

The YOLOv7 algorithm is making large waves within the pc imaginative and prescient and machine studying communities. On this article, we’ll present the fundamentals of how YOLOv7 works and what makes it the very best object detector algorithm accessible immediately.
The latest YOLO algorithm surpasses all earlier object detection fashions and YOLO variations in each velocity and accuracy. It requires a number of occasions cheaper {hardware} than different neural networks and could be skilled a lot sooner on small datasets with none pre-trained weights.
Therefore, YOLOv7 is anticipated to turn out to be the business customary for object detection within the close to future, surpassing the earlier state-of-the-art for real-time functions (YOLO v4).
About us: Viso.ai supplies the one end-to-end pc imaginative and prescient software platform, Viso Suite. The software program infrastructure is utilized by main organizations to assemble information, prepare YOLOv7 fashions, and ship pc imaginative and prescient functions. Get a Demo on your firm.
YOLO Actual-Time Object Detection
What’s real-time object detection?
In pc imaginative and prescient, real-time object detection is a vital activity that’s usually a key element in pc imaginative and prescient techniques. Functions that use real-time object detection fashions embody video analytics, robotics, autonomous autos, multi-object monitoring and object counting, medical picture evaluation, and so forth.
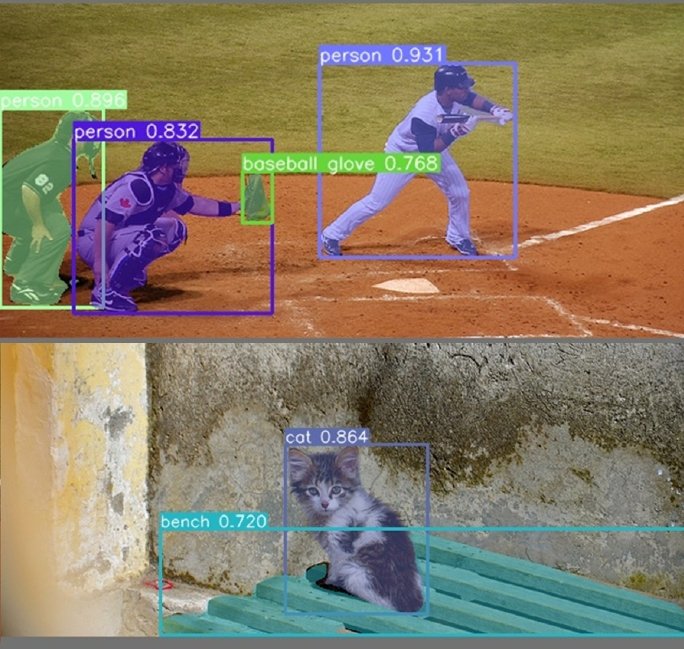
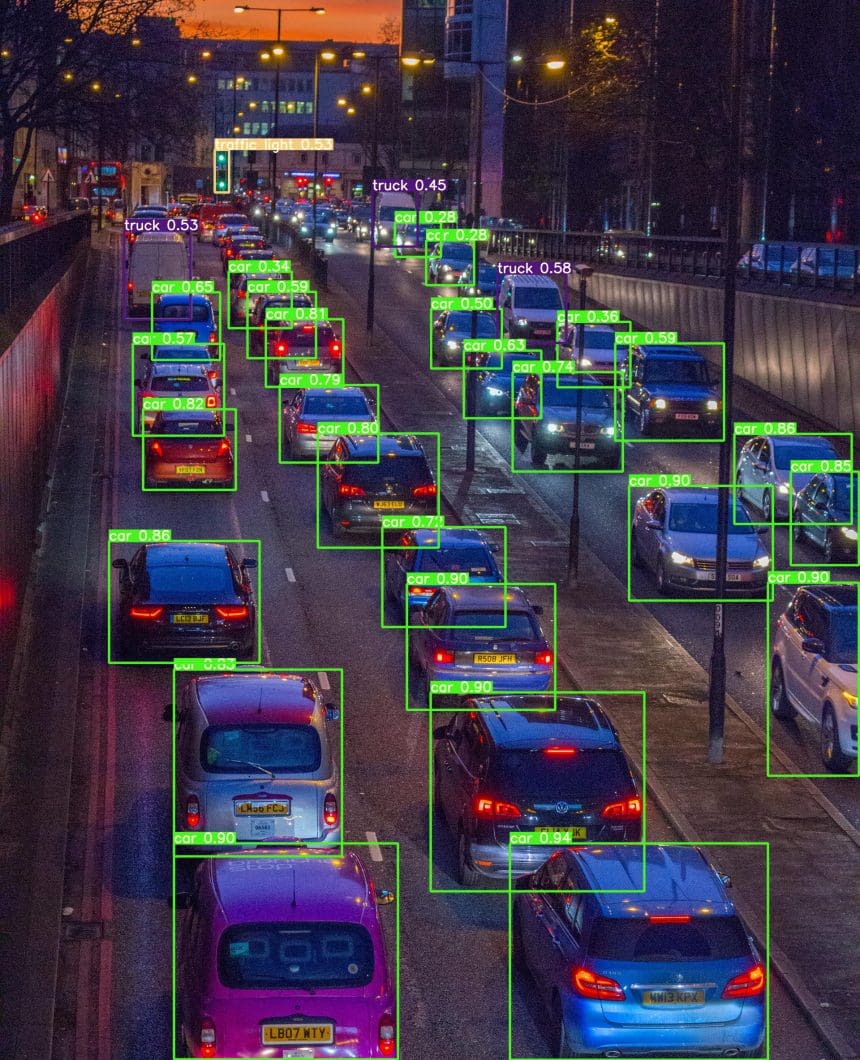
An object detector is an object detection algorithm that performs picture recognition duties by taking a picture as enter after which predicting bounding containers and sophistication possibilities for every object within the picture (see the instance picture under). Most algorithms use a convolutional neural community (CNN) to extract options from the picture to foretell the chance of realized lessons.

What’s YOLO in pc imaginative and prescient?
YOLO stands for “You Solely Look As soon as”; it’s a common household of real-time object detection algorithms. The unique YOLO object detector was first released in 2016. It was created by Joseph Redmon, Ali Farhadi, and Santosh Divvala. At launch, this structure was a lot sooner than different object detectors and have become state-of-the-art for real-time pc imaginative and prescient functions.
Since then, completely different variations and variants of YOLO have been proposed, every offering a major improve in efficiency and effectivity. The variations from YOLOv1 to the favored YOLOv3 have been created by then-graduate pupil Joseph Redmon and advisor Ali Farhadi. YOLOv4 was launched by Alexey Bochkovskiy, who continued the legacy since Redmon had stopped his pc imaginative and prescient analysis as a result of moral considerations.
YOLOv7 is the most recent official YOLO model created by the unique authors of the YOLO structure. We count on that many industrial networks will transfer instantly from YOLOv4 to v7, bypassing all the opposite numbers.

Unofficial YOLO variations
There have been some controversies within the pc imaginative and prescient neighborhood at any time when different researchers and firms printed their fashions as YOLO variations. A well-liked instance is YOLOv5 which was created by the corporate Ultralytics. It’s just like YOLOv4 however makes use of a unique framework, PyTorch, as an alternative of DarkNet. Nonetheless, the creator of YOLOv4, Alexey Bochkovskiy, provided benchmarks evaluating YOLOv4 vs. YOLOv5, displaying that v4 is equal or higher.
One other instance is YOLOv6 which was printed by the Chinese language firm Meituan (therefore the MT prefix of YOLOv6). And there’s additionally an unofficial YOLOv7 model that was launched within the yr earlier than the official YOLOv7 (there are two YOLOv7’s).
Each YOLOv5 and YOLOv6 usually are not thought-about a part of the official YOLO sequence however have been closely impressed by the unique one-stage YOLO structure. Critics argue that firms attempt to profit from the YOLO hype and that the papers weren’t adequately peer-reviewed or examined below the identical circumstances. Therefore, some say that the official YOLOv7 ought to be the true YOLOv5.

Actual-time object detectors and YOLO variations
Presently, state-of-the-art real-time object detectors are primarily primarily based on YOLO and FCOS (Totally Convolutional One-Stage Object Detection). The very best-performing object detectors are:
- YOLOv3 mannequin, launched by Redmon et al. in 2018
- YOLOv4 mannequin, launched by Bochkovskiy et al. in 2020,
- YOLOv4-tiny mannequin, research printed in 2021
- YOLOR (You Solely Study One Illustration) mannequin, published in 2021
- YOLOX mannequin, published in 2021
- NanoDet-Plus mannequin, published in 2021
- PP-YOLOE, an industrial object detector, published in 2022
- YOLOv5 mannequin v6.1 published by Ultralytics in 2022
- YOLOv7, published in 2022

Find out how to run object detection effectively on the Edge
Operating object detection in real-world pc imaginative and prescient functions is tough. Key challenges embody the allocation of computing assets, system robustness, scalability, effectivity, and latency. As well as, ML pc imaginative and prescient requires IoT communication (see AIoT) for information streaming with photos as enter and detections as output.
To beat these challenges, the idea of Edge AI has been launched, which leverages Edge Computing with Machine Studying (Edge ML, or Edge Intelligence). Edge AI modes ML processing from the cloud nearer to the info supply (digicam). Thus, Edge AI functions type distributed edge techniques with a number of, related edge gadgets or digital edge nodes (MEC or cloud).
The computing system that executes object detection is often some edge system with a CPU or GPU processor, in addition to neural processing models (NPU) or imaginative and prescient accelerators. Such NPU gadgets are more and more common AI {hardware} for pc imaginative and prescient inferencing, for instance:
Extra just lately, the design of environment friendly object detection architectures has targeted on fashions that can be utilized on CPU for scalable edge functions. Such fashions are primarily primarily based on MobileNEt, ShuffleNet, or GhostNet. Different mainstream object detectors have been optimized for GPU computing, they generally use ResNet, DarkNet, or DLA architectures.
The tip-to-end Edge AI imaginative and prescient platform Viso Suite helps you to enroll and handle edge gadgets, and use any AI {hardware}, digicam, and processor to run pc imaginative and prescient on the Edge. Request a demo right here.

What’s YOLOv7
YOLOv7 is the quickest and most correct real-time object detection mannequin for pc imaginative and prescient duties. The official YOLOv7 paper named “YOLOv7: Trainable bag-of-freebies units new state-of-the-art for real-time object detectors” was launched in July 2022 by Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao.
The YOLOv7 research paper has turn out to be immensely common in a matter of days. The supply code was launched as open supply below the GPL-3.0 license, a free copyleft license, and could be discovered within the official YOLOv7 GitHub repository that was awarded over 4.3k stars within the first month after launch. There’s additionally an entire appendix of the YOLOv7 paper.

The variations between the essential YOLOv7 variations
The completely different primary YOLOv7 fashions embody YOLOv7, YOLOv7-tiny, and YOLOv7-W6:
- YOLOv7 is the essential mannequin that’s optimized for atypical GPU computing.
- YOLOv7-tiny is a primary mannequin optimized for edge GPU. The suffix “tiny” of pc imaginative and prescient fashions signifies that they’re optimized for Edge AI and deep studying workloads, and extra light-weight to run ML on cellular computing gadgets or distributed edge servers and gadgets. This mannequin is necessary for distributed real-world pc imaginative and prescient functions. In comparison with the opposite variations, the edge-optimized YOLOv7-tiny makes use of leaky ReLU because the activation perform, whereas different fashions use SiLU because the activation perform.
- YOLOv7-W6 is a primary mannequin optimized for cloud GPU computing. Such Cloud Graphics Items (GPUs) are pc cases for operating functions to deal with large AI and deep studying workloads within the cloud with out requiring GPUs to be deployed on the native consumer system.
Different variations embody YOLOv7-X, YOLOv7-E6, and YOLOv7-D6, which have been obtained by making use of the proposed compound scaling technique (see YOLOv7 structure additional under) to scale up the depth and width of your complete mannequin.

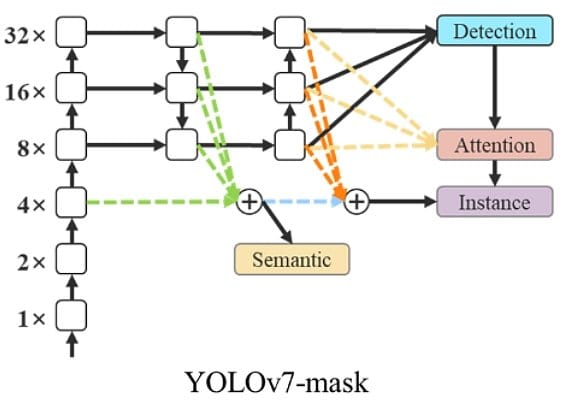
YOLOv7-mask
The combination of YOLOv7 with BlendMask is used to carry out occasion segmentation. Due to this fact, the YOLOv7 object detection mannequin was fine-tuned on the MS COCO occasion segmentation dataset and skilled for 30 epochs. It achieves state-of-the-art real-time occasion segmentation outcomes.
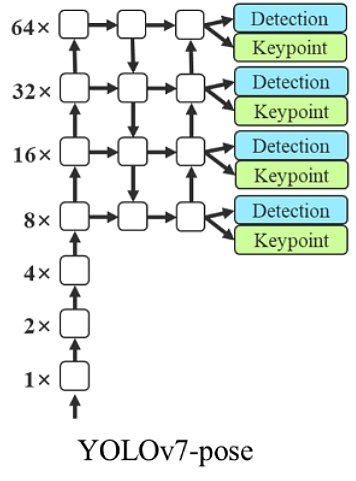
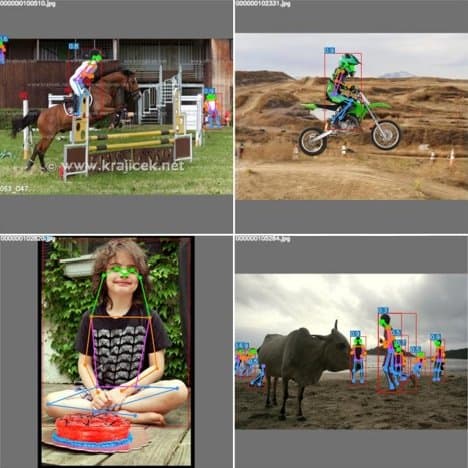
YOLOv7-pose
The combination of YOLOv7 with YOLO-Pose permits keypoint detection for Pose Estimation. The authors fine-tuned a YOLOv7-W6 folks detection mannequin on the MS COCO keypoint detection dataset and achieved state-of-the-art real-time pose estimation efficiency.
What’s new with YOLOv7?
YOLOv7 supplies a enormously improved real-time object detection accuracy with out growing the inference prices. As beforehand proven within the benchmarks, when in comparison with different identified object detectors, YOLOv7 can successfully scale back about 40% parameters and 50% computation of state-of-the-art real-time object detections, and obtain sooner inference velocity and better detection accuracy.
Typically, YOLOv7 supplies a sooner and stronger community structure that gives a more practical characteristic integration technique, extra correct object detection efficiency, a extra strong loss perform, and an elevated label task and mannequin coaching effectivity.
Because of this, YOLOv7 requires a number of occasions cheaper computing {hardware} than different deep studying fashions. It may be skilled a lot sooner on small datasets with none pre-trained weights.
The authors prepare YOLOv7 utilizing the MS COCO dataset with out utilizing every other picture datasets or pre-trained mannequin weights. Much like Scaled YOLOv4, YOLOv7 backbones don’t use Picture Internet pre-trained backbones (similar to YOLOv3).
The YOLOv7 paper introduces the next main adjustments. Later on this article, we’ll describe these architectural adjustments and the way YOLOv7 works.
- YOLOv7 Structure
- Prolonged Environment friendly Layer Aggregation Community (E-ELAN)
- Mannequin Scaling for Concatenation primarily based Fashions
- Trainable Bag of Freebies
- Deliberate re-parameterized convolution
- Coarse for auxiliary and effective for lead loss
What are Freebies in YOLOv7?
Bat-of-freebies options (extra optimum community construction, loss perform, and so forth.) improve accuracy with out reducing detection velocity. That’s why YOLOv7 will increase each velocity and accuracy in comparison with earlier YOLO variations.
The time period was launched within the YOLOv4 paper. Normally, a standard object detector is skilled off-line. Consequently, researchers all the time wish to take this benefit and develop higher coaching strategies that may make the article detector obtain higher accuracy with out growing the inference price (examine pc imaginative and prescient prices). The authors name these strategies that solely change the coaching technique or solely improve the coaching price a “bag of freebies”.
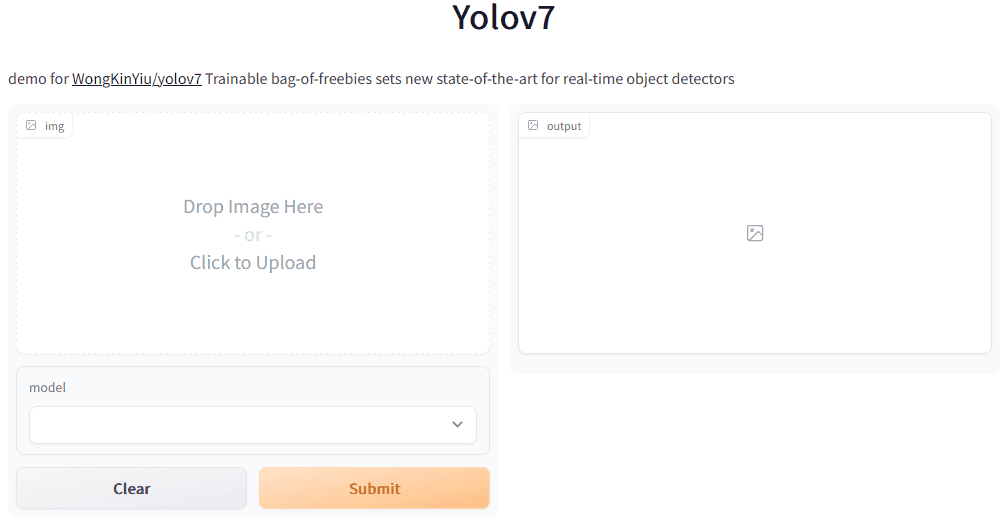
The place can I rapidly check YOLOv7?
Here’s a very quick option to check the brand new YOLOv7 deep studying mannequin instantly on Hugging Face: Find it here. This lets you
- (1) add your individual photos out of your native system,
- (2) choose a YOLOv7 mannequin, and
- (3) generate an output picture with label containers.
For the reason that DL mannequin was skilled on the COCO dataset, it is going to carry out picture recognition to detect the default COCO lessons (discover them in our information about MS COCO).
Efficiency of YOLOv7 Object Detection
The YOLOv7 efficiency was evaluated primarily based on earlier YOLO variations (YOLOv4 and YOLOv5) and YOLOR as baselines. The fashions have been skilled with the identical settings. The brand new YOLOv7 exhibits the very best speed-to-accuracy steadiness in comparison with state-of-the-art object detectors.
Typically, YOLOv7 surpasses all earlier object detectors when it comes to each velocity and accuracy, starting from 5 FPS to as a lot as 160 FPS. The YOLO v7 algorithm achieves the highest accuracy amongst all different real-time object detection fashions – whereas reaching 30 FPS or increased utilizing a GPU V100.

In comparison with the very best performing Cascade-Masks R-CNN fashions, YOLOv7 achieves 2% increased accuracy at a dramatically elevated inference velocity (509% sooner). That is spectacular as a result of such R-CNN variations use multi-step architectures that beforehand achieved considerably increased detection accuracies than single-stage detector architectures.
YOLOv7 outperforms YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, DETR, ViT Adapter-B, and plenty of extra object detection algorithms in velocity and accuracy.
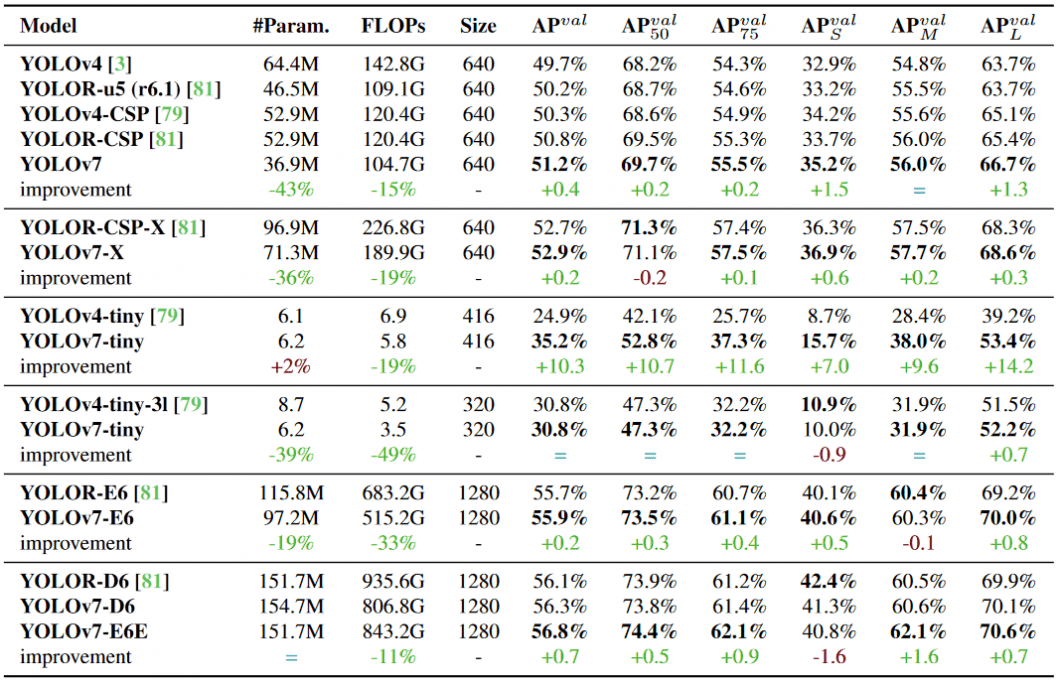
YOLOv7 vs YOLOv4 comparability
As compared with YOLOv4, YOLOv7 reduces the variety of parameters by 75%, requires 36% much less computation, and achieves 1.5% increased AP (common precision).
In comparison with the edge-optimized model YOLOv4-tiny, YOLOv7-tiny reduces the variety of parameters by 39%, whereas additionally lowering computation by 49%, whereas reaching the identical AP.
YOLOv7 vs YOLOR comparability
In comparison with YOLOR, Yolov7 reduces the variety of parameters by 43% parameters, requires 15% much less computation, and achieves 0.4% increased AP.
When evaluating YOLOv7 vs. YOLOR utilizing the enter decision 1280, YOLOv7 achieves an 8 FPS sooner inference velocity with an elevated detection charge (+1% AP).
When evaluating YOLOv7 with YOLOR, the YOLOv7-D6 achieves a comparable inference velocity, however a barely increased detection efficiency (+0.8% AP).
YOLOv7 vs YOLOv5 comparability
In comparison with YOLOv5-N, YOLOv7-tiny is 127 FPS sooner and 10.7% extra correct on AP. The model YOLOv7-X achieves 114 FPS inference velocity in comparison with the comparable YOLOv5-L with 99 FPS, whereas YOLOv7 achieves a greater accuracy (increased AP by 3.9%).
In contrast with fashions of an analogous scale, the YOLOv7-X achieves a 21 FPS sooner inference velocity than YOLOv5-X. Additionally, YOLOv7 reduces the variety of parameters by 22% and requires 8% much less computation whereas growing the common precision by 2.2%.
Evaluating YOLOv7 vs. YOLOv5, the YOLOv7-E6 structure requires 45% fewer parameters in comparison with YOLOv5-X6, and 63% much less computation whereas reaching a 47% sooner inference velocity.
YOLOv7 vs PP-YOLOE comparability
In comparison with PP-YOLOE-L, YOLOv7 achieves a body charge of 161 FPS in comparison with solely 78 FPS with the identical AP of 51.4%. Therefore, YOLOv7 achieves an 83 FPS or 106% sooner inference velocity. When it comes to parameter utilization, YOLOv7 is 41% extra environment friendly.
YOLOv7 vs YOLOv6 comparability
In comparison with the beforehand most correct YOLOv6 mannequin (56.8% AP), the YOLOv7 real-time mannequin achieves a 13.7% increased AP (43.1% AP) on the COCO dataset.
Any evaluating the lighter Edge mannequin variations below equivalent circumstances (V100 GPU, batch=32) on the COCO dataset, YOLOv7-tiny is over 25% sooner whereas reaching a barely increased AP (+0.2% AP) than YOLOv6-n.
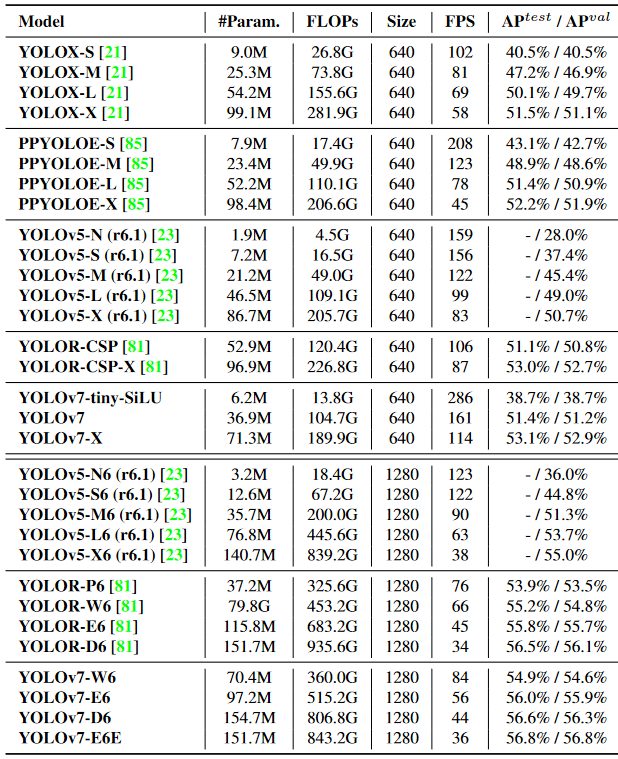
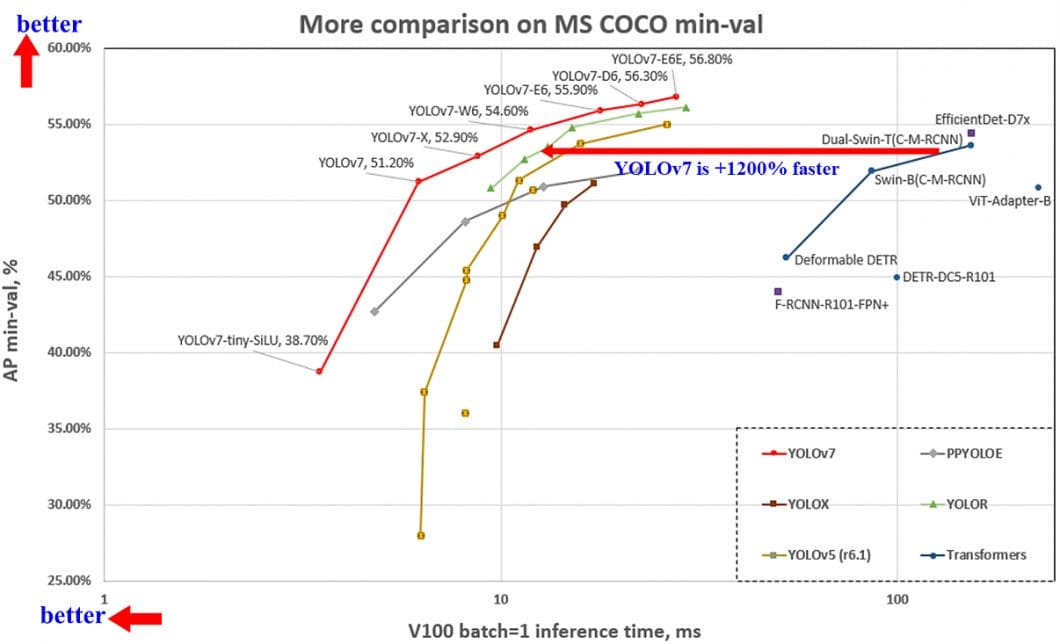
YOLOv7 Structure
The YOLOv7 structure is predicated on earlier YOLO mannequin architectures, particularly YOLOv4, Scaled YOLOv4, and YOLO-R. Within the following, we’ll present a high-level overview of a very powerful elements which can be detailed within the YOLOv7 paper. To study extra about deep studying architectures, take a look at our article in regards to the three common sorts of Deep Neural Networks.
Prolonged Environment friendly Layer Aggregation Community (E-ELAN)
The computational block within the YOLOv7 spine is known as E-ELAN, standing for Prolonged Environment friendly Layer Aggregation Community. The E-ELAN structure of YOLOv7 allows the mannequin to study higher by utilizing “develop, shuffle, merge cardinality” to realize the power to repeatedly enhance the training capacity of the community with out destroying the unique gradient path.
YOLOv7 Compound Mannequin Scaling
The primary objective of mannequin scaling is to regulate key attributes of the mannequin to generate fashions that meet the wants of various software necessities. For instance, mannequin scaling can optimize the mannequin width (variety of channels), depth (variety of levels), and backbone (enter picture dimension).
In conventional approaches with concatenation-based architectures (for instance, ResNet or PlainNet), completely different scaling components can’t be analyzed independently and have to be thought-about collectively. As an example, scaling-up mannequin depth will trigger a ratio change between the enter channel and output channel of a transition layer, which in flip might result in a lower in {hardware} utilization of the mannequin.
That is why YOLOv7 introduces compound mannequin scaling for a concatenation-based mannequin. The compound scaling technique permits to take care of the properties that the mannequin had on the preliminary design and thus preserve the optimum construction.
And that is how compound mannequin scaling works: For instance, scaling the depth issue of a computational block additionally requires a change within the output channel of that block. Then, width issue scaling is carried out with the identical stage of change on the transition layers.
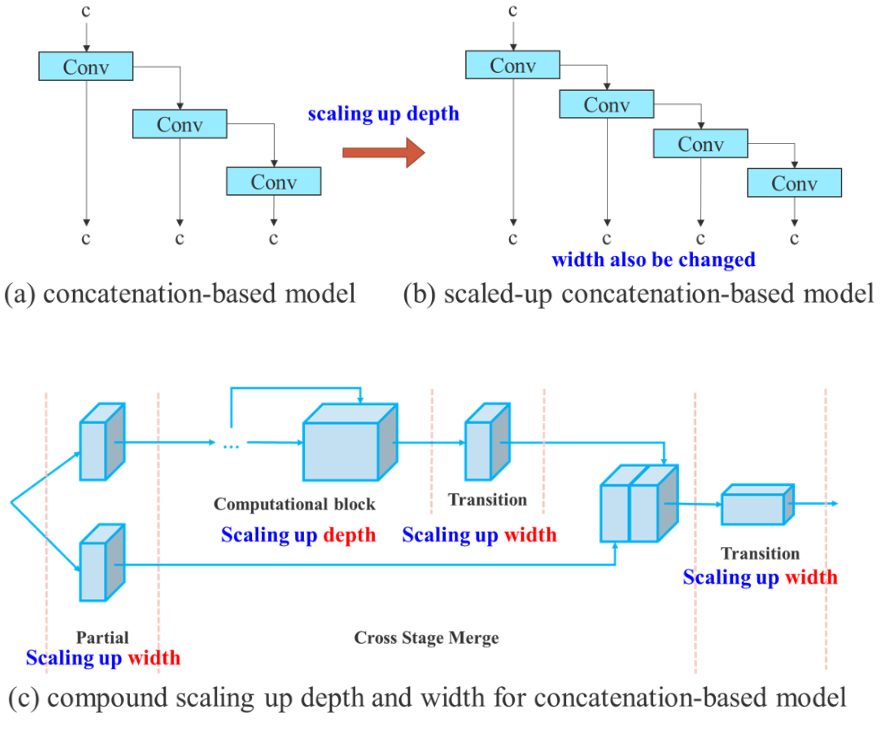
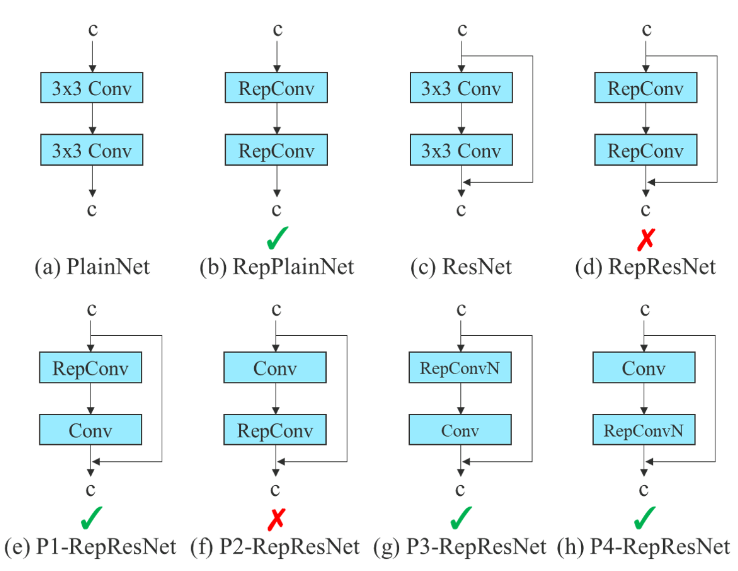
Deliberate re-parameterized convolution
Whereas RepConv has achieved nice efficiency in VGG architectures, the direct software in ResNet or DenseNet results in vital accuracy loss. In YOLOv7, the structure of deliberate re-parameterized convolution makes use of RepConv with out identification connection (RepConvN).
The thought is to keep away from that there’s an identification connection when a convolutional layer with residual or concatenation is changed by re-parameterized convolution.
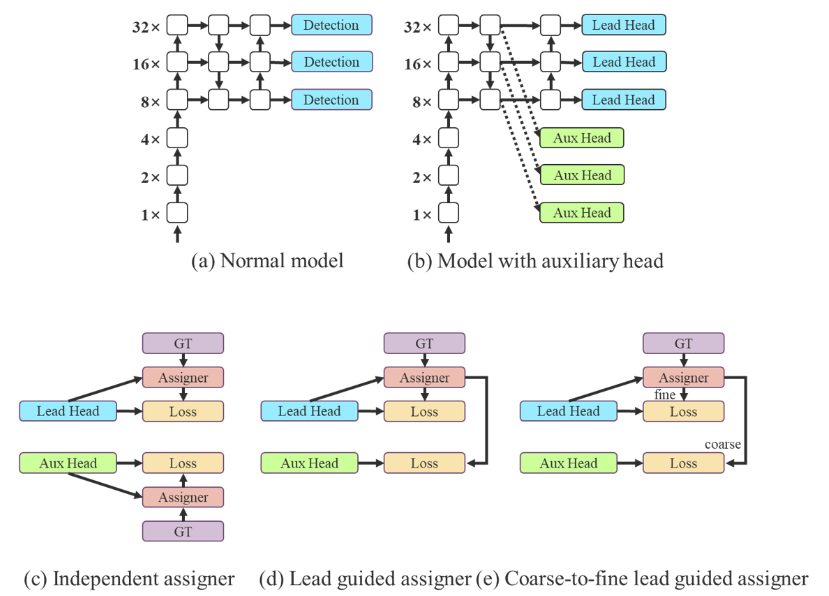
Coarse for auxiliary and effective for lead loss
A YOLO structure comprises a spine, a neck, and a head. The top comprises the anticipated mannequin outputs. Impressed by Deep Supervision, a method usually utilized in coaching deep neural networks, YOLOv7 is just not restricted to 1 single head. The top accountable for the ultimate output known as the lead head, and the top used to help coaching within the center layers is known as auxiliary head.
As well as, and to boost the deep community coaching, a Label Assigner mechanism was launched that considers community prediction outcomes along with the bottom reality after which assigns comfortable labels. In comparison with conventional label task that instantly refers back to the floor reality to generate laborious labels primarily based on given guidelines, dependable comfortable labels use calculation and optimization strategies that additionally take into account the standard and distribution of prediction output along with the bottom reality.
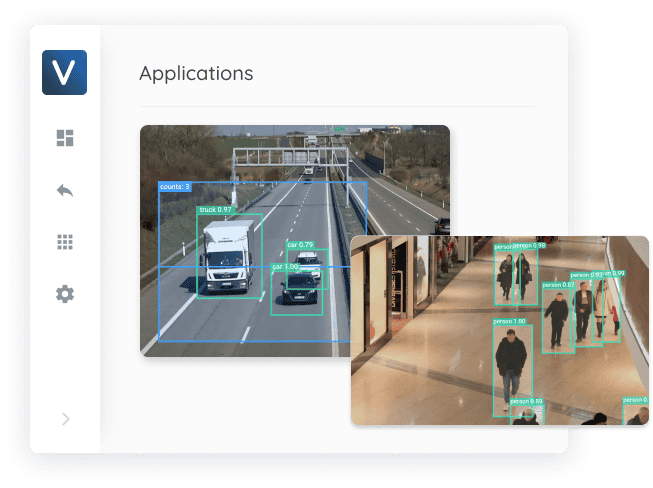
Functions of YOLOv7
Within the following, we’ll checklist real-world functions of YOLOv7 throughout completely different industries. It is very important perceive that the article detector is just one a part of a whole imaginative and prescient pipeline that usually features a sequence of steps – from digicam integration and picture acquisition to processing, output formatting, and system integration.
Safety and surveillance
Object detection is utilized in safety and surveillance to establish and monitor objects in a given space. This can be utilized for safety functions, similar to figuring out potential threats, or for monitoring the actions of individuals or objects in a pre-defined area (perimeter monitoring). Object detection can also be an integral a part of many facial recognition techniques.
In case you are on the lookout for an open-source deep studying library for face recognition, take a look at DeepFace.

Sensible metropolis and visitors administration
YOLOv7 allows object detection as utilized in visitors administration techniques to detect autos and pedestrians at intersections. Therefore, object detection has many use circumstances in sensible cities, to investigate massive crowds of individuals and examine infrastructure.
AI Retail analytics
Functions of pc imaginative and prescient in retail are of nice significance for retailers with bodily shops to digitize their operations. Visible AI allows data-driven insights which can be in any other case solely accessible in e-commerce (buyer habits, customer path, buyer expertise, and so forth.).
Object detection is used to detect and monitor buyer and worker motion patterns and footfall, enhance the accuracy of stock monitoring, improve safety, and way more.
Manufacturing and Vitality
Object detection expertise is a extremely disruptive rising tech in industrial manufacturing. YOLOv7 algorithms can be utilized to acknowledge and monitor objects as they transfer by way of a manufacturing line, permitting for extra environment friendly and correct manufacturing.
Moreover, object detection is used for high quality management and defect detection in merchandise or parts as they’re being manufactured. Conventional machine imaginative and prescient is more and more changed with trendy deep studying strategies. AI imaginative and prescient functions that assist keep away from interruptions or delays are sometimes of immense enterprise worth. Discover our article about AI imaginative and prescient in oil and fuel.

Autonomous Autos
Object detection is a key expertise for self-driving vehicles the place it’s used to detect different autos, pedestrians, and obstacles mechanically. AI imaginative and prescient can also be utilized in Aviation, for autonomous drones, asset administration, and even missile applied sciences.
Visible AI in Healthcare
One of the necessary functions for object detection is within the area of healthcare. Specifically, hospitals and clinics use it to detect and monitor medical tools, provides, and sufferers. This helps to maintain monitor of every thing that is happening within the hospital (affected person motion), permits for extra environment friendly stock administration, and improves affected person security. Additionally, physicians use object detection algorithms to help the prognosis of circumstances with medical imaging, similar to X-rays and MRI scans.
Getting Began
At viso.ai, we energy the enterprise no-code pc imaginative and prescient platform Viso Suite. The tip-to-end answer permits to construct, deploy and scale real-time pc imaginative and prescient functions on the Edge. Viso Suite absolutely integrates the brand new YOLOv7 mannequin and permits to coach YOLOv7 fashions with pre-built notebooks, handle mannequin variations and use them in highly effective imaginative and prescient pipelines.
Get in contact with us and request a private demo.
Learn extra about associated matters: