

YOLO (You Solely Look As soon as) is a household of real-time object detection machine-learning algorithms. Object detection is a pc imaginative and prescient activity that makes use of neural networks to localize and classify objects in pictures. This activity has a variety of functions, from medical imaging to self-driving vehicles. A number of machine-learning algorithms are used for object detection, one among which is convolutional neural networks (CNNs).
CNNs are the bottom for any YOLO mannequin, researchers and engineers use these fashions for duties like object detection and segmentation. YOLO fashions are open-source, and they’re broadly used within the discipline. These fashions have been bettering from one model to the following, leading to higher accuracy, efficiency, and extra capabilities. This text will discover the complete YOLO household, we’ll begin from the unique to the newest, exploring their structure, use circumstances, and demos.
About us: Viso Suite is the entire pc imaginative and prescient for enterprises. Throughout the platform, groups can seamlessly construct, deploy, handle, and scale real-time functions for implementation throughout industries. Viso Suite is use case-agnostic, which means that it performs all visible AI-associated duties together with individuals counting, defect detection, and security monitoring. To study extra, guide a demo with our group.
YOLOv1 The Unique
Earlier than introducing YOLO object detection, researchers used convolutional neural community (CNN) based mostly approaches like R-CNN and Quick R-CNN. These approaches used a two-step course of that predicted the bounding containers after which used regression to categorise objects in these containers. This method was gradual and resource-extensive, however YOLO fashions revolutionized object detection. When the primary YOLO was developed by Joseph Redmon and Ali Farhadi again in 2016, it overcame most issues with conventional object detection algorithms, with a brand new and enhanced structure.
Structure
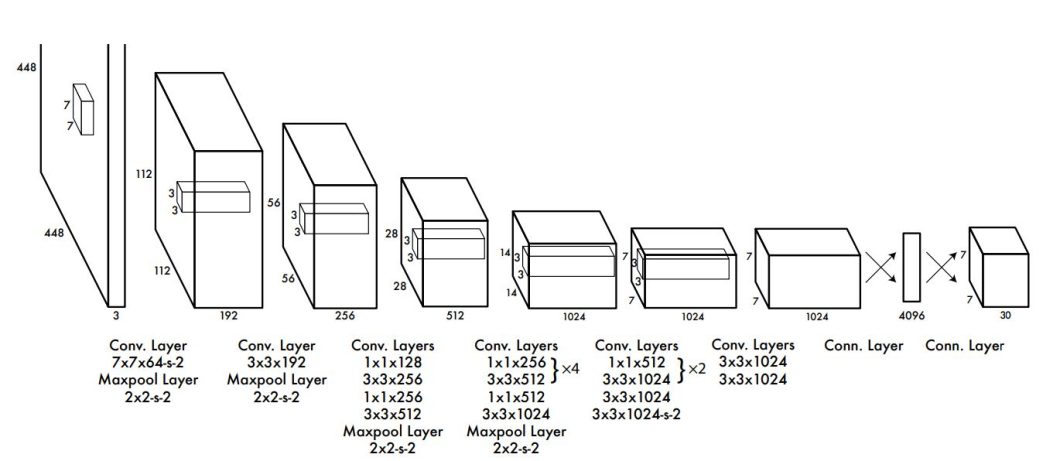
The unique YOLO structure consisted of 24 convolutional layers adopted by 2 totally linked layers impressed by the GoogLeNet mannequin for picture classification. The YOLOv1 method was the primary at its time.
The preliminary convolutional layers of the community extract options from the picture whereas the totally linked layers predict the output chances and coordinates. Which means each the bounding containers and the classification occur in a single step. This one-step course of streamlines the operation and achieves real-time effectivity. As well as, the YOLO structure used the next optimization methods.
- Leaky ReLU Activation: Leaky ReLU helps to forestall the “dying ReLU” downside, the place neurons can get caught in an inactive state throughout coaching.
- Dropout Regularization: YOLOv1 applies dropout regularization after the primary totally linked layer to forestall overfitting.
- Information Augmentation
How It Works
The essence of YOLO fashions is treating object detection as a regression downside. The YOLO method is to use a single convolutional neural community (CNN) to the total picture. This community divides the picture into areas and predicts bounding containers and chances for every area.
These bounding containers are weighted by the expected chances. These weights can then be thresholded to indicate solely the high-scoring detections.

YOLOv1 divides the enter picture right into a grid (SxS), and every grid cell is accountable for predicting bounding containers and sophistication chances for objects inside it. Every bounding field prediction features a confidence rating indicating the probability of an object being current within the field. The researchers calculate the arrogance scores utilizing methods like intersection over union (IOU), which can be utilized to filter the prediction. Regardless of the novelty and velocity of the YOLO method, it confronted some limitations like the next.
- Generalization: YOLOv1 struggles to detect new objects, not seen in coaching precisely.
- Spatial constraints: In YOLOv1, every grid cell predicts solely two containers and might solely have one class, which makes it wrestle with small objects that seem in teams, corresponding to flocks of birds.
- Loss Perform Limitations: The YOLOv1 loss perform treats errors the identical in small and enormous bounding containers. A small error in a big field is usually okay, however a small one has a a lot better impact on IOU.
- Localization Errors: One main challenge with YOLOv1 was accuracy, it usually mislocates the place objects are within the picture.
Now that we’ve got the fundamental mechanism of YOLOs lined, let’s have a look at how the researchers upgraded this mannequin’s capabilities within the subsequent model.
YOLOv2 (YOLO9000)
YOLO9000 got here one 12 months after YOLOv1 to handle the constraints in object detection datasets on the time. YOLO9000 was named that manner as a result of it could possibly detect over 9000 completely different object classes. This was transformative by way of accuracy and generalization.
The researchers behind YOLO9000 proposed a novel joint coaching algorithm that trains object detectors on each detection and classification information. This technique leverages labeled detection pictures to study to exactly localize objects and makes use of classification pictures to extend its vocabulary and robustness.
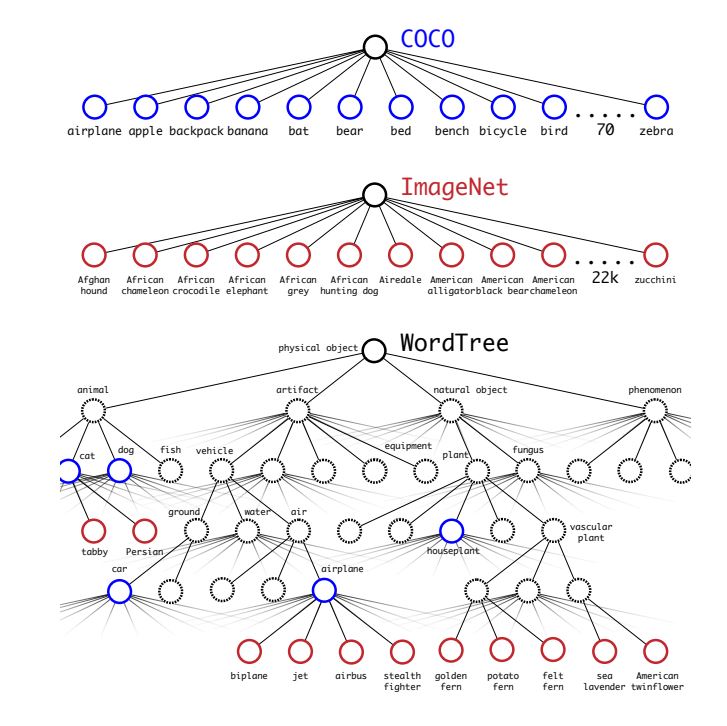
By combining the options from completely different datasets, for each classification and detection, YOLO9000 confirmed an excellent enchancment over its predecessor YOLOv1. YOLO9000 was introduced as higher, stronger, and quicker.
- Hierarchical Classification: A technique utilized in YOLO9000 based mostly on the WordTree construction, permitting elevated generalization to unseen objects, and elevated vocabulary or vary of objects.
- Architectural Adjustments: YOLO9000 launched a couple of modifications, like utilizing batch normalization for quicker coaching and stability, anchor containers or sliding window method, and makes use of Darknet-19 as a spine. Darknet-19 is a CNN with 19 layers designed to be correct and quick.
- Joint Coaching: An algorithm that enables the mannequin to make the most of the hierarchical classification framework and study from each classification and detection datasets like COCO and ImageNet.
Nevertheless, the YOLO household continued to enhance, subsequent we’ll have a look at YOLOv3.
YOLOv3 Little Adjustments, Massive Results
A few years later, the researchers behind YOLO got here up with the following model, YOLOv3. Whereas YOLO9000 was a state-of-the-art mannequin, object detection basically had its limitations. Enhancing accuracy and velocity is all the time one of many objectives of object detection fashions, which was the purpose of YOLOv3, little changes right here and there and we get a better-performing mannequin.
The enhancements begin with the bounding containers, whereas it nonetheless makes use of the sliding window method, YOLOv3 had some enhancements. YOLOv3 launched multi-scale predictions the place it predicts bounding containers at three completely different scales. This implies extra effectiveness in detecting objects of various sizes. This amongst different enhancements allowed YOLO again on the map of state-of-the-art fashions, with velocity and accuracy trade-offs.
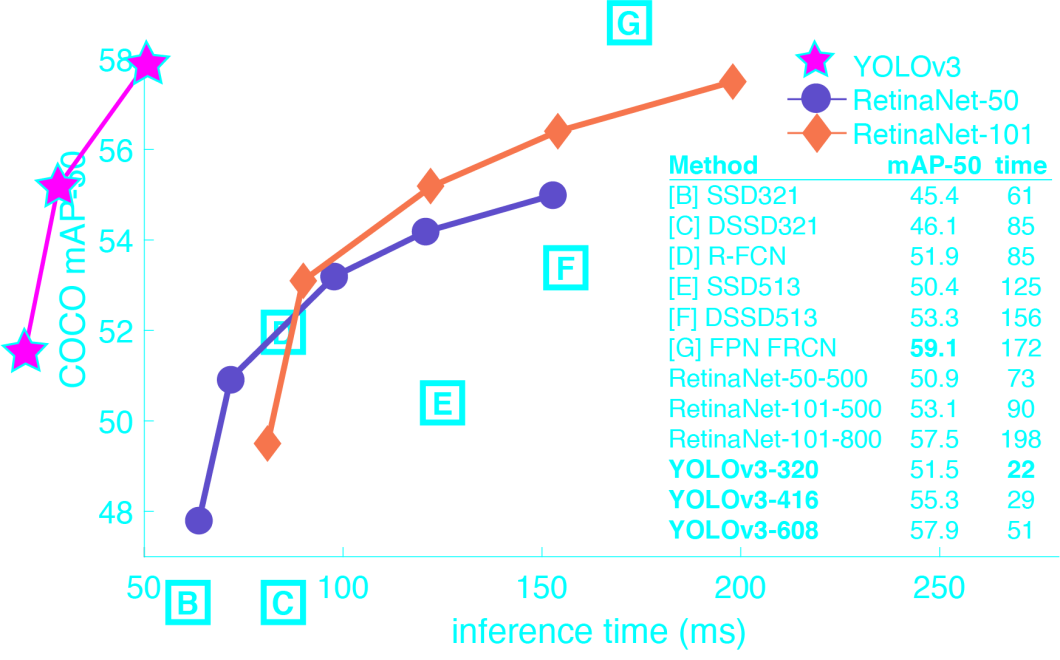
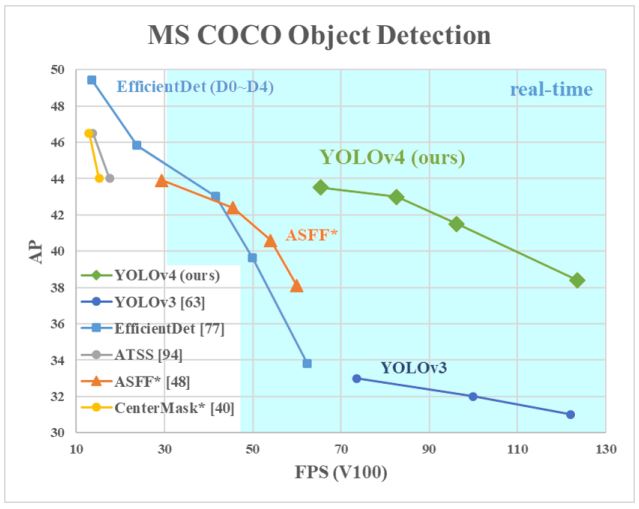
As seen within the graph YOLOv3 offered among the finest speeds and accuracies utilizing the imply common precision (mAP-50) metric. Moreover, YOLOv3 launched different enhancements as follows.
- Spine: YOLOv3 makes use of a greater and larger CNN spine which is Darknet-53 which consists of 53 layers and is a hybrid method between Darknet-19 and deep studying residual networks (Resnets), however extra environment friendly than ResNet-101 or ResNet-152.
- Predictions Throughout Scales: YOLOv3 predicts bounding containers at three completely different scales, just like function pyramid networks. This enables the mannequin to detect objects of assorted sizes extra successfully.
- Classifier: Unbiased logistic classifiers are used as a substitute of a softmax perform, permitting for a number of labels per field.
- Dataset: The researchers prepare YOLOv3 on the COCO dataset solely.
Additionally, whereas much less vital, YOLOv3 mounted just a little data-loading bug in YOLOv2, which helped by like 2 mAP factors. Up subsequent, let’s see how the YOLO mannequin advanced into YOLOv4.
YOLOv4 Optimization is Key
Persevering with the legacy of the YOLO household, YOLOv4 launched a number of enhancements and optimizations. Let’s dive deeper into the YOLOv4 mechanism.
Structure
Essentially the most notable change is the three half structure, whereas YOLOv4 remains to be a one-stage object detection community, the structure entails 3 foremost elements, spine, head, and neck. This structure break up was an important step within the evolution of YOLOs. The spine, head, and neck every have their very own performance in YOLOs.
The spine is the function extraction half, normally a CNN that learns options throughout layers. Then the neck refines and combines the extracted options from completely different ranges of the spine, making a wealthy and informative function illustration. Lastly, the top does the precise prediction, and outputs bounding containers, class chances, and objectness scores.
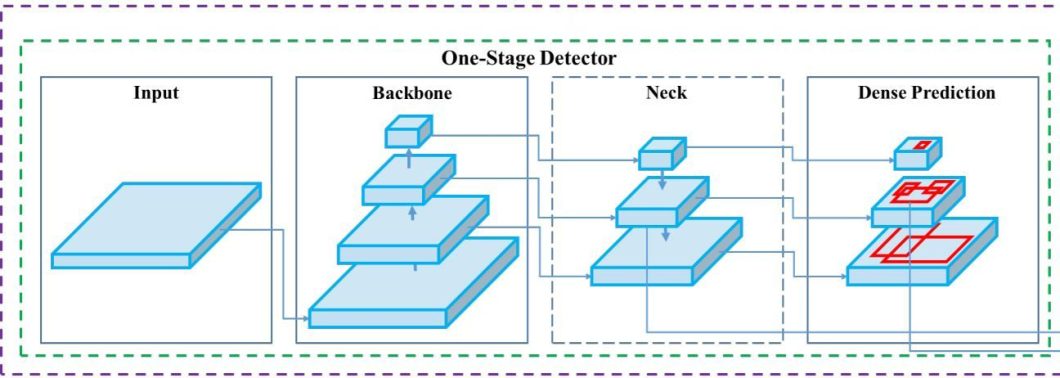
For YOLOv4 the researchers used the next elements for the spine, neck, and head.
- Spine: CSPDarknet53 is a convolutional neural community and spine for object detection that makes use of DarkNet-53 which makes use of a Cross Stage Partial Community (CSPNet) technique.
- Neck: Modified Spatial Pyramid Pooling (SPP) and Path aggregation community (PAN) have been used for YOLOv4, which produced extra granular function extraction, higher coaching, and higher efficiency.
- Head: YOLOv4 employs the (anchor-based) structure of YOLOv3 as the top of YOLOv4.
This was not all that YOLOv4 launched, there was a number of work on optimization and choosing the right strategies and methods, let’s discover these subsequent.
Optimization
The YOLOv4 mannequin got here with two baggage of strategies, because the researchers launched within the paper: Bag of Freebies (BoF) and Bag of Specials (BoS). These strategies have been instrumental within the efficiency of YOLOv4, on this part, we’ll discover the necessary strategies the researchers used.
- Mosaic Information Augmentation: This information augmentation technique combines 4 coaching pictures into one, enabling the mannequin to study to detect objects in a greater diversity of contexts and decreasing the necessity for giant mini-batch sizes. The researchers used it as part of the BoF for the spine coaching.
- Self-Adversarial Coaching (SAT): A two-stage information augmentation approach the place the community methods itself and modifies the enter picture to suppose there’s no object. Then, it trains on this modified picture to enhance robustness and generalization. Researchers used it as part of the BoF for the detector or head of the community.
- Cross mini-batch Normalization (CmBN): A modification of Cross-Iteration Batch Normalization (CBN) that makes coaching extra appropriate for a single GPU. Utilized by researchers as a part of the BoF for the detector.
- Modified Spatial Consideration Module (SAM): The researchers modify the unique SAM from spatial-wise consideration to point-wise consideration, enhancing the mannequin’s potential to concentrate on necessary options with out growing computational prices. Used as a part of the BoS as an extra block for the detector of the community.
Nevertheless, this isn’t all, YOLOv4 used many different methods inside the BoS and BoF, like Mish activation and cross-stage partial connections (CSP) for the spine as a part of the BoS. All these optimization modifications resulted in a state-of-the-art efficiency for YOLOv4, particularly in velocity, but additionally accuracy.
YOLOv5 The Most Cherished
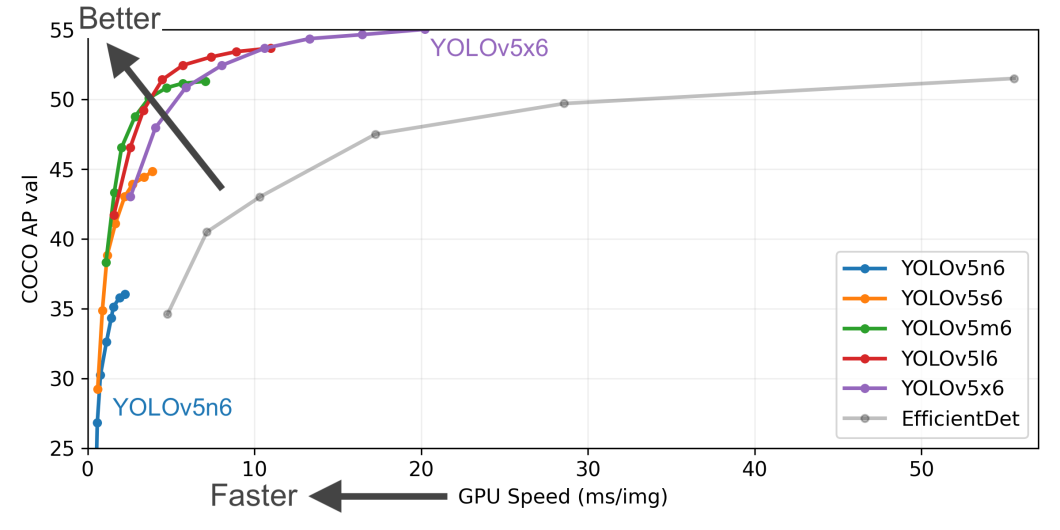
Whereas YOLOv5 didn’t include a devoted analysis paper, this mannequin has impressed all builders, engineers, and researchers. YOLOv5 got here just a few months after YOLOv4, there wasn’t a lot enchancment, nevertheless it was barely quicker. Ultralytics designed YOLOv5 for simpler implementation, and extra detailed documentation with a number of languages assist, most notably YOLOv5 was constructed on Pytorch making it simply usable for builders.
On the identical time, its predecessors have been barely more durable to implement. Ultralytics introduced YOLOv5 because the world’s most beloved imaginative and prescient AI, as well as, YOLOv5 got here with some nice options like completely different codecs for mannequin export, a coaching script to coach by yourself information, and a number of coaching methods like Check-Time Augmentation (TTA) and Mannequin Ensembling.
Demo
Since YOLOv5 could be very related in structure and dealing mechanism to YOLOv4 however has a neater implementation we are able to strive it out simply. This part will take a look at a pre-trained YOLOv5 mannequin on our pictures. This implementation will likely be performed on a Google Colab pocket book with Pytorch and will likely be straightforward for novices. Let’s get began.
import torch
mannequin = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True, trust_repo=True)
First, we import Pytorch and cargo the mannequin utilizing torch.hub.load, we’ll use the YOLOv5s mannequin which is a compact mannequin and really quick. Now that we’ve got the mannequin, let’s load some take a look at pictures and inference it.
im = '/content material/n09835506_ballplayer.jpeg' # file, Path, PIL.Picture, OpenCV, nparray, record outcomes = mannequin(im) # inference outcomes.save() #or .print(), .present(), .save(), .crop(), .pandas()
I will likely be utilizing some pattern pictures from the ImageNet dataset, the mannequin took round 17 milliseconds together with preprocessing to foretell pattern pictures. Under are the outcomes of three samples.

Ease of use, steady updates, a giant neighborhood, and good documentation make YOLOv5 the right compact mannequin that runs on gentle {hardware} and offers respectable accuracy in nearly real-time. YOLO fashions continued to evolve after YOLOv5 to YOLOv6 let’s discover that within the subsequent part.
YOLOv6 Industrial High quality
YOLOv6 emerges as a big evolution within the YOLO sequence, it introduces some key architectural and coaching modifications to realize a greater stability between velocity and accuracy. Notably, YOLOv6 distinguishes itself by specializing in industrial functions. This industrial focus provided deployment-ready networks and higher consideration of the constraints of real-world environments.
With the stability between velocity and accuracy, it may be run on generally used {hardware}, such because the Tesla T4 GPU making the deployment of object detection in industrial settings simpler than ever. YOLOv6 was not the one mannequin out there on the time, there have been YOLOv5, YOLOX, and YOLOv7 all competing candidates for environment friendly detectors to deploy. Now, let’s focus on the modifications that YOLOv6 launched.
Structure
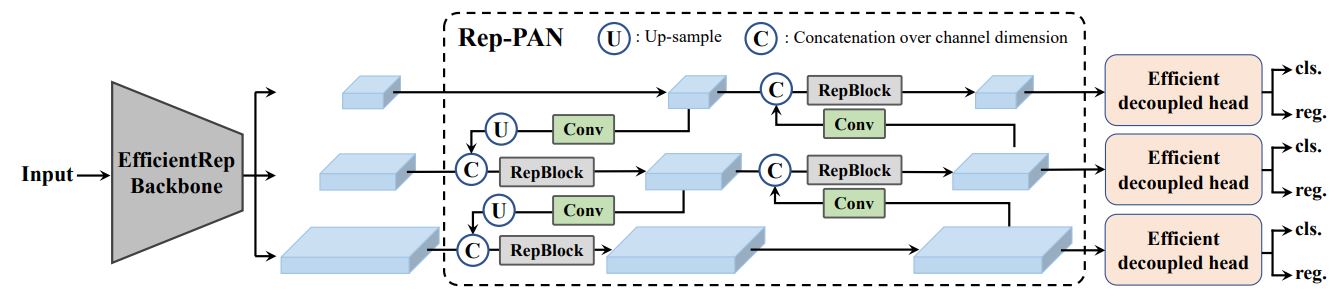
- Spine: The researchers construct the spine utilizing EfficientRep which is a hardware-aware CNN that includes RepBlock for small fashions (N and S) and CSPStackRep Block for bigger fashions (M and L).
- Neck: Makes use of Rep-PAN topology, enhancing the modified PAN topology from YOLOv4 and YOLOv5 with RepBlocks or CSPStackRep Blocks. Which supplies a extra environment friendly function aggregation from completely different ranges of the spine.
- Head: YOLOv6 launched the Environment friendly Decoupled Head simplifying the design for improved effectivity. It makes use of a hybrid-channel technique, decreasing the variety of center 3×3 convolutional layers and scaling the width collectively with the spine and neck.
YOLOv6 additionally incorporates a number of different methods to reinforce efficiency.
- Label Project: Makes use of Process Alignment Studying (TAL) to handle the misalignment between classification and field regression duties.
- Self-Distillation: It applies self-distillation to each classification and regression duties, bettering the accuracy much more.
- Loss Perform: It employs VariFocal Loss for classification and a mixture of SIoU and GIoU Loss for regression.
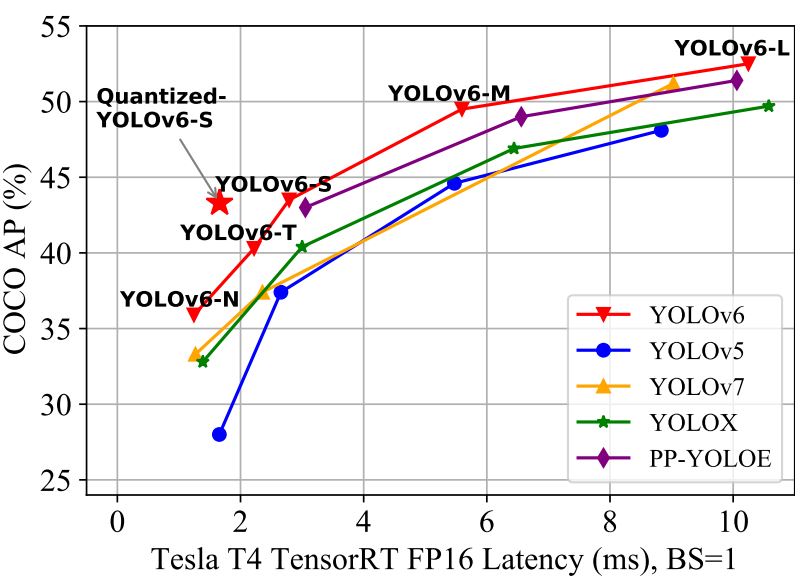
YOLOv6 represents a refined and enhanced method to object detection, constructing upon the strengths of its predecessors whereas introducing modern options to handle the challenges of real-world deployment. Its concentrate on effectivity, accuracy, and industrial applicability makes it a invaluable software for industrial functions.
YOLOv7: Trainable bag-of-freebies
Whereas technically YOLOv6 was launched earlier than YOLOv7, the manufacturing model of YOLOv6 got here after YOLOv7 and surpassed it in efficiency. Nevertheless, YOLOv7 launched a novel idea calling it the trainable bag of freebies (BoF). This features a sequence of fine-grained refinements moderately than an entire overhaul.
These refinements are primarily centered on optimizing the coaching course of and enhancing the mannequin’s potential to study efficient representations with out considerably growing the computational prices. Following are among the key options YOLOv7 launched.
- Mannequin Re-parameterization: YOLOv7 proposes a deliberate re-parameterized mannequin, which is a method relevant to layers in several networks with the idea of gradient propagation path.
- Dynamic Label Project: The coaching of the mannequin with a number of output layers presents a brand new challenge: “Methods to assign dynamic targets for the outputs of various branches?” To resolve this downside, YOLOv7 introduces a brand new label task technique known as coarse-to-fine lead guided label task.
- Prolonged and Compound Scaling: YOLOv7 proposes “lengthen” and “compound scaling” strategies for the article detector that may successfully make the most of parameters and computation.
YOLOv7 focuses on fine-grained refinements and optimization methods to reinforce the efficiency of real-time object detectors. Its emphasis on trainable bag-of-freebies, deep supervision, and architectural enhancements results in a big enhance in accuracy with out sacrificing velocity, making it a invaluable development within the YOLO sequence. Nevertheless, the evolution retains going producing YOLOv8 which is our topic subsequent.
YOLOv8
YOLOv8 is an iteration within the YOLO sequence of real-time object detectors, providing cutting-edge efficiency by way of accuracy and velocity. Nevertheless, YOLOv8 doesn’t have an official paper to it however just like YOLOv5 this was a user-friendly enhanced YOLO object detection mannequin. Developed by Ultralytics YOLOv8 introduces new options and optimizations that make it a super selection for varied object detection duties in a variety of functions. Here’s a fast overview of its options.
- Superior Spine and Neck Architectures
- Anchor-free Break up Ultralytics Head: YOLOv8 adopts an anchor-free break up Ultralytics head, which contributes to raised accuracy and a extra environment friendly detection course of in comparison with anchor-based approaches.
- Optimized Accuracy-Velocity Tradeoff
Along with all that YOLOv8 is a well-maintained mannequin by Ultralytics providing a various vary of fashions, every specialised for particular duties in pc imaginative and prescient like detection, segmentation, classification, and pose detection. Since YOLOv8 has ease of use by way of the Ultralytics library let’s strive it in a demo.
Demo
This demo will merely use the Ultralytics library in Python to deduce YOLOv8 fashions. There are lots of methods and choices to deduce YOLO fashions, here is a documentation of the prediction choices.
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8s mannequin
mannequin = YOLO("yolov8s.pt")
This may import the Ultralytics library and cargo the YOLOv8 small mannequin, which has stability between accuracy and velocity, if the Ultralytics library isn’t already put in, be sure to put in it in your pocket book with: !pip set up ultralytics. Now, let’s take a look at it on some pictures.
outcomes = mannequin("/content material/metropolis.jpg", save=True, conf=0.5)
This may run the detection activity, save the consequence, and solely embody bounding containers of not less than 0.5 confidence. Under is the results of the pattern picture I used.

YOLOv8 fashions obtain SOTA efficiency throughout varied benchmarking datasets. As an example, the YOLOv8n mannequin achieves a mAP (imply Common Precision) of 37.3 on the COCO dataset and a velocity of 0.99 ms on A100 TensorRT. Subsequent, let’s see how the YOLO household advanced additional with YOLOv9.
YOLOv9: Correct Studying
YOLOv9 takes a unique method in comparison with its predecessors, by straight addressing the problem of knowledge loss in deep neural networks. It introduces the idea of Programmable Gradient Info (PGI) and a brand new structure known as Generalized Environment friendly Layer Aggregation Community (GELAN) to fight info bottlenecks and guarantee dependable gradient move throughout coaching.
The researchers launched YOLOv9 as a result of present strategies ignore the truth that when enter information undergoes layer-by-layer function extraction and spatial transformation, a considerable amount of info will likely be misplaced. This info loss results in unreliable gradients and hinders the mannequin’s potential to study correct representations.
YOLOv9 introduces PGI, a novel technique for producing dependable gradients through the use of an auxiliary reversible department. This auxiliary department gives full enter info for calculating the target perform, guaranteeing that the gradients used to replace the community weights are extra informative. The reversible nature of the auxiliary department ensures that no info is misplaced through the feedforward course of.
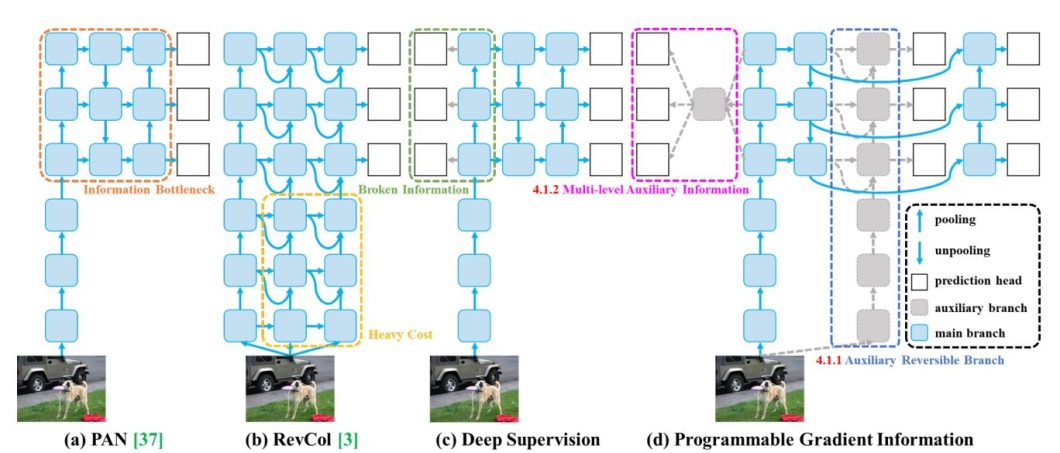
YOLOv9 additionally proposed GELAN as a brand new light-weight structure designed to maximise info move and facilitate the acquisition of related info for prediction. GELAN is a generalized model of the ELAN structure, making use of any computational block whereas sustaining effectivity and efficiency potential. The researchers designed it based mostly on gradient path planning, guaranteeing environment friendly info move by way of the community.

YOLOv9 presents a refreshed perspective on object detection by specializing in info move and gradient high quality. The introduction of PGI and GELAN, units YOLOv9 aside from its predecessors. This concentrate on the basics of knowledge processing in deep neural networks results in improved efficiency and a greater explainability of the training course of in object detection.
YOLOv10 Actual-Time Object Detection
The introduction of YOLOv10 was revolutionary for real-time end-to-end object detection. YOLOv10 surpassed all earlier velocity and accuracy benchmarks, reaching precise real-time object detection. YOLOv10 eliminates the necessity for non-maximum suppression (NMS) post-processing with NMS-Free Detection.
This not solely improves inference velocity but additionally simplifies the deployment course of. YOLOv10 launched a couple of key options like NMS-free coaching and a holistic design method that made it excel in all metrics.
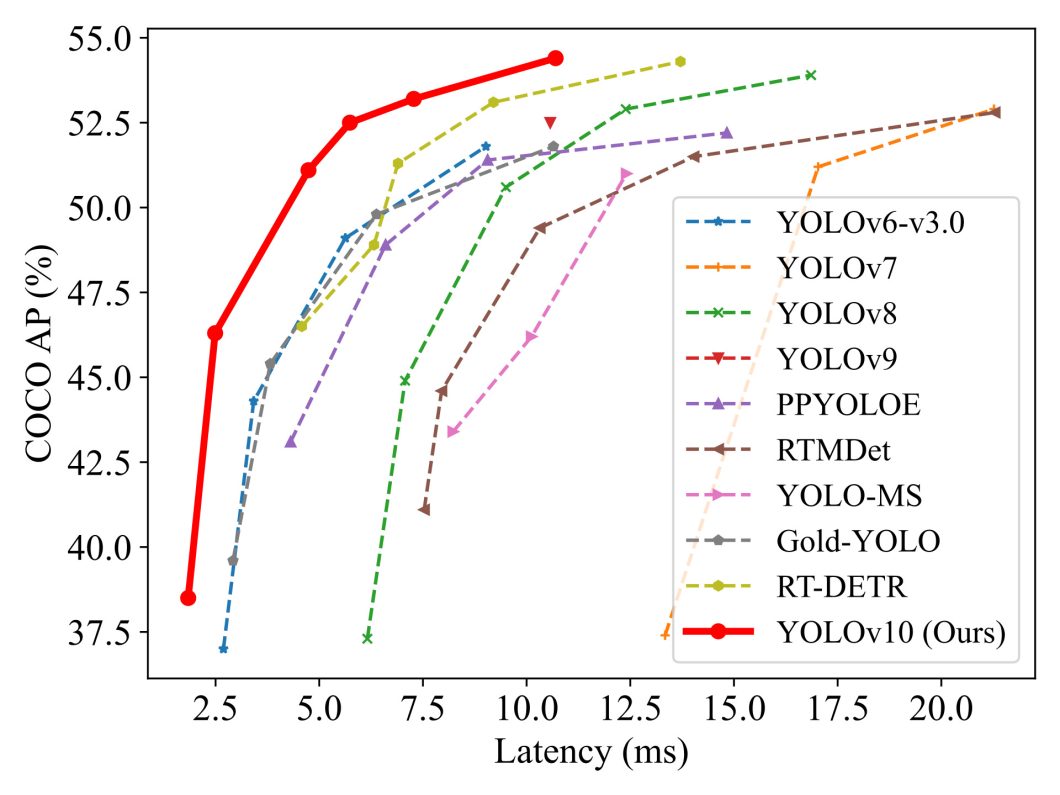
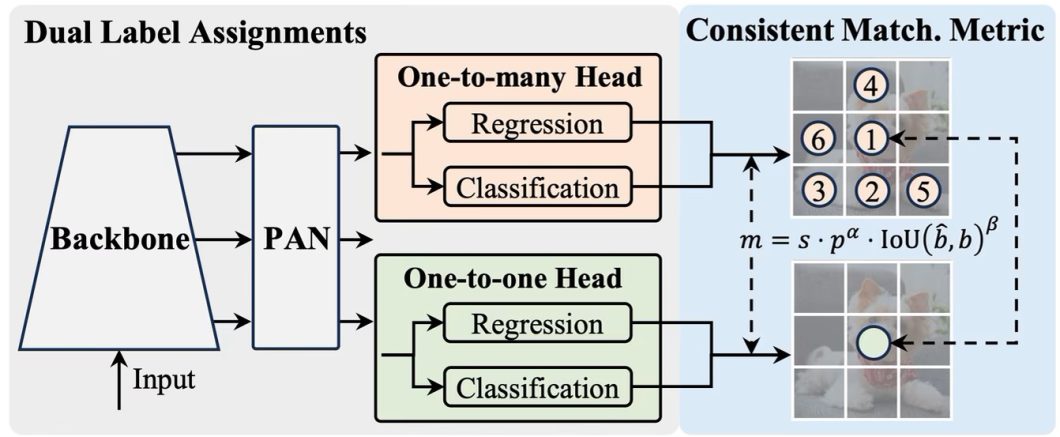
- NMS-Free Detection: YOLOv10 delivers a novel NMS-free coaching technique based mostly on constant twin assignments. It employs twin label assignments (one-to-many and one-to-one) and a constant matching metric to supply wealthy supervision throughout coaching whereas eliminating NMS throughout inference. Throughout inference, solely the one-to-one head is used, enabling NMS-free detection.
- Holistic Effectivity-Accuracy Pushed Design: YOLOv10 adopts a holistic method to mannequin design, optimizing varied elements for each effectivity and accuracy. It introduces a light-weight classification head, spatial-channel decoupled downsampling, and rank-guided block design to scale back computational value.
YOLO11: Architectural Enhancements
YOLO11 was launched in September 2024. It went by way of a sequence of architectural refinements and a concentrate on enhancing computational effectivity with out sacrificing accuracy.
It introduces novel elements just like the C3k2 block and the C2PSA block, which contribute to improved function extraction and processing. This leads to a barely higher efficiency, however with a lot fewer parameters for the mannequin. Following are the important thing options of YOLO11.
- C3k2 Block: YOLO11 introduces the C3k2 block, a computationally environment friendly implementation of the Cross Stage Partial (CSP) Bottleneck. It replaces the C2f block within the spine and neck, and employs two smaller convolutions as a substitute of 1 massive convolution, decreasing processing time.
- C2PSA Block: Introduces the Cross Stage Partial with Spatial Consideration (C2PSA) block after the Spatial Pyramid Pooling – Quick (SPPF) block to reinforce spatial consideration. This consideration mechanism permits the mannequin to focus extra successfully on necessary areas inside the picture, doubtlessly bettering detection accuracy.
With this, we’ve got mentioned the entire YOLO household of object detection fashions. However one thing tells me the evolution gained’t cease there, the innovation will proceed and we’ll see even higher performances sooner or later.
The Way forward for YOLO Fashions
The YOLO household has persistently pushed the boundaries of pc imaginative and prescient. It has advanced from a easy structure to a classy system. Every model has launched novel options and expanded the vary of supported duties.
Wanting forward, the pattern of accelerating accuracy, velocity, and multi-task capabilities will probably proceed. Potential areas of improvement embody the next.
- Improved Explainability: Making the mannequin’s decision-making course of extra clear.
- Enhanced Robustness: Making the mannequin extra resilient to difficult circumstances.
- Environment friendly Deployment: Optimizing the mannequin for varied {hardware} platforms.
The developments in YOLO fashions have vital implications for varied industries. YOLO’s potential to carry out real-time object detection has the potential to alter how we work together with the visible world. Nevertheless, it is very important handle moral issues and potential biases. Making certain equity, accountability, and transparency is essential for accountable innovation.