

The previous few years has witnessed a speedy development within the efficiency, effectivity, and generative capabilities of rising novel AI generative fashions that leverage intensive datasets, and 2D diffusion technology practices. Right now, generative AI fashions are extraordinarily able to producing totally different types of 2D, and to some extent, 3D media content material together with textual content, pictures, movies, GIFs, and extra.
On this article, we can be speaking in regards to the Zero123++ framework, an image-conditioned diffusion generative AI mannequin with the purpose to generate 3D-consistent multiple-view pictures utilizing a single view enter. To maximise the benefit gained from prior pretrained generative fashions, the Zero123++ framework implements quite a few coaching and conditioning schemes to attenuate the quantity of effort it takes to finetune from off-the-shelf diffusion picture fashions. We can be taking a deeper dive into the structure, working, and the outcomes of the Zero123++ framework, and analyze its capabilities to generate constant multiple-view pictures of top quality from a single picture. So let’s get began.
The Zero123++ framework is an image-conditioned diffusion generative AI mannequin that goals to generate 3D-consistent multiple-view pictures utilizing a single view enter. The Zero123++ framework is a continuation of the Zero123 or Zero-1-to-3 framework that leverages zero-shot novel view picture synthesis approach to pioneer open-source single-image -to-3D conversions. Though the Zero123++ framework delivers promising efficiency, the photographs generated by the framework have seen geometric inconsistencies, and it is the principle cause why the hole between 3D scenes, and multi-view pictures nonetheless exists.
The Zero-1-to-3 framework serves as the muse for a number of different frameworks together with SyncDreamer, One-2-3-45, Consistent123, and extra that add further layers to the Zero123 framework to acquire extra constant outcomes when producing 3D pictures. Different frameworks like ProlificDreamer, DreamFusion, DreamGaussian, and extra comply with an optimization-based strategy to acquire 3D pictures by distilling a 3D picture from numerous inconsistent fashions. Though these strategies are efficient, and so they generate passable 3D pictures, the outcomes might be improved with the implementation of a base diffusion mannequin able to producing multi-view pictures persistently. Accordingly, the Zero123++ framework takes the Zero-1 to-3, and finetunes a brand new multi-view base diffusion mannequin from Secure Diffusion.
Within the zero-1-to-3 framework, every novel view is independently generated, and this strategy results in inconsistencies between the views generated as diffusion fashions have a sampling nature. To deal with this difficulty, the Zero123++ framework adopts a tiling format strategy, with the thing being surrounded by six views right into a single picture, and ensures the right modeling for the joint distribution of an object’s multi-view pictures.
One other main problem confronted by builders engaged on the Zero-1-to-3 framework is that it underutilizes the capabilities supplied by Secure Diffusion that finally results in inefficiency, and added prices. There are two main explanation why the Zero-1-to-3 framework can not maximize the capabilities supplied by Secure Diffusion
- When coaching with picture circumstances, the Zero-1-to-3 framework doesn’t incorporate native or world conditioning mechanisms supplied by Secure Diffusion successfully.
- Throughout coaching, the Zero-1-to-3 framework makes use of lowered decision, an strategy through which the output decision is lowered under the coaching decision that may scale back the standard of picture technology for Secure Diffusion fashions.
To deal with these points, the Zero123++ framework implements an array of conditioning strategies that maximizes the utilization of assets supplied by Secure Diffusion, and maintains the standard of picture technology for Secure Diffusion fashions.
Bettering Conditioning and Consistencies
In an try to enhance picture conditioning, and multi-view picture consistency, the Zero123++ framework carried out totally different strategies, with the first goal being reusing prior strategies sourced from the pretrained Secure Diffusion mannequin.
Multi-View Technology
The indispensable high quality of producing constant multi-view pictures lies in modeling the joint distribution of a number of pictures appropriately. Within the Zero-1-to-3 framework, the correlation between multi-view pictures is ignored as a result of for each picture, the framework fashions the conditional marginal distribution independently and individually. Nevertheless, within the Zero123++ framework, builders have opted for a tiling format strategy that tiles 6 pictures right into a single body/picture for constant multi-view technology, and the method is demonstrated within the following picture.
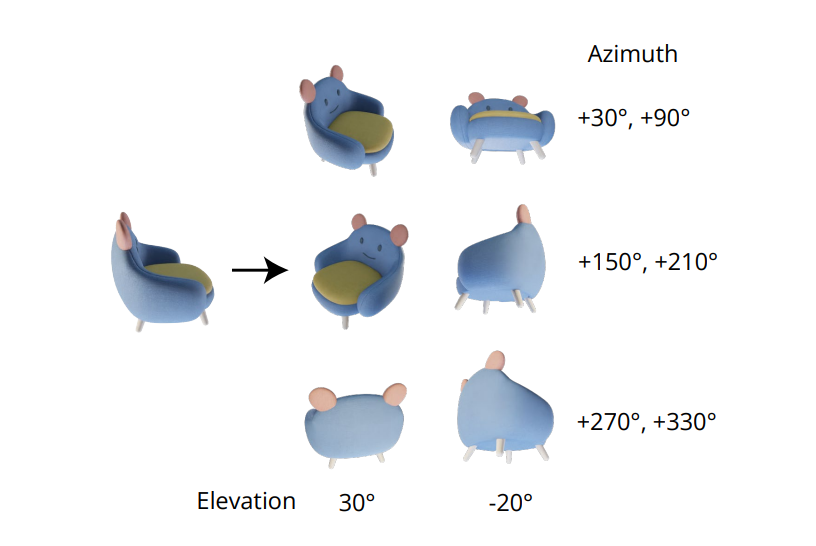
Moreover, it has been observed that object orientations are inclined to disambiguate when coaching the mannequin on digital camera poses, and to forestall this disambiguation, the Zero-1-to-3 framework trains on digital camera poses with elevation angles and relative azimuth to the enter. To implement this strategy, it’s essential to know the elevation angle of the view of the enter that’s then used to find out the relative pose between novel enter views. In an try to know this elevation angle, frameworks typically add an elevation estimation module, and this strategy typically comes at the price of further errors within the pipeline.
Noise Schedule
Scaled-linear schedule, the unique noise schedule for Secure Diffusion focuses totally on native particulars, however as it may be seen within the following picture, it has only a few steps with decrease SNR or Sign to Noise Ratio.

These steps of low Sign to Noise Ratio happen early throughout the denoising stage, a stage essential for figuring out the worldwide low-frequency construction. Decreasing the variety of steps throughout the denoising stage, both throughout interference or coaching typically leads to a higher structural variation. Though this setup is good for single-image technology it does restrict the power of the framework to make sure world consistency between totally different views. To beat this hurdle, the Zero123++ framework finetunes a LoRA mannequin on the Secure Diffusion 2 v-prediction framework to carry out a toy process, and the outcomes are demonstrated under.

With the scaled-linear noise schedule, the LoRA mannequin doesn’t overfit, however solely whitens the picture barely. Conversely, when working with the linear noise schedule, the LoRA framework generates a clean picture efficiently no matter the enter immediate, thus signifying the impression of noise schedule on the power of the framework to adapt to new necessities globally.
Scaled Reference Consideration for Native Circumstances
The only view enter or the conditioning pictures within the Zero-1-to-3 framework is concatenated with the noisy inputs within the characteristic dimension to be noised for picture conditioning.
This concatenation results in an incorrect pixel-wise spatial correspondence between the goal picture, and the enter. To supply correct native conditioning enter, the Zero123++ framework makes use of a scaled Reference Consideration, an strategy through which working a denoising UNet mannequin is referred on an additional reference picture, adopted by the appendation of worth matrices and self-attention key from the reference picture to the respective consideration layers when the mannequin enter is denoised, and it’s demonstrated within the following determine.

The Reference Consideration strategy is able to guiding the diffusion mannequin to generate pictures sharing resembling texture with the reference picture, and semantic content material with none finetuning. With nice tuning, the Reference Consideration strategy delivers superior outcomes with the latent being scaled.

World Conditioning : FlexDiffuse
Within the unique Secure Diffusion strategy, the textual content embeddings are the one supply for world embeddings, and the strategy employs the CLIP framework as a textual content encoder to carry out cross-examinations between the textual content embeddings, and the mannequin latents. Resultantly, builders are free to make use of the alignment between the textual content areas, and the resultant CLIP pictures to make use of it for world picture conditionings.
The Zero123++ framework proposes to utilize a trainable variant of the linear steering mechanism to include the worldwide picture conditioning into the framework with minimal fine-tuning wanted, and the outcomes are demonstrated within the following picture. As it may be seen, with out the presence of a worldwide picture conditioning, the standard of the content material generated by the framework is passable for seen areas that correspond to the enter picture. Nevertheless, the standard of the picture generated by the framework for unseen areas witnesses vital deterioration which is principally due to the mannequin’s incapability to deduce the thing’s world semantics.

Mannequin Structure
The Zero123++ framework is skilled with the Secure Diffusion 2v-model as the muse utilizing the totally different approaches and strategies talked about within the article. The Zero123++ framework is pre-trained on the Objaverse dataset that’s rendered with random HDRI lighting. The framework additionally adopts the phased coaching schedule strategy used within the Secure Diffusion Picture Variations framework in an try to additional decrease the quantity of fine-tuning required, and protect as a lot as potential within the prior Secure Diffusion.
The working or structure of the Zero123++ framework will be additional divided into sequential steps or phases. The primary section witnesses the framework fine-tune the KV matrices of cross-attention layers, and the self-attention layers of Secure Diffusion with AdamW as its optimizer, 1000 warm-up steps and the cosine studying price schedule maximizing at 7×10-5. Within the second section, the framework employs a extremely conservative fixed studying price with 2000 heat up units, and employs the Min-SNR strategy to maximise the effectivity throughout the coaching.
Zero123++ : Outcomes and Efficiency Comparability
Qualitative Efficiency
To evaluate the efficiency of the Zero123++ framework on the premise of its high quality generated, it’s in contrast in opposition to SyncDreamer, and Zero-1-to-3- XL, two of the best state-of-the-art frameworks for content material technology. The frameworks are in contrast in opposition to 4 enter pictures with totally different scope. The primary picture is an electrical toy cat, taken instantly from the Objaverse dataset, and it boasts of a big uncertainty on the rear finish of the thing. Second is the picture of a hearth extinguisher, and the third one is the picture of a canine sitting on a rocket, generated by the SDXL mannequin. The ultimate picture is an anime illustration. The required elevation steps for the frameworks are achieved through the use of the One-2-3-4-5 framework’s elevation estimation methodology, and background elimination is achieved utilizing the SAM framework. As it may be seen, the Zero123++ framework generates prime quality multi-view pictures persistently, and is able to generalizing to out-of-domain 2D illustration, and AI-generated pictures equally nicely.


Quantitative Evaluation
To quantitatively evaluate the Zero123++ framework in opposition to state-of-the-art Zero-1-to-3 and Zero-1to-3 XL frameworks, builders consider the Discovered Perceptual Picture Patch Similarity (LPIPS) rating of those fashions on the validation break up knowledge, a subset of the Objaverse dataset. To judge the mannequin’s efficiency on multi-view picture technology, the builders tile the bottom fact reference pictures, and 6 generated pictures respectively, after which compute the Discovered Perceptual Picture Patch Similarity (LPIPS) rating. The outcomes are demonstrated under and as it may be clearly seen, the Zero123++ framework achieves the most effective efficiency on the validation break up set.

Textual content to Multi-View Analysis
To judge Zero123++ framework’s potential in Textual content to Multi-View content material technology, builders first use the SDXL framework with textual content prompts to generate a picture, after which make use of the Zero123++ framework to the picture generated. The outcomes are demonstrated within the following picture, and as it may be seen, when in comparison with the Zero-1-to-3 framework that can’t assure constant multi-view technology, the Zero123++ framework returns constant, lifelike, and extremely detailed multi-view pictures by implementing the text-to-image-to-multi-view strategy or pipeline.

Zero123++ Depth ControlNet
Along with the bottom Zero123++ framework, builders have additionally launched the Depth ControlNet Zero123++, a depth-controlled model of the unique framework constructed utilizing the ControlNet structure. The normalized linear pictures are rendered in respect with the next RGB pictures, and a ControlNet framework is skilled to regulate the geometry of the Zero123++ framework utilizing depth notion.

Conclusion
On this article, we have now talked about Zero123++, an image-conditioned diffusion generative AI mannequin with the purpose to generate 3D-consistent multiple-view pictures utilizing a single view enter. To maximise the benefit gained from prior pretrained generative fashions, the Zero123++ framework implements quite a few coaching and conditioning schemes to attenuate the quantity of effort it takes to finetune from off-the-shelf diffusion picture fashions. We’ve additionally mentioned the totally different approaches and enhancements carried out by the Zero123++ framework that helps it obtain outcomes corresponding to, and even exceeding these achieved by present state-of-the-art frameworks.
Nevertheless, regardless of its effectivity, and skill to generate high-quality multi-view pictures persistently, the Zero123++ framework nonetheless has some room for enchancment, with potential areas of analysis being a
- Two-Stage Refiner Mannequin which may resolve Zero123++’s incapability to satisfy world necessities for consistency.
- Extra Scale-Ups to additional improve Zero123++’s potential to generate pictures of even greater high quality.