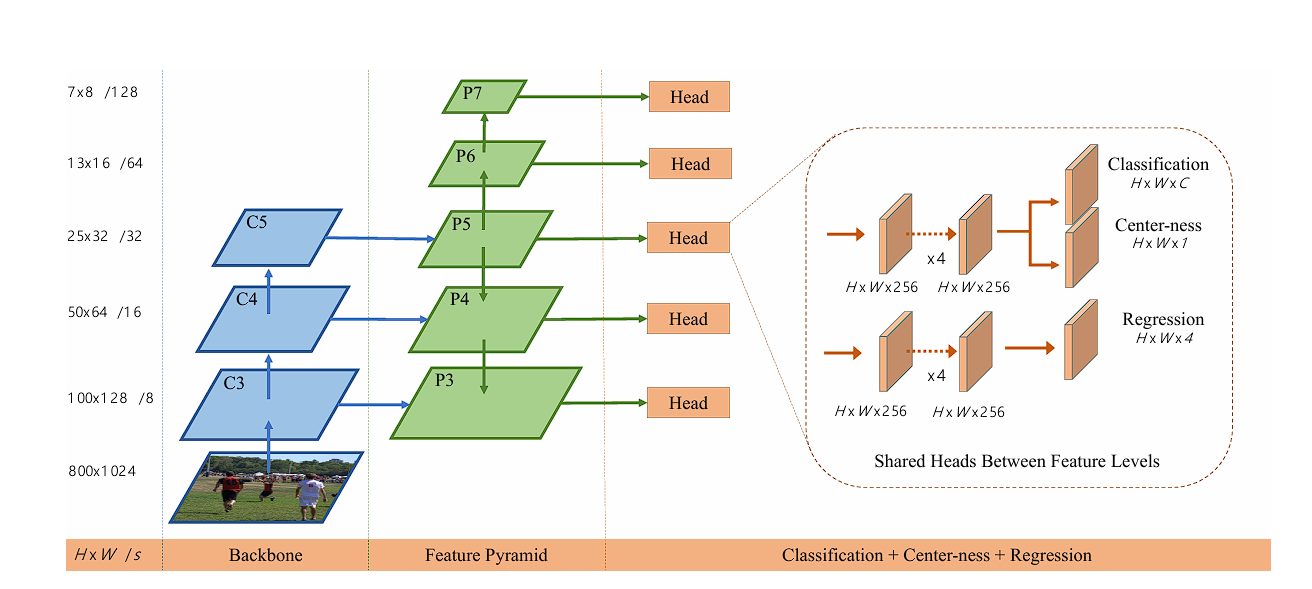
Spine Community
The spine community works because the characteristic extractor, by reworking photographs into wealthy characteristic maps that will probably be used within the later layers for detection functions within the structure of FCOS. Within the unique revealed analysis paper on FCOS, the researchers used ResNet and ResNeXt because the spine for the mannequin.
The spine community processes the enter picture by way of a number of layers of convolutions, pooling, and non-linear activations. Every layer captures more and more summary and sophisticated options, starting from easy edges and textures within the early layers to total object components and semantic ideas within the deeper layers.
The characteristic maps produced by the spine are then fed into subsequent layers that predict object places, sizes, and courses. The spine community’s output ensures that the options used for prediction are each spatially exact and semantically wealthy, bettering the accuracy and robustness of the detector.
ResNet (Residual Networks)
ResNet makes use of residual connections or shortcuts that skip a number of layers, which assist to sort out the vanishing gradient downside, permitting researchers to construct deeper fashions, resembling ResNet-50, ResNet-101, and ResNet-152 (it has a large 152 layers).
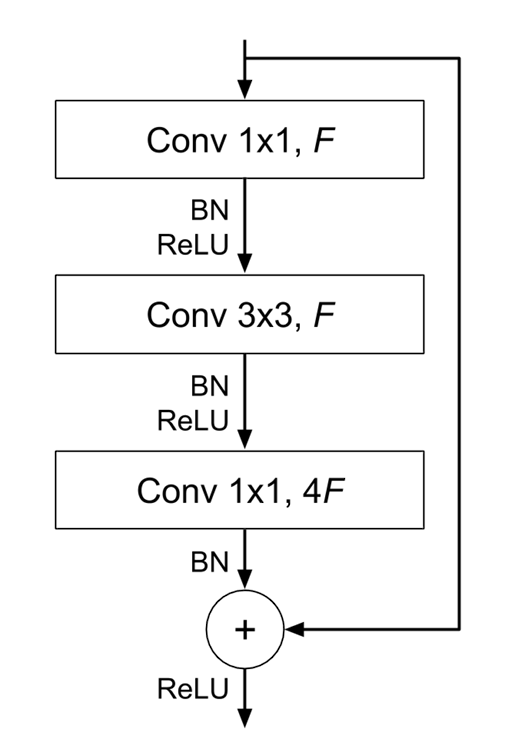
A residual connection connects the output of 1 earlier convolutional layer to the enter of one other future convolutional layer, a number of layers later into the mannequin (consequently a number of CNN layers are skipped). This enables for the gradients to circulation straight by way of the community throughout backpropagation, serving to with the vanishing gradient downside (a serious concern with coaching very deep neural networks).
Within the analysis paper on FCOS, the researchers additionally used a Function Pyramid Community (FPN).
What’s FPN?
A Function Pyramid Community (FPN) is designed to boost the flexibility of convolutional neural networks to detect objects at a number of scales. As mentioned above, the preliminary layers detect edges and shapes, whereas deeper layers seize components of a picture and different advanced options. FPN creates an outlet at each the preliminary layers and deeper layers. This leads to a mannequin able to detecting objects of varied sizes and scales.
By combining options from totally different ranges, the community higher understands the context, permitting for higher separation of objects and background muddle.
Furthermore, small objects are troublesome to detect as a result of they don’t seem to be represented in lower-resolution characteristic maps produced in deeper layers (characteristic map decision decreases because of max pooling and convolutions). The high-resolution characteristic maps from early layers in FPN enable the detector to determine and localize small objects.
Multi-Degree Prediction Heads
Within the FCOS, the prediction head is accountable for making the ultimate object detection predictions. In FCOS, there are three totally different heads are accountable for totally different duties.
These heads function on the characteristic maps produced by the spine community. The three heads are:
Classification Head
The classification head predicts the item class chances at every location within the characteristic map. The output is a grid the place every cell incorporates scores for all doable object courses, indicating the chance that an object of a selected class is current at that location.
Regression Head

The regression head precuts the bounding field coordinated with the item detected at every location on the characteristic map.
This head outputs 4 values for the bounding field coordinates (left, proper, prime, backside). By using this regression head, FCOS can detect objects with out the necessity for anchor bins.
For every level on the characteristic map, FCOS predicts 4 distances:
- l: Distance from the purpose to the left boundary of the item.
- t: Distance from the purpose to the highest boundary of the item.
- r: Distance from the purpose to the correct boundary of the item.
- b: Distance from the purpose to the underside boundary of the item.
The coordinates of the expected bounding field will be derived as:
bbox𝑥1=𝑝𝑥−𝑙
bbox𝑦1=𝑝𝑦−𝑡
bbox𝑥2=𝑝𝑥+𝑟
bbox𝑦2=𝑝𝑦+𝑏
The place (𝑝𝑥,𝑝𝑦) are the coordinates of the purpose on the characteristic map.
Heart-ness Head

This head predicts a rating of 0 and 1, indicating the chance that the present location is on the middle of the detected object. This rating is then used to down-weight the bounding field prediction for places removed from an object’s middle, as they’re unreliable and certain false predictions.
It’s calculated as:
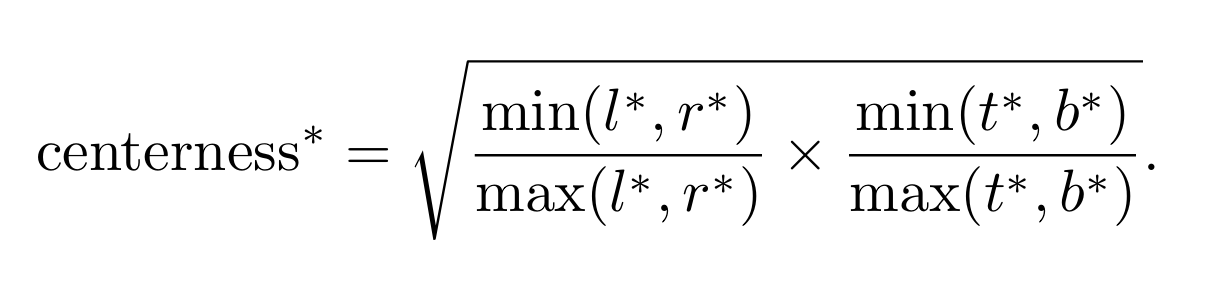
Right here l, r, t, and b are the distances from the placement to the left, proper, prime, and backside boundaries of the bounding field, respectively. This rating ranges between 0 and 1, with increased values indicating factors nearer to the middle of the item. It’s calculated utilizing binary cross entropy loss (BCE).
These three prediction heads work collaboratively to carry out object detection:
- Classification Head: This predicts the chance of every class label at every location.
- Regression Head: This head provides the exact bounding field coordinates for objects at every location, indicating precisely the place the item is positioned throughout the picture.
- Heart-ness Head: This head enhances and corrects the prediction made by the regression head, utilizing the center-ness rating, which helps in suppressing low-quality bounding field predictions (as bounding bins removed from the middle of the item are more likely to be false).
Throughout coaching, the outputs from these heads are mixed. The bounding bins predicted by the regression head are adjusted primarily based on the center-ness scores. That is achieved by multiplying the center-ness scores with prediction scores, which fits into the loss operate, this eradicates the low-quality and off-the-target bounding bins.
The Loss Operate
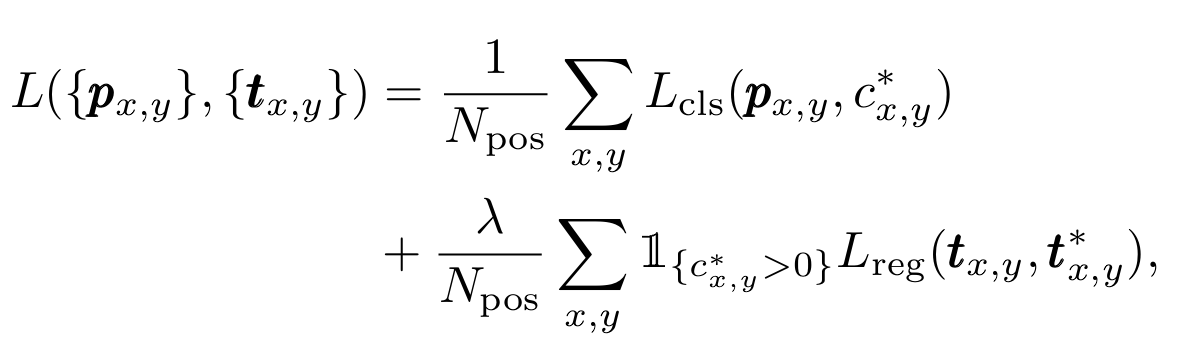
The full loss is the sum of the classification loss and regression loss phrases, with the classification loss Lcls being focal loss.
Conclusion
On this weblog, we explored FCOS (Totally Convolutional One-Stage Object Detection) which is a totally convolutional one-stage object detector that straight predicts object bounding bins with out the necessity for predefined anchors, one-stage object detectors resembling YOLO and SSD, that closely depends on anchors. As a result of anchor-less design, the mannequin fully avoids the sophisticated computation associated to anchor bins such because the IOU loss computation and matching between the anchor bins and ground-truth bins throughout coaching.
The FCOS mannequin structure makes use of the ResNet spine mixed with prediction heads for classification, regression, and center-ness rating (to regulate the bounding field coordinates predicted by the regression head). The spine extracts hierarchical options from the enter picture, whereas the prediction heads generate dense object predictions on characteristic maps.
Furthermore, the FCOS mannequin lays a particularly essential basis for future analysis works on bettering object detection fashions.
Learn our different blogs to boost your data of laptop imaginative and prescient duties: