


This text is about one of many revolutionary GANs, ProGAN from the paper Progressive Rising of GANs for Improved High quality, Stability, and Variation. We’ll go over it, see its targets, the loss operate, outcomes, implementation particulars, and break down its parts to know every of those. If we wish to see the implementation of it from scratch, take a look at this weblog, the place we replicate the unique paper as shut as doable, and make an implementation clear, easy, and readable utilizing PyTorch.
If we’re already acquainted with GANs and know the way they work, proceed by means of this text, but when not, it is advisable to take a look at this weblog publish first.
Gan Enhancements

On this part, We’ll find out about GAN enhancements. We’ll see how GANs have superior over time. Within the determine above we will see a visualization of the speed at which GANs have improved through the years.
- In 2014 Ian Goodfellow gave machines the reward of creativeness by creating the highly effective AI idea of GANs from the paper Generative Adversarial Networks, however they had been extremely delicate to hyperparameters, and the generated photographs appeared low-quality. We are able to see the primary face which is black and white and appears barely like a face. We are able to learn in regards to the unique GANs in these blogs: Uncover why GANs are superior!, Full Information to Generative Adversarial Networks (GANs), and Constructing a easy Generative Adversarial Community (GAN) utilizing TensorFlow.
- Since then researchers begin to enhance GANs, and in 2015 a brand new methodology was launched, DCGANs from the paper Unsupervised Illustration Studying with Deep Convolutional Generative Adversarial Networks. We are able to see within the second picture, that the face appears higher but it surely’s nonetheless removed from perfection. We are able to examine it on this weblog: Getting Began With DCGANs.
- Subsequent in 2016, CoGAN, from the paper Coupled Generative Adversarial Networks was launched, which improved face technology even additional.
- On the finish of 2017, researchers from NVIDIA AI launched ProGAN together with the paper Progressive Rising of GANs for Improved High quality, Stability, and Variation, which is the principle topic of this text. We are able to see that the fourth image appears extra real looking than the earlier ones.
- In 2018 the identical researchers give you StyleGAN from the paper A Model-Primarily based Generator Structure for Generative Adversarial Networks, which relies on ProGAN. We’ll cowl it in an upcoming article. We are able to see the high-quality faces that StyleGAN can generate and the way real looking they give the impression of being.
- In 2019 the identical researchers once more give you StyleGAN2 from the paper Analyzing and Enhancing the Picture High quality of StyleGAN which is an enchancment over StyleGAN. In 2021, once more they give you StyleGAN3 from the paper Alias-Free Generative Adversarial Networks, which is an enchancment over StyleGAN2. We’ll cowl each of them in upcoming articles individually, break down their parts and perceive them, then implement them from scratch utilizing PyTorch.
StyleGan3 is the king in picture technology, it beat different GANs out of the water on quantitative and qualitative analysis metrics, each with regards to constancy and variety.
Due to these papers and others, GANs have superior largely from improved coaching, stability, capability, and variety.
ProGAN Overview
On this part, we are going to find out about ProGAN’s comparatively new structure that is thought of an inflection level enchancment in GAN. We’ll go over ProGAN’s main targets and get an introduction to its structure in particular person parts.
ProGAN targets
- Produce high-quality, high-resolution photographs.
- Better variety of photographs within the output.
- Enhance stability in GANs.
- Enhance variation within the generated photographs.
Primary parts of ProGAN
Conventional Generative adversarial networks have two parts; the generator and the discriminator. The generator community takes a random latent vector (z∈Z) and tries to generate a sensible picture. The discriminator community tries to distinguish actual photographs from generated ones. Once we prepare the 2 networks collectively the generator begins producing photographs indistinguishable from actual ones.
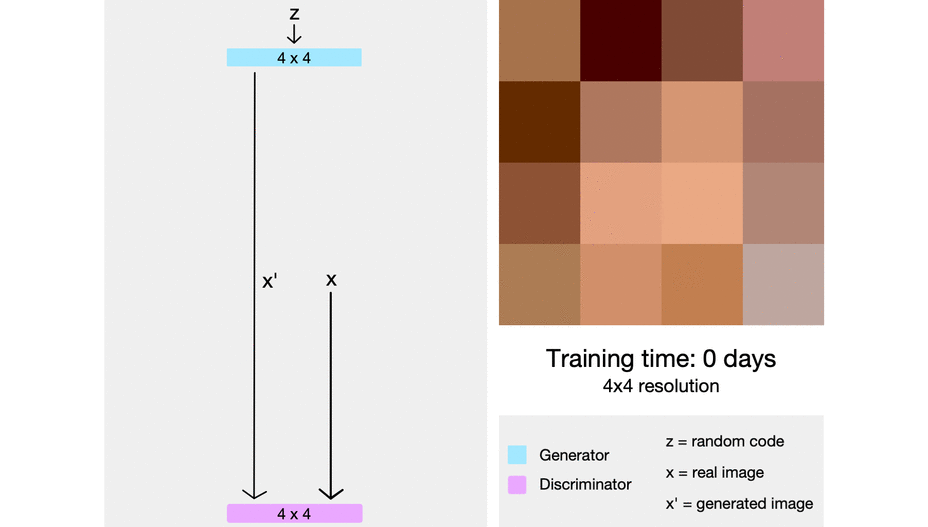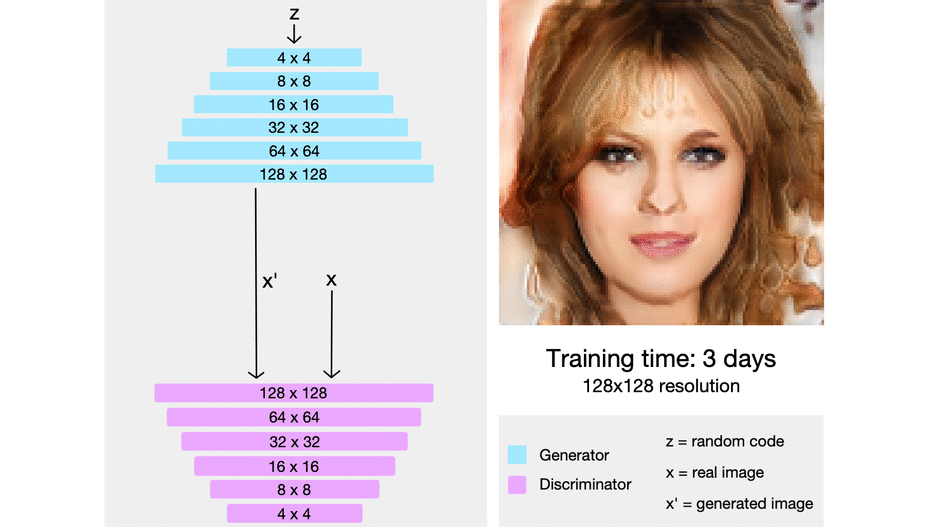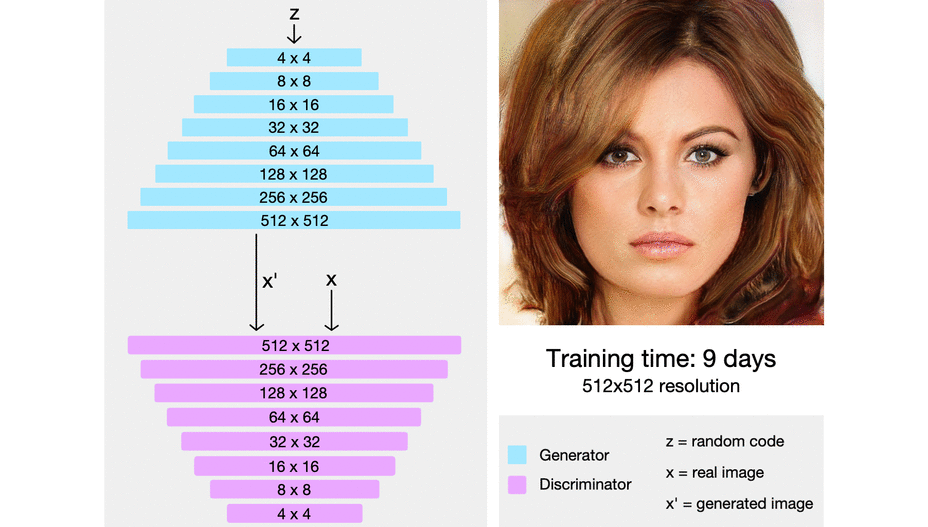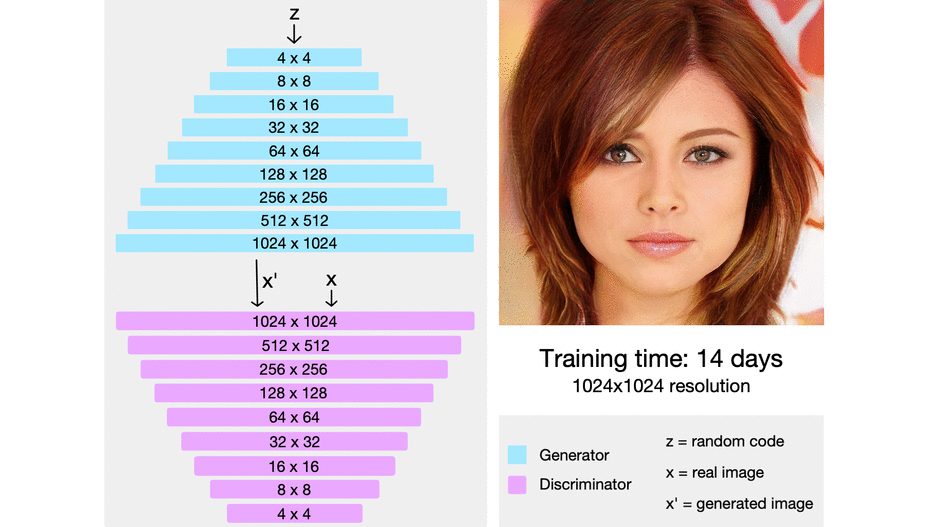
In ProGAN the important thing thought is to develop each the generator and discrimination progressively, The generator begins with studying to generate a really small enter picture of 4×4, after which when it has achieved that job, the place the goal photographs look very near the generated photographs so the discriminator cannot distinguish between them at this particular decision, then we replace it, and the generator generates 8×8 photographs. When it is completed with that problem, we improve it once more to 16×16, and we will think about this persevering with till finally attain 1024 x 1024 pixel photographs.
This concept simply is smart as a result of it is just like the best way that we be taught. If we take arithmetic, for instance, we do not ask on day 1 to calculate gradients; we begin from the muse doing easy addition, after which we’re progressively grown to do more difficult duties. That is the important thing thought in ProGAN, however moreover, the authors additionally describe a number of implementation particulars which might be necessary and they’re Minibatch Normal Deviation, Fading in new layers, and Normalization (PixelNorm & Eq. LR). Now let’s get a deeper dive into every of those parts and the way they work.
Progressive Rising
On this part, we are going to find out about progressive rising, which is the important thing thought of ProGAN. We’ll go over each the instinct behind it in addition to the motivation after which we are going to dive slightly bit deeper into tips on how to implement it.
First off, progressive rising is making an attempt to make it simpler for the generator to generate increased decision photographs by regularly coaching it from decrease decision photographs to increased decision photographs. Beginning with a better job, a really blurry picture for it to generate a 4×4 picture with solely 16 pixels to then a a lot increased decision picture over time.
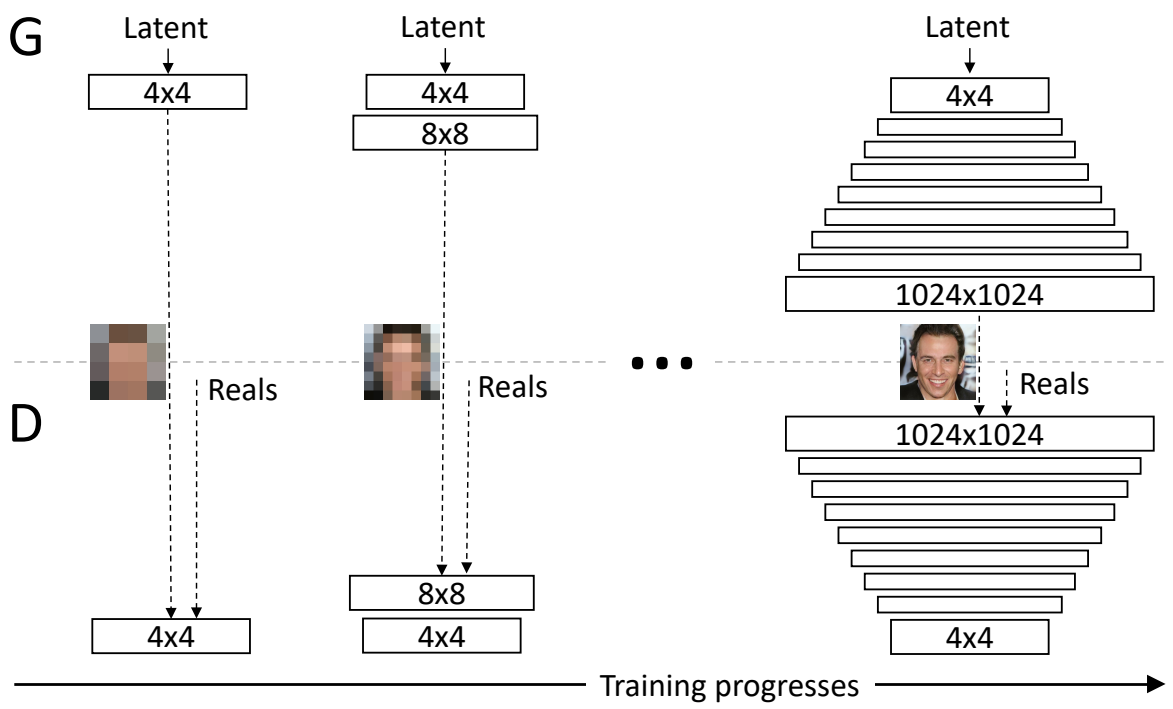
First, the generator simply must generate a four-by-four picture and the discriminator wants to judge whether or not it is actual or faux. After all, to make it not so apparent what’s actual or faux, the true photographs can even be downsampled to a four-by-four picture. Within the subsequent step of progressive rising, all the things is doubled, so the picture now generated is an eight-by-eight picture. It is of a a lot increased decision picture than earlier than, however nonetheless a better job than an excellent high-resolution picture, and naturally, the reals are additionally down-sampled to an eight-by-eight picture to make it not so apparent which of them are actual and which of them are faux. Following this chain, the generator is finally capable of generate tremendous high-resolution photographs, and the discriminator will have a look at that increased decision picture towards actual photographs that can even be at this excessive decision, so now not downsampled and be capable of detect whether or not it is actual or faux.
Within the picture under, we will see progressive rising in motion from actually pixelated four-by-four pixels to super-high-resolution photographs.
Minibatch Normal Deviation
GANs tend to not present as diversified photographs as in coaching knowledge, so the authors of ProGAN remedy this difficulty with a easy method. They first compute the usual deviation for each instance throughout the entire channels and the entire pixel values, after which they take a imply throughout all of over the batch. Then they replicate that worth (which is only a single scalar worth) throughout the entire examples after which the entire pixel values to get a single channel, and concatenate it to the enter.
Fading in new layers
By now, we should always perceive how, in ProGANs, we do progressive rising the place we begin by 4×4, then 8×8, and so on. However this progressive rising is not as simple as simply doubling in dimension instantly at these scheduled intervals, it is really slightly bit extra gradual than that.
For the generator
Once we wish to generate a double-size picture, first we upsample the picture (upsampling might use methods like nearest neighbors filtering). With out utilizing any realized parameters it is simply very primary upsampling, after which within the subsequent step we might do 99% upsampling and 1% of taking the upsampled picture right into a convolutional layer that produces a double dimension decision picture, so we have now some realized parameters.
Over time we begin to lower the share of upsampling, and enhance the share of realized parameters, so the picture begins to look maybe extra just like the goal (I.e face, if we wish to generate faces), and fewer like simply upsampling from nearest neighbors upsampling. Over time, the mannequin will start to rely not on the upsampling, however as a substitute simply depend on realized parameters for inference.
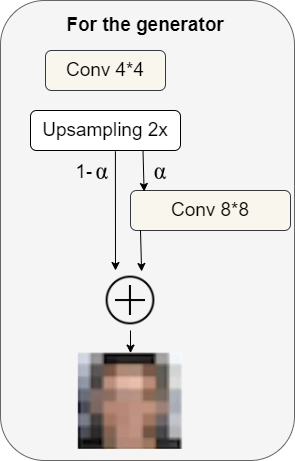
Extra usually, we will consider this as an α parameter that grows over time, the place α begins out as 0 after which grows all the best way as much as 1. We are able to write the ultimate formulation as follows: $[(1−α)×UpsampledLayer+(α)×ConvLayer]$
For the discriminator
For the discriminator, there’s one thing pretty related, however in the wrong way.
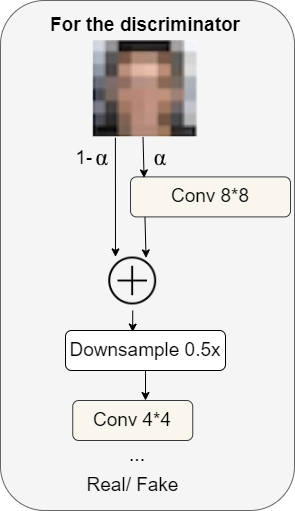
Now we have a high-resolution picture (instance: 8×8 within the determine above), and slowly over time, we undergo the downsampling layer to then deal with the low-resolution picture (exp: 4×4 within the determine above). On the very finish, we output a chance between zero and one (actual or faux) comparable to the prediction.
The α that we use within the discriminator is similar that we noticed within the generator.
Normalization
Most if not all earlier superior GANs use batch normalization within the generator and within the discriminator to remove covariate shift. However the authors of ProGAN noticed that this isn’t a problem in GANs and so they use a unique method that consists of a two-step course of.
Equalized Studying Price
Due to the issue with optimizers which is the gradient replace steps in Adam and RMSProp relying upon the dynamic vary of the parameters, the authors of ProGAN launched their resolution, the Equalized studying price, to raised remedy for his or her particular downside.
Earlier than each ahead go, studying charges might be equalized throughout layers by scaling the weights. For instance, earlier than performing a convolution with f filters of dimension (ok, ok, c), they scale the weights of these filters as proven under. In that approach, they be sure that each weight is in the identical dynamic vary, after which the educational velocity is similar for all weights.
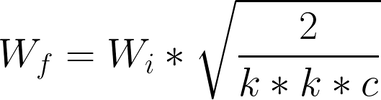
Pixel Normalization
To eliminate batch normalization, the authors utilized pixel normalization after the convolutional layers within the generator to stop sign magnitudes from spiraling uncontrolled throughout coaching.
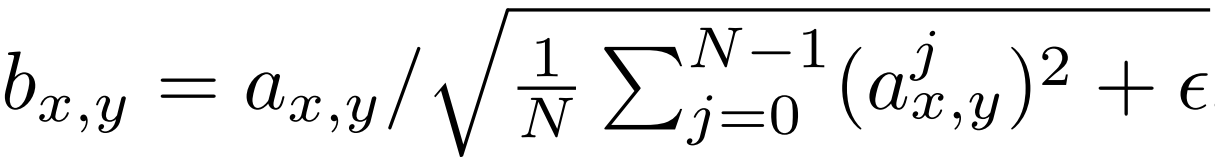
Mathematically the brand new characteristic vector in pixel (x,y) would be the outdated one divided by the sq. root of the imply of all pixel values squared for that specific location plus epsilon that equals 10^-8. The implementation of that is going to be fairly clear (You possibly can see the entire implementation of ProGAN from scratch on this weblog).
The Loss Perform
For the loss operate, the authors use one of many widespread loss features in GANs, the Wasserstein loss operate, also called WGAN-GP from the paper Improved Coaching of Wasserstein GANs. However, in addition they say that the selection of the loss operate is orthogonal to their contribution, which implies that not one of the parts of ProGAN (Minibatch Normal Deviation, Fading in new layers, and Normalization (PixelNorm & Eq. LR)) depend on a selected loss operate. It could due to this fact be affordable to make use of any of the GAN loss features we would like, and so they display so by coaching the identical community utilizing LSGAN loss as a substitute of WGAN-GP loss. The determine under exhibits six examples of 10242 photographs produced utilizing their methodology utilizing LSGAN.

Nevertheless, we are attempting to observe the paper precisely so let’s clarify WGAN-GP slightly bit. Within the determine under, we will see the loss equations the place:
- x’ is the generated picture.
- x is a picture from the coaching set.
- D is the discriminator.
- GP is a gradient penalty that helps stabilize coaching.
- The a time period within the gradient penalty refers to a tensor of random numbers between 0 and 1, chosen uniformly at random.
- The parameter λ is widespread to set to 10.
Outcomes

I feel the outcomes are shocking for most individuals, they give the impression of being superb, they’re 1024 by 1024 photographs and they’re quite a bit higher than the earlier ones. So that is a type of revolutionary papers that was the primary to generate actually high-quality photographs in GANs.
Implementation particulars
The authors prepare the community on eight tesla v100 GPUs till they did not observe any kind of enhancements. This took about 4 days. Of their implementation, they used an adaptive minibatch dimension relying on the output decision, in order that the obtainable reminiscence finances was optimally utilized (they decreased the batch dimension once they could not maintain that into the reminiscence).
Generator
In conventional GANs we ask the generator to generate instantly a set decision, like 128 by 128. Typically talking, increased decision photographs are far more troublesome to generate, and it is a form of a difficult job to immediately output high-quality photographs. In ProGAN we ask the generator to:
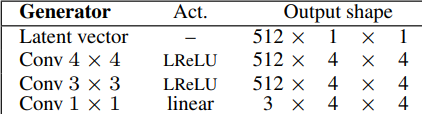
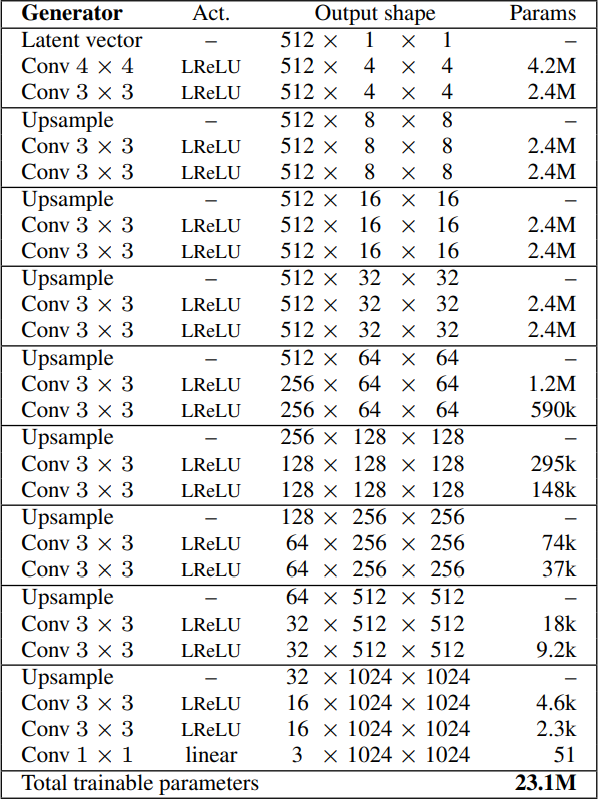
- First, generate 4 by 4 photographs by taking as enter a latent vector equal to 512. They’ll additionally title it noise vector or z-dim, then map it to 512 (in 1 channels). Then, they observe a pleasant pattern, the place they use a transposed convolution that maps one after the other to 4 by 4 to start with, adopted by the identical convolution with three by three filter, utilizing leaky ReLU as activation operate in each convolutions. Lastly,, they add a one after the other convolution that maps the variety of channels which is 512 to RGB (3 channels).
- Subsequent, they Generate eight by eight photographs by utilizing the identical structure with out the ultimate convolution layer that maps the variety of channels to RGB. Then, they add the next layers: upsampling to double the earlier decision, two Conv layers with three by three filter utilizing leaky ReLU as activation operate, and one other Conv layer with one after the other filter to output an RGB picture.
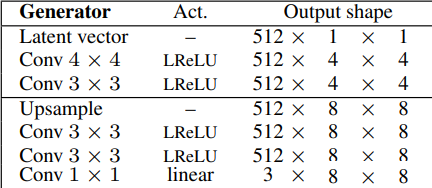
- Then, they once more generate double the scale of the earlier one by utilizing the identical structure with out the final convolution layer and including the identical layers (upsampling to double the earlier decision, two Conv layers with three by three filter utilizing leaky ReLU as activation operate, and one other Conv layer with one after the other filter to output an RGB picture.) till reaching the decision desired: 1024 x 1024. Within the picture under, we will see the ultimate structure of the generator.
Discriminator
For the discriminator, they do an reverse method. It is kind of a mirror picture of the generator. Once we attempt to generate a present decision, we downsample the true photographs to the identical decision to not make it so apparent what’s actual or faux.
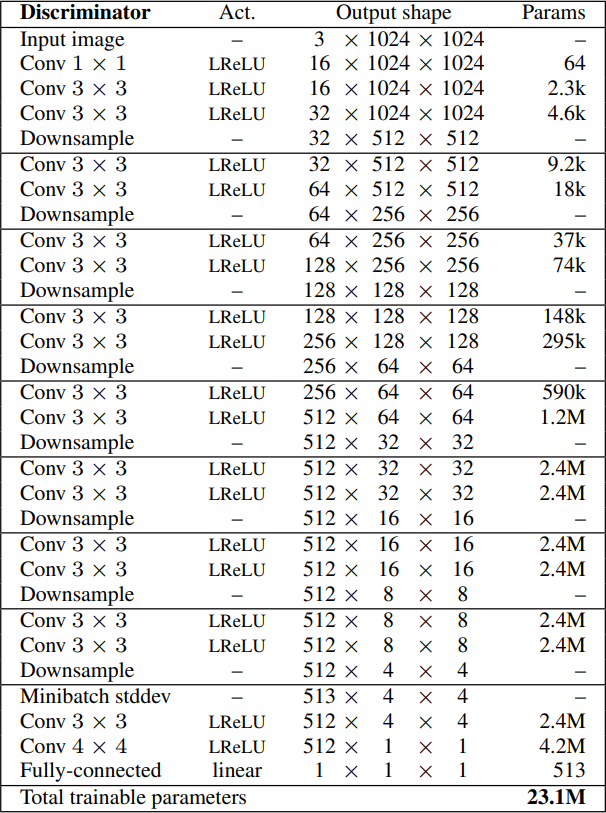
- They begin by producing four-by-four photographs, which implies downsampling the true photographs till reaching the identical decision. The enter of the discriminator is the RGB photographs we do three Conv layers the primary with one-by-one filter, and the others with three-by-three filters, utilizing leaky ReLU as an activation operate. We then downsample the picture to half the earlier present decision, and add two Conv layers with three-by-three filter and Leaky Relu. Then we downsample once more, and so forth till we attain the decision that we would like. Then, we inject Minibatch Normal Deviation as a characteristic map, so it goes from the variety of channels to the variety of channels + 1 (On this case 512 to 513). They’ll then run it by means of the final two Conv layers with 3×3 and 4×4 filters respectively. And in the long run, they’ve a full related layer to map the variety of channels (512) to 1 channel. Within the determine under, we will see the discriminator structure for four-by-four photographs.
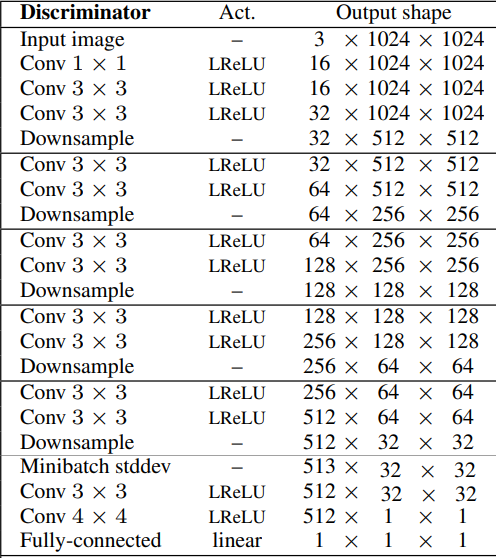
- If we wish to generate X-by-X photographs (by which X is the decision of the pictures) we simply use the identical steps as earlier till we attain the decision that we would like, then we add the ultimate 4 layers(Minibatch STddev, Conv 3x3x, Conv 4×4, and Totally related). Within the determine under, we will see the discriminator structure for 32×32 photographs.
Conclusion
On this article, we checked out a few of the main milestones within the developmental historical past of GANs, and went by means of the revolutionary ProGAN paper that was the primary to generate actually high-quality photographs. We then explored the unique mannequin’s targets, the loss operate, outcomes, implementation particulars, and its parts to assist perceive these networks in depth.
Hopefully, readers are capable of observe the entire steps and get an excellent understanding of it, and prepare to deal with the implementation. We are able to discover it on this article the place we made a clear, easy, and readable implementation of the mannequin to generate some vogue as a substitute of faces, utilizing this dataset from Kaggle for coaching. Within the determine under you may see the outcomes that we acquire for decision 128×128.

In upcoming articles, we are going to clarify and implement from scratch StyleGANs utilizing PyTorch (StyleGAN1 which relies on ProGAN, StyleGAN2 which is an enchancment over SyleGAN1, and StyleGAN3 which is an enchancment over SyleGAN2) to generate additionally some cool vogue.