

Xception, brief for Excessive Inception, is a Deep Studying mannequin that’s developed by Francois Chollet at Google, persevering with the recognition of Inception structure, and additional perfecting it.
The inception structure makes use of inception modules, nonetheless, the Xception mannequin replaces it with depthwise separable convolution layers, which totals 36 layers. Once we evaluate the Xception mannequin with the Inception V3 mannequin, it solely barely performs higher on the ImageNet dataset, nonetheless, on bigger datasets consisting of 350 million photos, Xception performs considerably higher.
The journey of Deep Studying fashions in Laptop Imaginative and prescient
Utilization of deep studying architectures in laptop imaginative and prescient started with AlexNet in 2012, it was the primary to make use of Convolutional Neural Community architectures (CNNs) for picture recognition, which gained the ImageNet Massive Scale Visible Recognition Problem (ILSVRC).
After AlexNet, the development was to extend the convolutional blocks’ depth within the fashions, resulting in researchers creating very deep fashions resembling ZFNet, VGGNet, and GoogLeNet (inception v1 mannequin).
These fashions experimented with numerous strategies and mixtures to enhance accuracy and effectivity, with strategies resembling smaller convolutional filters, deeper layers, and inception modules.
The Inception Mannequin
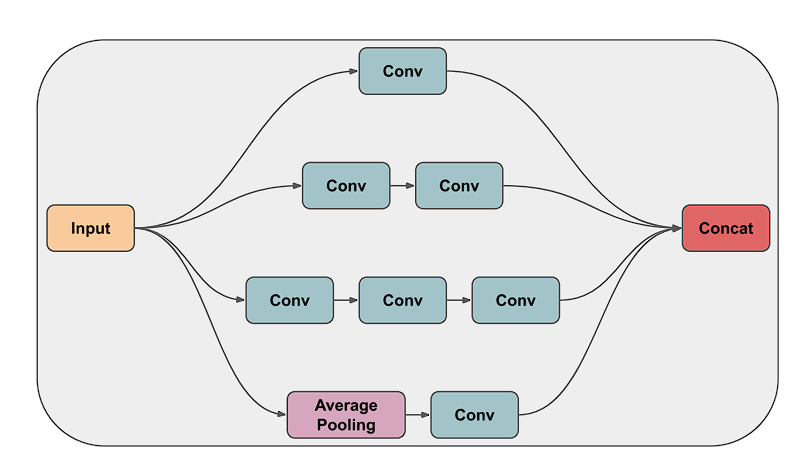
A regular convolution layer tries to be taught filters in a 3D house, specifically: width, top (spatial correlation), and channels (cross-channel correlation), thereby using a single kernel to be taught them.
Nevertheless, the Inception module divides the duty of spatial and cross-channel correlation utilizing filters of various sizes (1×1, 3×3, 5×5) in parallel, therefore benchmarks proved that that is an environment friendly and higher method to be taught filters.
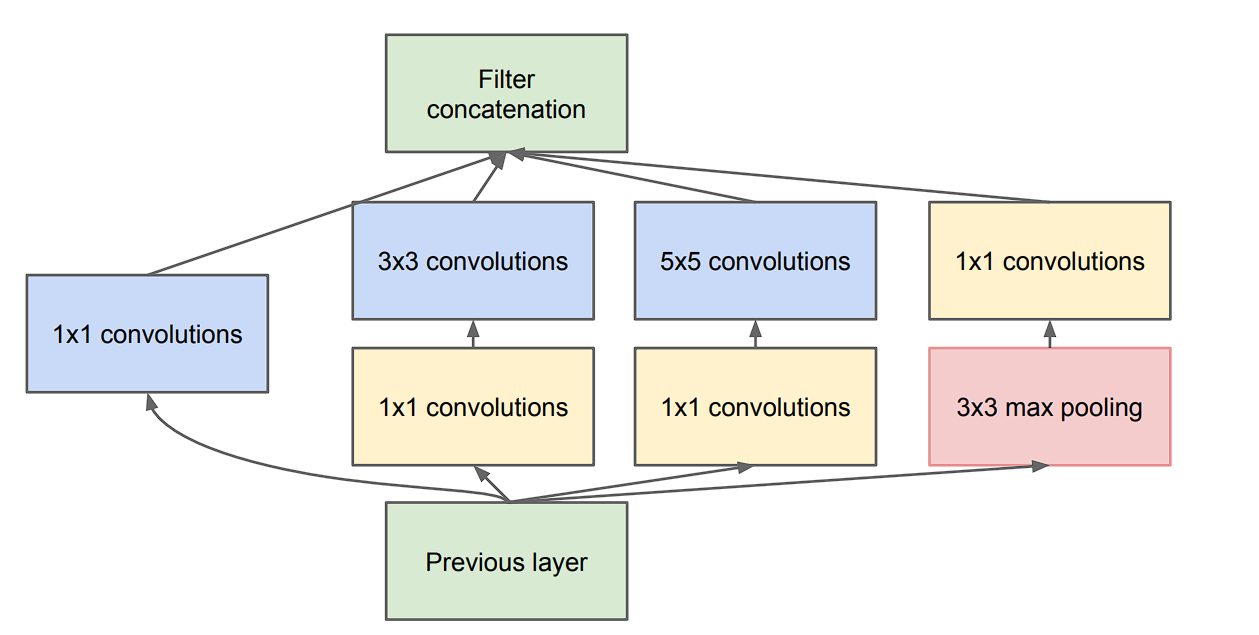
Xception mannequin takes an much more aggressive strategy because it completely decouples the duty of cross-channel and spatial correlation. This gave it the title Excessive Inception Mannequin.
Xception Structure
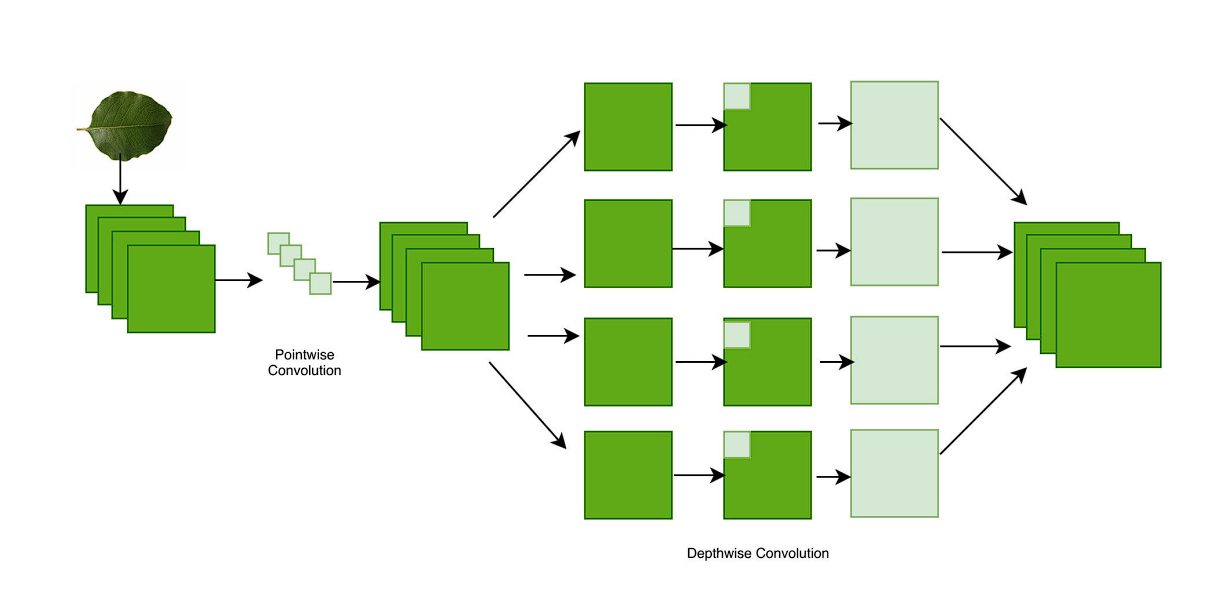
The Xception mannequin’s core is made up of depthwise separable convolutions. Due to this fact, earlier than diving into particular person parts of Xception’s structure, let’s check out depthwise separable convolution.
Depthwise Separable Convolution
Normal convolution learns filters in 3D house, with every kernel studying width, top, and channels.
Whereas, a depthwise separable convolution divides the method into two distinctive processes utilizing depth-wise convolution and pointwise convolution:
- Depthwise Convolution: Right here, a single filter is utilized to every enter channel individually. For instance, if a picture has three coloration channels (pink, inexperienced, and blue), a separate filter is utilized to every coloration channel.
- Pointwise Convolution: After the depthwise convolution, a pointwise convolution is utilized. It is a 1×1 filter that mixes the output of the depthwise convolution right into a single characteristic map.
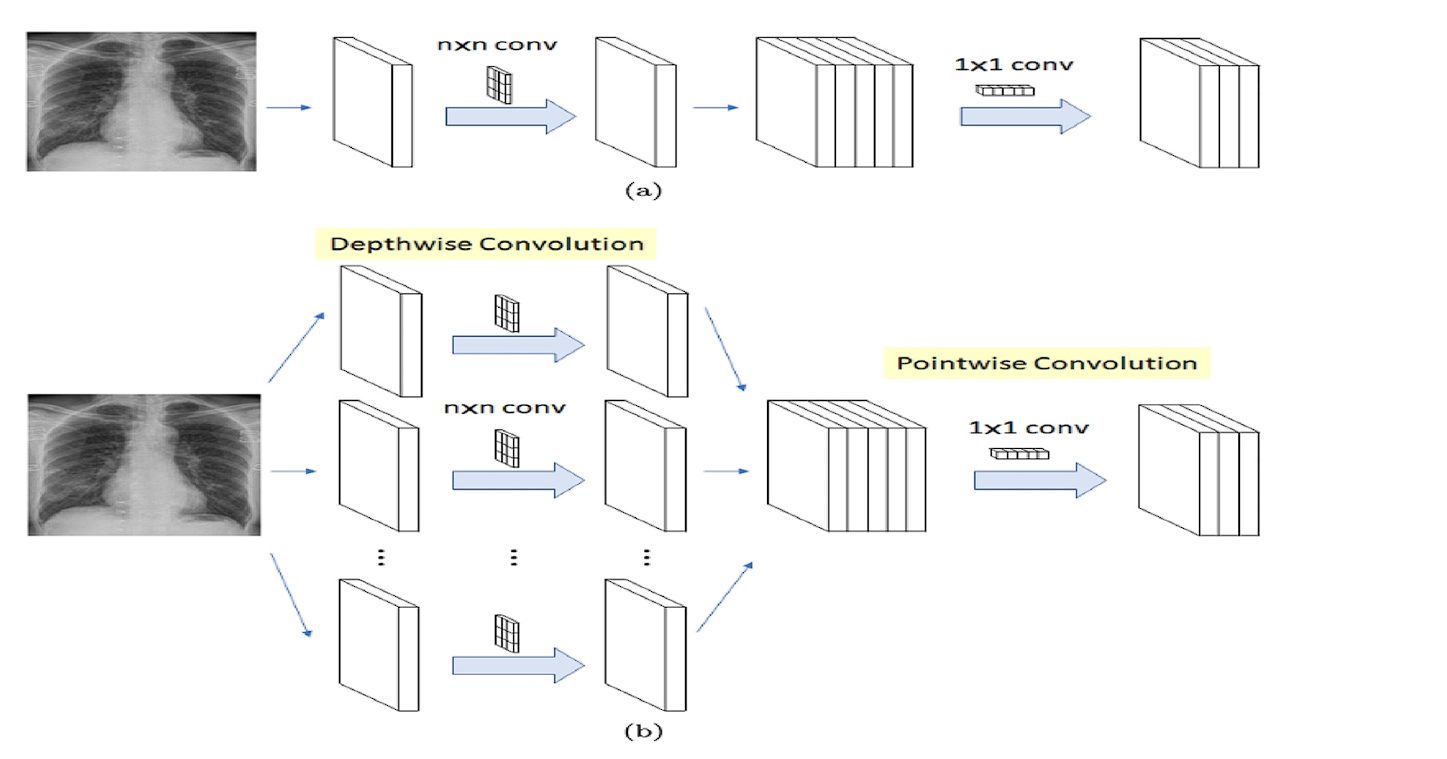
Xception mannequin makes use of a barely modified model of this. Within the unique depthwise separable convolution, we first carry out depthwise convolution, after which pointwise convolution. The Xcpetion mannequin performs pointwise convolution first (1×1), after which the depthwise convolution utilizing numerous nxn filters.
The Three Elements of Xception Structure
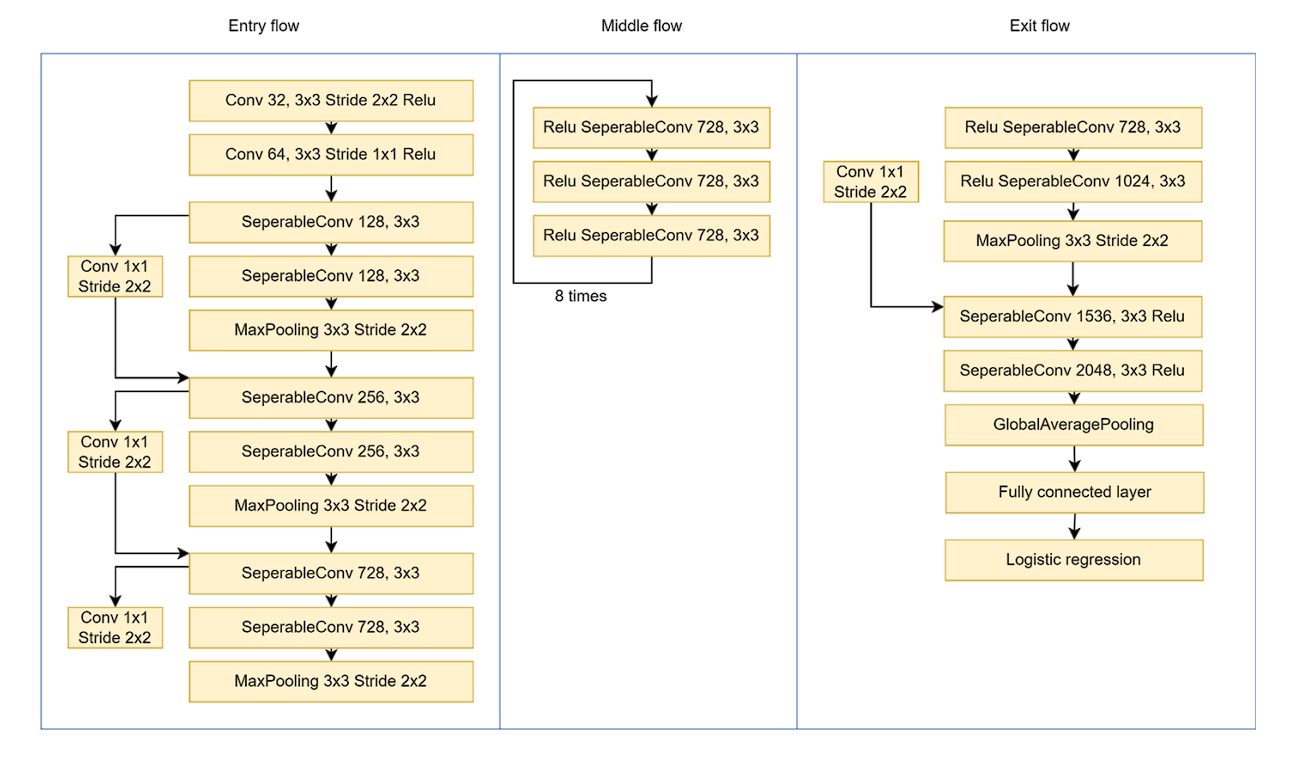
Your complete Xception structure is split into three primary components: the entry stream, the center stream, and the exit stream, with skip connections across the 36 layers.
Entry Circulate
- The enter picture is 299×299 pixels with 3 channels (RGB).
- A 3×3 convolution layer is used with 32 filters and a stride of two×2. This reduces the picture dimension and extracts low-level options. To introduce non-linearity, the ReLU activation operate is utilized.
- It’s adopted by one other 3×3 convolution layer with 64 filters and ReLU.
- After the preliminary low-level characteristic extraction, the modified depthwise separable convolution layer is utilized, together with the 1×1 convolution layer. Max pooling (3×3 with stride=2) reduces the dimensions of the characteristic map.
Center Circulate
- This block is repeated eight occasions.
- Every repetition consists of:
- Depthwise separable convolution with 728 filters and a 3×3 kernel.
- ReLU activation.
- By repeating it eight occasions, the center stream progressively extracts higher-level options from the picture.
Exit Circulate
- Separable convolution with 728, 1024, 1536, and 2048 filters, all with 3×3 kernel additional extracts advanced options.
- World Common Pooling is used to summarize all the characteristic maps right into a single vector.
- Lastly, on the finish, a completely linked layer with logistic regression is used to categorise the photographs.
Regularization Methods
Deep studying fashions intention to generalize (the mannequin’s capability to adapt correctly to new, beforehand unseen information), whereas overfitting stops the mannequin from generalizing.
When a mannequin learns noise from the coaching information or overly learns the coaching information, it’s referred to as overfitting. Regularization strategies assist to stop overfitting in machine studying fashions. The Xception mannequin makes use of weight decay and dropout regularization strategies.
Weight Decay
Weight decay, additionally referred to as L2 regularization, works by including penalties to the bigger weights. This helps to maintain the dimensions of weights small (when the weights are small, every characteristic contributes much less to the general resolution of the mannequin, which makes the mannequin much less delicate to fluctuations in enter information).
With out weight decay, the load might develop exponentially, resulting in overfitting.
Dropout
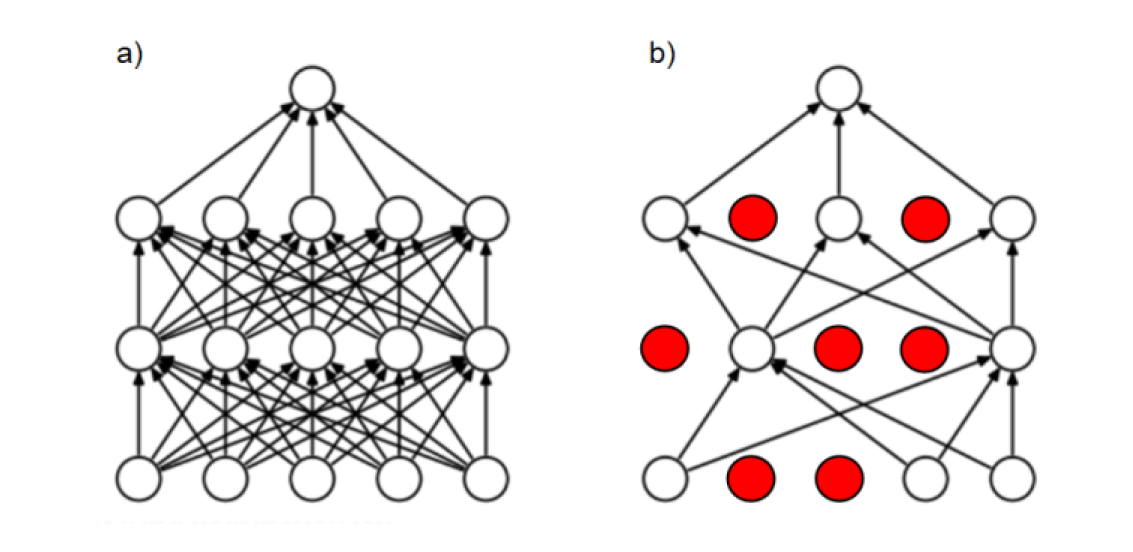
This regularization approach works by randomly ignoring sure neurons in coaching, throughout ahead and backward passes. The dropout fee controls the likelihood a sure neuron will likely be dropped. Consequently, for every coaching batch, a distinct subset of neurons is activated, resulting in a extra sturdy studying.
Residual Connections
The Xception mannequin has a number of skip connections all through its structure.
When coaching a really Deep Neural Community, the gradients used throughout coaching to replace weights turn into small and even typically vanish. It is a main downside all deep studying fashions face. So as to overcome this, researchers got here up with residual connections of their paper in 2016 on the ResNet mannequin.
Residual connections, additionally referred to as skip connections work by offering a connection between the sooner layers within the community with deeper or last layers within the community. These connections are used to assist the stream of gradients with out vanishing, as they bypass the intermediate layers.
When utilizing residual studying, the layers be taught to approximate the distinction (or residual) between the enter and the output, consequently, the unique operate 𝐻(𝑥) turns into 𝐻(𝑥)=𝐹(𝑥)+𝑥
Advantages of Residual Connections:
- Deeper Networks: Permits coaching of a lot deeper networks
- Improved Gradient Circulate: By offering a direct path for gradients to stream again to earlier layers, the vanishing gradient downside is solved.
- Higher Efficiency
As we speak, ResNet is a regular part in deep studying architectures.
Efficiency and Benchmarks
Within the unique paper on the Xception mannequin, it’s examined utilizing two totally different datasets: ImageNet and JFT. ImageNet is a well-liked dataset, which consists of 15 million labeled photos with 20,000 classes. For testing, a subset of ImageNet containing round 1.2 million coaching photos and 1,000 classes is used.
JFT is a big dataset that consists of over 350 million high-resolution photos annotated with labels of 17,000 courses.
The Xception mannequin is in contrast with inception v3 resulting from an identical parameter depend. This ensures that any efficiency distinction between the 2 fashions is a results of structure effectivity and never its dimension.
The outcome obtained for ImageNet confirmed a marginal distinction between the 2 fashions, nonetheless with a bigger dataset like JFT, the Xception mannequin exhibits a 4.3% relative enchancment. Furthermore, the Xception mannequin outperforms the ResNet-152 and VGG-16 fashions.
Functions of Xception Mannequin
Plan Identification
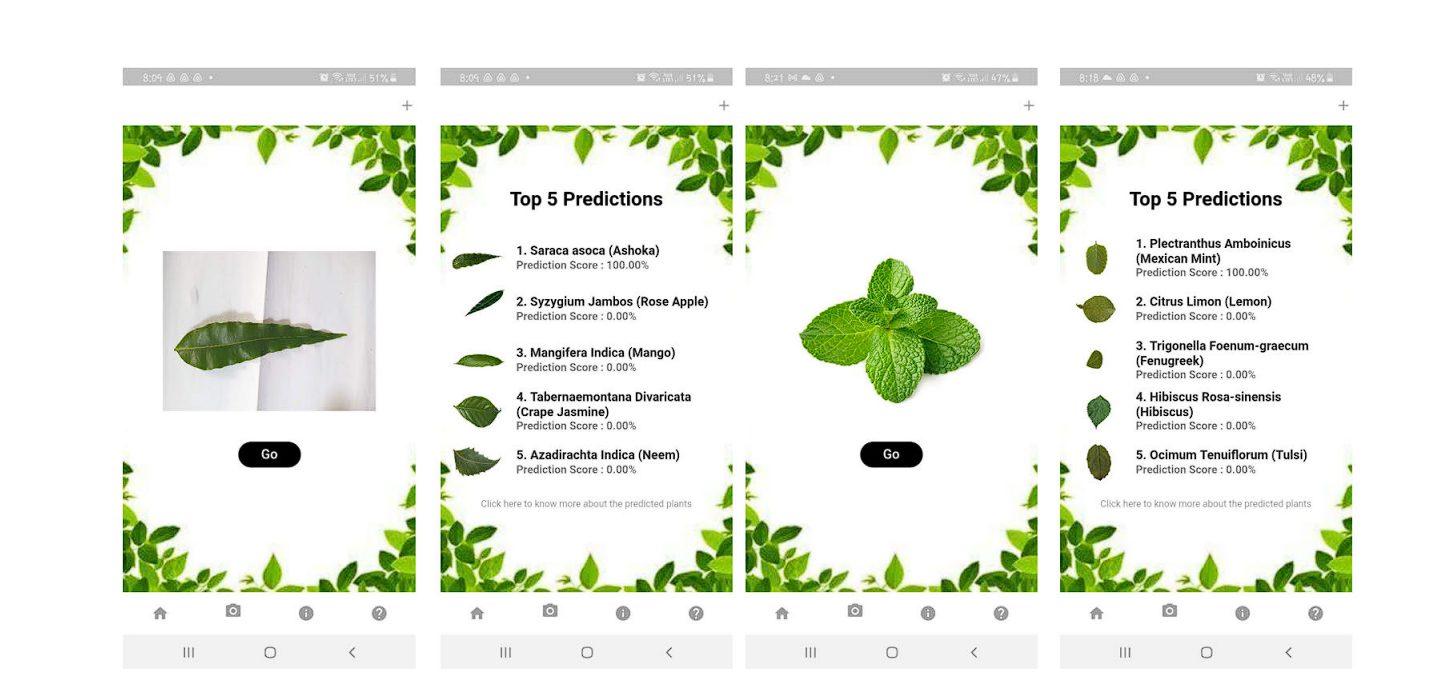
Researchers developed the DeepHerb utility, a system for routinely figuring out medicinal crops utilizing deep studying strategies. The DeepHerb dataset consists of 2515 leaf photos from 40 species of Indian herbs.
The researchers used numerous pre-trained convolutional neural community (CNN) architectures like VGG16, VGG19, InceptionV3, and Xception. The most effective-performing mannequin was the Xception mannequin which achieved an accuracy of 97.5%. The cell utility, HerbSnap, supplied herb identification with a 1-second prediction time.
Malware Detection

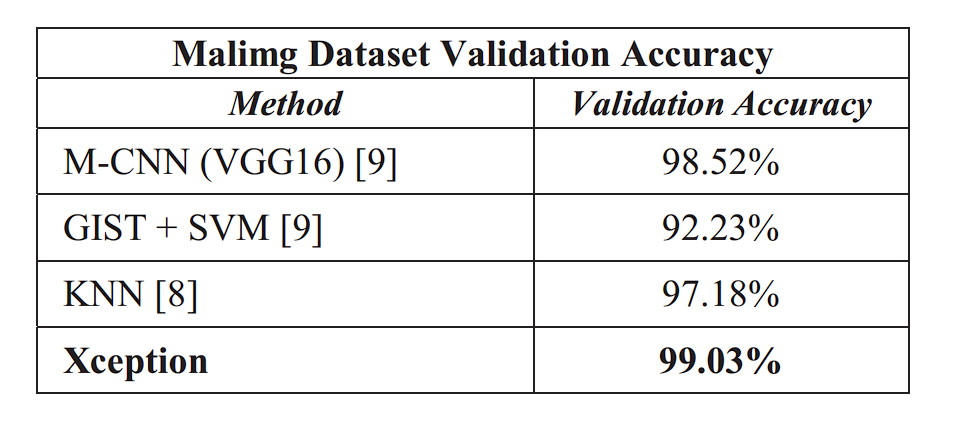
Researchers utilized Xception Community for malware classification utilizing switch studying. They first transformed malware information into grayscale photos after which labeled them utilizing a pre-trained Xception mannequin fine-tuned for malware detection. Two datasets had been used for this job: the Malimg Dataset (9,339 malware grayscale photos, 25 malware households) and the Microsoft Malware Dataset (10,868 malware grayscale photos, 10,873 testing samples, 9 malware households)
The ensuing Xception mannequin achieved an accuracy (99.04% on Malimg, 99.17% on Microsoft) in comparison with different strategies resembling VGG16.
The researchers additionally additional improved the accuracy by creating an Ensemble Mannequin that mixed the prediction outcomes from two forms of malware information (.asm and .bytes). The ensuing Ensemble Mannequin achieved an accuracy of 99.94%.
Leaf Illness Detection

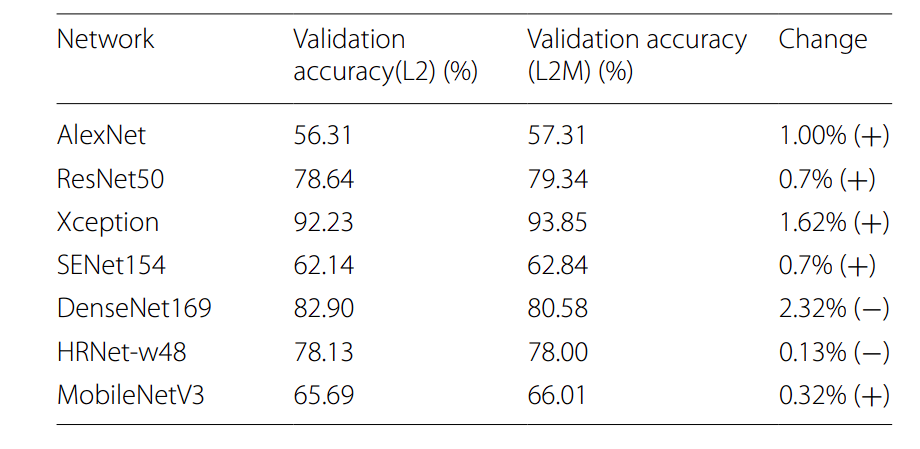
A research was performed on totally different illnesses present in peache, and its classifications utilizing totally different deep-learning fashions. Deep studying fashions that had been used consisted of MobileNet, ResNet, AlexNet, and extra. Amongst all these fashions, the Xception mannequin with L2M regularization achieved the very best rating of 93.85%, making it the simplest mannequin in that research for peach illness classification.
COVID-19 Detection
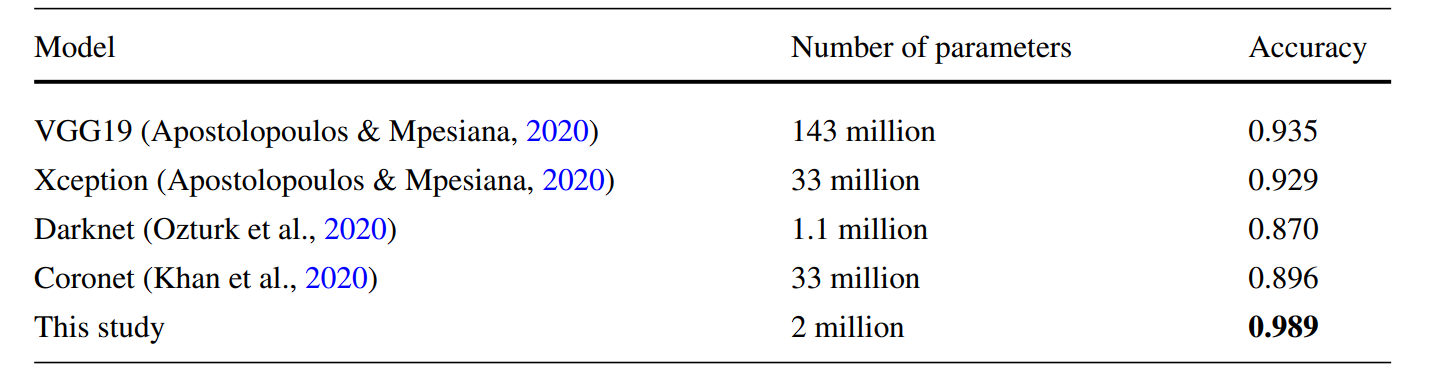
Researchers developed an improved Xception-based mannequin utilizing genetic algorithm strategies for community optimization. The ensuing Xception mannequin achieved excessive accuracy outcomes on the X-Ray photos—99.6% for 2 cass scores and 98.9% for 3 courses, considerably outperforming different deep studying (resembling DenseNet169, HRNet-w48, and AlexNet) used within the research.
Conclusion
On this weblog, we seemed on the Xception mannequin, a mannequin that improved upon the favored inception mannequin launched by Google. The important thing enchancment made within the Xception mannequin was using depthwise separable convolution. This noticed vital enchancment on giant datasets resembling JFT, nonetheless insignificant distinction was seen on smaller datasets resembling ImageNet.
Nevertheless, this confirmed that depthwise separable convolution was higher than the inception module. A number of researchers proved it by modifying the unique Xception mannequin to achieve a big benefit in accuracy over earlier fashions. Furthermore, after the Xception mannequin, MobileNets launched later additionally utilized depthwise convolution for a lightweight deep studying mannequin, able to working on cell phones.