

July sixth 2022 can be marked down as a landmark in AI historical past as a result of it was on this present day when YOLOv7 was launched. Ever since its launch, the YOLOv7 has been the most well liked subject within the Laptop Imaginative and prescient developer neighborhood, and for the precise causes. YOLOv7 is already being thought to be a milestone within the object detection trade.
Shortly after the YOLOv7 paper was published, it turned up because the quickest, and most correct real-time objection detection mannequin. However how does YOLOv7 outcompete its predecessors? What makes YOLOv7 so environment friendly in performing pc imaginative and prescient duties?
On this article we’ll attempt to analyze the YOLOv7 mannequin, and attempt to discover the reply to why YOLOv7 is now changing into trade normal? However earlier than we will reply that, we can have to take a look on the transient historical past of object detection.
What’s Object Detection?
Object detection is a department in pc imaginative and prescient that identifies and locates objects in a picture, or a video file. Object detection is the constructing block of quite a few purposes together with self-driving automobiles, monitored surveillance, and even robotics.
An object detection mannequin will be categorised into two completely different classes, single-shot detectors, and multi-shot detectors.
Actual Time Object Detection
To really perceive how YOLOv7 works, it’s important for us to grasp YOLOv7’s predominant goal, “Actual Time Object Detection”. Actual Time Object Detection is a key element of recent pc imaginative and prescient. The Actual Time Object Detection fashions attempt to determine & find objects of curiosity in actual time. Actual Time Object Detection fashions made it actually environment friendly for builders to trace objects of curiosity in a transferring body like a video, or a dwell surveillance enter.

Actual Time Object Detection fashions are basically a step forward from the traditional picture detection fashions. Whereas the previous is used to trace objects in video information, the latter locates & identifies objects inside a stationary body like a picture.
In consequence, Actual Time Object Detection fashions are actually environment friendly for video analytics, autonomous autos, object counting, multi-object monitoring, and way more.
What’s YOLO?
YOLO or “You Solely Look As soon as” is a household of actual time object detection fashions. The YOLO idea was first launched in 2016 by Joseph Redmon, and it was the speak of the city nearly immediately as a result of it was a lot faster, and way more correct than the prevailing object detection algorithms. It wasn’t lengthy earlier than the YOLO algorithm turned a normal within the pc imaginative and prescient trade.

The elemental idea that the YOLO algorithm proposes is to make use of an end-to-end neural community utilizing bounding containers & class chances to make predictions in actual time. YOLO was completely different from the earlier object detection mannequin within the sense that it proposed a distinct method to carry out object detection by repurposing classifiers.
The change in method labored as YOLO quickly turned the trade normal because the efficiency hole between itself, and different actual time object detection algorithms had been important. However what was the explanation why YOLO was so environment friendly?
When in comparison with YOLO, object detection algorithms again then used Area Proposal Networks to detect doable areas of curiosity. The popularity course of was then carried out on every area individually. In consequence, these fashions typically carried out a number of iterations on the identical picture, and therefore the shortage of accuracy, and better execution time. Then again, the YOLO algorithm makes use of a single totally linked layer to carry out the prediction without delay.
How Does YOLO Work?
There are three steps that specify how a YOLO algorithm works.
Reframing Object Detection as a Single Regression Drawback
The YOLO algorithm tries to reframe object detection as a single regression drawback, together with picture pixels, to class chances, and bounding field coordinates. Therefore, the algorithm has to have a look at the picture solely as soon as to foretell & find the goal objects within the photographs.
Causes the Picture Globally
Moreover, when the YOLO algorithm makes predictions, it causes the picture globally. It’s completely different from area proposal-based, and sliding methods because the YOLO algorithm sees the whole picture throughout coaching & testing on the dataset, and is ready to encode contextual details about the lessons, and the way they seem.
Earlier than YOLO, Quick R-CNN was one of the fashionable object detection algorithms that couldn’t see the bigger context within the picture as a result of it used to mistake background patches in a picture for an object. When in comparison with the Quick R-CNN algorithm, YOLO is 50% extra correct in relation to background errors.
Generalizes Illustration of Objects
Lastly, the YOLO algorithm additionally goals at generalizing the representations of objects in a picture. In consequence, when a YOLO algorithm was run on a dataset with pure photographs, and examined for the outcomes, YOLO outperformed current R-CNN fashions by a large margin. It’s as a result of YOLO is very generalizable, the possibilities of it breaking down when applied on surprising inputs or new domains had been slim.
YOLOv7: What’s New?
Now that now we have a fundamental understanding of what actual time object detection fashions are, and what’s the YOLO algorithm, it’s time to debate the YOLOv7 algorithm.
Optimizing the Coaching Course of
The YOLOv7 algorithm not solely tries to optimize the mannequin structure, but it surely additionally goals at optimizing the coaching course of. It goals at utilizing optimization modules & strategies to enhance the accuracy of object detection, strengthening the associated fee for coaching, whereas sustaining the interference value. These optimization modules will be known as a trainable bag of freebies.
Coarse to Superb Lead Guided Label Task
The YOLOv7 algorithm plans to make use of a brand new Coarse to Superb Lead Guided Label Task as a substitute of the traditional Dynamic Label Task. It’s so as a result of with dynamic label task, coaching a mannequin with a number of output layers causes some points, the most typical one among it being the way to assign dynamic targets for various branches and their outputs.
Mannequin Re-Parameterization
Mannequin re-parametrization is a vital idea in object detection, and its use is usually adopted with some points throughout coaching. The YOLOv7 algorithm plans on utilizing the idea of gradient propagation path to research the mannequin re-parametrization insurance policies relevant to completely different layers within the community.
Lengthen and Compound Scaling
The YOLOv7 algorithm additionally introduces the prolonged and compound scaling strategies to make the most of and successfully use the parameters & computations for actual time object detection.

YOLOv7 : Associated Work
Actual Time Object Detection
YOLO is presently the trade normal, and a lot of the actual time object detectors deploy YOLO algorithms, and FCOS (Totally Convolutional One-Stage Object-Detection). A state-of-the-art actual time object detector often has the next traits
- Stronger & quicker community structure.
- An efficient function integration methodology.
- An correct object detection methodology.
- A strong loss operate.
- An environment friendly label task methodology.
- An environment friendly coaching methodology.
The YOLOv7 algorithm doesn’t use self-supervised studying & distillation strategies that usually require massive quantities of knowledge. Conversely, the YOLOv7 algorithm makes use of a trainable bag-of-freebies methodology.
Mannequin Re-Parameterization
Mannequin re-parameterization methods is thought to be an ensemble approach that merges a number of computational modules in an interference stage. The approach will be additional divided into two classes, model-level ensemble, and module-level ensemble.
Now, to acquire the ultimate interference mannequin, the model-level reparameterization approach makes use of two practices. The primary follow makes use of completely different coaching information to coach quite a few equivalent fashions, after which averages the weights of the skilled fashions. Alternatively, the opposite follow averages the weights of fashions throughout completely different iterations.
Module stage re-parameterization is gaining immense reputation lately as a result of it splits a module into completely different module branches, or completely different equivalent branches through the coaching part, after which proceeds to combine these completely different branches into an equal module whereas interference.
Nonetheless, re-parameterization methods can’t be utilized to every kind of structure. It’s the explanation why the YOLOv7 algorithm makes use of new mannequin re-parameterization methods to design associated methods fitted to completely different architectures.
Mannequin Scaling
Mannequin scaling is the method of scaling up or down an current mannequin so it suits throughout completely different computing gadgets. Mannequin scaling usually makes use of quite a lot of components like variety of layers(depth), measurement of enter photographs(decision), variety of function pyramids(stage), and variety of channels(width). These components play an important position in making certain a balanced commerce off for community parameters, interference velocity, computation, and accuracy of the mannequin.
Some of the generally used scaling strategies is NAS or Community Structure Search that mechanically searches for appropriate scaling components from serps with none sophisticated guidelines. The most important draw back of utilizing the NAS is that it’s an costly method for looking out appropriate scaling components.
Nearly each mannequin re-parameterization mannequin analyzes particular person & distinctive scaling components independently, and moreover, even optimizes these components independently. It’s as a result of the NAS structure works with non-correlated scaling components.
It’s value noting that concatenation-based fashions like VoVNet or DenseNet change the enter width of some layers when the depth of the fashions is scaled. YOLOv7 works on a proposed concatenation-based structure, and therefore makes use of a compound scaling methodology.

The determine talked about above compares the prolonged environment friendly layer aggregation networks (E-ELAN) of various fashions. The proposed E-ELAN methodology maintains the gradient transmission path of the unique structure, however goals at rising the cardinality of the added options utilizing group convolution. The method can improve the options discovered by completely different maps, and may additional make using calculations & parameters extra environment friendly.
YOLOv7 Structure
The YOLOv7 mannequin makes use of the YOLOv4, YOLO-R, and the Scaled YOLOv4 fashions as its base. The YOLOv7 is a results of the experiments carried out on these fashions to enhance the outcomes, and make the mannequin extra correct.
Prolonged Environment friendly Layer Aggregation Community or E-ELAN
E-ELAN is the basic constructing block of the YOLOv7 mannequin, and it’s derived from already current fashions on community effectivity, primarily the ELAN.
The primary issues when designing an environment friendly structure are the variety of parameters, computational density, and the quantity of computation. Different fashions additionally think about components like affect of enter/output channel ratio, branches within the structure community, community interference velocity, variety of components within the tensors of convolutional community, and extra.
The CSPVoNet mannequin not solely considers the above-mentioned parameters, but it surely additionally analyzes the gradient path to study extra various options by enabling the weights of various layers. The method permits the interferences to be a lot quicker, and correct. The ELAN structure goals at designing an environment friendly community to manage the shortest longest gradient path in order that the community will be simpler in studying, and converging.
ELAN has already reached a steady stage whatever the stacking variety of computational blocks, and gradient path size. The steady state is perhaps destroyed if computational blocks are stacked unlimitedly, and the parameter utilization price will diminish. The proposed E-ELAN structure can remedy the difficulty because it makes use of growth, shuffling, and merging cardinality to repeatedly improve the community’s studying means whereas retaining the unique gradient path.
Moreover, when evaluating the structure of E-ELAN with ELAN, the one distinction is within the computational block, whereas the transition layer’s structure is unchanged.
E-ELAN proposes to broaden the cardinality of the computational blocks, and broaden the channel through the use of group convolution. The function map will then be calculated, and shuffled into teams as per the group parameter, and can then be concatenated collectively. The variety of channels in every group will stay the identical as within the unique structure. Lastly, the teams of function maps can be added to carry out cardinality.
Mannequin Scaling for Concatenation Based mostly Fashions
Mannequin scaling helps in adjusting attributes of the fashions that helps in producing fashions as per the necessities, and of various scales to fulfill the completely different interference speeds.

The determine talks about mannequin scaling for various concatenation-based fashions. As you’ll be able to in determine (a) and (b), the output width of the computational block will increase with a rise within the depth scaling of the fashions. Resultantly, the enter width of the transmission layers is elevated. If these strategies are applied on concatenation-based structure the scaling course of is carried out in depth, and it’s depicted in determine (c).
It might thus be concluded that it’s not doable to research the scaling components independently for concatenation-based fashions, and somewhat they should be thought of or analyzed collectively. Due to this fact, for a concatenation primarily based mannequin, it is appropriate to make use of the corresponding compound mannequin scaling methodology. Moreover, when the depth issue is scaled, the output channel of the block should be scaled as effectively.
Trainable Bag of Freebies
A bag of freebies is a time period that builders use to explain a set of strategies or methods that may alter the coaching technique or value in an try to spice up mannequin accuracy. So what are these trainable baggage of freebies in YOLOv7? Let’s take a look.
Deliberate Re-Parameterized Convolution
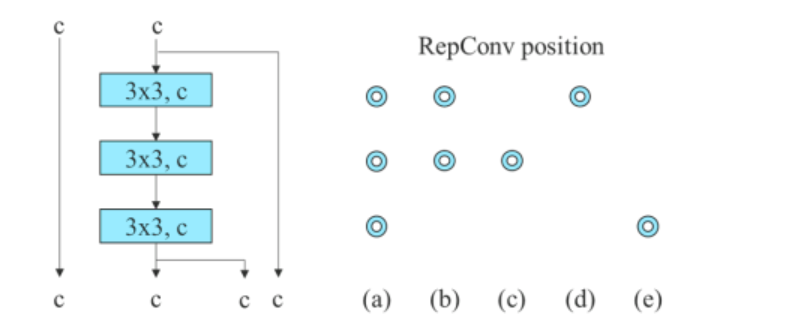
The YOLOv7 algorithm makes use of gradient move propagation paths to find out the way to ideally mix a community with the re-parameterized convolution. This method by YOLov7 is an try to counter RepConv algorithm that though has carried out serenely on the VGG mannequin, performs poorly when utilized on to the DenseNet and ResNet fashions.
To determine the connections in a convolutional layer, the RepConv algorithm combines 3×3 convolution, and 1×1 convolution. If we analyze the algorithm, its efficiency, and the structure we’ll observe that RepConv destroys the concatenation in DenseNet, and the residual in ResNet.

The picture above depicts a deliberate re-parameterized mannequin. It may be seen that the YOLov7 algorithm discovered {that a} layer within the community with concatenation or residual connections shouldn’t have an id connection within the RepConv algorithm. Resultantly, it is acceptable to change with RepConvN with no id connections.
Coarse for Auxiliary and Superb for Lead Loss
Deep Supervision is a department in pc science that usually finds its use within the coaching technique of deep networks. The elemental precept of deep supervision is that it provides an extra auxiliary head within the center layers of the community together with the shallow community weights with assistant loss as its information. The YOLOv7 algorithm refers back to the head that’s chargeable for the ultimate output because the lead head, and the auxiliary head is the pinnacle that assists in coaching.
Transferring alongside, YOLOv7 makes use of a distinct methodology for label task. Conventionally, label task has been used to generate labels by referring on to the bottom fact, and on the premise of a given algorithm. Nonetheless, lately, the distribution, and high quality of the prediction enter performs an necessary position to generate a dependable label. YOLOv7 generates a comfortable label of the article through the use of the predictions of bounding field and floor fact.
Moreover, the brand new label task methodology of the YOLOv7 algorithm makes use of lead head’s predictions to information each the lead & the auxiliary head. The label task methodology has two proposed methods.
Lead Head Guided Label Assigner
The technique makes calculations on the premise of the lead head’s prediction outcomes, and the bottom fact, after which makes use of optimization to generate comfortable labels. These comfortable labels are then used because the coaching mannequin for each the lead head, and the auxiliary head.
The technique works on the belief that as a result of the lead head has a better studying functionality, the labels it generates needs to be extra consultant, and correlate between the supply & the goal.
Coarse-to-Superb Lead Head Guided Label Assigner
This technique additionally makes calculations on the premise of the lead head’s prediction outcomes, and the bottom fact, after which makes use of optimization to generate comfortable labels. Nonetheless, there’s a key distinction. On this technique, there are two units of soppy labels, coarse stage, and high-quality label.
The coarse label is generated by by enjoyable the constraints of the constructive pattern
task course of that treats extra grids as constructive targets. It’s performed to keep away from the chance of dropping data due to the auxiliary head’s weaker studying power.

The determine above explains using a trainable bag of freebies within the YOLOv7 algorithm. It depicts coarse for the auxiliary head, and high-quality for the lead head. Once we evaluate a Mannequin with Auxiliary Head(b) with the Regular Mannequin (a), we’ll observe that the schema in (b) has an auxiliary head, whereas it’s not in (a).
Determine (c) depicts the widespread unbiased label assigner whereas determine (d) & determine (e) respectively signify the Lead Guided Assigner, and the Coarse-toFine Lead Guided Assigner utilized by YOLOv7.
Different Trainable Bag of Freebies
Along with those talked about above, the YOLOv7 algorithm makes use of further baggage of freebies, though they weren’t proposed by them initially. They’re
- Batch Normalization in Conv-Bn-Activation Know-how: This technique is used to attach a convolutional layer on to the batch normalization layer.
- Implicit Information in YOLOR: The YOLOv7 combines the technique with the Convolutional function map.
- EMA Mannequin: The EMA mannequin is used as a remaining reference mannequin in YOLOv7 though its main use is for use within the imply trainer methodology.
YOLOv7 : Experiments
Experimental Setup
The YOLOv7 algorithm makes use of the Microsoft COCO dataset for coaching and validating their object detection mannequin, and never all of those experiments use a pre-trained mannequin. The builders used the 2017 prepare dataset for coaching, and used the 2017 validation dataset for choosing the hyperparameters. Lastly, the efficiency of the YOLOv7 object detection outcomes are in contrast with state-of-the-art algorithms for object detection.
Builders designed a fundamental mannequin for edge GPU (YOLOv7-tiny), regular GPU (YOLOv7), and cloud GPU (YOLOv7-W6). Moreover, the YOLOv7 algorithm additionally makes use of a fundamental mannequin for mannequin scaling as per completely different service necessities, and will get completely different fashions. For the YOLOv7 algorithm the stack scaling is finished on the neck, and proposed compounds are used to upscale the depth & width of the mannequin.
Baselines
The YOLOv7 algorithm makes use of earlier YOLO fashions, and the YOLOR object detection algorithm as its baseline.

The above determine compares the baseline of the YOLOv7 mannequin with different object detection fashions, and the outcomes are fairly evident. When put next with the YOLOv4 algorithm, YOLOv7 not solely makes use of 75% much less parameters, but it surely additionally makes use of 15% much less computation, and has 0.4% larger accuracy.
Comparability with State of the Artwork Object Detector Fashions

The above determine exhibits the outcomes when YOLOv7 is in contrast in opposition to state-of-the-art object detection fashions for cellular & normal GPUs. It may be noticed that the strategy proposed by the YOLOv7 algorithm has one of the best speed-accuracy trade-off rating.
Ablation Research : Proposed Compound Scaling Methodology

The determine proven above compares the outcomes of utilizing completely different methods for scaling up the mannequin. The scaling technique within the YOLOv7 mannequin scales up the depth of the computational block by 1.5 instances, and scales the width by 1.25 instances.
When put next with a mannequin that solely scales up the depth, the YOLOv7 mannequin performs higher by 0.5% whereas utilizing much less parameters, and computation energy. Then again, compared with fashions that solely scale up the depth, YOLOv7’s accuracy is improved by 0.2%, however the variety of parameters should be scaled by 2.9%, and computation by 1.2%.
Proposed Deliberate Re-Parameterized Mannequin
To confirm the generality of its proposed re-parameterized mannequin, the YOLOv7 algorithm makes use of it on residual-based, and concatenation primarily based fashions for verification. For the verification course of, the YOLOv7 algorithm makes use of 3-stacked ELAN for the concatenation-based mannequin, and CSPDarknet for residual-based mannequin.
For the concatenation-based mannequin, the algorithm replaces the three×3 convolutional layers within the 3-stacked ELAN with RepConv. The determine under exhibits the detailed configuration of Deliberate RepConv, and 3-stacked ELAN.
Moreover, when coping with the residual-based mannequin, the YOLOv7 algorithm makes use of a reversed darkish block as a result of the unique darkish block doesn’t have a 3×3 convolution block. The under determine exhibits the structure of the Reversed CSPDarknet that reverses the positions of the three×3 and the 1×1 convolutional layer. 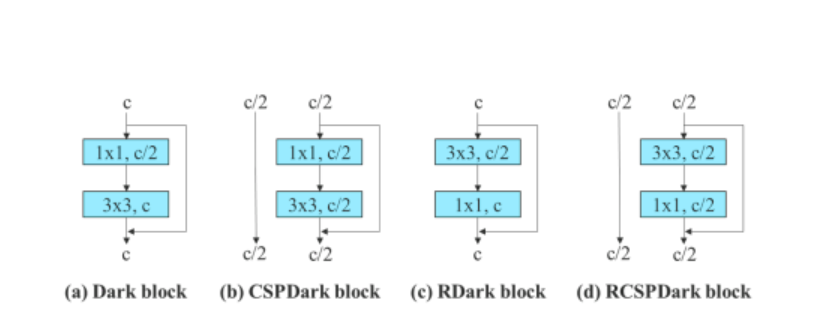
Proposed Assistant Loss for Auxiliary Head
For the assistant loss for auxiliary head, the YOLOv7 mannequin compares the unbiased label task for the auxiliary head & lead head strategies.

The determine above comprises the outcomes of the research on the proposed auxiliary head. It may be seen that the general efficiency of the mannequin will increase with a rise within the assistant loss. Moreover, the lead guided label task proposed by the YOLOv7 mannequin performs higher than unbiased lead task methods.
YOLOv7 Outcomes
Based mostly on the above experiments, right here’s the results of YOLov7’s efficiency when in comparison with different object detection algorithms.

The above determine compares the YOLOv7 mannequin with different object detection algorithms, and it may be clearly noticed that the YOLOv7 surpasses different objection detection fashions by way of Common Precision (AP) v/s batch interference.
Moreover, the under determine compares the efficiency of YOLOv7 v/s different actual time objection detection algorithms. As soon as once more, YOLOv7 succeeds different fashions by way of the general efficiency, accuracy, and effectivity.

Listed below are some further observations from the YOLOv7 outcomes & performances.
- The YOLOv7-Tiny is the smallest mannequin within the YOLO household, with over 6 million parameters. The YOLOv7-Tiny has an Common Precision of 35.2%, and it outperforms the YOLOv4-Tiny fashions with comparable parameters.
- The YOLOv7 mannequin has over 37 million parameters, and it outperforms fashions with larger parameters like YOLov4.
- The YOLOv7 mannequin has the very best mAP and FPS price within the vary of 5 to 160 FPS.
Conclusion
YOLO or You Solely Look As soon as is the state-of-the-art object detection mannequin in fashionable pc imaginative and prescient. The YOLO algorithm is understood for its excessive accuracy, and effectivity, and consequently, it finds intensive utility in the actual time object detection trade. Ever for the reason that first YOLO algorithm was launched again in 2016, experiments have allowed builders to enhance the mannequin repeatedly.
The YOLOv7 mannequin is the most recent addition within the YOLO household, and it’s essentially the most highly effective YOLo algorithm until date. On this article, now we have talked concerning the fundamentals of YOLOv7, and tried to elucidate what makes YOLOv7 so environment friendly.